(译)判别训练的多尺度可变形部件模型 A Discriminatively Trained, Multiscale, Deformable Part Model
原文:http://blog.csdn.net/masibuaa/article/details/17533419
判别训练的多尺度可变形部件模型
Pedro.Felzenszwalb,David.McAllester,Deva.Ramanan
摘要
本文介绍了一种用于目标检测的判别训练的多尺度可变形部件模型。我们的系统在平均精度上达到了2006 PASCAL 人体检测竞赛中最优结果的两倍,同样比2007 PASCAL目标检测比赛中20个类别中的10个的最优结果都要好。此系统非常依赖于可变形部件模型。随着可变形部件模型逐渐流行,它的价值并没有在类似PASCAL的较难的数据集上被展示。我们的系统还依赖于判别训练的新方法。我们将一种挖掘难例(Hard Negative Example)的间隔敏感方法与隐藏变量SVM(Latent variable SVM)结合在一起。隐藏SVM类似于隐藏条件随机场(Hidden CRF)问题,最终是一个非凸规划的训练问题。隐藏SVM是半凸规划(semi-convex)问题,但是一旦将隐藏信息指明给正样本,则训练问题变为凸规划问题。我们相信我们的训练方法最终可以利用更多的隐藏信息,例如层次(grammar)模型以及包含隐式三维姿态的模型。
1 引言
我们所研究的是在静态图片中的某类目标(例如人、车)的检测和定位问题。我们提出了一种多尺度可变形部件模型来解决此问题,此模型的判别训练过程只需要正样本的标注矩形框(意思是说只需要整个目标的标注信息,不需要各个部件的标注信息)。基于此模型实现了一个高效而精确的检测系统,可以在两秒内处理一张图片并达到明显比之前方法更高的检测精度。
我们的系统在平均精度上可以达到2006 PASCAL人体检测挑战赛最佳结果[5](Dalal的HOG方法)检测精度的两倍,同样比2007 PASCAL目标检测中20个类别中的10个的最优结果都要好。图1显示了我们的人体模型的检测结果。

图1 人体模型的检测结果。此模型是由一个粗糙的全局模版、几个高分辨率的部件模版和每个部件之间的空间模型构成的。
目标可被可变形部件表示的概念提供了表示目标类别的框架[1-3,6,10,12,13,15,16,22]。尽管这些模型在概念上很吸引人,但是很难在实际中实现。在一些难度大的数据集上,可变形模型经常被一些从理论上看很弱的模型——例如刚体(固定rigid)模版[5]或特征袋[23]——在实践中所超越。我们的主要目标就是要解决这一问题。
可变形部件模型包括一个粗糙的包含整个目标的全局模版,以及若干个高分辨率的部件模版,所谓的模版就是梯度方向直方图HOG[5]特征向量。就像[14,19,21]中所述,模型是判别训练的。然而,我们的系统是半监督的,使用最大间隔框架进行训练,并且不依赖于特征检测。我们还介绍了一种简单而有效的从非完美标注的数据集中学习部件模型的方法。和论文[4]中的需要大量计算的方法不同,我们的方法在单CPU上可以在3小时内学习一个模型。
此论文的另一个贡献是提出了一种新的判别训练方法,我们为处理隐藏变量例如部件位置扩展了SVM,并且提出了一种挖掘难例(HardNegative Examples)的新方法。我们认为处理部分标注的数据是机器学习在计算机视觉领域中的一个重要问题。例如,PASCAL的数据集只给出了每个目标的正样本的矩形框。我们将目标的每个部件的位置看做隐藏变量,同时也将目标的位置看做是隐藏变量,只需要我们的分类器选出一个与已标注的矩形框有大量重叠的窗口。
