Going deeper with convolutions笔记
Going deeper with convolutions笔记
- Abstract
- Introduction
- Related Work
- Motivation and High Level Considerations
- Architectural Details
- GoogLeNet
- Training Methodology
- ILSVRC 2014 Classification Challenge Setup and Results
- ILSVRC 2014 Detection Challenge Setup and Results
- Conclusions
本文是20150112
Abstract
本文提出了一种新的分类和检测的新网络。该网络最大的特点就是提升了计算资源的利用率。在网络需要的计算不变的前提下,通过工艺改进来提升网络的宽度和深度。最后基于Hebbian Principle和多尺寸处理的直觉来提高性能。在ILSVRC-2014中提交了这种网络,叫GoogLeNet有22层。
本篇论文是针对ImageNet2014的比赛,论文中的方法是比赛的第一名,包括task1分类任务和task2检测任务。本文主要关注针对计算机视觉的高效深度神经网络结构,通过改进神经网络的结构达到不增加计算资源需求的前提下提高网络的深度,从而达到提高效果的目的。
googlenet的构造在原本n通道和m通道的两层间加入了一个p通道的层。这个做法不仅降低了参数量和计算量并且符合神经学的Hebbian principle,所以在效果上也有不小的提升。
我认为google的inception layer之所以有用一是因为Hebbian principle,二是对图像尺度的考虑。
本文提出了一个新深度网络的“结构”,命名为inception(开端之意,个人命名为起航);这个结构可以充分利用网络中“计算资源”(充分开发和利用每层提取的特征);在保证固定计算复杂度前提下,通过人工的进行设计来允许增加网络的深度和宽度实现的。结构是基于Hebbian准则和multi-scale处理来优化其性质的。
我们可以假定,反射活动的持续与重复会导致神经元稳定性的持久性提升……当神经元A的轴突与神经元B很近并参与了对B的重复持续的兴奋时,这两个神经元或其中一个便会发生某些生长过程或代谢变化,致使A作为能使B兴奋的细胞之一,它的效能增强了。这一理论经常会被总结为“一起发射的神经元连在一起”(Cells that fire together, wiretogether)。这可以用于解释“联合学习”(associative learning),在这种学习中通过对神经元的刺激使得神经元间的突触强度增加。这样的学习方法被称为赫布型学习(Hebbian learning)。 (百度百科)
海扁学习法专业描述。我们来重新专业地描述一下。如果两个神经元常常同时产生动作电位,或者说同时激动(fire),这两个神经元之间的连接就会变强,反之则变弱。(http://blog.sina.com.cn/s/blog_569d6df80100wug8.html)
1. Main Contribution
-
Improve utilization of the computing resources inside the network, which is achieved by carefully crafted design and allows for increasing the depth and width of the network while keeping the computational budget constant.
-
Architecture decisions are based on the Hebbian principle and the intuition of multi-scale processing.
-
A 22 layers deep network is assessed in the competition.
