深度学习入门笔记(四):向量化
专栏——深度学习入门笔记
声明
1)该文章整理自网上的大牛和机器学习专家无私奉献的资料,具体引用的资料请看参考文献。
2)本文仅供学术交流,非商用。所以每一部分具体的参考资料并没有详细对应。如果某部分不小心侵犯了大家的利益,还望海涵,并联系博主删除。
3)博主才疏学浅,文中如有不当之处,请各位指出,共同进步,谢谢。
4)此属于第一版本,若有错误,还需继续修正与增删。还望大家多多指点。大家都共享一点点,一起为祖国科研的推进添砖加瓦。
文章目录
- 专栏——深度学习入门笔记
- 声明
- 深度学习入门笔记(四):向量化
- 1、向量化
- 2、深入理解向量化
- 3、向量化逻辑回归
- 4、向量化逻辑回归的梯度输出
- 推荐阅读
- 参考文章
深度学习入门笔记(四):向量化
1、向量化
向量化 是非常基础的去除代码中 for 循环的艺术。为什么要去除 for 循环?
当在深度学习安全领域、深度学习实践中应用深度学习算法时,会发现在代码中显式地使用 for 循环使算法很低效,同时在深度学习领域会有越来越大的数据集,因为深度学习算法处理大数据集效果很棒,所以代码运行速度非常重要,否则如果在大数据集上,代码可能花费很长时间去运行,你将要等待非常长的时间去得到结果。所以算法能应用且没有显式的 for 循环是很重要的,并且会帮助你适用于更大的数据集。所以在深度学习领域这里有一项叫做向量化的技术,是一个关键的技巧,它可以允许你的代码摆脱这些显式的 for 循环,举个栗子说明什么是向量化。
在逻辑回归中,需要去计算 z = w T x + b z={{w}^{T}}x+b z=wTx+b,其中 w w w、 x x x 都是列向量。如果有很多的特征,那么就会有一个非常大的向量,所以 w ∈ R n x w\in {{\mathbb{R}}^{{{n}_{x}}}} w∈Rnx , x ∈ R n x x\in{{\mathbb{R}}^{{{n}_{x}}}} x∈Rnx,那么如果想使用非向量化方法去计算 w T x {{w}^{T}}x wTx,就需要用如下方式(基于 python 编程实现):
z = 0
for i in range(n_x):
z += w[i] * x[i]
z += b
这是一个非向量化的实现,实践之后,你会发现这个是真的很慢,,,作为对比,向量化的实现将会非常直接计算 w T x {{w}^{T}}x wTx,代码如下:
z = np.dot(w, x) + b
这是向量化方式进行计算 w T x {{w}^{T}}x wTx 的方法,你会发现这个非常快,尤其是对比之前的非向量化的实现。
让我们用一个小例子说明一下,在我的我将会写一些代码(以下为教授在他的Jupyter notebook上写的Python代码,)
import time # 导入时间库
import numpy as np # 导入numpy库
a = np.array([1, 2, 3, 4]) # 创建一个数据a
print(a)
# [1 2 3 4]
a = np.random.rand(1000000)
b = np.random.rand(1000000) # 通过round随机得到两个一百万维度的数组
tic = time.time() # 现在测量一下当前时间
# 向量化的版本
c = np.dot(a, b)
toc = time.time()
print("Vectorized version:" + str(1000 * (toc - tic)) + "ms") # 打印一下向量化的版本的时间
# 继续增加非向量化的版本
c = 0
tic = time.time()
for i in range(1000000):
c += a[i] * b[i]
toc = time.time()
print(c)
print("For loop:" + str(1000 * (toc - tic)) + "ms") # 打印for循环的版本的时间
运行结果见下图:
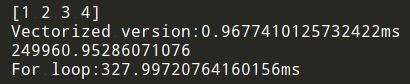
在上面的代码中,使用两个方法——向量化和非向量化,计算了相同的值,其中向量化版本花费了0.968毫秒,而非向量化版本的 for 循环花费了327.997毫秒,大概是300多倍,准确倍数是 338.840 倍。仅仅在这个自己举的例子中,都可以明显看到效果。这意味着如果向量化方法需要花费一分钟去运行的数据,使用 for 循环将会花费5个小时去运行。
一句话总结,向量化快!!!
