当TensorFlow遇见CNTK
当TensorFlow遇见CNTK
CNTK是微软用于搭建深度神经网络的计算网络工具包,此项目已在Github上开源。因为我最近写了关于TensorFlow的文章,所以想比较一下这两个系统的相似和差异之处。毕竟,CNTK也是许多图像识别挑战赛的卫冕冠军。为了内容的完整性,我应该也对比一下Theano、Torch和Caffe。后三者也是现在非常流行的框架。但是本文仅限于讨论CNTK和TensorFlow,其余的框架将在今后讨论。Kenneth Tran对这五个深度学习工具包做过一次高水平(以他个人观点)的分析。本文并不是一个CNTK或者TensorFlow的使用教程。我的目的在于从程序员的角度对它们做高层次的对比。本文也不属于性能分析,而是编程模型分析。文中会夹杂着大量的代码,如果你讨厌阅读代码,请直接跳到结论部分。
CNTK有一套极度优化的运行系统来训练和测试神经网络,它是以抽象的计算图形式构建。如此看来,CNTK和TensorFlow长得非常相似。但是,它们有一些本质上的区别。为了演示这些特性和区别,我会用到两个标准示例,它们分别包括了两个系统及调用各自系统完成的任务。第一个例子是用较浅的卷积神经网络来解决标准的MNIST手写数字集的识别任务。我会针对它们两种递归神经网络方法的差异性做一些点评总结。
TensorFlow和CNTK都属于脚本驱动型的。我的意思是说神经网络构建的流程图都是在一个脚本里完成,并调用一些智能的自动化步骤完成训练。TensorFlow的脚本是与Python语言捆绑的,Python操作符能够用来控制计算图的执行过程。CNTK目前还没有和Python或是C++绑定(尽管已经承诺过),所以它目前训练和测试的流程控制还是需要精心编制设计的。等会我将展示,这个过程并不能算是一种限制。CNTK网络需要用到两个脚本:一个控制训练和测试参数的配置文件和一个用于构建网络的网络定义语言(Network Definition Language, NDL)文件。
我会首先描述神经网络的流程图,因为这是与TensorFlow最相似之处。CNTK支持两种方式来定义网络。一种是使用“Simple Network Builder”,只需设置几个参数就能生成一个简单的标准神经网络。另一种是使用网络定义语言(NDL)。此处例子(直接从Github下载的)使用的是NDL。下面就是Convolution.ndl文件的缩略版本。(为了节省页面空间,我把多行文件合并到同一行,并用逗号分隔)
CNTK网络图有一些特殊的节点。它们是描述输入数据和训练标签的FeatureNodes和LabelNodes,用来评估训练结果的CriterionNodes和EvalNodes,和表示输出的OutputNodes。当我们在下文中遇到它们的时候我再具体解释。在文件顶部还有一些用来加载数据(特征)和标签的宏定义。如下所示,我们将MNIST数据集的图像作为特征读入,经过归一化之后转化为若干浮点数组。得到的数组“featScaled”将作为神经网络的输入值。
load = ndlMnistMacros
# the actual NDL that defines the network
run = DNN
ndlMnistMacros = [
imageW = 28, imageH = 28
labelDim = 10
features = ImageInput(imageW, imageH, 1)
featScale = Const(0.00390625)
featScaled = Scale(featScale, features)
labels = Input(labelDim)
]
DNN=[
# conv1
kW1 = 5, kH1 = 5
cMap1 = 16
hStride1 = 1, vStride1 = 1
conv1_act = ConvReLULayer(featScaled,cMap1,25,kW1,kH1,hStride1,vStride1,10, 1)
# pool1
pool1W = 2, pool1H = 2
pool1hStride = 2, pool1vStride = 2
pool1 = MaxPooling(conv1_act, pool1W, pool1H, pool1hStride, pool1vStride)
# conv2
kW2 = 5, kH2 = 5
cMap2 = 32
hStride2 = 1, vStride2 = 1
conv2_act = ConvReLULayer(pool1,cMap2,400,kW2, kH2, hStride2, vStride2,10, 1)
# pool2
pool2W = 2, pool2H = 2
pool2hStride = 2, pool2vStride = 2