隐藏SVM就像条件随机场CRF[19]一样,最终是一个非凸训练问题。然而,隐藏SVM是半凸规划(semi-convex)问题,但是一旦将隐藏信息指明给正样本,则训练问题变为凸规划问题,可使用一般的坐标下降算法求解。
系统综述
我们的系统使用窗口扫描方法。目标模型包括一个全局的根滤波器和几个部件模型。每个部件模型包括一个空间模型和一个部件滤波器,空间模型定义了一系列此部件相对于检测窗口的空间位置,以及每个相对位置的变形花费。
检测窗口的得分是根滤波器的分数加上各个部件的分数的总和,每个部件的分数是此部件的各个空间位置得分的最大值,每个部件的空间位置得分是部件在该子窗口上滤波器的得分减去变形花费。这与经典的基于部件的模型很相似[10][13]。根滤波器和部件滤波器的得分都是通过计算窗口内的梯度方向直方图和一些权重的点积来获得的。根滤波器就等价于Dalal-Triggs的HOG模型[5]。部件滤波器的特征是在两倍根滤波器分辨率的空间上计算的。我们的模型是在混合尺度中定义的,检测目标时通过搜索图像金字塔来实现。
训练使用一系列含标注的图像,每个目标的实例都有一个矩形框。我们将检测问题转换为二分类问题。对于每个样本x,通过下式计算x的得分:

β是模型的参数向量,z是隐藏变量(例如部件的位置)。我们定义了一种扩展的SVM,叫做隐藏变量SVM(LSVM,Latent variable SVM)。LSVM的一个重要特性是,当将隐藏信息指明给正样本时,则训练问题变为凸优化问题,从而可以使用坐标下降算法求解。
在实际中,我们对三元组(<x1, z1,y1>, ... , <xn, zn, yn>)迭代地应用经典SVM方法,其中zi是上一次迭代学习到的模型中最适合xi的隐藏标签。最初的根滤波器由PASCAL数据集的矩形框所标定的目标产生,各个部件根据根滤波器进行初始化。
2 模型
我们模型的潜在基础是论文[5]中的方向梯度直方图(HOG)。我们在两个不同的尺度上提取HOG特征:全局固定模版使用粗糙特征,可以覆盖整个检测窗口;局部部件模版使用精细尺度特征,可以相对于检测窗口移动。部件相对位置的空间模型等价于星型图或论文[3]中的3-fan图,而粗糙全局模版作为位置参考。
2.1HOG描述子
我们根据论文[5]中的描述来构建HOG特征。图像首先被划分为不重叠的8*8像素区域,或者叫做细胞单元(cell)。对于每个细胞单元统计一个一维的梯度方向直方图,这些直方图可以表示局部形状特征,并且能适应小的形变。
每个像素的梯度方向被离散到9个方向bin之一,而每个像素的梯度幅值为方向进行投票。对于彩色图,分别计算每个通道的梯度,选取梯度幅值最大的那个通道的梯度作为像素点的梯度。然后,将2*2个细胞单元组成块(block),对块进行归一化,形成一个9*4大小的向量。
通过计算标准图像金字塔中每层图像的HOG特征,我们定义了一个HOG特征金字塔,HOG金字塔中每一层的的最小单位是细胞单元,见图2。金字塔顶层的特征可以在大范围内捕获粗糙的梯度直方图,金字塔底层的特征捕获小范围的精细尺度梯度直方图。

图2,HOG特征金字塔以及人的模型在该金字塔内的示例。蓝色矩形表示根滤波器的作用区域,每个黄色矩形表示对应的部件滤波器的作用区域。部件滤波器被放置在两倍空间分辨率于根滤波器位置的层。
2.2滤波器(模版)
滤波器就是指定HOG金字塔子窗口权重的矩形模版,一个w * h大小的滤波器F是一个含w * h * 9 * 4个权重的向量。所谓滤波器的得分就是此权重向量与HOG金字塔中w * h大小子窗口的HOG特征向量的点积(Dot Product)。
论文[5]中的系统使用单个滤波器来定义目标模型,通过对HOG金字塔中每个w * h大小子窗口的得分进行阈值化来检测特定类别的目标。
