【深度学习】注意力机制(四)
本文介绍一些注意力机制的实现,包括VIP/CoAtNet/Scaling Local Self-Attention/PSA/CoT。
【深度学习】注意力机制(一)
【深度学习】注意力机制(二)
【深度学习】注意力机制(三)
【深度学习】注意力机制(五)
目录
一、VIP
二、CoAtNet Attention
三、Scaling Local Self-Attention
四、Polarized Self-Attention
五、CoT(Contextual Transformer block)
一、VIP
论文地址:VISION PERMUTATOR: A PERMUTABLE MLP-LIKE ARCHITECTURE FOR VISUAL RECOGNITION
如下图:
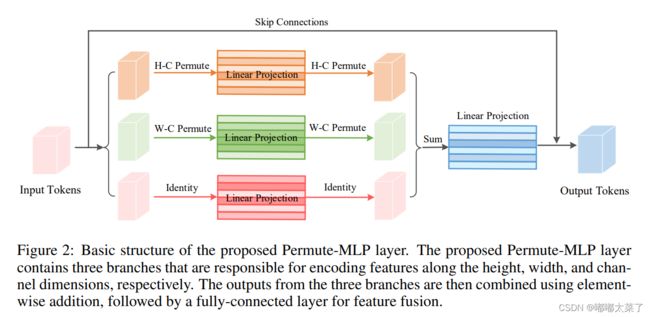
该模块依赖于timm,代码如下(代码链接):
import torch
import torch.nn as nn
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.layers import DropPath, trunc_normal_
from timm.models.registry import register_model
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .96, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD, 'classifier': 'head',
**kwargs
}
default_cfgs = {
'ViP_S': _cfg(crop_pct=0.9),
'ViP_M': _cfg(crop_pct=0.9),
'ViP_L': _cfg(crop_pct=0.875),
}
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class WeightedPermuteMLP(nn.Module):
def __init__(self, dim, segment_dim=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.segment_dim = segment_dim
self.mlp_c = nn.Linear(dim, dim, bias=qkv_bias)
self.mlp_h = nn.Linear(dim, dim, bias=qkv_bias)
self.mlp_w = nn.Linear(dim, dim, bias=qkv_bias)
self.reweight = Mlp(dim, dim // 4, dim *3)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, H, W, C = x.shape
S = C // self.segment_dim
h = x.reshape(B, H, W, self.segment_dim, S).permute(0, 3, 2, 1, 4).reshape(B, self.segment_dim, W, H*S)
h = self.mlp_h(h).reshape(B, self.segment_dim, W, H, S).permute(0, 3, 2, 1, 4).reshape(B, H, W, C)
w = x.reshape(B, H, W, self.segment_dim, S).permute(0, 1, 3, 2, 4).reshape(B, H, self.segment_dim, W*S)
w = self.mlp_w(w).reshape(B, H, self.segment_dim, W, S).permute(0, 1, 3, 2, 4).reshape(B, H, W, C)
c = self.mlp_c(x)
a = (h + w + c).permute(0, 3, 1, 2).flatten(2).mean(2)
a = self.reweight(a).reshape(B, C, 3).permute(2, 0, 1).softmax(dim=0).unsqueeze(2).unsqueeze(2)
x = h * a[0] + w * a[1] + c * a[2]
x = self.proj(x)
x = self.proj_drop(x)
return x
二、CoAtNet Attention
该网络将卷积和注意力结合起来,论文地址:CoAtNet: Marrying Convolution and Attention for All Data Sizes
如下图(论文没图,图片来自图片来源):

代码如下(代码来源):
import torch
import torch.nn as nn
from einops import rearrange
from einops.layers.torch import Rearrange
def conv_3x3_bn(inp, oup, image_size, downsample=False):
stride = 1 if downsample == False else 2
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.GELU()
)
class PreNorm(nn.Module):
def __init__(self, dim, fn, norm):
super().__init__()
self.norm = norm(dim)
self.fn = fn
def forward(self, x, **kwargs):
return self.fn(self.norm(x), **kwargs)
class SE(nn.Module):
def __init__(self, inp, oup, expansion=0.25):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(oup, int(inp * expansion), bias=False),
nn.GELU(),
nn.Linear(int(inp * expansion), oup, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout=0.):
super().__init__()
self.net = nn.Sequential(
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
class MBConv(nn.Module):
def __init__(self, inp, oup, image_size, downsample=False, expansion=4):
super().__init__()
self.downsample = downsample
stride = 1 if self.downsample == False else 2
hidden_dim = int(inp * expansion)