pool2 = MaxPooling(conv2_act, pool2W, pool2H, pool2hStride, pool2vStride)
h1Dim = 128
h1 = DNNSigmoidLayer(512, h1Dim, pool2, 1)
ol = DNNLayer(h1Dim, labelDim, h1, 1)
ce = CrossEntropyWithSoftmax(labels, ol)
err = ErrorPrediction(labels, ol)
# Special Nodes
FeatureNodes = (features)
LabelNodes = (labels)
CriterionNodes = (ce)
EvalNodes = (err)
OutputNodes = (ol)
]DNN小节定义了网络的结构。此神经网络包括了两个卷积-最大池化层,接着是有一个128节点隐藏层的全连接标准网络。
在卷积层I 我们使用5x5的卷积核函数,并且在参数空间定义了16个(cMap1)。操作符ConvReLULayer实际上是在宏文件中定义的另一个子网络的缩写。
在计算时,我们想把卷积的参数用矩阵W和向量B来表示,那么如果输入的是X,网络的输出将是f(op(W, X) + B)的形式。在这里操作符op就是卷积运算,f是标准规则化函数relu(x)=max(x,0)。
ConvReLULayer的NDL代码如下图所示:
ConvReLULayer(inp, outMap, inWCount, kW, kH, hStride, vStride, wScale, bValue) =
[
convW = Parameter(outMap, inWCount, init="uniform", initValueScale=wScale)
convB = Parameter(outMap, 1, init="fixedValue", value=bValue)
conv = Convolution(convW, inp, kW, kH, outMap, hStride,vStride,
zeroPadding=false)
convPlusB = Plus(conv, convB);
act = RectifiedLinear(convPlusB);
]矩阵W和向量B是模型的参数,它们会被赋予一个初始值,并在训练的过程中不断更新直到生成最终模型。这里,convW是一个16行25列的矩阵,B是长度为16的向量。Convolution是内置的卷积函数,默认不使用补零的方法。也就是说对28x28的图像做卷积运算,实际上只是对24x24的中心区域操作,得到的结果是16个24x24的sudo-image。
接着我们用2x2的区域应用最大池化操作,最后得到的结果是16个12x12的矩阵。
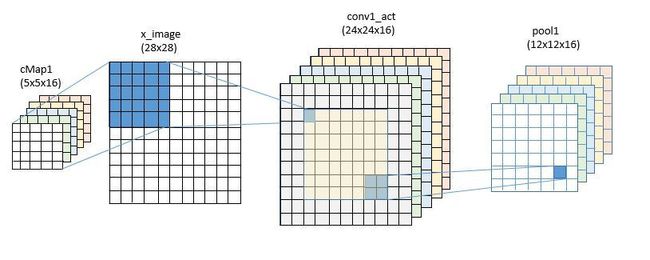
对于第二个卷积层,我们把卷积滤波器的个数由16个提升到32个。这一次我们有16通道的输入数据,因此W矩阵的尺寸为32行25×16 = 400列,向量B的长度为32。这次的卷积运算针对12x12图像帧的中心区域,所以得到的结果是32个8x8的矩阵。第二次池化操作的结果是32个4x4的帧,或者32x16=512。
最后两层,是由512个池化输出结果经过128个节点的隐藏层连接到10个输出节点,经历了两次运算操作。
DNNSigmoidLayer(inDim, outDim, x, parmScale) = [
W = Parameter(outDim, inDim, init="uniform", initValueScale=parmScale)
b = Parameter(outDim, 1, init="uniform", initValueScale=parmScale)
t = Times(W, x)
z = Plus(t, b)
y = Sigmoid(z)
]
DNNLayer(inDim, outDim, x, parmScale) = [
W = Parameter(outDim, inDim, init="uniform", initValueScale=parmScale)
b = Parameter(outDim, 1, init="uniform", initValueScale=parmScale)
t = Times(W, x)
z = Plus(t, b)
]如你所见,这些运算步骤都是标准的线性代数运算形式W*x+b。
图定义的最后部分是交叉熵和误差节点,以及将它们绑定到特殊的节点名称。
我们接着要来定义训练的过程,但是先把它与用TensorFlow构建相似的网络模型做个比较。我们在之前的文章里讨论过这部分内容,这里再讨论一次。你是否注意到我们使用了与CNTK相同的一组变量,只不过这里我们把它称作变量,而在CNTK称作参数。维度也略有不同。尽管卷积滤波器都是5x5,在CNTK我们前后两级分别使用了16个和32个滤波器,但是在TensorFlow的例子里我们用的是32个和64个。