假设H是HOG金字塔,p = (x, y, l) 表示金字塔第l层 (x, y) 位置的一个细胞单元。
φ(H, p, w, h)是将金字塔H中以p为左上角点的w * h大小子窗口的HOG特征串接起来得到的向量。所以,滤波器F在此检测窗口上的得分为:F·φ(H, p, w, h)。此后,在不引起歧义的情况下,我们使用φ(H, p)代表φ(H, p, w, h)。
2.3可变部件模型
我们的可变形部件模型包括一个覆盖整个目标的粗糙的根滤波器(root filter),和若干个表示目标各个部件的高分辨率的部件滤波器(part filter)。图2表明此模型在HOG金字塔中的位置。根滤波器的位置定义了检测窗口(即滤波器中的细胞单元所包含的所有像素)。部件滤波器位于金字塔的下几层,使得部件滤波器所在层的HOG细胞单元尺寸是根滤波器所在层的细胞单元尺寸的一半。
我们发现使用高分辨率的特征来定义部件滤波器对于获得高识别率是必要的,这样部件滤波器相比于根滤波器就可以表示更细腻的边缘信息。例如在建立人脸模型时,根滤波器用来捕获脸的边界这些粗糙信息,部件滤波器可以捕获眼镜、鼻子、嘴这些细节信息。
含n个部件的模型可以通过根滤波器F0和一系列部件模型(P1, ..., Pn)来定义,其中
Pi =(Fi, vi, si, ai, bi)。Fi是第i个部件的滤波器;vi和si都是二维向量,都以细胞单元为单位,vi指明第i个部件位置的矩形中心点相对于根位置的坐标,si是此矩形的大小;ai和bi也都是二维向量,指明一个二次函数的参数,此二次函数用来对第i个部件的每个可能位置进行评分。图1展示了一个人体模型。
模型在HOG金字塔中的位置可以用z =(p0, ..... , pn)来表示,当i=0时,pi= (xi, yi, li )表示根滤波器的位置;i>0时,pi= (xi, yi, li )表示第i个部件滤波器的位置。我们假设每个部件所在层的HOG细胞单元的尺寸是根所在的层的细胞单元尺寸的一半。空间位置的得分等于每个部件滤波器的得分(从数据来看)加上(?加上减去都一样,通过正负号控制就行)每个部件的位置相对于根的得分(从空间来看)。
即:
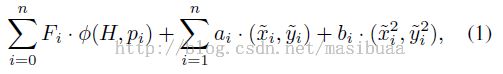
注意:上式是原版论文中的公式,如果表示为减去变形花费就是:

其中
![]()
注意:上式是原版论文中的,可能是写错了,否则解释不通,正确的是:
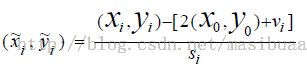
(x0,y0)是根滤波器在其所在层的坐标,为了统一到部件滤波器所在层需乘以2。
vi是部件i相对于根的坐标偏移,所以2(x0, y0)+vi表示未发生形变时部件i的坐标。
所以 ![]() 表示部件i的变形程度,
表示部件i的变形程度, ![]() 和
和![]() 在-1到1之间。
在-1到1之间。
模型在HOG金字塔中的位置有很多可能(指数级),我们使用动态规划和距离变换方法[9][10]来计算模型中各个部件的最佳位置,使其成为根位置的函数。这会花费O(nk)的时间,n是模型中的部件个数,k是HOG金字塔中细胞单元的个数。在进行目标检测时,根据各个部件的最可能位置来对根位置评分,然后对此分数进行阈值化。
空间位置z的得分可以表示为模型参数向量β与向量ψ(H, z)的点积,即β·ψ(H, z),其中:

ψ(H, z)可以简单的理解为HOG金字塔H中模版z对应的特征向量。
我们使用此表达式来学习模型参数,它将可变形部件模型和线性分类器联系了起来。
这里定义的空间模型的一个有意思的地方是我们允许参数(ai, bi)是负的,如此以来,相对于此前的quadratic”spring”?花费,此模型变得更具通用性。
