利用R中的corrmorant包绘制精美的相关性热图
大家好,我是带我去滑雪!
相关性热图 (correlation heatmap) 是一种可视化工具,用于展示数据集中各个变量之间的相关性。它以矩阵的形式显示变量之间的相关系数,并通过色彩编码来表示相关性的强度。在相关性热图中,每个变量都对应图中的一行和一列。图中的每个单元格代表两个变量之间的相关性,通常使用颜色来表示相关性的强度。通常,相关性的计算采用的是Pearson相关系数,它度量线性关系的强度和方向。热图中的颜色编码比较常见的方式是使用一个渐变的色谱图。一般来说,较高的正相关性对应着较深或较亮的颜色,如红色或黄色;而较高的负相关性对应着较深或较亮的颜色,如蓝色或绿色;较低的相关性则对应着较浅或较暗的颜色。
相关性热图可以帮助我们快速观察和理解数据集中变量之间的关系。通过分析相关性热图,我们可以发现哪些变量之间存在强相关性、弱相关性或者无相关性。这对于特征选择、变量关系分析和模型构建等任务都非常有用。那么如何利用R绘制一些漂亮的相关性热图呢?本期介绍一个corrmorant包。
目录
1、安装corrmorant包并调用
2、导入数据
3、绘制相关性矩阵
4、绘制相关性热图
5、生成R绘图配色表
1、安装corrmorant包并调用
install.packages("remotes")
remotes::install_github("r-link/corrmorant",force = TRUE)
library(corrmorant)
library(ggplot2)
library(cols4all)
2、导入数据
使用R语言自带的鸢尾花数据集,该数据集有五个变量,分别是鸢尾花的萼片长度、萼片宽度、花瓣长度、花瓣宽度以及鸢尾花的种类,由于种类不是数值变量,故只用前四个变量。
data <- datasets::iris
head(data)输出结果:
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
3、绘制相关性矩阵
(1)第一种
在相关性矩阵中,对角线放置直方图,下三角放置散点图和拟合曲线,上三角放置相关系数。
picture <- ggcorrm(data,
corr_method = c('pearson')) + #分析方法选择,可选'pearson','kendall' or 'spearman'
lotri(geom_point()) + #下三角区域添加散点图
lotri(geom_smooth(method = 'lm')) + #下三角区域添加拟合曲线
utri_corrtext(corr_size = TRUE) + #上三角区域添加相关性系数
dia_names(y_pos = 0.15) + #对角线区域添加分类标签
dia_histogram(lower = 0.3, upper = 0.98, color = 'grey30') #对角线区域添加直方图picture
输出结果:
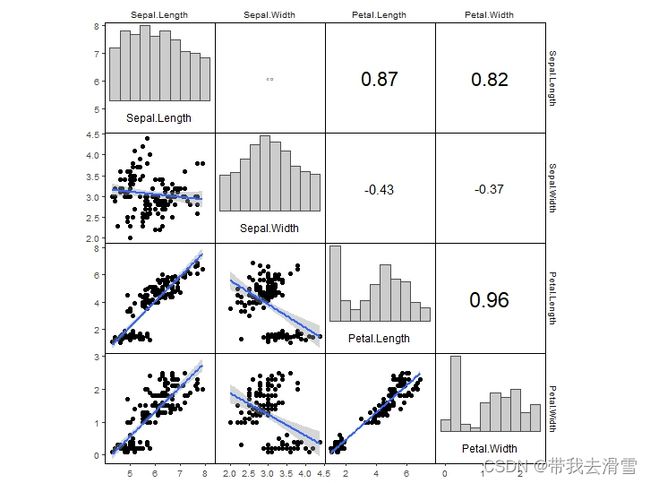
(2)第二种
对角线放置核密度曲线,下三角放置散点图和拟合曲线,上三角放置相关系数
pictures <- ggcorrm(data,
corr_method = c('pearson')) +
lotri(geom_point(alpha = 0.3)) +
lotri(geom_smooth(method = 'lm',
fill = 'slateblue',color = 'sienna2')) +
utri_corrtext(corr_size = FALSE) + #逻辑值为TRUE时,按照相关性强弱调整系数文本大小;FALSE则按相同大小显示