if self.downsample:
self.pool = nn.MaxPool2d(3, 2, 1)
self.proj = nn.Conv2d(inp, oup, 1, 1, 0, bias=False)
if expansion == 1:
self.conv = nn.Sequential(
# dw
nn.Conv2d(hidden_dim, hidden_dim, 3, stride,
1, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.GELU(),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
# pw
# down-sample in the first conv
nn.Conv2d(inp, hidden_dim, 1, stride, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.GELU(),
# dw
nn.Conv2d(hidden_dim, hidden_dim, 3, 1, 1,
groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.GELU(),
SE(inp, hidden_dim),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
self.conv = PreNorm(inp, self.conv, nn.BatchNorm2d)
def forward(self, x):
if self.downsample:
return self.proj(self.pool(x)) + self.conv(x)
else:
return x + self.conv(x)
class Attention(nn.Module):
def __init__(self, inp, oup, image_size, heads=8, dim_head=32, dropout=0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == inp)
self.ih, self.iw = image_size
self.heads = heads
self.scale = dim_head ** -0.5
# parameter table of relative position bias
self.relative_bias_table = nn.Parameter(
torch.zeros((2 * self.ih - 1) * (2 * self.iw - 1), heads))
coords = torch.meshgrid((torch.arange(self.ih), torch.arange(self.iw)))
coords = torch.flatten(torch.stack(coords), 1)
relative_coords = coords[:, :, None] - coords[:, None, :]
relative_coords[0] += self.ih - 1
relative_coords[1] += self.iw - 1
relative_coords[0] *= 2 * self.iw - 1
relative_coords = rearrange(relative_coords, 'c h w -> h w c')
relative_index = relative_coords.sum(-1).flatten().unsqueeze(1)
self.register_buffer("relative_index", relative_index)
self.attend = nn.Softmax(dim=-1)
self.to_qkv = nn.Linear(inp, inner_dim * 3, bias=False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, oup),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
qkv = self.to_qkv(x).chunk(3, dim=-1)
q, k, v = map(lambda t: rearrange(
t, 'b n (h d) -> b h n d', h=self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
# Use "gather" for more efficiency on GPUs
relative_bias = self.relative_bias_table.gather(
0, self.relative_index.repeat(1, self.heads))
relative_bias = rearrange(
relative_bias, '(h w) c -> 1 c h w', h=self.ih*self.iw, w=self.ih*self.iw)
dots = dots + relative_bias
attn = self.attend(dots)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
out = self.to_out(out)
return out
class Transformer(nn.Module):
def __init__(self, inp, oup, image_size, heads=8, dim_head=32, downsample=False, dropout=0.):
super().__init__()
hidden_dim = int(inp * 4)
self.ih, self.iw = image_size
self.downsample = downsample
if self.downsample:
self.pool1 = nn.MaxPool2d(3, 2, 1)
self.pool2 = nn.MaxPool2d(3, 2, 1)
self.proj = nn.Conv2d(inp, oup, 1, 1, 0, bias=False)
self.attn = Attention(inp, oup, image_size, heads, dim_head, dropout)
self.ff = FeedForward(oup, hidden_dim, dropout)
self.attn = nn.Sequential(
Rearrange('b c ih iw -> b (ih iw) c'),
PreNorm(inp, self.attn, nn.LayerNorm),
Rearrange('b (ih iw) c -> b c ih iw', ih=self.ih, iw=self.iw)
)
self.ff = nn.Sequential(
Rearrange('b c ih iw -> b (ih iw) c'),
PreNorm(oup, self.ff, nn.LayerNorm),
