读数学之美笔记
题记:早闻《数学之美》这本书相当的好,偶见室友在读,便也开始拜读。看的比较快,因为里面很多东西自己也了解一些。读完后觉得应该好好做个读书笔记,虽然吴军老师讲的不深入,但是这些对于未曾涉足具体内容的我来说也是一个很好的学习。感触最深的一句话:技术有两种,具体的做事方法是术,做事的原理和原则是道。只追求术的技术员是三流人员。
文字:信息的载体而非信息本身。任何一种语言都是一种编码方式,语言的语法规则是编解码的算法。自然语言处理可分为基于规则(分析语句、获取语义)的方法和基于统计模型的方法。
统计语言模型:一个句子是否合理,看它的可能性大小如何。
S表示一个有意义的句子,由一连串特定顺序排列的词w1,w2,...,wn组成。S在文本中出现的频率P(S)=P(w1,w2,...,wn)=P(w1)*P(w2|w1)...P(wn|w1,w2,...,wn-1)。
马尔可夫假设:假设任意一个词Wi出现的概率只同它前面的Wi-1有关。则P(S)=P(w1)*P(w2|w1)*P(w3|w2)...P(wn|wn-1)。
条件概率:
相对频度:
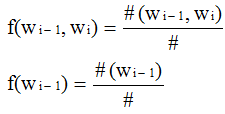
根据大数定理,只要统计量足够,相对频度就等于概率。也即P(wi-1,wi)=#(wi-1,wi)/#; P(wi-1)=#(wi-1)/#
因此:条件概率
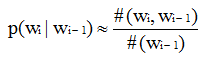
N-1阶马尔可夫假设:Wi的出现同其前面的N-1个词有关系。
解决零概率问题: 在统计中相信可靠的统计数据,对不可靠的统计数据打折扣的一种概率估计方法,同时将折扣出来的小部分概率给与未看见的事件。
出现r次的词有Nr个 计算频度时用dr替代r,而dr = (r+1)*Nr+1/Nr < r 下调出现频率很低的词的概率 这样d0 > 0,给未出现的词赋予了一个很小的非零值。
观测信号+状态序列:用观测信号:o1,o2,o3,...on来推测信号源发送的信息s1,s2,s3等于求概率P(s1,s2,s3,...|o1,o2,o3,...)达到最大值的那个信息串s1,s2,s3,...即s1,s2,s3,...=ArgMaxP(s1,s2,s2,...|o1,o2,o3,...)<-->P(o1,o2,o3,...|s1,s2,s3,...)*P(s1,s2,s3,...)
s1,s2,s3...也叫状态序列
马尔可夫链:任意时刻t,对应的状态st是随机的,一个随机过程s1,s2,s3,...,st,...中各个状态st的概率分布只与它的前一个状态st-1有关,即P(st|s1,s2,s3,...,st-1)=P(st|st-1)
符合这个假设的随机过程称为马尔可夫过程,也称为马尔可夫链。
根据观测量计算转移概率的方法:运行一段时间T,生成一个状态序列:s1,s2,s3,...sT,数出状态mi的出现次数#(mi),以及从mi转移到mj的次数#(mi,mj).
则P(mj|mi) = #(mi,mj)/#(mi)。
隐马尔可夫模型:马尔可夫链的一个扩展。
1、任意时刻t的状态st是不可见的,无法通过观察一个状态序列S1,S2,...ST来推测转移概率等参数。
2、独立输出假设:模型每个时刻t会输出一个符号Ot,Ot仅仅和St相关。

基于马尔可夫假设+独立输出假设:
P(s1,s2,s3,...,01,02,03,...) = 连乘P(st|st-1)*P(ot|st)
P(01,02,03,...|s1,s2,s3,...) = 连乘P(ot|st)
P(s1,s2,s3,...) = 连乘P(st|st-1)
隐马尔可夫模型的三个基本问题:
1、给定一个模型,如何计算某个特定的输出序列的概率。 Forward-Backward算法
2、给定一个模型和某个特定的输出序列,如何找到最可能产生这个输出的状态序列。维特比算法
3、给定足够多的观测数据,如何估计模型的参数。包括转移概率P(st|st-1) 和 生成概率P(ot|st)即每个状态st产生相应输出符号ot的概率P(ot|st)
针对3,当然可以用统计频度的方法计算,但是一是代价高、二是有可能无法计算。最好的方法是通过大量观测到的信号01,02,03,..推算出模型的转移概率和生成概率