我认为google的inception layer之所以有用一是因为Hebbian principle,二是对图像尺度的考虑。
我认为google的inception layer之所以有用一是因为Hebbian principle,二是对图像尺度的考虑。
Introduction
GoogLeNet 只用了比[9]少12倍的参数,但正确率更高。本文最大的工作是通过CNN和普通的计算机视觉结合,类似于R-CNN[6]。因为算法的ongoing traction of mobile和嵌入式计算,算法的效率变得很重要。也导致了本文不会使用绝对的数量。本文将会关注CV的深度神经网络“Inception”。本文既将Inception提升到了一个新的高度,也加深了网络的深度。
近年来在图像识别和物体检测领域的进步,除了强悍的硬件,大的数据集,大的模型外,还有新想法,算法和改进的网络结构的功劳。GoogLeNet比Alex-net少12倍的参数而且更加准确。在物体检测领域,最大的贡献来源于深度网络和经典的计算机视觉算法的融合,例如RNN,感觉SPP也是。
本文不光追求推进网络的识别率,算法的效率和内存也是本文的关注点;所以本文所有网络的设计,保证在测试阶段在15亿乘-加指令以内
本文关注于一个对于CV来说高效的深度网络结构-inception。本文的深度有两次意思:
1,以inception模块的形式提出了一种新的深度组织形式
2,直接增加层数的意思
一般来说,可以把inception看成是Network inNetwork的“逻辑顶点”;从“Provable bounds for learning deep representation”的理论研究中获得灵感和指导。
Related Work
最近两年的工作是增加层数和层大小,利用dropout来解决过拟合的问题。而传统的CNN还用来进行定位、检测、人体姿势估计。
[15]用了不同的大小。GoogLeNet用了很多相同的层,共22层。[12]的Network in Network用来提高神经网络的power。本文用Network in Network有两方面用途,降低维度来降低计算瓶颈,也可以提高网络的深度和宽度。[6]所提出的R-CNN将检测分成两部分:在浅层利用颜色、次像素组成等信息检测,再利用深层的CNN进行分类。作者对这种方法也进行了提高。
- 本文提出的网络结构为Inception,得名于论文参考文献12(network in network)。
- Recent trend of CNN is to increase the number of layers and layer size, while using dropout to address the problem of overfitting。
- 论文参考文献15使用不同尺度的Gabor过滤器来处理多尺度问题,同本文的Inception Model类似。
- 本文借鉴参考论文12,使用了很多1×1的卷积核。卷积核在本文中的作用主要在于降维,以此来去除计算瓶颈。
- Detection task’s leading approach is Regions with Convolutional Neural Networks(R-CNN) (参考文献6)。该方法分为两步:
- First utilize low-level cues such as color and superpixel consistency for potential object proposals in a category-agnostic fashion.
- Then use CNN classifiers to identity object categories at those locations.
受到灵长类神经视觉系统的启发,Serre使用不同尺寸的Gabor滤波器来处理不同尺寸的图片,这个和inception很相似。
Network-inNetwork是为了增加网络表达能力提出的深度网络。当应用到卷积网络,其可以被看做是1*1的卷积层,后面跟着ReLU函数。本文的网络大量应用这种结构,然而在我们的网络中这种结构有双重作用:主要用于维数约减模块来移除计算瓶颈,否则这个瓶颈会限制我们网络的大小。这样不仅允许我们增加深度,而且允许我们增加宽度。
当前最流行的检测算法就是Girshick提出的Regions-CNN;R-CNN把检测任务分解为两个子任务:1利用“底层的”线索(颜色或者像素的一致性)提取潜在的物体。2使用CNN来分类潜在的物体。我们进一步改进了其算法,例如multi-box预测等。
3. Motivation and High level considerations
简单的使网络更深更大,容易导致过拟合,且增加计算性能的消耗。其根本的解决办法是将全连接层变为稀疏链接层[2]。对于非均衡的稀疏数据,今天的计算效率不高。[3]提出将多个稀疏矩阵合并成相关的稠密子矩阵来解决问题。
……
3.1. Drawback of increasing CNN size directly:
- More prone to overfitting.
- Dramatically increase use of computational resources. (for example, if most weights end up to be close to zero, then lots of computations is wasted.)
3.2. How to solve it?
- The fundamental way would be by ultimately moving from fully connected to sparsely connected architectures.