dia_names(y_pos = 0.15, size = 3.5) +
dia_density(lower = 0.3, upper = 0.98,
fill = 'turquoise2', color = 'cyan', alpha = 0.3) #对角线区域添加核密度曲线
pictures输出结果:

(3)第三种
绘制几种类别的数据在同一幅图中方便进行比较。
pictures1 <- ggcorrm(data,
mapping = aes(color = Species, fill = Species)) +
lotri(geom_point(alpha = 0.3)) +
lotri(geom_smooth(method = 'lm')) +
utri_corrtext(nrow = 2, #
squeeze = 0.5, #存在多标签时,用于调整宽/高比例
corr_size = F) +
dia_names(y_pos = 0.15, size = 3.5) +
dia_density(lower = 0.3, upper = 0.98,
alpha = 0.6)
pictures1输出结果:

4、绘制相关性热图
数据使用往期利用python爬取的房价信息,变量信息如下表所示。
表1 变量表
| 属性 |
解释 |
类型 |
变量名 |
| WSSL |
房屋的卧室数量(个) |
连续值 |
x1 |
| KTSL |
房屋的客厅数量(个) |
连续值 |
x2 |
| MJ |
房屋面积(平方米) |
连续值 |
x3 |
| FWZXQK |
房屋装修情况 |
离散值,0=其他;1=毛坯;2=简装;3=精装 |
x4 |
| YWDT |
有无电梯 |
离散值,0=无电梯;1=有电梯 |
x5 |
| LCWZ |
房屋所在楼层位置 |
离散值,0=低楼层;1=中楼层;2=高楼层 |
x6 |
| FJYWDT |
房屋附近有无地铁 |
离散值,0=无地铁;1=有地铁 |
x7 |
| GZD |
关注度(人次) |
连续值 |
x8 |
| KFCS |
看房次数 |
连续值 |
x9 |
| TOTAL PRICE |
房屋总价(万元) |
连续值 |
y1 |
表2 经过数据预处理后的数据集
| 编号 |
x1 |
x2 |
x3 |
x4 |
x5 |
x6 |
x7 |
x8 |
x9 |
y1 |
| 1 |
2 |
2 |
78.6 |
0 |
1 |
2 |
1 |
58 |
14 |
210 |
| 2 |
4 |
2 |
98 |
0 |
1 |
0 |
1 |
2337 |
18 |
433 |
| 3 |
2 |
1 |
58.1 |
2 |
1 |
1 |
1 |
25 |
18 |
255 |
| 4 |
4 |
2 |
118 |
3 |
0 |
1 |
0 |
2106 |
6 |
195 |
| 5 |
3 |
1 |
97.7 |
2 |
0 |
2 |
0 |
1533 |
7 |
150 |
| 6 |
3 |
2 |
115.94 |
2 |
1 |
1 |
1 |
47 |
5 |
570 |
| 7 |
3 |
2 |
102.72 |
2 |
1 |
0 |
1 |
80 |
19 |
630 |
| 8 |
3 |
2 |
102.72 |
2 |
1 |
0 |
1 |
80 |
19 |
630 |
| 9 |
2 |
2 |
73.3 |
2 |
1 |
0 |
1 |
873 |
21 |
310 |
| 10 |
3 |
2 |
92 |
2 |
1 |
1 |
0 |
64 |
14 |
203 |
| ⋮ |
⋮ |
⋮ |
⋮ |
⋮ |
⋮ |
⋮ |
⋮ |
⋮ |