def weight_variable(shape, names):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial, name=names)
def bias_variable(shape, names):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial, name=names)
x = tf.placeholder(tf.float32, [None, 784], name="x")
sess = tf.InteractiveSession()
W_conv1 = weight_variable([5, 5, 1, 32], "wconv")
b_conv1 = bias_variable([32], "bconv")
W_conv2 = weight_variable([5, 5, 32, 64], "wconv2")
b_conv2 = bias_variable([64], "bconv2")
W_fc1 = weight_variable([7 * 7 * 64, 1024], "wfc1")
b_fc1 = bias_variable([1024], "bfcl")
W_fc2 = weight_variable([1024, 10], "wfc2")
b_fc2 = bias_variable([10], "bfc2")网络的构建过程也大同小异。
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
#first convolutional layer
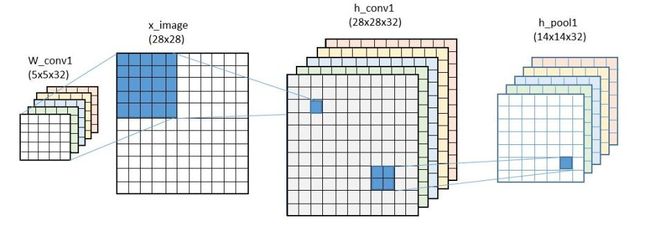
x_image = tf.reshape(x, [-1,28,28,1])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
#second convolutional layer
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
#final layer
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)卷积运算的唯一不同之处是这里定义了补零,因此第一次卷积运算的输出是28x28,经过池化后,降为14x14。第二次卷积运算和池化之后的结果降为了7x7,所以最后一层的输入是7x7x64 = 3136维,有1024个隐藏节点(使用relu而不是sigmoid函数)。(在训练时,最后一步用到了dropout函数将模型数值随机地置零。如果keep_prob=1则忽略这步操作。)
网络训练
CNTK中设置网络模型训练的方式与TensorFlow差别巨大。训练和测试步骤是在一个convolution.config的文件内设置。CNTK和TensorFlow都是通过符号化分析流程图来计算梯度下降训练算法中所用到的梯度值。CNTK组给出了一本非常赞的“书”来阐述梯度是如何计算的。现阶段CNTK只支持一种学习方法:Mini-batch随机梯度下降法,但他们承诺今后加入更多的算法。He, Zhang, Ren 和 Sun发表了一篇优秀的论文介绍他们是如何用嵌套残留还原法(nested residual reduction)来训练极度深层(深达1000层)的网络模型,所以让我们拭目以待这个方法被融入到CNTK中。配置文件的缩略版如下所示。
command = train:test
modelPath = "$ModelDir$/02_Convolution"
ndlMacros = "$ConfigDir$/Macros.ndl"
train = [
action = "train"
NDLNetworkBuilder = [
networkDescription = "$ConfigDir$/02_Convolution.ndl"
]
SGD = [
epochSize = 60000
minibatchSize = 32
learningRatesPerMB = 0.5
momentumPerMB = 0*10:0.7
maxEpochs = 15
]
reader = [
readerType = "UCIFastReader"
file = "$DataDir$/Train-28x28.txt"
features = [
dim = 784
start = 1
]
labels = [
# details deleted
]
]
]
test = [
….
