重学数据结构系列之——八大排序算法
一、有一种分类
稳定排序:如果线性表中的两个元素 ai 和 aj 满足 i < j 且 ai = aj ,那么这两个元素在排序在经过稳定排序以后 ai 一定在 aj 的前面。(简单来说就是排序前有两个或多个相等的元素,排序后他们的相对位置不会改变)
不稳定排序:不是上面的情况就是了
注:下面的默认都是升序排序,时间复杂度都是最坏情况
以下排序使用的“框架"(只要把下面的sort函数具体实现不同的排序算法就行)
#include <iostream>
#include <cstring>
using namespace std;
class Vector {
private:
int size, length;
int * data, *temp;
public:
Vector(int input_size) {
size = input_size;
length = 0;
data = new int[size];
temp = new int[size];
}
~Vector() {
delete[] data;
delete[] temp;
}
bool insert(int loc, int value) {
if (loc < 0 || loc > length) {
return false;
}
if (length >= size) {
return false;
}
for (int i = length; i > loc; --i) {
data[i] = data[i - 1];
}
data[loc] = value;
length++;
return true;
}
void print() {
for (int i = 0; i < length; ++i) {
if (i > 0) {
cout << " ";
}
cout << data[i];
}
cout << endl;
}
void sort(){
}
};
int main() {
int n;
cin >> n;
Vector arr(n);
for (int i = 0; i < n; ++i) {
int x;
cin >> x;
arr.insert(i, x);
}
arr.sort();
arr.print();
return 0;
}
二、稳定排序算法
1.插入排序
将元素看成左右两部分,左边是已经排好序的,右边是没排好的,从右边取元素插入到左边去,指导右边没排序的没有元素,排序就完成了(注这里的插入可以与前面的逐个比较,交换位置,也可以通过二分查找优化)
代码实现
//插入排序
void sort() {
//外层循环从0到长度
for (int i = 0; i < length; i++) {
//内层循环就从i的前一个到0(因为i的前一个是已经排好序的【第一个的前一个就不用管了】,所以,我们的第i个要跟前i-1个逐一比较交换,直到位置合适[看下面])
for (int j = i -1; j >= 0; j--) {
//如果前面的大于后面就交换,这样才会升序排列嘛
if (data[j] > data[j+1] ) {
swap(data[j], data[j+1]);
}else{
//否则说明已经在正确的位置上了,退出内层循环,继续插入下一个元素
break;
}
}
}
}时间复杂度:O(n^2) : 外层循环n次 内层循环平均 (1 + 2 +... n -1)/n-1 = n/2 所以总的就是n^2/2, 即O(n^2)
运行一下
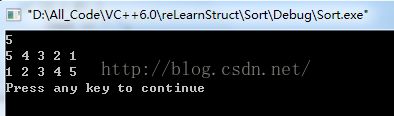
下面的就不截图了,都是运行测试过的,代码有什么问题欢迎提出,谢谢。
2.冒泡排序
一般如果升序的话:相邻两个元素进行比较,如果第一个大于第二个,则进行交换,直到全部比较交换完成,最后的一个元素肯定是最大的元素,那么下一轮就不加入下一轮交换了
代码实现
//冒泡排序
void sort(){
//外层循环是为内层服务的,就是j < length - i -1,也就是从i=1时,内层循环条件是j<length-1,到最后i=length-2,内层循环条件是j<1
for (int i = 0; i < length - 1; i++) {
for (int j = 0; j < length - i -1; j++ ) {
if (data[j] > data[j+1]) {
swap(data[j], data[j+1]);
}
}
}
}
时间复杂度:O(n^2),计算方法跟上面类似
void sort() {
for (int i = 0; i < length - 1; i++) {
bool swapped = false;
for (int j = 0; j < length - i -1; j++ ) {
if (data[j] > data[j+1]) {
swap(data[j], data[j+1]);
swapped = true;
}
}
if(swapped == false){
break;
}
}
}
3.归并排序