鲍姆-韦尔奇算法:1、找一个可以产生输出序列O的模型参数M0 2、通过M0算出输出概率及路径概率。3、根据2计算得到的“标记数据”计算新的模型参数。类似于EM过程期望最大化。
信息的度量:一条信息的信息量和它的不确定性有直接的关系。对于随机变量X,信息的度量熵定义如下:
![]()
为什么与log有关:比如猜测32支球队谁是冠军,只需要最多猜测5次=log32
为什么与P(x)有关:不同的变量其出现的概率不同,比如32支球队中事先知道谁夺冠的概率大,概率小,则可以先猜测概率大的球队。这样猜测的次数将可能随之减少。故与样本出现概率有关。
信息的作用在于消除不确定性。而且信息是消除系统不确定性的唯一办法。
条件熵:
![]()
互信息:在了解一个Y的前提下,对消除另一个X不确定性所提供的信息量。
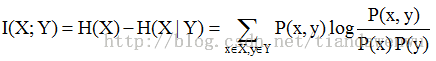
图论
BFS:Breadth-First Search 广度优先搜索
DFS:Depth-First Search 深度优先搜索
网络爬虫:将互联网看成一张大图,每个网页看成一个节点,每个网页的超链接看成连接网页的弧。用图的遍历算法,自动地访问每一网页并存储,这个就叫网络爬虫。
工程要点:1、用BFS还是DFS?a.应该在有限时间爬下最重要网页 b.分布式结构和网络通信的握手成本。用一个优先级队列存储已经发现当时尚未下载的网页。
搜索:自动下载网页、构建网页索引、衡量网页的质量Quality、确定网页和查询的相关性Relevance。
自动下载网页:构建网络爬虫:在有限时间内最多的爬下最重要的网页。是一个在相对复杂的下载优先级排序的方法。
构建网页索引:URL表即Hash表记录已经下载的网页,防止一个网页被多次下载。
维护:大到无法存储。 问题:访问、插入的通信问题。
解决:1、分而治之:明确每台下载服务器的分工。2、批量处理,减少通信的次数。
衡量网页的质量:PageRank网页排名算法:一个网页被链接的次数越多,那么认为其受到普遍的承认和信赖,那么排名就应该高。同时不同类别的网页其Voting的比重还应该区别对待,可信度高的网页其权重较大。Pagerank = P(X1) + P(X2) + P(X3) + ... + P(Xk)
怎么确定P(X1)、P(X2)...简单概述:1、每个网页初始化一个概率,每个网页排名相同 2、迭代计算网页的排名。迭代多次后会收敛到排名的真实值。
确定网页和查询的相关性:搜索关键词权重的科学度量TF-IDF:词频率—逆向文本频率
TF:Term Frequency单文本词频 (根据网页的长度,对关键字的次数进行归一化)关键字的次数/网页的总字数
总词频:TF = TF1 + TF2 + ... + TFn (当然要去掉 “是”、“和”等停止词)
IDF:Inverse Document Frequency逆文本频率指数。每个词预测主题的能力不同。所以对每个词还得加上预测的权重,预测能力强的权重较大。假定一个关键词w在Dw个网页中出现过,那么Dw越大,w的权重越小。IDF = log(D/Dw).D为全部网页数
TF-IDF = TF1*IDF1 + TF2*IDF2 + ... + TFn*IDFn
地图和本地搜索的最基本技术:有限状态机和动态规划
定位和导航:1、卫星定位 2、地址的识别 3、根据起点和终点,在地图上规划最短路线和最快路线。
2、地址的识别:使用有限状态机识别地址。a.通过有效的地址建立状态机。b.地址子串的匹配。基于概率的有限状态机能够解决模糊匹配的问题。
3、动态规划:图论中的动态规划算法。将寻找全程最短路线划分为寻找局部路线的问题。
新闻的分类:1、计算新闻文章的特征向量 2、特征向量匹配。
新闻的特征向量:新闻由词组成,词表达不同的语义。怎么度量每个实词的重要性。借用搜索中的词频-逆文本TF--IDF来描述词的重要程度。
建立一个实词的词汇表,计算文章中每个词的TF--IDF,按照对应实词在词汇表的位置依次排列,得到一个向量。向量中每个维度的大小代表每个词对新闻 主题的贡献。当然实词在文章的位置在分类时的重要性也不同,开始、结尾的词也应该加大权重。
特征向量匹配:向量的距离度量:计算两个向量的夹角。
怎么获取新闻类别的特征向量:1、手工建,麻烦。 2、自动生成。
2、自动生成:一种自底向上不断合并的办法。
a.计算所有新闻两两的余旋相似性,将相似性大于一定阈值的新闻合成一个小类。这样N篇新闻合并成N1个小类