2、深入理解向量化
通过 numpy内置函数 和 避开显式的循环(loop) 的方式进行向量化,从而有效提高代码速度。根据经验,在写神经网络程序时,或者在写 逻辑(logistic)回归 时,或者在写其他神经网络模型时,应该避免写 循环(loop) 语句。虽然有时写 循环(loop) 是不可避免的,但是如果可以使用其他办法去替代计算,程序效率总是更快。
来看另外一个例子。如果想计算向量 u = A v u=Av u=Av,这时根据矩阵乘法的定义,有 u i = ∑ j A ij v i u_{i} =\sum_{j}^{}{A_{\text{ij}}v_{i}} ui=∑jAijvi。
- 非向量化方法:用 u = n p . z e r o s ( n , 1 ) u=np.zeros(n,1) u=np.zeros(n,1), 然后通过两层循环 f o r ( i ) : f o r ( j ) : for(i): for(j): for(i):for(j):,可以得到:
u [ i ] = u [ i ] + A [ i ] [ j ] ∗ v [ j ] u[i]=u[i]+A[i][j]*v[j] u[i]=u[i]+A[i][j]∗v[j]
- 向量化方法:用 u = n p . d o t ( A , v ) u=np.dot(A,v) u=np.dot(A,v)
吴恩达老师手写稿如下:

下面通过另一个例子继续了解向量化。如果有一个向量 v v v,并且想要对向量 v v v 的每个元素做指数操作。
- 非向量化方法:初始化向量 u = n p . z e r o s ( n , 1 ) u=np.zeros(n,1) u=np.zeros(n,1),然后通过循环依次计算每个元素 v i v^{i} vi
- 向量化方法:通过 python 的 numpy 内置函数,执行 u = n p . e x p ( v ) u=np.exp(v) u=np.exp(v) 命令
numpy 库有很多向量函数,比如 u=np.log 是按元素计算对数函数( l o g log log)、 np.abs() 是按元素计算数据的绝对值函数、np.maximum(v, 0) 是按元素计算 v v v 中每个元素和和0相比的最大值,v**2 是按元素计算元素 v v v 中每个值的平方、 1/v 是按元素计算 v v v 中每个元素的倒数等等。
PS:当想写循环时,检查 numpy 是否存在类似的内置函数。
吴恩达老师手写稿如下:

希望你现在有一点向量化的感觉了,减少一层循环可以使代码更快一些!!!
3、向量化逻辑回归
如何实现逻辑回归的向量化计算?只要实现了,就能处理整个数据集了,甚至不会用一个明确的 for 循环,听起来是不是特别地 inspiring。
先回顾一下逻辑回归的前向传播,现有 m m m 个训练样本,然后对第一个样本进行预测, z ( 1 ) = w T x ( 1 ) + b z^{(1)}=w^{T}x^{(1)}+b z(1)=wTx(1)+b;激活函数 a ( 1 ) = σ ( z ( 1 ) ) a^{(1)}=\sigma (z^{(1)}) a(1)=σ(z(1));计算第一个样本的预测值 y y y。然后对第二个样本进行预测,第三个样本,依次类推。。。如果有 m m m 个训练样本,可能需要这样重复做 m m m 次。可不可以不用任何一个明确的 for 循环?
首先,定义一个 n x n_x nx 行 m m m 列的矩阵 X X X 作为训练输入(如下图中蓝色 X X X),numpy 形式为 ( n x , m ) (n_{x}, m) (nx,m)。
吴恩达老师手稿如下:

前向传播过程中,如何计算 z ( 1 ) z^{(1)} z(1), z ( 2 ) z^{(2)} z(2), ……一直到 z ( m ) z^{(m)} z(m)?构建一个 1 × m 1\times m 1×m 的行向量用来存储 z z z,这样可以让所有的 z z z 值都同一时间内完成。实际上,只用了一行代码。即 [ z ( 1 ) , z ( 2 ) , . . . , z ( m ) ] = w T X + [ b , b , . . . , b ] = [ w T x ( 1 ) + b , w T x ( 2 ) + b . . . w T x ( m ) + b ] [z^{(1)}, z^{(2)}, ..., z^{(m)}]=w^{T}X+[b, b, ..., b]=[w^{T}x^{(1)}+b,w^{T}x^{(2)}+b...w^{T}x^{(m)}+b] [z(1),z(2),...,z(m)]=wTX+[b,b,...,b]=[wTx(1)+b,wTx(2)+b...wTx(m)+b]。为什么 w w w 要转置呢?