3 学习
PASCAL训练数据集包含大量用矩形框标注目标实例的图片。我们把利用这些数据学习可变形部件模型的问题简化为二分类问题。设D = (<x1, y1>, ..., <xn, yn>)是标注好的一系列样本,其中yi∈{-1, 1}是样本类别,H(xi)是HOG金字塔,Z(xi)是根滤波器和部件滤波器的合法位置。我们从训练集的矩形框中截取正样本,对于这些样本定义Z(xi),其中根滤波器的位置必须至少和矩形框的位置重叠50%。负样本来自不包含目标的图片,图中每个根滤波器的位置产生一个负样本。
注意在正样本中,我们将根滤波器和部件滤波器的位置看做隐藏变量。我们发现在训练时允许根滤波器的位置存在不确定性可以很大程度上提高系统的表现(见第四部分)。
3.1隐藏变量SVM
隐藏变量SVM的定义如下。对每个输入样本x用以下函数进行评分:
![]()
其中β是模型参数向量,z是一系列隐藏变量。对于可变形模型,定义Φ(x, z) = ψ(H(x), z),所以β·Φ(x, z)是根据位置z放置模型的得分。
类比经典SVM,根据标注的样本集D =(<x1, y1>, ..., <xn, yn>),通过最优化下面的目标函数来训练模型参数β,β*(D) 表示样本集D上的最优β值(或者说是根据样本集D训练得到的模型参数β):

如果将隐藏变量域Z(xi)指明为确定的值, ![]() 变为确定的数β,由此就变为线性SVM问题,这是隐藏变量SVM的一个特例。隐藏变量SVM是通用的基于能量的模型(energy-based models)[18]的一个实例。
变为确定的数β,由此就变为线性SVM问题,这是隐藏变量SVM的一个特例。隐藏变量SVM是通用的基于能量的模型(energy-based models)[18]的一个实例。
3.2半凸
公式(2)中定义的 ![]() 是β的线性函数的最大值,因此
是β的线性函数的最大值,因此![]() 是β的凸函数。这意味着,当yi是-1时(即对于负样本),铰链损失(hinge loss)
是β的凸函数。这意味着,当yi是-1时(即对于负样本),铰链损失(hinge loss)![]() 是β的凸函数。也就是说,对于负样本来说损失函数是β的凸函数,我们将损失函数的这一特性叫做半凸。
是β的凸函数。也就是说,对于负样本来说损失函数是β的凸函数,我们将损失函数的这一特性叫做半凸。
如果LSVM中正样本的隐藏变量域Z(xi)指明为确定值,则每个正样本的损失函数变为凸函数,加上损失函数的半凸性质,所以公式(3)是β的凸函数。
如果正样本的隐藏变量不确定,可以使用坐标下降算法计算公式(3)的局部最优:
1) 保持β值不变,找到正样本的隐藏变量zi的最优值:
![]()
2) 保持正样本的zi值不变,通过解上面定义的凸规划问题(标准SVM)最优化β值。
可以看出以上两个步骤或者优化目标函数(3)的值或者维持目标函数值不变。如果两个步骤都使目标函数值保持不变的话(达到收敛),就得到了目标函数(3)的较强的局部最优值。步骤1在指数空间内搜索正样本的隐藏变量,同时步骤2搜索权重向量和指数空间内负样本的隐藏变量。
3.3难例数据挖掘
在目标检测中,用于训练的大多数样本都是负样本,因此不可能同时考虑所有的负样本。所以,经常需要构建包含正样本和负样本难例(难样本,Hard Negative,Hard Example,Hard Instance )的训练集,其中的负样本难例是从大范围的可能负样本中挖掘出来的。
这里我们介绍一种适用于SVM和LSVM的对样本进行数据挖掘的方法。此方法只用难例来迭代解决子问题。此方法的创新之处是能够在理论上保证最终会得到完全训练集之上的训练问题的准确解。此方法需要用到难例的间隔敏感特性。