]命令行显示了执行的顺序:先训练后测试。先声明了各种文件的路径,然后训练模块设置了待训练的网络模型以及随机梯度下降(SGD)的参数。读取模块根据NDL文件中的设置读取了“特征”和“标签”数据。测试模块设置了用于测试的参数。
16核(没有GPU)的Linux VM需要消耗62.95分钟来执行训练和测试过程,999.01分钟的用户时间和4分钟的系统时间。用户时间指的是所有16个核都在满负荷运转(999/63 = 15.85)。但这并不算什么,因为CNTK是为并行计算而设计的,大规模GPU支持才是真正的设计点。
TensorFlow的训练步骤在Python控制流程中设置得更清晰。而使用的算法Adam也是基于梯度计算的,由Kingma和Ba发明。TensorFlow的函数库里有大量基于梯度的优化方法,但我没有尝试其它的方法。
如下所以,cross_entropy是按照标准形式定义的,然后传入优化器生成一个 “train_step”对象。
y_ = tf.placeholder(tf.float32, [None, 10])
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
sess.run(tf.initialize_all_variables())
for i in range(20000):
batch = mnist.train.next_batch(50)
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print("test accuracy %g"%accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))随后Python脚本每批处理50条数据,以50%的舍弃率执行train_step,迭代20000次。测试步骤在整个测试集上评估准确率。
除了巧妙的自动求积分和Adam优化器的构建,一切都是直截了当的。我在16核的服务器上用CNTK例子中相同的数据集又跑了一遍。出乎我意料的是所需的时间与CNTK几乎一模一样。实际运行时间是62.02分钟,用户时间为160.45分钟,所以几乎没用利用并行运算。我觉得这些数字不能说明什么。CNTK和TensorFlow都是为大规模GPU运算而设计的,它们运行的训练算法并不完全一致。
递归神经网络在CNTK和TensorFlow的实现
递归神经网络(RNNs)在语言建模方面用途广泛,例如打字时预测下一个输入单词,或是用于自动翻译系统。(更多例子请参见Andrej Karpathy的博客)真是个有趣的想法。系统的输入是一个单词(或者一组单词)以及系统基于目前所出现单词而更新的状态,输出的是一个预测单词列表和系统的新状态,如图1所示。

当然,RNN还有许多变种形式。其中一种常见的形式是长短期记忆模型(LSTM),其定义公式如下:
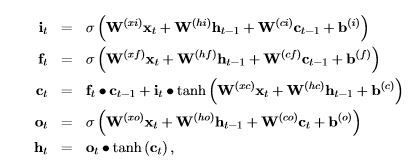
此处 \sigma 表示sigmoid函数。
如果你有兴趣读一篇关于LSTM及其工作原理的博文,我推荐Christopher Olah所写的这篇。他绘制了一张示意图,使得上面的等式更容易理解。我把它稍作修改,使它符合CNTK版本的方程式,结果如下图所示。
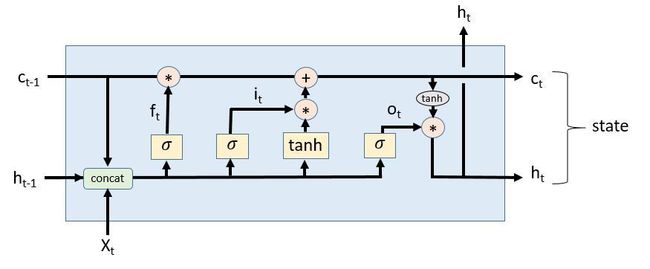
图中使用了sigmoid和tanh函数,并且级联变量得到了下面的表达式:
![]()
其中W和b是学习得到的权重。
CNTK版本
下面是为LSTM模型设置的NDL。有两件事需要注意。一个是网络模型中使用了一个称作“PastValue”的延迟操作符直接处理了递归的逻辑,它用到了维度和延迟时间两个变量,返回该值的一个副本。第二件事情是注意W矩阵的处理方式,它与上面以及图3中所示的级联操作有何区别。在这里,它们把属于x和h的所有W压入堆栈,把所有b值也存入堆栈。然后计算一个W*x和一个W*h并求和,再加上b的值。然后再使用一个行切分操作符,分别用独立的sigmoid函数处理它们。还需关注的是针对c的W矩阵都是对角阵。
LSTMPComponent(inputDim, outputDim, cellDim, inputx, cellDimX2, cellDimX3, cellDimX4) = [
wx = Parameter(cellDimX4, inputDim, init="uniform", initValueScale=1);
b = Parameter(cellDimX4, 1, init="fixedValue", value=0.0);
Wh = Parameter(cellDimX4, outputDim, init="uniform", initValueScale=1);
Wci = Parameter(cellDim, init="uniform", initValueScale=1);
Wcf = Parameter(cellDim, init="uniform", initValueScale=1);