Rearrange('b (ih iw) c -> b c ih iw', ih=self.ih, iw=self.iw)
)
def forward(self, x):
if self.downsample:
x = self.proj(self.pool1(x)) + self.attn(self.pool2(x))
else:
x = x + self.attn(x)
x = x + self.ff(x)
return x
class CoAtNet(nn.Module):
def __init__(self, image_size, in_channels, num_blocks, channels, num_classes=1000, block_types=['C', 'C', 'T', 'T']):
super().__init__()
ih, iw = image_size
block = {'C': MBConv, 'T': Transformer}
self.s0 = self._make_layer(
conv_3x3_bn, in_channels, channels[0], num_blocks[0], (ih // 2, iw // 2))
self.s1 = self._make_layer(
block[block_types[0]], channels[0], channels[1], num_blocks[1], (ih // 4, iw // 4))
self.s2 = self._make_layer(
block[block_types[1]], channels[1], channels[2], num_blocks[2], (ih // 8, iw // 8))
self.s3 = self._make_layer(
block[block_types[2]], channels[2], channels[3], num_blocks[3], (ih // 16, iw // 16))
self.s4 = self._make_layer(
block[block_types[3]], channels[3], channels[4], num_blocks[4], (ih // 32, iw // 32))
self.pool = nn.AvgPool2d(ih // 32, 1)
self.fc = nn.Linear(channels[-1], num_classes, bias=False)
def forward(self, x):
x = self.s0(x)
x = self.s1(x)
x = self.s2(x)
x = self.s3(x)
x = self.s4(x)
x = self.pool(x).view(-1, x.shape[1])
x = self.fc(x)
return x
def _make_layer(self, block, inp, oup, depth, image_size):
layers = nn.ModuleList([])
for i in range(depth):
if i == 0:
layers.append(block(inp, oup, image_size, downsample=True))
else:
layers.append(block(oup, oup, image_size))
return nn.Sequential(*layers)
def coatnet_0():
num_blocks = [2, 2, 3, 5, 2] # L
channels = [64, 96, 192, 384, 768] # D
return CoAtNet((224, 224), 3, num_blocks, channels, num_classes=1000)
def coatnet_1():
num_blocks = [2, 2, 6, 14, 2] # L
channels = [64, 96, 192, 384, 768] # D
return CoAtNet((224, 224), 3, num_blocks, channels, num_classes=1000)
def coatnet_2():
num_blocks = [2, 2, 6, 14, 2] # L
channels = [128, 128, 256, 512, 1026] # D
return CoAtNet((224, 224), 3, num_blocks, channels, num_classes=1000)
def coatnet_3():
num_blocks = [2, 2, 6, 14, 2] # L
channels = [192, 192, 384, 768, 1536] # D
return CoAtNet((224, 224), 3, num_blocks, channels, num_classes=1000)
def coatnet_4():
num_blocks = [2, 2, 12, 28, 2] # L
channels = [192, 192, 384, 768, 1536] # D
return CoAtNet((224, 224), 3, num_blocks, channels, num_classes=1000)
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
if __name__ == '__main__':
img = torch.randn(1, 3, 224, 224)
net = coatnet_0()
out = net(img)
print(out.shape, count_parameters(net))
net = coatnet_1()
out = net(img)
print(out.shape, count_parameters(net))
net = coatnet_2()
out = net(img)
print(out.shape, count_parameters(net))
net = coatnet_3()
out = net(img)
print(out.shape, count_parameters(net))
net = coatnet_4()
out = net(img)
print(out.shape, count_parameters(net))三、Scaling Local Self-Attention
论文地址:Scaling Local Self-Attention for Parameter Efficient Visual Backbones
如下图:

代码如下(代码来源):
import torch
from torch import nn, einsum
import torch.nn.functional as F
from einops import rearrange, repeat
# relative positional embedding
def to(x):
return {'device': x.device, 'dtype': x.dtype}
def pair(x):
return (x, x) if not isinstance(x, tuple) else x