- 论文的参考文献2表明,考虑到统计相关性,一个稀疏网络结构可以重新构建出最优结构。并产生了Hebbian principle——neurons that fire together, wire together。
- 从更底层考虑,现在的硬件在非一致稀疏数据结构上的计算非常不高效,尤其在这些数据上使用已经为密集矩阵优化过的库时。原来自论文参考文献9以来,都会使用随机稀疏的网络结构来打破对称性,提高学习率。但论文参考文献11中又重新使用全连接的结构,以图利用密集计算的高效性。
- 所以,现在的问题是有没有一种方法,既能保有网络结构的稀疏性,又能利用密集矩阵的高计算性能。论文提出了一种Inception Module,可以达到此等效果。
在大量的带标签的数据集前提下,提升深度网络性能最简单的方式就是增加网络的size;包括增加深度和宽度。这种方法有两个瓶颈:
1,大的网络需要更多的参数,较多的参数在固定的数据集下,容易造成网络过拟合。高质量的大数据集是非常昂贵的。
2,大的网络需要更多的计算资源。例如连个相互连接的卷积网络,一致的增加网络的卷积数目,导致计算量二阶增涨。此外,如果额外增加的网络没有得到有效的利用(很多权值接近0),会造成计算资源浪费。
本文认为解决上了两个问题最基本的方式是:从全连接转到稀疏连接结构。稀疏连接除了模仿生物系统外,Arora还提出了很好的理论基础。Arora强调:“数据集的概率分布被一个大的稀疏的网络代表,那么理想的网络拓扑结构应该这样建立(这样的意思是:通过一层一层的统计层间激活值的相关性,然后通过对高度相关的输出进行聚类)”。尽管严格的数学证明需要很多的前提条件,但是这个观点和Hebbian准则(fire together,wired together)相互呼应,这也意味着在弱前提条件下,这个想法也是适用的。
此外,涉及到非一致稀疏数据数值计算时,当前的计算设施还很不高效。尽管算数操作的数量减少了100倍,查找和缓存丢失是如此显著以至于转到稀疏矩阵没有取得成功。通过利用经过稳定改进的,高度调节的数值计算库来快速计算密集矩阵相乘,或者详尽地调节CPU和GPU,会使得这种gap扩大(这个没有明白,感觉应该是非一致稀疏矩阵计算有些复杂,当前处理的方法不但不高效,而且还有些不准确)。非一致稀疏矩阵的计算需要更加复杂的计算设施。当前的视觉机器学习系统只是通过卷积的方式来实现一种空间的局部稀疏性。然而,卷积在基础小的patches(感觉应该每个filter或者kernal)上是全连接的。传统的卷积网络在特征空间使用随机和稀疏的连接方式;因为他们(LeCun)想打破对称性和提升学习能力;然而为了更好的优化并行计算系统,这种趋势有转回到全连接方式。结构的一致性,大量的filter和更大的minibatch size允许使用高效的dense compution。
是否存在一个中间的步骤:一个可以利用额外稀疏性的结构,甚至在filter层,但是通过利用在密集矩阵上的计算来探索当前的硬件。稀疏矩阵计算研究建议:把稀疏矩阵聚类到密集子矩阵能够很好的解决问题。这种方法也可以应用在未来自动建立非一致深度结构上。(翻译的晕晕乎乎)
本文的inception结构起初提出用来评估一个复杂网络拓扑构建算法的假设输出,这个算法尝试近似一个稀疏结构,通过密集,容易获得的成分来覆盖假设输出。尽管这个理论是假设性的,在准确拓扑选择后,经过两次迭代,作者得到了不错的结果。在进一步调整学习率等参数后,作者建立的inception结构在检测网络中得到了很好的结果。尽管大多数的原始结构的选择被提出和测试,但是至少这个被证明是局部最优的。(额,有些糊涂;就理解着翻译了)。
尽管inception结构已经取得了很好的结果,但是inception的特性是否能够归功于上面分析的指导原则是值得怀疑的。
Architectural Details
Inception主要的思想就是如何找出最优的局部稀疏结构并将其覆盖为近似的稠密的组件。[2]提出一个层与层的结构,在结构的最后一层进行相关性统计,将高相关性的聚集到一起。这些簇构成下一层的单元,与上一层的单元连接。假设前面层的每个单元对应输入图像的某些区域,这些单元被滤波器进行分组。低层(接近input层)的单元集中在某些局部区域,意味着在最终会得到在单个区域的大量群,他们能在下一层通过1*1卷积覆盖[12]。然而也可以通过一个簇覆盖更大的空间来减小簇的数量。为了避免patch-alignment问题,现在滤波器大小限制在1*1,3*3和5*5(主要是为了方便也非必要)。在pooling层添加一个备用的pooling路径可以增强效率。
Inception模块都堆在其他Inception模块的上面,……
上述模块一个巨大的问题就是,即使是一个合适数量的卷积,也会因为大量的滤波而变得特别expensive。经过pooling层输出的合并,最终可能会导致数量级增大不可避免。处理效率不高导致计算崩溃。
第二种方法:在需要大量计算的地方进行慎重的降维。压缩信息以聚合。1*1卷积不仅用来降维,还用来修正线性特性。
只在高层做这个,底层还是普通的卷积。
……
The main idean of the Inception architecture is based on finding out how an optimal local sparse structure in a convolutional vision network can be approximated and covered b readily available dense components.