Wco = Parameter(cellDim, init="uniform", initValueScale=1);
dh = PastValue(outputDim, output, timeStep=1);
dc = PastValue(cellDim, ct, timeStep=1);
wxx = Times(wx, inputx);
wxxpb = Plus(wxx, b);
whh = Times(wh, dh);
wxxpbpwhh = Plus(wxxpb,whh)
G1 = RowSlice(0, cellDim, wxxpbpwhh)
G2 = RowSlice(cellDim, cellDim, wxxpbpwhh)
G3 = RowSlice(cellDimX2, cellDim, wxxpbpwhh);
G4 = RowSlice(cellDimX3, cellDim, wxxpbpwhh);
Wcidc = DiagTimes(Wci, dc);
it = Sigmoid (Plus ( G1, Wcidc));
bit = ElementTimes(it, Tanh( G2 ));
Wcfdc = DiagTimes(Wcf, dc);
ft = Sigmoid( Plus (G3, Wcfdc));
bft = ElementTimes(ft, dc);
ct = Plus(bft, bit);
Wcoct = DiagTimes(Wco, ct);
ot = Sigmoid( Plus( G4, Wcoct));
mt = ElementTimes(ot, Tanh(ct));
Wmr = Parameter(outputDim, cellDim, init="uniform", initValueScale=1);
output = Times(Wmr, mt);
]TensorFlow版本
TensorFlow版本的LSTM递归神经网络模型与CNTK版本完全不同。尽管它们所执行的操作符都一样,但TensorFlow的表示方式充分发挥了Python控制流的作用。这个概念模型非常简单。我们创建了一个LSTM单元,并且定义一个“状态”作为此单元的输入,同时也是此单元的输出。伪代码如下所示:
cell = rnn_cell.BasicLSTMCell(lstm_size)
# Initial state of the LSTM memory.
state = tf.zeros([batch_size, lstm.state_size])
for current_batch_of_words in words_in_dataset:
# The value of state is updated after processing each batch of words.
output, state = cell(current_batch_of_words, state)这段摘自教程的伪代码版本很好地反映了图1的内容。折磨人的地方在于微妙细节的处理。记住大部分时间TensorFlow的python代码是在搭建流程图,所以我们需要下一点功夫来绘制用于训练和执行的循环流程图。
这里最大的挑战在于如何在一个循环内创建并重复使用权重矩阵和偏置向量。CNTK使用了“PastValue”操作符来创建所需的循环。TensorFlow则使用了上面提到的所谓递归机制,和一个非常聪明的变量保存和调用机制来完成同样的任务。“PastValue”在TensorFlow中对应的是一个函数, tf.get_variable( “name”, size, initializer = None) ,它的行为取决于当前变量域中的“reuse”这个标志位。如果reuse==False而且在当时不存在其它的同名变量,那么get_variable 用那个变量名返回一个新的变量,并用初始化器对其初始化。否则将会返回错误。如果reuse == True,那么get_variable返回之前已经存在的那个变量。如果不存在这样的变量,则返回一个错误。
为了演示这种用法,以下是TensorFlow的一个函数的简化版本,用来创建上面等式一的sigmoid函数。它只是W*x+b 的一个演化版本,其中x是一个list[a,b,c,…]
def linear(args, output_size, scope=None):
#Linear map: sum_i(args[i] * W[i]), where W[i] is a variable.
with vs.variable_scope(scope):
matrix = vs.get_variable("Matrix", [total_arg_size, output_size])
res = math_ops.matmul(array_ops.concat(1, args), matrix)
bias_term = vs.get_variable(
"Bias", [output_size],
initializer=init_ops.constant_initializer(1.))