希望你尽快熟悉矩阵乘法,因为矩阵乘法的要求中有一条是,两个矩阵相乘,左面矩阵的列数需要等于右面矩阵的行数, X X X 也是 ( n x , m ) (n_{x}, m) (nx,m), w w w 也是 ( n x , 1 ) (n_{x}, 1) (nx,1),而 w T w^T wT 是 ( 1 , n x ) (1, n_{x}) (1,nx),正好符合 w T X + b w^T X + b wTX+b 的公式,且保证了矩阵乘法的条件。其中 w T x ( 1 ) + b w^{T}x^{(1)}+b wTx(1)+b 这是第一个元素, w T x ( 2 ) + b w^{T}x^{(2)}+b wTx(2)+b 这是第二个元素, …, w T x ( m ) + b w^{T}x^{(m)}+b wTx(m)+b 这是第 m m m 个元素。分别与 z ( 1 ) z^{(1)} z(1), z ( 2 ) z^{(2)} z(2), …对应。所以, X X X 是一次获得的一次获得全部。
但是细心的你会发现,为了计算 w T X + [ b , b , . . . , b ] w^{T}X+[b, b, ..., b] wTX+[b,b,...,b],使用 numpy 命令 Z = n p . d o t ( w . T , X ) + b Z=np.dot(w.T,X)+b Z=np.dot(w.T,X)+b。这里有一个巧妙的地方, n p . d o t ( w . T , X ) np.dot(w.T,X) np.dot(w.T,X) 是一个 1 × m 1\times m 1×m 的矩阵,而 b b b 是一个实数,或者可以说是一个 1 × 1 1\times 1 1×1 的矩阵,那么如何把一个向量加上一个实数?
这里简单说一下:Python 自动地把实数 b b b 扩展成一个 1 × m 1\times m 1×m 的行向量,只有这样才能进行矩阵相加(矩阵相加需要两个矩阵等大小)。这个操作似乎有点不可思议,它在 Python 中被称作 广播(brosdcasting),目前你不用对此感到顾虑,这在博客——深度学习入门笔记(五):神经网络的编程基础中会详细讲解!
现在说一下字母规范:大写的 Z Z Z 是一个包含所有小写 z ( 1 ) z^{(1)} z(1) 到 z ( m ) z^{(m)} z(m) 的 1 × m 1\times m 1×m 的矩阵,而大写 A A A 则是包含所有小写 a ( 1 ) a^{(1)} a(1) 到 a ( m ) a^{(m)} a(m) 的 1 × m 1\times m 1×m 的矩阵。
简单小结一下,不要 for 循环,利用 m m m 个训练样本使用向量化的方法,一次性计算出 Z Z Z 和 A A A。
Z = w T X + b Z = w^TX + b Z=wTX+b
A = σ ( Z ) A=\sigma (Z) A=σ(Z)
4、向量化逻辑回归的梯度输出
注:本节中大写字母代表向量,小写字母代表元素
如何 同时 计算 m m m 个数据的梯度,并且实现一个非常高效的 逻辑回归算法(Logistic Regression) ?