b.计算小类的特征向量,再计算小类之间的余旋相关性,合并大一点的小类。假设为N2个类别
c.重复步骤2
网址的信息指纹:128位二进制:16字节的整数空间。存放在Hash表中。
字符串:1、费内存 2、费查找时间(网址长度不固定,以字符串的形式查找,效率很低)3、hash存储效率低。
信息指纹:1、节省内存 2、当产生随机数的算法足够好,不同字符串将对应不同的信息指纹。
计算方法:1、将字符串看成一个特殊的、长度很长的整数。2、伪随机数产生器算法(PRNG),通过它将任意长的整数转换成特定长度的伪随机数。
常用算法有:128位的MD5 160位的SHA-1
信息指纹用途:判断集合相同。
1、对两个集合进行排序,然后进行顺序比较。时间为O(NlogN)
2、将集合1存入hash,然后对集合2与hash表中的元素进行对比。O(N),但是有附加的O(N)空间。
3、计算两个集合的指纹,然后直接比较。不同元素的指纹相同的概率非常非常小。
相似哈希:一种特殊的信息指纹。下载网页时排查重复网页的列子。
如果两个网页的相似哈希相差越小,这两个网页的相似性越高。找到每个网页的相似哈希后,可以找到重复的网页,就不必重复建索引浪费计算机资源。
最大熵原理:保留全部的不确定性,降低风险。
对随机事件的概率进行预测时,应当满足全部已知的条件,不要对未知的情况做任何假设。此时概率分布最均匀,预测的风险最小。此时概率分布的信息熵最大。
拼音输入法的数学原理:
汉字的编码:1、对拼音的编码 2、消除歧义性的编码
香农第一定理:对于一个信息,任何编码的长度都不小于它的信息熵。
汉字的平均编码长度:假设每一个汉字出现的相对频率是p1,p2,p3,...,p6700 编码长度为L1,L2,L3,...,L6700
平均编码长度为:p1*L1 + p2*L2 + ... + p6700*L6700
汉字的信息熵:H = -p1*logp1 - p2*logp2 - p3*logp3 - ... - p6700*log6700 近似为10比特
每个字母代表的信息log26 = 4.7比特 故每个汉字平均需要敲2.1次键
以词为单位统计信息熵,并考虑上下文的相关性,那么每个汉字的平均信息熵将会减少。
拼音转汉字的算法:类似于本地搜索中的动态规划算法。
y1,y2,y2,...,yN:输入的拼音串 w11,w12,w13:第一个音y1的候选汉字 用w1代表。
从第一个字到最后一个字可以组成很多句子,每个句子和图中的一条路径对应。
w1,w2,...,wN = ArgMaxP(w1,w2,w3,...,wN|y1,y2,...,yN) 对应上图,等于找从起点到终点的一条最短路径。
插入图。。。UNDO
判断一个元素是否在一个集合当中。
HashTable:1、快速准确 2、耗费存储内存
如存放Email地址:1、计算Email的8字节信息指纹 2、将信息指纹存入HashTable 3、HashTable的存储效率只有50%,因此一个Email地址需要16个字节。
布隆过滤器:一个很长的二进制向量+一系列随机映射函数。
原理:假定存储一亿个电子邮件地址。
1、先建立一个16亿二进制:两翼字节的向量,对16亿个二进制位全部清零。
2、对每个电子邮件地址X,用8个随机数产生器(F1,F2,....F8)产生8个信息指纹(f1,f2,...,f8) 再用一个随机数产生器G将8个信息指纹映射到1--16亿个电子邮件地址的8个自然数g1,g2,...,g8,把这8个位置的二进制全部设置为1。
3、对于一个可疑的电子邮件Y,判断是否在黑名单中。用8个随机数产生器产生8个信息指纹,再对应到布隆过滤器的8个二进制位。如果是可疑地址,则8位全为1.
插入图。。。UDDO
贝叶斯网络:一个由有向图构成的网络,每个状态只和与它直接相连的状态有关,而和它间接相连的状态没有直接关系。
相关性:一个量化的可信度,用一个概率描述。 贝叶斯网络的弧:附加的权重。
每个节点的概率都可以用贝叶斯公式计算。
插入图。。。UNDO
维特比算法:维特比是高通公司的创始人之一。维特比算法是一个特殊但应用广泛的动态规划算法(动态规划算法可以解决一个图中的最短路径问题):解决篱笆网络的有向图的最短路径问题提出的。我们需要找到从第一个状态到最后一个状态的一条最短路径。如果遍历每条路径来找最短路径,那么序列状态数的增长将成指数爆炸式。