def expand_dim(t, dim, k):
t = t.unsqueeze(dim = dim)
expand_shape = [-1] * len(t.shape)
expand_shape[dim] = k
return t.expand(*expand_shape)
def rel_to_abs(x):
b, l, m = x.shape
r = (m + 1) // 2
col_pad = torch.zeros((b, l, 1), **to(x))
x = torch.cat((x, col_pad), dim = 2)
flat_x = rearrange(x, 'b l c -> b (l c)')
flat_pad = torch.zeros((b, m - l), **to(x))
flat_x_padded = torch.cat((flat_x, flat_pad), dim = 1)
final_x = flat_x_padded.reshape(b, l + 1, m)
final_x = final_x[:, :l, -r:]
return final_x
def relative_logits_1d(q, rel_k):
b, h, w, _ = q.shape
r = (rel_k.shape[0] + 1) // 2
logits = einsum('b x y d, r d -> b x y r', q, rel_k)
logits = rearrange(logits, 'b x y r -> (b x) y r')
logits = rel_to_abs(logits)
logits = logits.reshape(b, h, w, r)
logits = expand_dim(logits, dim = 2, k = r)
return logits
class RelPosEmb(nn.Module):
def __init__(
self,
block_size,
rel_size,
dim_head
):
super().__init__()
height = width = rel_size
scale = dim_head ** -0.5
self.block_size = block_size
self.rel_height = nn.Parameter(torch.randn(height * 2 - 1, dim_head) * scale)
self.rel_width = nn.Parameter(torch.randn(width * 2 - 1, dim_head) * scale)
def forward(self, q):
block = self.block_size
q = rearrange(q, 'b (x y) c -> b x y c', x = block)
rel_logits_w = relative_logits_1d(q, self.rel_width)
rel_logits_w = rearrange(rel_logits_w, 'b x i y j-> b (x y) (i j)')
q = rearrange(q, 'b x y d -> b y x d')
rel_logits_h = relative_logits_1d(q, self.rel_height)
rel_logits_h = rearrange(rel_logits_h, 'b x i y j -> b (y x) (j i)')
return rel_logits_w + rel_logits_h
# classes
class HaloAttention(nn.Module):
def __init__(
self,
*,
dim,
block_size,
halo_size,
dim_head = 64,
heads = 8
):
super().__init__()
assert halo_size > 0, 'halo size must be greater than 0'
self.dim = dim
self.heads = heads
self.scale = dim_head ** -0.5
self.block_size = block_size
self.halo_size = halo_size
inner_dim = dim_head * heads
self.rel_pos_emb = RelPosEmb(
block_size = block_size,
rel_size = block_size + (halo_size * 2),
dim_head = dim_head
)
self.to_q = nn.Linear(dim, inner_dim, bias = False)
self.to_kv = nn.Linear(dim, inner_dim * 2, bias = False)
self.to_out = nn.Linear(inner_dim, dim)
def forward(self, x):
b, c, h, w, block, halo, heads, device = *x.shape, self.block_size, self.halo_size, self.heads, x.device
assert h % block == 0 and w % block == 0, 'fmap dimensions must be divisible by the block size'
assert c == self.dim, f'channels for input ({c}) does not equal to the correct dimension ({self.dim})'
# get block neighborhoods, and prepare a halo-ed version (blocks with padding) for deriving key values
q_inp = rearrange(x, 'b c (h p1) (w p2) -> (b h w) (p1 p2) c', p1 = block, p2 = block)
kv_inp = F.unfold(x, kernel_size = block + halo * 2, stride = block, padding = halo)
kv_inp = rearrange(kv_inp, 'b (c j) i -> (b i) j c', c = c)
# derive queries, keys, values
q = self.to_q(q_inp)
k, v = self.to_kv(kv_inp).chunk(2, dim = -1)
# split heads
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> (b h) n d', h = heads), (q, k, v))
# scale
q *= self.scale
# attention
sim = einsum('b i d, b j d -> b i j', q, k)
# add relative positional bias
sim += self.rel_pos_emb(q)