如何发现最优结构呢? 可以这样考虑,较低的层次对应着图像的某个区域,使用1×1的卷积核仍然对应这个区域,使用3×3的卷积核,可以得到更大的区域对应。因而设计如图1。
图 1 Inception Module, Naïve version
为了降维,使用1×1的核进行降维,设计如图2。降维能够起效主要得益于embedding技术的发展,即使较低的维度仍然可以包含很多信息。
图 2 Inception Module with dimension reductions
在Filter concatenation层将1×1/3×3/5×5的卷积结果连接起来。
如此设计的好处在于防止了层数增多带来的计算资源的爆炸性需求。从而使网络的宽度和深度均可扩大。使用了Inception层的结构可以有2-3×的加速。
Inception的主要思想是找到卷积网络中理想的局部稀疏结构怎样通过容易获得的密集成分来拟合和覆盖。假设通过卷积块来建立平移不变性,这样我们需要做的就是找到理想的局部构造,然后在空间上拓展重复。Arora建议要逐层构建:需要分析后一层的统计相关性;然后把高度相关的单元聚类在一起。下一层聚集到一起的单元,连接到上一层的单元。
我们假设前几层的单元对应输入图像的一些区域,这些单元被聚集到filter bank中;这样前几层的相关单元聚集到局部区域。这意味着,许多的聚类被聚集到一个单一区域,他们可以被下一层的1*1的卷积覆盖。然而,我们也希望存在少数的空间拓展的聚类,这些聚类可以被在大的patch上的卷积覆盖,随着patch区域的增大,数量应该减小。
为了避免patch alignment(区域布局)问题,当前的inception结构被限制在卷积尺寸1*1,3*3和5*5,这种设计是基于更加的方便而不是必须的。这种结构也意味着所有层filter的输出被聚集到一个单一的输出向量,从而形成下一层的输入。此外,由于pooling结构是当前卷积网络成功的关键,在每个阶段增加一个可选择的并行pooling结构。
上面inception模块的一个问题是计算问题,因为一个中等的5*5卷积运算在有很多的特征存在情况下都是被禁止的。这个问题更加的突显出来当pooling层加入其中时:输出filter的数量等于等于输入filter的数量。融合pooling层和卷基层层的输出会导致一个不可避免的增加输出的数量。尽管这个结构能够覆盖理想的稀疏结构,在计算上非常不高效。
这就引起了本文的第二个考量:当计算需求增加的时候,应用维数约减和projection(投影);这个是基于低维的嵌入可能包涵许多大的图像区域的信息。然而以一个密集,压缩的方法嵌入代表的信息和压缩的信息是非常困难的。我们只是想在大多数地方保持特征稀疏,压缩信息仅仅在特征不得不融合在一起时;这就是为什么1*1的卷积在3*3和5*5卷积前使用的原因;1*1filter出了维数约减外,还起到增加非线性的作用。
一般滴,inception网络是一个有inception模块堆叠组成的网络;偶尔使用s=2的max-pooling来使特征减半。由于技术的原因(训练阶段存储效率),似乎在高层使用inception模块更加有益,让底层的保持原始的卷积网络形状。
这个结构的主要贡献是:在可控的计算复杂度增量下,增加每个阶段的单元个数。无处不在的维数约减,允许上一层的大量的输入filter“shield”到下一层。在一个大的patch卷积之前,先进行维数约减。
另一个有用的方面就是这种设计灵感来源于:视觉信息应该在不同尺度上处理,然后融合;以便下一层能够从不同的scale上提取特征。
GoogLeNet
 表1
表1
#3*3 reduce代表3*3卷积前1*1滤波器的个数。所有的reduction/projection层都利用了修正线性激活。网络包含22层带参数层和5层不含参数的pooling层。总共有约100层。分类前的pooling是基于[12],只是我们利用了不同的线性层。有利于精细的调节网络,但不期望它有多出色。从全连接层move到下采样会将Top1准确率提高0.6%,但是dropout仍然需要。
 图1
图1
图2
