VRP的优质解与劣质解的区别分析

关键词
数据挖掘 启发式 车辆路由问题 问题特定知识
文章概述
启发式算法是解决复杂组合优化问题时的首选武器。尽管大量的研究集中在对特定问题调整启发式,但很少有研究来研究问题本身的结构特征。
文章认为,关于区分组合优化问题的好解和不那么好解的结构特征的知识,可以有助于设计有效的启发式方法。文章开发了一种基于数据挖掘的方法,可以生成这样的知识,并将其应用于车辆的路径问题。
通过定义几个度量标准来描述VRP解决方案和VRP实例,并为各种实例生成和分类192.000个解决方案。
有了这些指标,我们就能够区分最优解和非最优解,准确率高达90%。我们讨论了良好的VRP解决方案的最显著的特征,并展示了如何使用由此产生的知识来提高现有的启发式方法的性能。
设计指标,然后用数据挖掘的方式判定哪些指标有用,然后用这些指标区分不同解,也没挖出知识来啊。。。由果推因,只能说是相关性吧,大概率有用之类的,
研究背景
对于许多组合优化问题,基于局部搜索或构造策略的启发式算法已经被证明可以提供解决方案质量和计算时间之间的最佳权衡。近年来,启发式策略的效率在很大程度上取决于它如何利用正在解决的问题的特点。为了尽可能高效,启发式搜索策略需要一些关于好的解决方案和不太好的解决方案的区别的知识。
然而,在许多情况下,这一知识仅限于一个琐碎的事实,即前者的目标函数将比后者的目标函数更接近最优。一个在很大程度上仍未回答的问题是,是否有可能确定好的解决方案在结构上与不那么好的解决方案是否不同,也就是说,我们是否可以仅通过查看解决方案本身而不是它们的目标函数值来区分接近最优的解决方案和不那么接近最优的解决方案。
研究目的
研究好的解决方案的特点,而不是那些不太好的解决方案的VRP,这些信息可以用来指导搜索。
例如,如果有可能识别出不太可能出现在良好的解决方案中的边,则可以使用一种策略,试图删除这些边。指导启发式搜索过程并使其适应所解决的特定问题实例的想法已经引起了大量的关注。
使用数据挖掘技术来寻找区分VRP的好的和不太好的解决方案的特征。
数据挖掘的目的是找到能够在大量数据中识别模式和建立关系的模型。与统计数据相反,这些模型的目标不是“推断真实的分布,而是尽可能准确地预测未来的数据”。
换句话说,通过数据挖掘,我们的目标是预测以前未见过的数据,而不是解释手头的数据,重点是关联,而不是因果关系。
预测模型并不一定能提供因果关系的解释。然而,也有可能推导出一些因果理论。如果使用简单的线性模型作为偏好模型,就可以通过观察它们的系数来解释不同特征的相对重要性。如果内部模型是非线性的,可以使用规则提取来获得一组解释预测的规则。
这样,我们就能从数据中推断出理论。由于这些理论是广义的发现,可以很容易地应用于新的数据,问题的特征通常是一组相关的或具有代表性的实例,例如基准测试实例。如果关于问题的发现可以推广到所有相关的实例,那就是特定于问题的知识。
度量指标
解决方法的度量
为了发现好的解决方案的典型特征,我们需要用定义的度量来“度量”一个解决方案,也就是说,我们需要将解决方案的结构转换为定量度量,然后作为预测模型的输入。这一步是高度探索性的,因为没有关于应该包括哪些指标的指导方针,作为一个经验法则,我们可以定义的指标越多,分类学习者检测到模式的机会就越大。
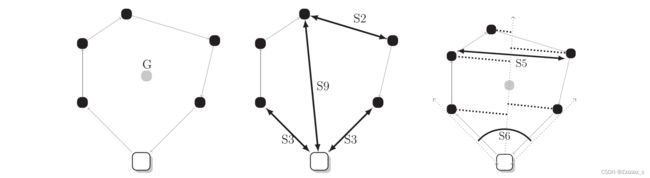