# mask out padding (in the paper, they claim to not need masks, but what about padding?)
mask = torch.ones(1, 1, h, w, device = device)
mask = F.unfold(mask, kernel_size = block + (halo * 2), stride = block, padding = halo)
mask = repeat(mask, '() j i -> (b i h) () j', b = b, h = heads)
mask = mask.bool()
max_neg_value = -torch.finfo(sim.dtype).max
sim.masked_fill_(mask, max_neg_value)
# attention
attn = sim.softmax(dim = -1)
# aggregate
out = einsum('b i j, b j d -> b i d', attn, v)
# merge and combine heads
out = rearrange(out, '(b h) n d -> b n (h d)', h = heads)
out = self.to_out(out)
# merge blocks back to original feature map
out = rearrange(out, '(b h w) (p1 p2) c -> b c (h p1) (w p2)', b = b, h = (h // block), w = (w // block), p1 = block, p2 = block)
return out四、Polarized Self-Attention
论文地址:Polarized Self-Attention: Towards High-quality Pixel-wise Regression
如下图:
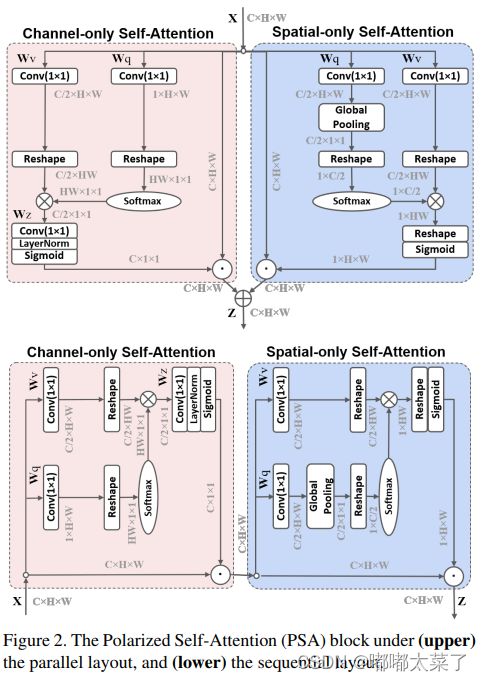
代码如下(代码来源):
import torch
import torch.nn as nn
import torch._utils
import torch.nn.functional as F
def constant_init(module, val, bias=0):
if hasattr(module, 'weight') and module.weight is not None:
nn.init.constant_(module.weight, val)
if hasattr(module, 'bias') and module.bias is not None:
nn.init.constant_(module.bias, bias)
def kaiming_init(module,
a=0,
mode='fan_out',
nonlinearity='relu',
bias=0,
distribution='normal'):
assert distribution in ['uniform', 'normal']
if distribution == 'uniform':
nn.init.kaiming_uniform_(
module.weight, a=a, mode=mode, nonlinearity=nonlinearity)
else:
nn.init.kaiming_normal_(
module.weight, a=a, mode=mode, nonlinearity=nonlinearity)
if hasattr(module, 'bias') and module.bias is not None:
nn.init.constant_(module.bias, bias)
class PSA_p(nn.Module):
def __init__(self, inplanes, planes, kernel_size=1, stride=1):
super(PSA_p, self).__init__()
self.inplanes = inplanes
self.inter_planes = planes // 2
self.planes = planes
self.kernel_size = kernel_size
self.stride = stride
self.padding = (kernel_size-1)//2
self.conv_q_right = nn.Conv2d(self.inplanes, 1, kernel_size=1, stride=stride, padding=0, bias=False)
self.conv_v_right = nn.Conv2d(self.inplanes, self.inter_planes, kernel_size=1, stride=stride, padding=0, bias=False)
self.conv_up = nn.Conv2d(self.inter_planes, self.planes, kernel_size=1, stride=1, padding=0, bias=False)
self.softmax_right = nn.Softmax(dim=2)
self.sigmoid = nn.Sigmoid()
self.conv_q_left = nn.Conv2d(self.inplanes, self.inter_planes, kernel_size=1, stride=stride, padding=0, bias=False) #g
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_v_left = nn.Conv2d(self.inplanes, self.inter_planes, kernel_size=1, stride=stride, padding=0, bias=False) #theta
self.softmax_left = nn.Softmax(dim=2)
self.reset_parameters()
def reset_parameters(self):
kaiming_init(self.conv_q_right, mode='fan_in')
kaiming_init(self.conv_v_right, mode='fan_in')
kaiming_init(self.conv_q_left, mode='fan_in')
kaiming_init(self.conv_v_left, mode='fan_in')
self.conv_q_right.inited = True
self.conv_v_right.inited = True
self.conv_q_left.inited = True
self.conv_v_left.inited = True
