Apache Flink fault tolerance源码剖析(三)
上一篇文章我们探讨了基于定时任务的周期性检查点触发机制以及基于Akka的actor模型的消息驱动协同机制。这篇文章我们将探讨Zookeeper在Flink的Fault Tolerance所起到的作用。
其实,Flink引入Zookeeper的目的主要是让JobManager实现高可用(leader选举)。
因为Zookeeper在Flink里存在多种应用场景,本篇我们还是将重心放在
Fault Tolerance上,即讲解Zookeeper在检查点的恢复机制上发挥的作用。
如果用一幅图表示快照机制(检查点)大致的流程可见下图:
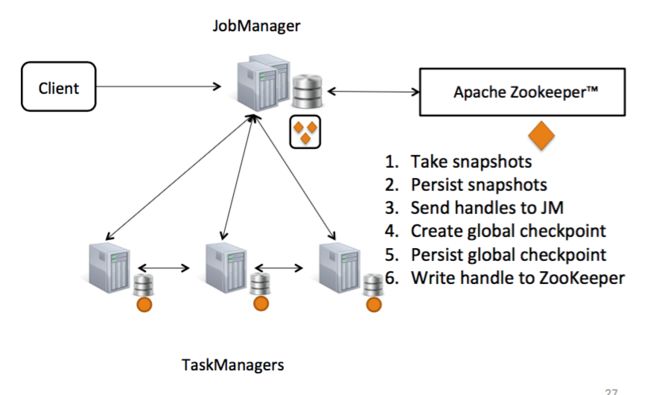
跟本文相关的主要有4,5,6三步
两种恢复模式
因为跟本文切实相关,所以先介绍一下JobManager的RecoveryMode(恢复模式)。RecoveryMode作为一个枚举类型,它有两个枚举值:
- STANDALONE
- ZOOKEEPER
STANDALONE表示不对JobManager的失败进行恢复。而ZOOKEEPER表示JobManager将基于Zookeeper实现HA(高可用)。
两种类型的检查点
在前面的文章中已经提及过Flink里的检查点分为两种:PendingCheckpoint(正在处理的检查点)和CompletedCheckpoint(完成了的检查点)。
PendingCheckpoint表示一个检查点已经被创建,但还没有得到所有该应答的task的应答。一旦所有的task都给予应答,那么它将会被转化为一个CompletedCheckpoint。PendingCheckpoint通过toCompletedCheckpoint实例方法来将其转化为已完成了的检查点。其核心实现如下:
if (notYetAcknowledgedTasks.isEmpty()) {
CompletedCheckpoint completed = new CompletedCheckpoint(jobId, checkpointId,checkpointTimestamp, System.currentTimeMillis(), new ArrayList<StateForTask>(collectedStates));
dispose(null, false);
return completed;
}它会检查还没有ack该检查点的task集合,如果集合为空(即所有task都已应答),则基于当前实例的属性构建一个CompletedCheckpoint的实例,并最终返回新创建的实例。但在返回之前,调用了dispose进行资源释放。
这个dispose方法是一个私有方法,其内部实现依赖于releaseState这个flag,上面的dispose调用将其置为false,意为不释放task状态:
if (releaseState) {
for (StateForTask state : collectedStates) {
state.discard(userClassLoader);
}
}但最终,collectedStates这个集合总是会被清空:
collectedStates.clear();
notYetAcknowledgedTasks.clear();toCompletedCheckpoint方法为什么不释放task的状态呢,因为它的语义只是提供转化操作,其实collectedStates这个集合已经在构造CompletedCheckpoint时被深拷贝给CompletedCheckpoint的实例了。而这些task的状态其最终的释放,将会由CompletedCheckpoint的discard方法完成。
PendingCheckpoint的公共的discard方法的实现就会直接释放收集的状态集合:
public void discard(ClassLoader userClassLoader) {
dispose(userClassLoader, true);
}公共的discard方法常用于检查点超时回收以及当最新的检查点已经完成时,距离当前时间更久的未完成的检查点的自动失效。
CompletedCheckpoint表示一个已经成功完成了得检查点,当一个检查点在得到所有要求的task的应答之后被认为是一个已完成的检查点。
已完成的检查点的存储
根据JobManager的恢复模式,Flink提供了两种已完成的检查点的存储机制的实现:
- StandaloneCompletedCheckpointStore
- ZooKeeperCompletedCheckpointStore
他们都实现了接口CompletedCheckpointStore,这个接口提供了思个值得关注的方法:
- recover :用于恢复可访问的检查点
CompletedCheckpoint的实例 - addCheckpoint :将已完成的检查点加入到检查点集合
- getLatestCheckpoint :获得最新的检查点
- discardAllCheckpoints : 回收所有的已完成的检查点
针对RecoveryMode为STANDALONE提供了StandaloneCompletedCheckpointStore。它提供了一个基于JVM堆内存的ArrayDeque来存放检查点。
而针对RecoveryMode为ZOOKEEPER提供的ZooKeeperCompletedCheckpointStore要复杂得多。这也是我们关注的重点。它的实现依赖于两个存储机制:
在Zookeeper中的分布式存储:
private final ZooKeeperStateHandleStore<CompletedCheckpoint> checkpointsInZooKeeper;本地JVM内存中的存储:
private final ArrayDeque<Tuple2<StateHandle<CompletedCheckpoint>, String>> checkpointStateHandles;我们先来看恢复方法recover,恢复的过程首先是从Zookeeper获取所有的检查点,这里为了规避并发修改带来的失败,采用了循环重试的机制:
while (true) {
try {
initialCheckpoints = checkpointsInZooKeeper.getAllSortedByName();
break;
}
catch (ConcurrentModificationException e) {
LOG.warn("Concurrent modification while reading from ZooKeeper. Retrying.");
}
}在恢复时,将从Zookeeper中读取最新的检查点,如果检查点超过一个,仅仅最新的那个检查点有效,旧的都会被丢弃。如果存在着网络分区,多个JobManager的实例并发对相同的程序实行检查点,那么选择任意一个验证通过的已完成的检查点都是没有问题的。
if (numberOfInitialCheckpoints > 0) {
// Take the last one. This is the latest checkpoints, because path names are strictly
// increasing (checkpoint ID).