这里讨论的结果既适用于经典SVM问题,又适用于LSVM的坐标下降算法中的步骤2所定义的问题。由于空间有限,这里忽略证明过程。此方法与论文[17]中的工作集方法有关。
模型参数β在样本集D上的难例表示为:
![]()
即M(β,D)是分错类的训练样本或靠近由β定义的分类器边缘的样本。接下来我们要说明样本集D上的最优β值β*(D)只依赖于难例。
定理1 设C是样本集D的一个子集,如果 ![]() 则
则![]()
这意味着,理论上我们可以使用一个更小的样本集合进行训练,此样本集是根据最优模型β*(D)定义的。
给定一个固定的β,可以用M(β,D)来近似M(β*(D), D)。如此一来,就可以使用一种迭代算法,不断地根据上次迭代产生的模型参数β定义的难例来计算模型参数β。
定理2 ![]()
设C是最初的样本缓冲区(cache)。实际上可以将正样本和随机负样本放在一起。考虑如下迭代算法:
(1) 设β:= β*(C)
(2) 收缩C,使得C := M(β,C)
(3) 通过不断向C中增加M(β, D)中的样本来增大C,直到达到内存限制L。
定理3 如果每次经上述算法步骤2的迭代后,有|C|<L,则算法在有限时间内会收敛到![]() 。
。
3.4实现细节
我们讨论的很多思想在系统中只得到了近似实现。事实上,在训练LSVM时,是对三元组<x1, z1,y1>, ... , <xn, zn, yn>迭代应用经典SVM算法。其中,zi是上一次迭代中对xi得分最高的隐藏标签。每个三元组对应一个用来训练线性分类器的样本<Φ(xi, zi), yi>。这使得我们可以使用一个经过优化的SVM工具包SVMLight[17]。在单个CPU上,每个PASCAL数据集中的目标类别大概需要3到4个小时的训练时间,这其中包括部件的初始化时间。
根滤波器初始化:对于每个目标类别,根据训练数据集中目标矩形框大小的统计值,自动选择根滤波器的尺寸。使用不含隐藏变量的SVM训练得到一个初始的根滤波器F0。正样本从PASCAL数据集中含无遮挡的目标的图片中截取得到,这些截取的正样本非均匀地缩放到根滤波器大小的尺寸和长宽比。负样本从不包含目标的图片中随机截取。
根滤波器更新:给定上一步训练得到的初始根滤波器,对于训练集中的每个矩形框,在根滤波器和矩形框显著重叠(重叠50%以上)的条件下,找到滤波器得分最高的一个位置。此过程是在原始的、未缩放的图片上进行的。用得到的新的正样本集和初始的随机负样本集重新训练F0,如此迭代两次。
部件滤波器初始化:我们使用一种简单的启发式方法根据上面训练的根滤波器初始化六个部件滤波器。首先选择面积a,使得6a等于根滤波器面积的80%。使用贪心方法从根滤波器中选出面积为a的具有最大正能量(most positive energy,正能量是该区域中所有细胞单元的正权重平方和)的矩形区域,将此区域的所有权重清零然后继续选择,直到选出六个矩形区域。部件滤波器的初值是对应矩形区域内根滤波器的权值,但需要进行插值来适应更高的空间分辨率。每个位置的初始变形花费是位移的平方,参数是ai = (0,0),bi = -(1,1)。
模型更新:通过构建新的训练数据三元组来更新模型。对于训练数据集中每个正样本矩形框,在保证至少50%重叠的情况下用现有检测器在所有可能位置和尺度进行检测,在其中选出具有最高得分的位置作为此矩形框对应的正样本(如图3),放入样本缓冲区中。在不包含目标物体的图片中选择检测得分高的位置作为负样本,不断向样本缓冲区中添加负样本直到文件最大限制。利用SVMLight在缓冲区中的正负样本上训练新的模型,所有样本都有部件位置标注。使用上一节中描述的样本缓冲区策略迭代更新模型10次。在每次迭代过程中,将上一次样本缓冲区的难例保存下来,并不断向缓冲区中添加新的难例。最后一次迭代完成后,缓冲区中保留下来所有的样本难例M(β,D),并且所有模型参数也已通过训练获得。