⋮ |
⋮ |
| 2981 |
2 |
1 |
80.3 |
2 |
1 |
1 |
1 |
8 |
0 |
375 |
| 2982 |
2 |
2 |
64.81 |
2 |
1 |
1 |
1 |
2 |
0 |
268 |
| 2983 |
2 |
1 |
57.26 |
0 |
0 |
0 |
1 |
0 |
0 |
235 |
| 2984 |
2 |
1 |
75.38 |
2 |
1 |
2 |
0 |
0 |
0 |
300 |
data=read.table("E:/工作/硕士/博客/博客38-/data.csv",header=TRUE,sep=",")
head(data)输出结果:
x1 x2 x3 x4 x5 x6 x7 x8 x9 y1
1 2 2 78.60 0 1 2 1 58 14 210
2 4 2 98.00 0 1 0 1 2337 18 433
3 2 1 58.10 2 1 1 1 25 18 255
4 4 2 118.00 3 0 1 0 2106 6 195
5 3 1 97.70 2 0 2 0 1533 7 150
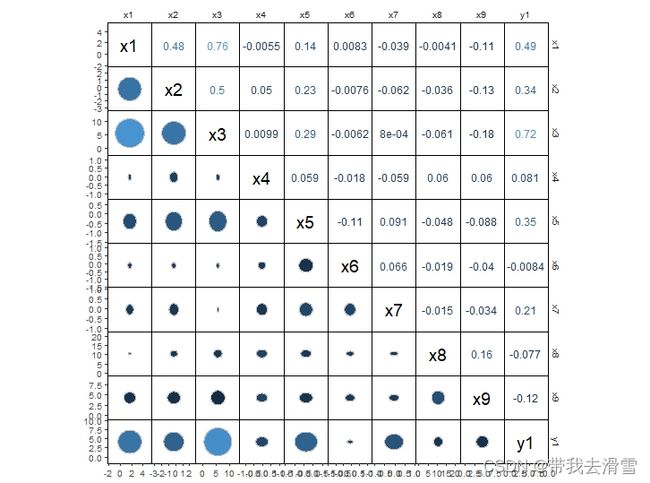
6 3 2 115.94 2 1 1 1 47 5 570pictures2 <- ggcorrm(data,
mapping = aes(color = .corr, fill = .corr),
corr_method = c('pearson'),
rescale = 'by_sd') +
lotri_heatcircle(alpha = 1, color = 'grey') + #下三角区域添加圆形热图
utri_corrtext(squeeze = 0.6, corr_size = F) +
dia_names(y_pos = 0.5, size = 5, color = 'black')
pictures2输出结果:
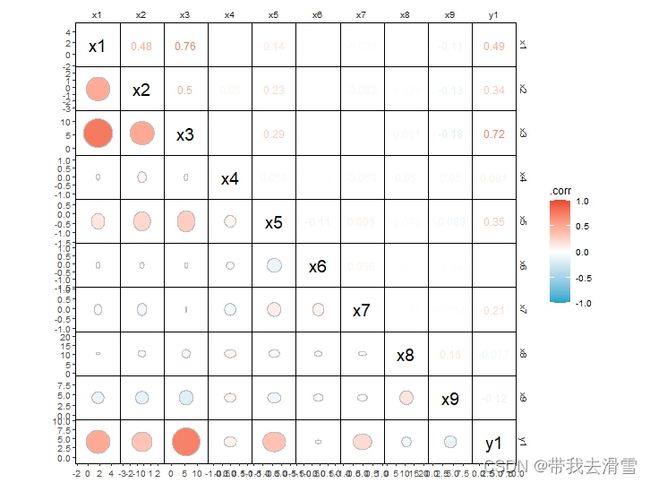
在pictures2的基础上进一步美化,选择渐变配色:
pictures3 <- pictures2 +
scale_colour_gradient2(aesthetics = c("fill", "color"),
limits = c(-1, 1),
low = '#06a7cd',
mid = "white",
high = '#e74a32')
pictures3输出结果:
5、生成R绘图配色表
在科研中,好的配色能够使绘制的图看着更加精美,下面生成R中所有的配色:
pdf('R语言颜色表.pdf',9,16)
cl=colors()
par(mar=c(0,0,0,0),bty="n")
plot(c(0, 98), c(0, 73), type = "n", xlab = "", ylab = "")
title(line = -2, main = 'R语言颜色表')
for(i in 0:8){
rect(i*11,73:1,i*11+10,72:0,col=cl[1:73+i*73])
text(i*11+5,73:1-0.5,labels = cl[1:73+i*73],cex = 0.6)
}
dev.off()
输出结果:

需要数据集的家人们可以去百度网盘(永久有效)获取:
链接:https://pan.baidu.com/s/16GeXC9_f6KI4lS2wQ-Z1VQ?pwd=2138
提取码:2138
更多优质内容持续发布中,请移步主页查看。
若有问题可邮箱联系:[email protected]
博主的WeChat:TCB1736732074
点赞+关注,下次不迷路!