def spatial_pool(self, x):
input_x = self.conv_v_right(x)
batch, channel, height, width = input_x.size()
# [N, IC, H*W]
input_x = input_x.view(batch, channel, height * width)
# [N, 1, H, W]
context_mask = self.conv_q_right(x)
# [N, 1, H*W]
context_mask = context_mask.view(batch, 1, height * width)
# [N, 1, H*W]
context_mask = self.softmax_right(context_mask)
# [N, IC, 1]
# context = torch.einsum('ndw,new->nde', input_x, context_mask)
context = torch.matmul(input_x, context_mask.transpose(1,2))
# [N, IC, 1, 1]
context = context.unsqueeze(-1)
# [N, OC, 1, 1]
context = self.conv_up(context)
# [N, OC, 1, 1]
mask_ch = self.sigmoid(context)
out = x * mask_ch
return out
def channel_pool(self, x):
# [N, IC, H, W]
g_x = self.conv_q_left(x)
batch, channel, height, width = g_x.size()
# [N, IC, 1, 1]
avg_x = self.avg_pool(g_x)
batch, channel, avg_x_h, avg_x_w = avg_x.size()
# [N, 1, IC]
avg_x = avg_x.view(batch, channel, avg_x_h * avg_x_w).permute(0, 2, 1)
# [N, IC, H*W]
theta_x = self.conv_v_left(x).view(batch, self.inter_planes, height * width)
# [N, 1, H*W]
# context = torch.einsum('nde,new->ndw', avg_x, theta_x)
context = torch.matmul(avg_x, theta_x)
# [N, 1, H*W]
context = self.softmax_left(context)
# [N, 1, H, W]
context = context.view(batch, 1, height, width)
# [N, 1, H, W]
mask_sp = self.sigmoid(context)
out = x * mask_sp
return out
def forward(self, x):
# [N, C, H, W]
context_channel = self.spatial_pool(x)
# [N, C, H, W]
context_spatial = self.channel_pool(x)
# [N, C, H, W]
out = context_spatial + context_channel
return out
class PSA_s(nn.Module):
def __init__(self, inplanes, planes, kernel_size=1, stride=1):
super(PSA_s, self).__init__()
self.inplanes = inplanes
self.inter_planes = planes // 2
self.planes = planes
self.kernel_size = kernel_size
self.stride = stride
self.padding = (kernel_size - 1) // 2
ratio = 4
self.conv_q_right = nn.Conv2d(self.inplanes, 1, kernel_size=1, stride=stride, padding=0, bias=False)
self.conv_v_right = nn.Conv2d(self.inplanes, self.inter_planes, kernel_size=1, stride=stride, padding=0,
bias=False)
# self.conv_up = nn.Conv2d(self.inter_planes, self.planes, kernel_size=1, stride=1, padding=0, bias=False)
self.conv_up = nn.Sequential(
nn.Conv2d(self.inter_planes, self.inter_planes // ratio, kernel_size=1),
nn.LayerNorm([self.inter_planes // ratio, 1, 1]),
nn.ReLU(inplace=True),
nn.Conv2d(self.inter_planes // ratio, self.planes, kernel_size=1)
)
self.softmax_right = nn.Softmax(dim=2)
self.sigmoid = nn.Sigmoid()
self.conv_q_left = nn.Conv2d(self.inplanes, self.inter_planes, kernel_size=1, stride=stride, padding=0,
bias=False) # g
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_v_left = nn.Conv2d(self.inplanes, self.inter_planes, kernel_size=1, stride=stride, padding=0,
bias=False) # theta
self.softmax_left = nn.Softmax(dim=2)
self.reset_parameters()
def reset_parameters(self):
kaiming_init(self.conv_q_right, mode='fan_in')
kaiming_init(self.conv_v_right, mode='fan_in')
kaiming_init(self.conv_q_left, mode='fan_in')
kaiming_init(self.conv_v_left, mode='fan_in')
self.conv_q_right.inited = True