图3,左边的图显示了人体正样本的所有隐藏变量的最优位置。虚线矩形框是PASCAL训练集提供的目标的标注矩形框。大的实线矩形框是检测窗口的位置,小的实线矩形框是各个部件的位置。右边的图显示的是一个难例(Hard Negative Example)。
4 结果
我们在PASCAL VOC 2006和2007挑战赛上测试了我们的系统。论文[7][8]中有详细的结果描述,需要强调的是,PASCAL VOC被公认为是非常难的目标检测实验数据集。数据集中包含几千个真实世界场景的图片,在其中标注了几个类别的ground-truth矩形框,只有当检测结果的矩形框和ground-truth矩形框重叠超过50%时才被认为是检测正确。通过一条精度-召回率曲线(precision-recall curve)的平均精度(AP Average Precision)对系统进行评价(精度:检测正确的目标占检测的总目标的比例。召回率:检测到的目标占ground-truth中标注的所有目标的比例)。
近来在行人检测领域趋向于用检测率-每窗口误报率(False Positives Per Window)进行评价,通过剪裁后的正样本和不包含目标的图片进行测量。这种评价方法依赖于扫描窗口的分辨率,忽略了非极大值抑制的影响,所以不适合比较不同的系统。我们认为PASCAL评价标准能够更加可靠地对系统性能进行评价。
PASCAL VOC 2007挑战赛有20个目标类别。我们用系统的初始版本参加了官方的比赛,在6个类别上获得了最高得分。我们当前的系统可以在10个类别上获得最高得分,并在6个类别中获得第二高得分。表1显示了PASCAL 2007的比赛结果。

表1,PASCAL VOC2007比赛结果。表中显示了我们的系统和参加比赛的其他系统的平均精度[7]。空白格表示该方法在对应的类别中没有进行测试。每个类别的最高得分做了加粗处理。我们的当前系统可以在20个类别中的10个中得到最高分,我们系统的初始版本可以在官方竞赛的6个类别中得到最高分。
我们的系统在刚体目标(例如车和沙发)和容易发生形变的目标(例如人和马)上表现较好。同时还注意到,我们的系统在大量或少量训练样本的情况下都能成功。在人体类别中有大约4700个正训练样本,但在沙发类别中只有250个正训练样本。图4是我们的系统学习到的一些模型。图5展示了一些检测结果。

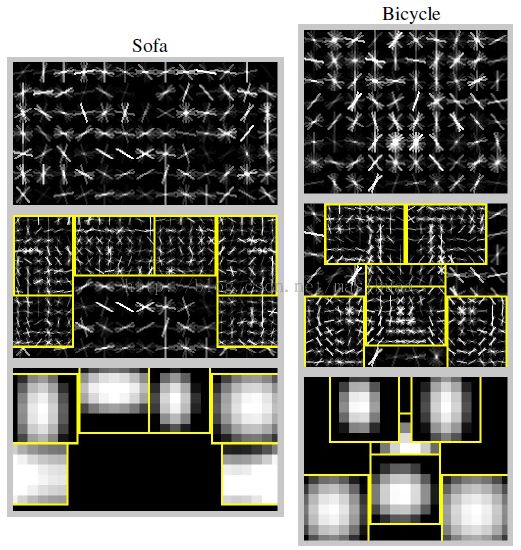
图4,从PSACAL VOC 2007数据集中学习到的一些模型。图中展示了根滤波器和部件滤波器中HOG细胞单元内所有方向的总能量,部件滤波器放置在所有允许位置的中心。图中还显示了每个部件的空间模型,亮的区域代表“代价低”的位置(即相对正确的部件位置),黑的区域代表“代价高”的位置(即相对错误的部件位置)。

图5,PASCAL 2007 数据集上的一些检测结果。每行是同一个类别的模型的检测结果(人,瓶子,小桥车,沙发,自行车,马)。每行的前三列是正确的检测结果,最后一列是误报。图中表明我们的系统可以检测各种尺度(见小轿车的检测结果)和各种姿势(见马的检测结果)的目标。同样可以检测部分遮挡的目标,例如灌木丛后的人。就连误报也经常是相当合理的,例如使用小轿车模型检测出公共汽车,使用自行车模型检测出自行车标志,使用马模型检测出狗。通常情况下,每个部件滤波器都代表一个定位准确的有意义的目标部分,例如人体模型的头部。