return res + bias_term接下来定义BasicLSTMCell,大致的写法如下所示。(想要查看这些函数的完整版本,请前往TensorFlow Github代码库里的rnn_cell.py脚本。)
class BasicLSTMCell(RNNCell):
def __call__(self, inputs, state, scope=None):
with vs.variable_scope(scope):
c, h = array_ops.split(1, 2, state)
concat = linear([inputs, h], 4 * self._num_units)
i, j, f, o = array_ops.split(1, 4, concat)
new_c = c * sigmoid(f) + sigmoid(i) * tanh(j)
new_h = tanh(new_c) * sigmoid(o)
return new_h, array_ops.concat(1, [new_c, new_h])你可以看到,这里相当准确地再现图3中的图示。你会注意到上面的split操作符正是对应于CNTK的row slice操作符。
现在我们可以创建一个可以用于训练的递归神经网络模型,在同样的变量域我们能用共享的W和b变量创建另一个网络模型用于测试。具体的做法在TensorFlow的递归神经网络教程ptb_word_lm.py脚本中有介绍。还有两点值得留意。(应该说它们对于我理解这个例子,有着至关重要的作用)他们创建一个lstmModel类来训练和测试网络模型。
class lstmModel:
def __init__(self, is_training, num_steps):
self._input_data = tf.placeholder(tf.int32, [batch_size, num_steps])
self._targets = tf.placeholder(tf.int32, [batch_size, num_steps])
cell = rnn_cell.BasicLSTMCell(size, forget_bias=0.0)
outputs = []
states = []
state = self._initial_state
with tf.variable_scope("RNN"):
for time_step in range(num_steps):
if time_step > 0:
tf.get_variable_scope().reuse_variables()
(cell_output, state) = cell(inputs[:, time_step, :], state)
outputs.append(cell_output)
states.append(state)
… many details omitted …我们在主程序中创建一个训练实例和一个测试实例,并调用它们(事实上还要创建一个实例,为了简化过程我暂时先把它忽略)。
with tf.variable_scope("model", reuse=None, initializer=initializer):
m = PTBModel(is_training=True, 20)
with tf.variable_scope("model", reuse=True, initializer=initializer):
mtest = PTBModel(is_training=False, 1)在上述代码中,创建了实例m,初始化设置20步且不用reuse。从初始化这一步你能观察到,在计算流程图中该单元被展开成20个副本,并且在首次迭代后reuse标志置为True,此时所有的实例都将共享同一组W和b。训练过程在这个展开的版本上完成。第二个版本mtest设置reuse=True,且在图中只有该单元的一个实例。但是变量域和m相同,因此它与m共享同一组训练得到的变量。
一旦训练完成,我们可以用一个内核来调用这个网络模型。
cost, state = sess.run([mtest.cost, mtest.final_state],
{mtest.input_data: x,
mtest.targets: y,
mtest.initial_state: state})x和y是输入变量。这和教程示例中的完整过程相去甚远。举个例子,我完全没有深入到训练过程的细节中去,完整的示例使用了stacked LSTM并设置了dropout的比例。我的希望是,我在此罗列的细节将有助于读者了解代码的最基本结构。
总结
我对两个系统的编程模型做了比较。这里是一些顶层的想法。
-
TensorFlow和CNTK在卷积神经网络那个简单例子中的做法非常相似。然而,我发现tensorflow版本更容易进行实验,因为它是由Python驱动的。我能用IPython notebook加载它并做一些其它尝试。而CNTK则需要用户完全理解如何用配置文件表达想法。我觉得这很困难。我用TensorFlow能很容易写一个简单的k-means聚类算法(详见我之前关于TensorFlow的文章)。我却无法用CNTK来实现,不过这可能是由于我的无知,而不是CNTK的局限性。如果有人能提示我该怎么做,我会很感激的)。
-
在LSTM递归神经网络的例子里,我发现CNTK的版本相当的透明。我发现TensorFlow版本的顶层想法非常优雅,但我也发现想了解它的所有细节却非常困难,因为涉及到了变量作用域和变量共享的巧妙用法。我不得不深入地了解它的工作原理。但到现在我也不是十分清楚!我在TensorFlow版本里确实发现了一个微小但很容易修复的bug,而且我不相信变量作用域和reuse标志是解决封装问题的最好方法。但是TensorFlow的好处在于我能很容易地修改实验。
-
我也必须说CNTK书和TensorFlow教程都是优秀入门级读物。我相信有更多详细的、深入的书马上就会面世。
我也相信,随着两个系统的不断成熟,它们都会有改进,并且能更容易地使用。我在此不讨论性能问题,但CNTK目前在解决某些挑战难题的速度方面略胜一筹。但随着这些系统的快速发展,我希望看到竞争也随之升温。