self.conv_v_right.inited = True
self.conv_q_left.inited = True
self.conv_v_left.inited = True
def spatial_pool(self, x):
input_x = self.conv_v_right(x)
batch, channel, height, width = input_x.size()
# [N, IC, H*W]
input_x = input_x.view(batch, channel, height * width)
# [N, 1, H, W]
context_mask = self.conv_q_right(x)
# [N, 1, H*W]
context_mask = context_mask.view(batch, 1, height * width)
# [N, 1, H*W]
context_mask = self.softmax_right(context_mask)
# [N, IC, 1]
# context = torch.einsum('ndw,new->nde', input_x, context_mask)
context = torch.matmul(input_x, context_mask.transpose(1, 2))
# [N, IC, 1, 1]
context = context.unsqueeze(-1)
# [N, OC, 1, 1]
context = self.conv_up(context)
# [N, OC, 1, 1]
mask_ch = self.sigmoid(context)
out = x * mask_ch
return out
def channel_pool(self, x):
# [N, IC, H, W]
g_x = self.conv_q_left(x)
batch, channel, height, width = g_x.size()
# [N, IC, 1, 1]
avg_x = self.avg_pool(g_x)
batch, channel, avg_x_h, avg_x_w = avg_x.size()
# [N, 1, IC]
avg_x = avg_x.view(batch, channel, avg_x_h * avg_x_w).permute(0, 2, 1)
# [N, IC, H*W]
theta_x = self.conv_v_left(x).view(batch, self.inter_planes, height * width)
# [N, IC, H*W]
theta_x = self.softmax_left(theta_x)
# [N, 1, H*W]
# context = torch.einsum('nde,new->ndw', avg_x, theta_x)
context = torch.matmul(avg_x, theta_x)
# [N, 1, H, W]
context = context.view(batch, 1, height, width)
# [N, 1, H, W]
mask_sp = self.sigmoid(context)
out = x * mask_sp
return out
def forward(self, x):
# [N, C, H, W]
out = self.spatial_pool(x)
# [N, C, H, W]
out = self.channel_pool(out)
# [N, C, H, W]
# out = context_spatial + context_channel
return out
五、CoT(Contextual Transformer block)
论文地址:Contextual Transformer Networks for Visual Recognition
如下图:
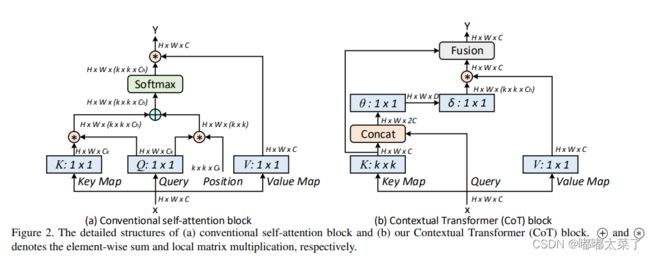
代码如下(代码地址):
import numpy as np
import torch
from torch import flatten, nn
from torch.nn import init
from torch.nn.modules.activation import ReLU
from torch.nn.modules.batchnorm import BatchNorm2d
from torch.nn import functional as F
class CoTAttention(nn.Module):
def __init__(self, dim=512,kernel_size=3):
super().__init__()
self.dim=dim
self.kernel_size=kernel_size
self.key_embed=nn.Sequential(
nn.Conv2d(dim,dim,kernel_size=kernel_size,padding=kernel_size//2,groups=4,bias=False),
nn.BatchNorm2d(dim),
nn.ReLU()
)
self.value_embed=nn.Sequential(
nn.Conv2d(dim,dim,1,bias=False),
nn.BatchNorm2d(dim)
)
factor=4
self.attention_embed=nn.Sequential(
nn.Conv2d(2*dim,2*dim//factor,1,bias=False),
nn.BatchNorm2d(2*dim//factor),
nn.ReLU(),
nn.Conv2d(2*dim//factor,kernel_size*kernel_size*dim,1)
)
def forward(self, x):
bs,c,h,w=x.shape
k1=self.key_embed(x) #bs,c,h,w
v=self.value_embed(x).view(bs,c,-1) #bs,c,h,w
y=torch.cat([k1,x],dim=1) #bs,2c,h,w
att=self.attention_embed(y) #bs,c*k*k,h,w
att=att.reshape(bs,c,self.kernel_size*self.kernel_size,h,w)
att=att.mean(2,keepdim=False).view(bs,c,-1) #bs,c,h*w
k2=F.softmax(att,dim=-1)*v
k2=k2.view(bs,c,h,w)
return k1+k2
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
cot = CoTAttention(dim=512,kernel_size=3)
output=cot(input)
print(output.shape)