我们在花费更长时间建立的2006人体数据集上评价系统的不同部分。PASCAL 2006人体检测的最高AP得分是.16,是通过使用HOG特征的固定模版获得的[5]。之前得分.19的最好结果增加了一个基于分割的验证过程[20]。图6总结了我们训练的几个模型的性能。只含有根滤波器的模型等价于论文[5]中的模型,并且得到稍微高一点的.18AP。如果在模型中为每个正样本增加隐藏的位置和尺度变量,使用LSVM进行训练的话,性能会大幅增加到.24AP。这表明LSVM即使对于固定模版模型也是非常有用的,因为增加隐藏变量可以允许训练数据中的检测窗口进行自我调整。加入可形变部件模型后,性能增加到.34AP——之前最优结果的两倍。最后,我们训练了一个只含有部件滤波器没有根滤波器的模型,可以达到.29AP,这说明了使用多尺度表示的优点。

图6,系统在PASCAL VOC 2006人体数据集上的表现。Root代表只使用根滤波器并且没有正样本中检测窗口的隐藏位置变量。Root +Latent表示使用带有隐藏的检测窗口位置变量的根滤波器。Parts + Latent表示带有隐藏位置变量的部件滤波器,不含根滤波器。Root + Parts + Latent表示带有检测窗口隐藏位置变量的根滤波器和部件滤波器。
我们还在PASCAL 2006人体数据集上考察了空间模型和允许形变量对系统性能的影响。如2.3节所述,si是部件的允许位移量(?si不是部件矩形框的大小吗?),以HOG细胞单元为单位。我们训练一个固定的带有高分辨率部件的模型,将si设为0,此模型比只有根滤波器的模型要好,得分在.27AP到.24AP之间。在不使用形变花费的情况下,增加允许位移量,则结果会逐渐接近特征袋方法(bag-of-features)。当si等于1时,性能达到最优,这表明约束部件的位移量很有必要。最优策略是:允许更大的位移量,同时加入形变花费(deformationcost)。下面的表格中的前三列是允许任意位移量的情况下系统的性能得分,最后一列是使用二次形变花费并最大允许位移量为2个HOG细胞单元的情况下系统的性能得分。

5 讨论
本文中介绍了一个训练含有隐藏变量的SVM的通用框架。我们使用LSVM基于多尺度、可变形模型建立了一个识别系统。在不同测试集上的实验结果表明我们的系统是目标检测领域的当前最优结果(state-of-art)。
LSVM可以探索目标识别中额外的隐藏结构。我们可以考虑更深的部件层次(部件中包含部件),混合模型(汽车的前视模型和侧视模型),以及三维姿态。通过使用共享的部件词典(shared vocabulary of parts),我们可以训练并同时检测多个类别。我们还计划使用A*搜索[11]在检测时高效的搜索隐藏参数。
文章下载:http://download.csdn.net/detail/masikkk/6763781
Deformable Part Model 相关网页:http://www.cs.berkeley.edu/~rbg/latent/index.html
Pedro Felzenszwalb的个人主页:http://cs.brown.edu/~pff/
PASCAL VOC 目标检测挑战:http://pascallin.ecs.soton.ac.uk/challenges/VOC/
以及Pedro Felzenszwalb 在PAMI 2010的一篇更详尽的期刊文章的翻译:
Object Detection with Discriminatively Trained Part Based Models[PAMI 2010]的中文翻译
有关可变形部件模型(Deformable Part Model)中一些难点的一些说明:
http://blog.csdn.net/masibuaa/article/details/17534151