Tuple2<StateHandle<CompletedCheckpoint>, String> latest = initialCheckpoints
.get(numberOfInitialCheckpoints - 1);
CompletedCheckpoint latestCheckpoint = latest.f0.getState(userClassLoader);
checkpointStateHandles.add(latest);
LOG.info("Initialized with {}. Removing all older checkpoints.", latestCheckpoint);
for (int i = 0; i < numberOfInitialCheckpoints - 1; i++) {
try {
removeFromZooKeeperAndDiscardCheckpoint(initialCheckpoints.get(i));
}
catch (Exception e) {
LOG.error("Failed to discard checkpoint", e);
}
}
}而discardAllCheckpoints方法会做四件事:
- 迭代每个检查点,将其从Zookeeper中移除
- discard每个已完成的检查点
- discard每个存储的状态
- 将本地集合清空掉
检查点编号计数器
每个检查点都有各自的编号,为Long类型。根据JobManager的恢复模式分别提供了两种计数器:
- StandaloneCheckpointIDCounter
- ZooKeeperCheckpointIDCounter
计数器在这里被认为是一种服务,它具备
start和stop方法
StandaloneCheckpointIDCounter 只是简单得对 AtomicLong进行了包装,因为在这种模式下,JobManager几乎是不可恢复的,所以这么做就足够了。
ZooKeeperCheckpointIDCounter是基于Zookeeper实现的一种分布式原子累加器。具体的做法是每一个计数器,在Zookeeper上新建一个ZNode,形如:
/flink/checkpoint-counter/<job-id> 1 [persistent]
....
/flink/checkpoint-counter/<job-id> N [persistent]在Zookeeper中的检查点编号被要求是升序的,这可以使得我们在JobManager失效的情况下,可以拥有一个共享的跨JobManager实例的计数器。
值得一提的是,这里使用的Zookeeper的客户端是CuratorFramework,同时还利用了它附带的SharedCount这一recipes来作为分布式共享的计数器。
而在累加接口方法getAndIncrement的实现上,使用了循环尝试的机制:
public long getAndIncrement() throws Exception {
while (true) {
ConnectionState connState = connStateListener.getLastState();
if (connState != null) {
throw new IllegalStateException("Connection state: " + connState);
}
VersionedValue<Integer> current = sharedCount.getVersionedValue();
Integer newCount = current.getValue() + 1;
if (sharedCount.trySetCount(current, newCount)) {
return current.getValue();
}
}
}另外从stop方法的实现来看,如果一个计数器停止,则会再Zookeeper中删除其对应的ZNode。
检查点恢复服务
所谓的检查点恢复服务,其实就是聚合了上面的已完成的检查点存储以及检查点编号计数器这两个功能。因为Flink提供了STANDALONE以及ZOOKEEPER这两个恢复模式,所以这里存在一个基于不同模式创建服务的工厂接口CheckpointRecoveryFactory。并针对这两种恢复模式分别提供了两个工厂:StandaloneCheckpointRecoveryFactory以及ZooKeeperCheckpointRecoveryFactory。
具体的功能聚合体现在这两个方法上:
/** * Creates a {@link CompletedCheckpointStore} instance for a job. * * @param jobId Job ID to recover checkpoints for * @param userClassLoader User code class loader of the job * @return {@link CompletedCheckpointStore} instance for the job */
CompletedCheckpointStore createCompletedCheckpoints(JobID jobId, ClassLoader userClassLoader)
throws Exception;
/** * Creates a {@link CheckpointIDCounter} instance for a job. * * @param jobId Job ID to recover checkpoints for * @return {@link CheckpointIDCounter} instance for the job */
CheckpointIDCounter createCheckpointIDCounter(JobID jobId) throws Exception;两个工厂的具体实现并没有什么特别的地方。检查点恢复服务会被JobManager使用到。
小结
本篇文章我们主要分析了,Zookeeper在Flink的Fault Tolerance机制中发挥的作用。但因为Zookeeper在Flink中得主要用途是实现JobManager的高可用,所以里面的部分内容多少还是跟这一主题有所联系。
微信扫码关注公众号:Apache_Flink

QQ扫码关注QQ群:Apache Flink学习交流群(123414680)