之前在讲梯度计算的时候(深度学习入门笔记(二):神经网络基础),列举过几个例子, d z ( 1 ) = a ( 1 ) − y ( 1 ) dz^{(1)}=a^{(1)}-y^{(1)} dz(1)=a(1)−y(1), d z ( 2 ) = a ( 2 ) − y ( 2 ) dz^{(2)}=a^{(2)}-y^{(2)} dz(2)=a(2)−y(2), ……等等一系列类似公式。不过当时是单样本数据计算,现在对 m m m 个数据做同样的计算,可以照着上一章讲过的,定义一个新的变量 d Z = [ d z ( 1 ) , d z ( 2 ) . . . d z ( m ) ] dZ=[dz^{(1)} ,dz^{(2)} ... dz^{(m)}] dZ=[dz(1),dz(2)...dz(m)],每一个样本的 d z dz dz 横向排列,就可以得到一个 1 × m 1\times m 1×m 的 d Z dZ dZ 矩阵了。
A = [ a ( 1 ) , a ( 2 ) , . . . , a ( m ) ] A=[a^{(1)},a^{(2)}, ..., a^{(m)}] A=[a(1),a(2),...,a(m)] 我们已经知道计算方法了,那么就差一个 Y = [ y ( 1 ) , y ( 2 ) , . . . , y ( m ) ] Y=[y^{(1)}, y^{(2)}, ..., y^{(m)}] Y=[y(1),y(2),...,y(m)],然后就可以计算 d Z = A − Y = [ a ( 1 ) − y ( 1 ) , a ( 2 ) − y ( 2 ) , . . . , a ( m ) − y ( m ) ] dZ=A-Y=[a^{(1)}-y^{(1)}, a^{(2)}-y^{(2)}, ..., a^{(m)}-y^{(m)}] dZ=A−Y=[a(1)−y(1),a(2)−y(2),...,a(m)−y(m)],刚好分别对应 d z ( 1 ) dz^{(1)} dz(1), d z ( 2 ) dz^{(2)} dz(2),……
开始向量化逻辑回归的梯度输出:
首先是
d b = 1 m ∑ i = 1 m d z ( i ) db=\frac{1}{m}\sum_{i=1}^{m}dz^{(i)} db=m1i=1∑mdz(i)
向量化代码如下:
d b = 1 m ∗ n p . s u m ( d Z ) db=\frac{1}{m}*np.sum(dZ) db=m1∗np.sum(dZ)
接下来是
d w = 1 m ∗ X ∗ d z T dw=\frac{1}{m}*X*dz^{T} dw=m1∗X∗dzT
其中, X X X 是一个行向量。因此展开后是
d w = 1 m ∗ ( x ( 1 ) d z ( 1 ) + x ( 2 ) d z ( 2 ) + . . . + x m d z m ) dw=\frac{1}{m}*(x^{(1)}dz^{(1)}+x^{(2)}dz^{(2)}+...+x^{m}dz^{m}) dw=m1∗(x(1)dz(1)+x(2)dz(2)+...+xmdzm)
向量化代码如下:
d b = 1 m ∗ n p . s u m ( d Z ) db=\frac{1}{m}*np.sum(dZ) db=m1∗np.sum(dZ)
d w = 1 m ∗ X ∗ d z T dw=\frac{1}{m}*X*dz^{T} dw=m1∗X∗dzT
这样,就避免了在训练集上使用 for 循环。对比之前实现的逻辑回归,可以发现,没有向量化是非常低效的,代码量还多。。。
翻新后的计算如下:
Z = w T X + b = n p . d o t ( w . T , X ) + b Z = w^{T}X + b = np.dot( w.T,X)+b Z=wTX+b=np.dot(w.T,X)+b
A = σ ( Z ) A = \sigma( Z ) A=σ(Z)
d Z = A − Y dZ = A - Y dZ=A−Y
d w = 1 m ∗ X ∗ d z T {{dw} = \frac{1}{m}*X*dz^{T}\ } dw=m1∗X∗dzT
d b = 1 m ∗ n p . s u m ( d Z ) db= \frac{1}{m}*np.sum( dZ) db=m1∗np.sum(dZ)
w : = w − a ∗ d w w: = w - a*dw w:=w−a∗dw
b : = b − a ∗ d b b: = b - a*db b:=b−a∗db
前五个公式完成了前向和后向传播,后两个公式进行梯度下降更新参数。
最后的最后,终于得到了一个高度向量化的、非常高效的逻辑回归的梯度下降算法,是不是?
推荐阅读
- 深度学习入门笔记(一):深度学习引言
- 深度学习入门笔记(二):神经网络基础
- 深度学习入门笔记(三):求导和计算图
参考文章
- 吴恩达——《神经网络和深度学习》视频课程