在浅层网络来说,相对中间的网络产生的特征非常有辨识力。在这些层中增加一些额外的分类器,能个增加BP的梯度信号和提供额外的正则化。这些分类器将小的卷积网络放在4a和4b的输出上。在训练过程中,损失会根据权重叠加,而在测试时丢弃。
如图3所示。更详细的结构图太大请见原论文。
图 3 GoogLeNet incarnation of Inception architecture
若按照经典的网络结构分法,本文应该算作是5 stage网络(每个pooling层算一个stage,inception内部的pooling不计算在内)。
Input(224,224,3)→64F(7,7,3,s=2) →max-p1(3,3,2) →192F(3,3,64,1) →max-p2(3,3,2) →2inception→max-p3(3,3,2)→5inception→max-p4(3,3,2) →2inception→avg-p5(7,7) →dropout40%→linear→softmax.
前4个stage使用max-p,最后一个stage使用avg-p;这是基于Network in Network中的考虑;这可以为了其他数据集修改和调整网络更加容易和方便。把fc层变成均值pooling层导致top-1有0.6%的提升。Dropout仍然很关键。
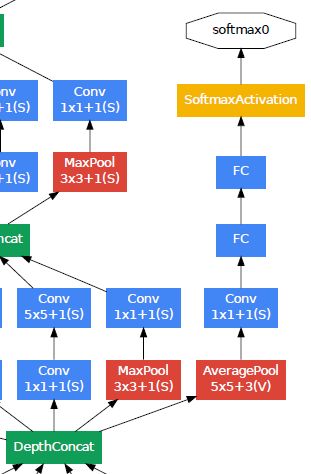
考虑到网络的深度,梯度反向传递是一个问题。一个有趣的现象是中间层网络的特征具有很好的判决性。通过增加辅助分类器给中间层,我们希望增加底层特征的判决性,增加反向传递的梯度信号,同时也提供了额外的规则化。这些辅助分类器采用小的卷积网络放在inception-4a和inception-4d的上面。在训练阶段,辅助分类器的梯度误差通过加权(辅助梯度权值为0.3)的方式增加到主网络的梯度误差上。
inception-4a辅助分类器说明:
inception-4a的输出特征为14*14*512,经过512F(5,5,512,s=3)的卷积得到4*4*512个特征,在经过1*1的卷积过程,进入两个fc层(每层有1024个单元,70%dropout,)然后是一个带softmax损失函数的线性层。
Training Methodology
利用[4]提供的分布式机器学习系统和数据平行。用数个高端GPU,一周达到收敛。利用[17]异步随机梯度下降,0.9动量,学习率每八个周期下降4%。最后用Polyak averaging [13]来创建最后用来测试的模型。
采样变化很大。[8]的光度扭曲有助于对付过拟合。还进行了随机插入。
- Using DistBelief distributed machine learning system with modest amount model and data parallelism.
- Training with asynchronous stochastic gradient descent with 0.9 momentum, fixed learning rate schedule(decreasing the learning rate by 4% every 8 epochs) and Polyak averaging(论文参考文献13)is used。
- Sampling of various sized patches of the image whose size is distributed evenly between 8% and 100% of the image area and whose aspect ratio is chosen randomly between 3/4 and 4/3.
- Photometric distortions
- Using random interpolation methods for resizing relatively late and in conjunction with other hyperparameter changes.