首先可以两个两个一组,比如a[0]和a[1]一组,a[2]和a[3]一组,将a[0]和a[1],a[2]和a[3],分别排好序,
跟着将a[0]和a[1]跟a[2]和a[3]排序,出来a[0],a[1],a[2],a[3]一个有序的序列,以此类推,直到归并到线性表的长度为止
代码实现
void sort(){
merge_sort(0, length-1);
}类里加下面这个成员函数(私有成员比较安全)
//l:left,要排序的左端点
//r:right,要排序的右端点
void merge_sort(int l, int r){
//如果左等于右,说明每个区间只剩1个元素了,排序完成,直接返回
if (l == r) {
return;
}
//计算中间的索引,进行二分
int mid = (l + r) /2;
//递归调用,排序范围:左端点到中点
merge_sort(l, mid);
//递归调用,排序范围:中点到右端点
merge_sort(mid+1, r);
//x:记录左边的处理到哪个元素了,初始化为左端点
//y:记录右边的处理到哪个元素了,初始化为中间+1
//loc:记录临时保存数据的数组的索引位置(这个数组就是左右排序后的结果)
int x = l, y = mid + 1, loc = l;
//循环条件:左边和右边的元素都没处理完,即x小于等于中间,y小于等于右端点
while (x <= mid || y <= r) {
//若x小于等于中间,且(y>r:右边处理完了 或 左边的数据小于右边对应的数据)
if (x <= mid && (y > r || data[x] <= data[y])) {
//将x对应的数据放到临时数组的对应位置
temp[loc] = data[x];
//位置后移
x++;
}else{
//否则,其实条件就是 x>mid或者(y<=r且data[x]>data[y])
temp[loc] = data[y];
//位置后移
y++;
}
//临时数组位置后移
loc++;
}
//将结果覆盖到原数组
for (int i = l; i <= r; i++) {
data[i] = temp[i];
}
}时间复杂度:O(nlogn), 因为他像二叉树一样排序分治了,需要logn层归并操作,每层还是要O(n)
4.基数排序
基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位上的数分别比较分类(形象地说就是分到0-9,共10个桶中),直到进行到最大值的最高位。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数(反正基本都是特殊的情况)
代码实现
int maxbit() //辅助函数,求数据的最大位数
{
int d = 1; //保存最大的位数,初始化为1
int p = 10; // 每次乘以10就是百,千,万......
for(int i = 0; i < length-1; ++i)
{
while(data[i] >= p)
{
p *= 10;
++d;
}
}
return d;
}
//基数排序
void sort()
{
int d = maxbit();
int *tmp = new int[length];
int *count = new int[10]; //计数器
int i, j, k;
int radix = 1; //基数,用于获取对应位的数的大小
for(i = 1; i <= d; i++) //最大的位数为d,所以进行d次排序
{
//每次分配前清空计数器
for(j = 0; j < 10; j++)
count[j] = 0;
//统计每个桶(即对应为是0到9)中的记录数,即那个位是0的有多少,是1的有多少........
for(j = 0; j < length; j++) {
k = (data[j] / radix) % 10;
count[k]++;
}
//根据记录数算出,第i个桶的右边界索引,这里的索引值比数组的索引大了1,所以下一个for循环是tmp[count[k] - 1]
//比如个位的时候,个位为0 的右边界是count[0],个位为1的右边界就是count[0]+count[1]【因为count只是计数,加上前面的才能知道自己在数组的右边界】
for(j = 1; j < 10; j++)
count[j] = count[j - 1] + count[j];
//根据上面的边界索引将记录依次收集到tmp数组中
//因为count[k]是右边界,所以我们从后往前处理
for(j = length - 1; j >= 0; j--) {
k = (data[j] / radix) % 10;
tmp[count[k] - 1] = data[j];
count[k]--;
}
//临时数组内容提取到原数组中
for(j = 0; j < length; j++)
data[j] = tmp[j];
//下次循环上升一个位
radix = radix * 10;
