(2016.4.17)文献总结Learning Hierarchical Features for Scene Labeling
LearningHierarchical Features for Scene Labeling
Introduction:
Full-scenelabeling 就是 scene parsing
关键在于用ConNet提取特征向量!!!
1.sceneparsing的困难之处在于一个过程里要结合detection, segmentation,multilabel recognition.
2.问题有两个:一是对视觉信息产生好的表达,二是使用背景信息保证对图片解释的一致性
3.文章的主要方法:使用卷积神经网络(引用Lecun的文本识别的论文)
卷积神经网络用原始像素的图片,以监督学习方式训练分类
每一层包括filterbank module, nonlinearity, spatial pooling mudule
4.multiscaleConNet解决像素分类依赖于小范围的信息,也依赖于长范围的信息。
5.过程:1)使用图方法来产生分割类别的假设。2)candidate segment(CS理解为测试部分)提取特征。3)用CFR或其他图方法被训练用来对CS产生标签(分类)
改进的方法在于使用大的背景窗来标志像素,减少对处理方法的要求
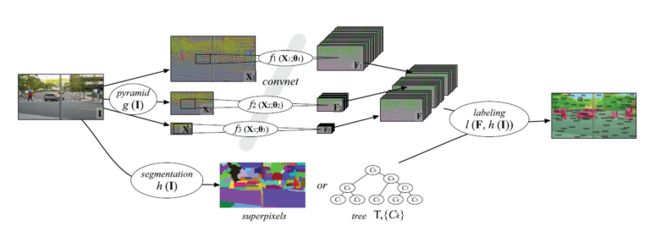
Sceneparsing系统分为两部分:
1.multiscaleconvolutional networks
g(I)是对输入图像做Laplacian pyramid变换,不同的scale,得到特征。缺点是没法准确突出区域的边界。用superpixel来得到图像的轮廓natural contours.
2.graphbased classification
Superpixels:simple and effective, butsuboptimal
CRF oversuperpixels:有效避免局部超越(如人在空中),但是没有用处,multiscale featurerepresentation已经把景色层次的关系考虑进去了。
MultilevelCut with Class Purity Criterion:下文细说
Relatedworks:
Learning Object-Class Segmentation withConvolutional Neural Networks,2012
Deep Convolutional Networks for SceneParsing,2009
Multiscale feature extraction for scene parsing
1.scale-invariant,scene-level feature extraction
好的internal representation是分层次的
Pixel edglets motifs parts objectsscenes
The input and output of each stage---feature maps
三层的ConvNet:
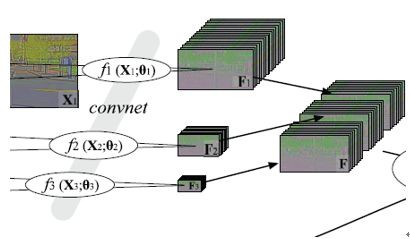
前两层有一堆滤波器F1,F2,F3还有f1,f2,f3。第三层只有一堆滤波器F。
滤波器即卷积内核是来自训练。每一堆滤波器都是移不变的(输入怎么移输出怎么移)
全景理解需要系统在完整图像的规模方面建模复杂的相互关系。
上图是multiscale pyramid的示意图,目的是产生不同大小的图片。有Gaussian pyramid、Laplacian pyramid、Steerable pyramid。对输入图像使用Laplacian pyramid得到不同大小的图片。并且预处理使得local neighborhoods有0均值和单位方差。Fs可以被视作是一系列的线性变换,其中穿插着非线性变换(比如sigmoid函数,这篇文章用tanh函数)
Fs有共L层layer(和上面说的层不同,上面说的层是stage)如下,在l层的隐含矩阵单元如下
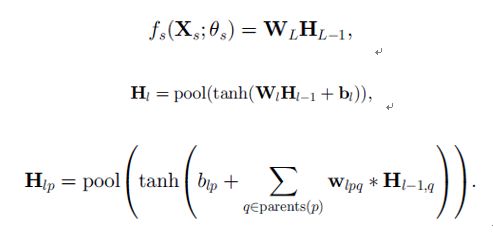
滤波器WL和偏移量bL用\theta_s表示。Pool是一个考虑近邻的activations并且每个近邻产生一个activation值。参见(http://blog.csdn.net/zhoubl668/article/details/24801103)。得到F函数,a map of feature vectors,u(.)是上采样函数。
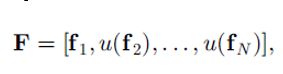
权重(应该是滤波器WL)在fs之间是共享的,这样的好处是迫使网络学习规模不变的特征(应该是图片被缩小后其卷积后的特征矩阵也要相应缩小)并且减少过拟合的可能性。
Learning discriminative scale-invariant features
理想情况下,线性分类器应该对每一个像素产生正确的分类,根据向量Fi。训练\theta来达到这一目标,用多类cross entropy函数。Ci是归一化的对像素i的预测,用softmax函数归一化。

Scene labeling strategies
最简单的方法用预测的argmax对于像素i。得到标记,

Superpixels超像素的方法
使用两层的网络让系统抓住不同规模下特征的非线性关系。W1,W2是可训练参数,dk,a是超像素块上所有像素点的平均。
Conditional RandomFields(待学习,貌似和MRF挺多不一样的)
在超像素的基础上完善传统的CRF,因为超像素不包含对景色的总体理解。虽然ConvNet有能力表达景色的整体关系,但是CRF能加强这一特性。策略是将图片与数据结构上的图联合,定义energy函数找最优。
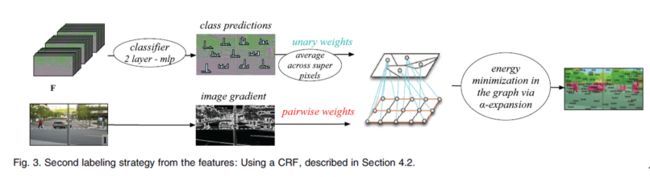
过程不解释。。。
Parameter-free multilevel parsing
以上两种方法是基于对图像的随意分割,会将图片分解的过小或过大。本文提出提出一种分类的方法来分析一个分割集(family of segments)然后对于每一个像素自动发现最好的观察层次。一个这种分割集特别的方案是分割树,分割树(segment tree)上的分割是按照等级组织的。此方法不仅限于这种分割树,还可用于近邻的随意集(?)。
“超像素分割”或“分层图像分割”(两篇最经典的文献)直接用得到Ck,成分(component)Ck是图像上所有与定义的网格相连的成分(k=1…K),Sk是与每一个成分的cost,对每一个像素i,想要找到k*(i)(表示成分的索引,就是第几个成分,1…K),能最好的解释这个像素i(cost最小)。
接着Ck的元素太多,只能考虑他的一个子集,下图为例,圆圈旁的数值是Sk*(i),圆圈内是Ck*(i),找到最佳覆盖的集合C,只要找到每个分支上最小权重的点Ck。另外一种方法,用不同的合并阈值在“超像素分割”算法中,找到最佳覆盖的方法是。。。


产生confidence costs(给定Ck,怎么求Sk)