使用google的DistBelief分布式机器学习系统;本文只在CPU上部署,主要的限制来自于内存(作者粗略估计本文网络可以在几个GPU上一周内训练完成)。本文使用异步的SGD,动量项=0.9;没迭代8次,减小4%的学习率。
对于图像采样方法一直在改变,并没固定的方法;已经收敛的网络是在其他的选择下训练的,所以给出一个有效的训练网络的方法是困难的。更为复杂的是,一些网络在相对小的patch上训练,一些网络在相对大的patch上训练,;还有一个技巧被证明很有效:提取各种各样的patches,patches的size均匀地分布在图像区域8%和100%之间,比例也在3/4和4/3之间随机选择。还有一些其他数据增益技术。
ILSVRC 2014 Classification Challenge Setup and Results
为了获得更好的结果,使用了一下几种方法:
1,multi-module 融合:7个网络融合(包括最初提到的wider网络)。模型的初始值相同,但是采用不同的采样方法。
2,multi-scale:256,288,320,352共计4个scale;在每个scale首先剪裁左中右3个方块A;然后在每个方块A上提取的4个角和中心提取224*224的patches,同时也把A缩小到224*224,然后在水平翻转;这样每张图片就产生了4*3*6*2=144个样本。
结果:
①训练了7个网络,只是采样方法和随机输入图像不同,取综合值。
②将图像的短边缩放成4中:256,288,320,352。取图像的上中下块。每块取四个角、中间的224*224和将其缩放到224*224以及它们的镜像。结果是4*3*6*2=144,即每个图像采样144块输入图。但可能实际生产中不能应用。
③maxpooling和在分类器平均,最后的结果都不如简单的平均好。
 表2
表2
 表3
表3
结果:
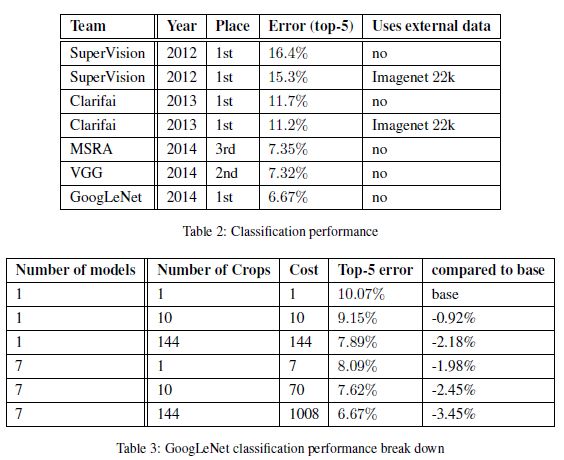
从table2,可以看出本文在ILSVRC中获得了6.67%的最好成绩;从table3中可以看出,单个网络,在一个crop的情况下,取得了10.07%的成绩,随着Crop的增多,结果有了近2%的提升;7个网络模型平均,性能也提升了近2%;说明multi-crops,multi-module对于发挥网络的性能很关键。
ILSVRC 2014 Detection Challenge Setup and Results
方法与[6]的R-CNN很像,但增加了Inception模块。结合了用multi-box [5] 的方法和Selective Search [20] 来提高定位框的召回率。这让从Selective Search [20] 得到的结果减半。再加上200个[6]的方法,总共[6]占60%,可以将覆盖率从92%提高到93%。上述方法可以将准确率相对单一模型提高1%。在分类区域的时候利用6个卷积网络科将准确率从40%提高到43.9%。
表4最后GoogLeNet最好,比去年大了接近一倍。表5表示GoogLeNet在单模型的情况下,只比最好的低0.3%,但那个用了3个模型,而GoogLeNet在多模型的情况下结果好得多。
 表4
表4

表5
Experiments Setup and Results
- Trained 7 versions of same GoogLeNet model, performed ensembel prediction with them. These models are trained with the same initialization, but differ in sampling methodologies and the random order in which they see input images.
- Testing: resize the image to 4 scales where the shorter dim is 256,288,320,352. Take the left, right, center square of these resized images, then take the 4 corners and the center 224×224 crop and the square resize 224×224, and their mirror version. Namely, 4×3×6×2=144 crops per image.