这些指标及其度量在上图中可视化。前两个指标反映了运筹学领域的观察结果,特别是关于著名的旅行推销员问题。我们期望好的解决方案往往有更少的交叉点和更少的极长的边。相比之下,其他指标的影响似乎还不太完善。度量S3是探索性的,我们假设在好的解决方案中,连接仓库和客户的边缘应该相当短。直观地看,路线应清晰分开(S4),宽度(S5)和深度(S9)。
因此,我们期望好的解决方案平均会有更少、更宽、更深的路线,从而导致它们之间的距离相对较高。路线的宽度也可以通过查看客户朝向仓库的弧度来解释(S6)。狭窄的路线也往往对其客户的弧度有较小的差异,这是在流行的扫描启发式中使用的。路线的形状可以更像一条线(非常紧凑),也可以更圆形(不那么紧凑),我们用S7来测量。请注意,度规的紧致度与度规的宽度非常相似,因为紧凑的路线往往不那么宽。然后,紧致度也可以通过一个路线的客户的弧度的变化来衡量(S8)。最后,使用S10,我们根据交付的客户的数量来衡量路线的平衡程度。
路由的数量通常也是标准VRP中的解决方案的一部分。但是,为了简单起见,我们假设路由的数量是预先定义的,并且在接近最优和各自的非最优解中的路由的数量总是相同的。得出这一假设的原因是,我们研究了溶液的结构对其质量的影响,而不同数量的路由可能会显著改变解的结构
实例的度量
上述解决方案指标的值取决于各自的实例。例如,如下图所示。对于这两种情况,每条路线的平均宽度在最优解中都较低,由此可以得出结论,低宽度是好解的一个预测器。但是,这两个实例之间的值并没有可比性,因为这些实例在路由的数量和客户的数量和位置上有所不同。
分类器不知道两组解度量(对于接近最优和非最优解)是否来自同一实例并成对,只有比较绝对值才会导致错误或没有预测。因此,我们需要根据各自的实例来规范化解决方案的度量标准。这就需要定义能够捕获实例特征的相关度量标准。


指标I1和I2是基本的实例参数。产能利用率(I3)由需求除以所有车辆的可用产能。这个值对于每个实例的所有计算解都是相同的,因为我们确定了车辆的数量。最后五个指标表明了客户对彼此和仓库的相对位置。例如,如果客户更集群,I4更低,如果客户均匀分散,I4更高。同样地,如果仓库处于更中心的位置,I7也会更低。对于每个客户,我们也从仓库的角度来确定弧度。那么,如果仓库位于边缘,客户更聚集,I8的值较低。
创新点
研究的创新性在于其方法论的方法。它使用数据挖掘来生成关于VRP解决方案的见解,这是该领域中的一种新颖方法。这种预测建模用于指导设计更高效的启发式算法,可能适用于广泛的组合优化问题。
通过上述过程,我们希望通过以下方式获得特定于问题的知识。我们生成实例,对于每个实例,我们计算一个接近最优的解和一个非最优的解。然后,我们从两个解决方案中提取已定义的特征,并使用分类学习器来找到两种解决方案类型之间的区分模式。
研究思路
我们想了解一个好的解决方案的特点。根据不同的公式,我们可以问是什么区分最优或接近最优解和更差的解。如果我们找到这样的有区别的属性,它们可以帮助我们更有效地找到这些好的解,每个启发式的目标是什么。因此,我们需要计算和比较不同质量的解。找到这些特性之后,根据这些特性设计启发式算法,实验表明,当问题实例增加复杂性时,特定问题的知识变得更有价值。随着更高的复杂性,在搜索的每一步中可能的选项的数量也会增加,因此,即使是有限的知识也可以帮助做出更好的决策。
研究结果
研究结论与讨论
先定义一些特性,然后根据数据挖掘技术,生成大量的实例来判断这些特性的有效性,然后根据这些特性设计启发式算法求解问题。
本文介绍了一个推导组合优化问题的问题特定知识的框架,并将其应用于车辆路径问题。该框架的核心是数据挖掘,这是一种发现和提取模式并将其推广到新数据的技术。因此,最具挑战性的步骤是定义相关度量来度量解决方案的结构和实例的结构。这是一项探索性的任务,需要对问题有更深入的理解和一些创造力。
在VRP的例子中,路线的紧致性、宽度和弧度的跨度,以及相交边的数量和连接边到仓库的距离是接近最优和非最优解的区别特征。
证明了这些特征可以通过引导搜索过程来更好地创建一个好的启发式。特定问题的知识可以到特定的启发式中,可能取决于它的设计。在我们的例子中,我们简单地调整了边缘的评价函数,得到了更好的结果。一般来说,围绕特定问题的知识建立一个启发式似乎是合理的,而不是建立相反的方法。如果我们知道好的解决方案的结构特征,那么设计操作符和函数来引导我们到达似乎是明智的
在这项工作中,我们只是触及了可能的表面。在推导出的规则集的帮助下,指南可以以更精细的具体方式设计。在启发式的每一步中,我们可以识别相关的规则,并相应地调整参数和操作符,例如,优先消除某些交叉口,而不是减少路线宽度。这个过程可能是启发式设计自动化的第一步。给定一个特定的问题,以及元启发式设计、操作符和特定问题知识的数据库,一个有效的启发式几乎可以自主开发,辅以开发人员的创造力和经验。
我以为这些基于问题的知识是用数据挖掘挖出来的,结果是自己定义的,然后用数据挖掘证实了是有用的,这是假设检验?欺负我概率与统计学的不好啊。这相关性检验??
后续工作
目前有50多篇引用了这篇文献,想知道他们是怎么使用的。学一学别人的思路,顺藤摸瓜试一下。2023年12月14日17:21:09
