Pandas进阶,20个提升数据分析技能的代码(上)
大家好,在当今数据驱动的世界中,数据分析是决策的基石,而Pandas是一种强大的工具,赋予数据分析师高效操作和分析数据的能力。
无论是专业的数据分析师想要提升自己的水平,还是新手对Pandas世界充满期待,这些代码片段将为你的学习之旅提供帮助。它们就像一个向导,帮助大家解锁这个多功能库的所有神奇功能,又像工具箱中的实用工具,专门用来解决日常数据挑战。
接下来跟随本文一起学习这些Pandas代码,改变处理数据分析的方式。
1. 加载数据集
import pandas as pd
# 加载数据集(例如,CSV文件)
# df = pd.read_csv('your_dataset.csv')
titanic_df = pd.read_csv('titanic.csv')
加载数据集是任何数据分析任务的第一步,将'titanic.csv'替换为你实际的文件路径或数据集的URL。
2. 显示数据集的基本信息
# 显示数据集的基本信息
titanic_df.info()

数据集信息
这提供了数据集的简明摘要,包括每列中非空值的数量和数据类型。
3. 查看数据集的前几行
# 显示数据集的前几行
titanic_df.head()
这可以帮助你快速检查数据集的结构和内容。

4. 描述性统计
# 生成描述性统计
titanic_df.describe(include = 'all')
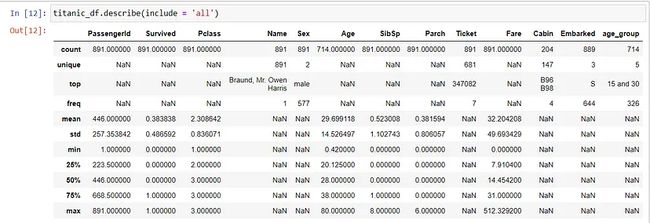
这提供了关键统计信息的概览,如数字列的均值、标准差和四分位数,写入"include = all"也可以显示定性变量(字符串/对象变量)的摘要。
5. 处理缺失值
处理缺失值非常重要,下面的示例展示了如何填充缺失值。
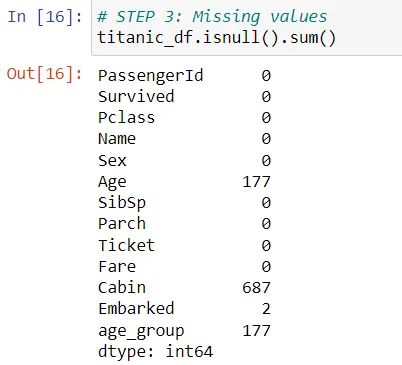
# 查找缺失值
titanic_df.isnull().sum()
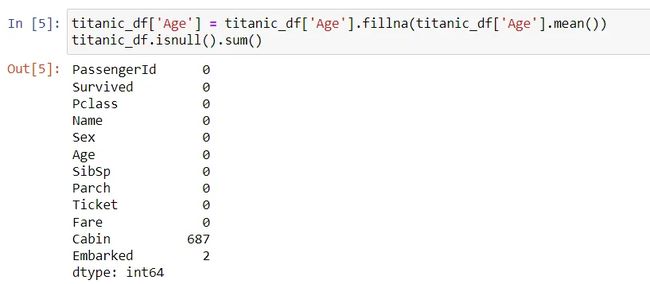
# 使用特定值填充缺失值
titanic_df['Age'] = titanic_df['Age'].fillna(titanic_df['Age'].mean())
6. 数据过滤
# 根据条件过滤数据
titanic_df.loc[titanic_df['Age'] > 30]
过滤功能可让帮助专注于数据的特定子集,例如此示例中的高收入个体。

7. 数据排序
排序可以根据选择的标准对数据进行组织,例如此示例中的按票价排序。
# 根据特定列对数据排序
titanic_df_sorted = titanic_df.sort_values(by='Fare')
titanic_df_sorted
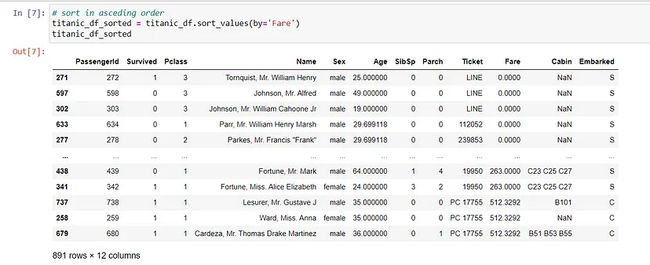
排序后的数据帧
8. 数据分组和聚合
分组和聚合数据对于总结信息至关重要,如计算按性别分组的平均收入,示例如下所示。
# 按分类变量对数据分组并计算平均值
titanic_df.groupby('Sex')['Survived'].mean()

9. 创建新列
# 基于现有列创建新列
titanic_df['total_relative'] = titanic_df['SibSp'] + titanic_df['Parch']
创建新列可以帮助从数据中获得更多的信息,例如此示例中的总亲属人数。

10. 使用Pandas进行数据可视化
Pandas与Matplotlib等可视化库无缝集成,可通过可视化快速而轻松地探索数据。
import matplotlib.pyplot as plt
# 绘制“Age”列的直方图
plt.hist(titanic_df['Fare'],bins = 40)
plt.show()

本文已经介绍了10个提升数据分析技能的代码,后续的代码将在Pandas 20个提升数据分析技能的代码(下)中展示。
Pandas进阶,20个提升数据分析技能的代码(下)-CSDN博客