- Softmax probabilities are averaged over multiple crops and over all individual classifiers to obtain the final prediction. Simple averaged is the best.结果如下:
图 4 performance of the competition
图 5 performance of fusions of Models
Conclusions
将最佳稀疏结构稠密化是一种有效提高CV神经网络的方法。优点是只适度增加计算量。本文检测方法不利用上下文,不会定位框回归,证明了Inception方法的强壮。本文提供了一个将稀疏变稠密的途径。
八 ILSVRC 检测
ILSVRC 检测任务是预测图像中大约200个类别的边框。
检测方法类似R-CNN,首先进行区域提取,通过结合Selective Search和multi-box预测来改进区域提取算法。为了减少错误positives的数量,像素增加2倍;这种方法把selective search提取的区域减半,然后又从multi-box结果中添加200个区域,最后大约使用60%的区域,同时增加覆盖范围从92%到93%。削减区域最后使mAP提高1%,最后使用6个网络来对每个区域进行分类。
本文在没有使用额外预训练数据的情况下,没有使用bounding boxregression的情况喜爱,获得了单个网络获得38.02%;6个网络获得了43.9%的成绩;说明multi-module对于分类和检测都很重要。
九,结论
通过容易获得的密集building block来近似理想的稀疏结构是一个可行的方法。这种方法的主要贡献是在微小增加计算量的情况下明显地提升效果。我们的方法有力地证明了转移到稀疏结构是一个灵活并且有用的想法。
一些困惑和理解
本文之前读了好几遍了,记了一边笔记,今天又总结了一遍,还是是一头雾水,可能自己懂得太少了,除了网络结构,其他的理论似懂非懂的,除了困惑还是困惑。下面就复制一些知乎上贾扬清的观点:
原文链接:http://www.zhihu.com/question/24904450
今年我们在Google提交的结果与去年相比有了很大的提高,并且在classification和detection两个方向都获得了最好的结果。不过,话说回来,大家也应该都估计到了今年的结果会比去年好:)个人觉得,更有意思的是“how to get the number"而不是“what the number is”。我从classification和detection两个track分别聊一下个人的拙见。
Classification:与Alex在2012年提出的AlexNet不同的一点是,我们这次的结果大大增加的网络的深度,并且去掉了最顶层的全连接层:因为全连接层(Fully Connected)几乎占据了CNN大概90%的参数,但是同时又可能带来过拟合(overfitting)的效果。这样的结果是,我们的模型比以前AlexNet的模型大大缩小,并且减轻了过拟合带来的副作用。另外,我们在每一个单独的卷积层上也作了一些工作(“with intuitions gained from the Hebbian principle”),使得在增加网络深度的情况下,依然可以控制参数的数量和计算量,这都是一些很有趣的方向。
Detection:个人觉得,在detection上最有意思的工作应该是ILSVRC2013以后,Jeff Donahue和Ross Girshick(和我在Berkeley同一个实验室的Phd学生和Postdoc)所发表的R-CNN方法。R-CNN的具体想法是,将detection分为寻找object(不管具体类别,只管“那儿好像有个东西”)和识别object(识别每个“东西”到底是狗还是猫)两个过程。在第一步,我们可以用很多底层特征,比如说图像中的色块,图像中的边界信息,等等。第二步就可以祭出CNN来做识别,网络越好,识别率也就越高。今年很多参与detection的组都借鉴了R-CNN的想法。
总的来说,CNN的效果还是很不错的,但是还是有一些不足的地方:比如说,Detection的正确率依然还没有很高,并且很多时候我们的分类器其实并不一定知道具体的object,它只是学习到了一些场景信息。比如下图:

顺便也要纠正一下在提到CNN的时候经常出现的错误:“CNN的参数太多,造成学习困难。”
其实CNN相比较于以前的模型,参数并不见得多:在CNN之前,NEC Labs采用sparse SIFT+Pyramid Pooling的方法取得过ILSVRC的冠军,在这些模型中,最后线性SVM的输入特征在160K到260K不等。因为一共有1000类,所以SVM的总参数是160M-260M左右。Alex 2012年的模型只有60M参数,而我们今年的模型大概只有7M。(补充编辑:这些图像特征一般都是稀疏的,但是SVM的参数并不稀疏。)
所以,其实我们应该说的是,CNN的优化是一个非凸(non-convex)的问题,所以才比较困难 :)