}
//释放内存
delete[]tmp;
delete[]count;
}
二、不稳定排序算法
1.选择排序
每次都把自己及右边范围内的最小值放在自己的位置上,通过比较交换来实现
代码实现
//选择排序
void sort(){
//外层循环,可理解为对第i位进行处理,处理结果:data[i]就是第i+1小的(i从0开始嘛因为)
for (int i = 0; i < length -1; i++) {
for (int j = i + 1; j < length; j++) {
//data[i]与后面的不断比较,相当于找到自己及后面的范围内最小值放到data[i]中
if (data[i] > data[j]) {
swap(data[i], data[j]);
}
}
}
}时间复杂度:O(n^2),计算方法跟插入排序类似
2.快速排序
每次选取待排序区间的第一个元素作为基准,将小于基准和大于基准的分为左右两部分,在对左右两部分递归即可
代码实现
//快速排序
void sort(){
quick_sort(0, length-1);
}
类里加下面这个成员函数(私有成员比较安全)
void quick_sort(int l, int r){
//pivot:基准(默认设置为区间的第一个元素的值) i,j:区间的左右两端 (下面处理完成后,j:是小于pivot元素的右端,i:大于pivot元素的左端)
int pivot = data[l], i = l, j = r;
do {
//从最左边开始,找到第一个大于等于基准元素的下标(其实就是基准元素的下标)
//因为大于等于pivot时,循环结束,此时的i即所求的下标
while (i <= j && data[i] < pivot) {
i++;
}
//从最右边开始,找到第一个小于等于基准元素的下标
//因为小于等于pivot时,循环结束,此时的j即所求的下标
while (i <= j && data[j] > pivot ) {
j--;
}
//i<=j说明左边找到了比pivot大,右边比pivot小的元素,交换以分为小于pivot和大于pivot两部分
if (i <= j) {
swap(data[i], data[j]);
i++;
j--;
}
} while(i <= j);
//上面的do while结束,整个区间已经分为小于pivot和大于pivot两部分(i及左边(不包括pivot)就是小于pivot,i的右边就是大于pivot的元素,可以自己画图理解一下)
//若左边小于pivot部分的元素的个数大于1(即l小于j,因为j是小于pivot元素的右端),则递归调用
if (l < j) {
quick_sort(l, j);
}
//若右边大于pivot部分的元素的个数大于1(即r大于i,因为i是大于pivot元素的左端),则递归调用
if (r > i) {
quick_sort(i, r);
}
}
时间复杂度:O(n^2),这个最坏的情况是,每一层递归都是i和j都基本移动n次吧
3.堆排序
代码实现
这个是不稳定排序,看我这篇吧: http://blog.csdn.net/u012763794/article/details/51002372
4.希尔排序(shell sort)
间隔一开始是元素总数的一半,每个元素与间隔gap个的元素比较交换,直至gap间隔”有序“,gap再除以2,再每个元素与间隔gap个的元素比较交换,最后指导gap=0,循环结束
代码实现
//希尔排序
void sort(){
//gap:间隔 swapped:内存循环有无交换过,默认为0,即没有交换
int gap = length/2, swapped;
do{
do{
swapped=0;
//size-gap:这是比较的次数(这里我们看最后一个元素,他应该跟向前面数gap位的元素比较,而向前面数gap位的元素之前的元素都是要比较了,那么其实比较的时候就是后面的gap位不用比较)
//举个例子,size=8,gap=2,位置索引0,1,2,3,4,5的值都是要和向后数2位的依次比较,6的话,+2就是8,超出数组的索引了,所以这例子是后面的gap(2)位,6,7不用比较
for(int i = 0; i < length-gap ; i++){
if(data[i]>data[i+gap])
{
swap(data[i], data[i+gap]);
swapped=1;
}
}
}while(swapped); //若走一趟循环都没有交换过,就说明前半部分都“小于”后半部分(即当前的gap间隔的排序已经“有序”),可以进行下一轮的gap
//为什么同一个gap的排序要可能进行多遍呢,比如 5 2 1 3 4,gap=2,第一次结果时1 2 5 3 4,swapped=1;进行第二次gap=2循环,1 2 4 3 5,这样4,5交换了,再循环就没有交换,swapped=0,进入下一轮gap=2/2= 1的循环了
}while(gap=gap/2);//不断除以2,当gap等于1,除以2就等于0 ,循环结束,(所以gap等于1是最后一次循环)
}