同时也要做一下广告:一直以来我都很希望许多研究工作可以开放源代码(好多PhD应该都有同感吧,读完一篇paper然后痛苦地实现文中的方法。。。然后老板很奇怪为啥你花那么久),去年用Decaf/Caffe参加比赛,主要也在于推广一个开源的框架,方便大家做进一步的实验。R-CNN发表以后,我们在github上公布了完整的基于Caffe的实现,今年很多组都提到使用了Caffe或者R-CNN的研究成果,让我们在Berkeley的同事倍感欣慰。今后也希望看到Caffe能支持更新的研究工作。
知乎上另一个叫做刘留的人的回答:
GoogLeNet和VGG的Classification模型从原理上并没有与传统的CNN模型有太大不同。大家所用的Pipeline也都是:训练时候:各种数据Augmentation(剪裁,不同大小,调亮度,饱和度,对比度,偏色),剪裁送入CNN模型,Softmax,Backprop。测试时候:尽量把测试数据又各种Augmenting(剪裁,不同大小),把测试数据各种Agumenting后在训练的不同模型上的结果再继续Averaging出最后的结果。
今年的结果看起来是越深的模型越好(VGG的结果在12月份Revised过的Paper上也是他们最深的模型效果最好)。但是越深的模型训练所需要的时间越长。VGG的Mode D我在4个GPU上跑了三周多。GoogLeNet的训练时间看起来会短一些,但是怎样优化内存占用还不是很清楚,所以现在还没有重复出来的结果(没有DistBelief啊喂!Princeton的结果看起来还没有达到GoogLeNet的效果)。
就今年的结果而言,还有几点在Engineering上不太清楚:
1). VGG的模型,如果直接训练,不用Mode A来初始化,结果会好些吗,可以用训练好的几个ModeE来Averaging吗?(似乎最近的结果看起来Initialization对结果确实会有一些影响:http://arxiv.org/pdf/1312.6120v3.pdf)
2). GoogLeNet模型中那些分叉出去的softmax layers到底有效果,还是为了工程实践上的方便?
3). VGG模型前两层的小reception fields到底有用吗?还是和GoogLeNet一样用Matt & Fergus的7x7,5x5在前几层不影响?(大量的3x3 kernelconvolution在前几层很慢,内存占用也大)。
4). 从其他人的结果看起来,似乎更多的Data Augmentation是有帮助的,但是在sub-10%的Level,更多的Data Augmentation帮助到底有多大?
5). GoogLeNet的最后一层是Average Pooling,大大降低了参数数量,这样对结果有负面影响吗?
6). 大家都用7、8个模型来Averaging,把这些模型distilling到一起的话有帮助吗?
总结一下的话,今年大家的结果都很好,但是要实用起来还有一段路(Google除外)
[2] Sanjeev Arora, Aditya Bhaskara, Rong Ge, and Tengyu Ma. Provable bounds for learning some deep representations. CoRR, abs/1310.6343, 2013.
[6] Ross B. Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In Computer Vision and Pattern Recognition, 2014. CVPR 2014. IEEE Conference on, 2014.
[9] Alex Krizhevsky, Ilya Sutskever, and Geoff Hinton. Imagenet classification with deep con-volutional neural networks. In Advances in Neural Information Processing Systems 25, pages 1106–1114, 2012.
[12] Min Lin, Qiang Chen, and Shuicheng Yan. Network in network. CoRR, abs/1312.4400, 2013.
[15] Thomas Serre, Lior Wolf, Stanley M. Bileschi, Maximilian Riesenhuber, and Tomaso Poggio. Robust object recognition with cortex-like mechanisms. IEEE Trans. Pattern Anal. Mach. Intell., 29(3):411–426, 2007.
http://blog.csdn.net/whiteinblue/article/details/43635575 深度学习研究理解11:Going deeper with convolutions