【论文笔记】物体检测系列 Light-Head R-CNN: In Defense of Two-Stage Object Detector
文章:https://arxiv.org/abs/1711.07264v1
这篇文章是旷视科技和清华大学联合出品的,主要是对其今年在COCO检测竞赛上的部分成果分享。他们总共拿下了 COCO Detection/Segmentation Challenge(检测/分割)、COCO Keypoint Challenge(人体关键点检测)、Places Instance Segmentation(实体分割)三个项目的冠军,也出了三篇论文,这是其中一篇。
文章题目起的不错,叫做守护二阶段物体检测器的尊严。那么是怎么守护的呢,让我们来研究一下。
1. 为什么two-stage比one-stage慢?
原因是Heavy Head. 对于每一个ROI进行计算的子网络很大,导致即使backbone再怎么变化去选用轻量级的网络,也并不会对速度有很大的提升。
作者举了两个two-stage物体检测器的例子:Faster R-CNN和R-FCN。
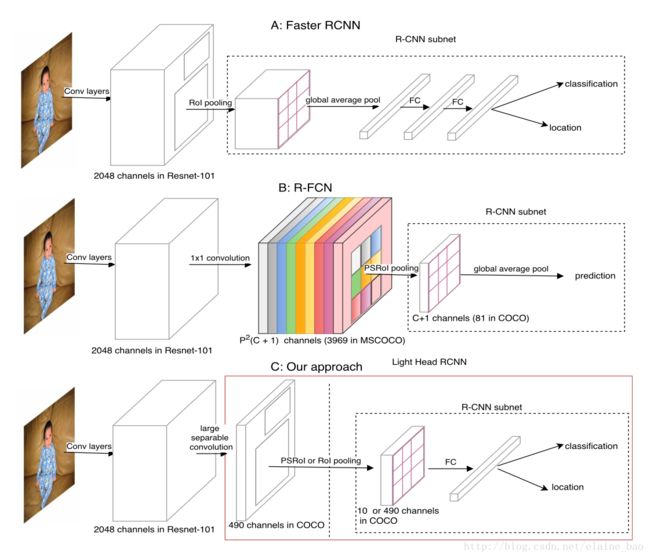
如上图。Faster-RCNN在ROI Pooling以后要对每个ROI做的计算,也就是R-CNN subnet,这部分包括两个FC层,且第一个FC层要全连接上一层的全部channel,比如resnet101在上一层有2048个channel,这个计算量就很大了。所以说ROI-wise部分的计算太重了。
R-FCN为了对ROI-wise subnet进行加速,就采用了一种全卷积的策略。它在输入ROI Pooling(确切地说是Position Sensitive ROI Pooling,PSROI Pooling)之前生成了一个 W∗H∗[P2(C+1)] 大小的的feature map,其中channel数为 P2(C+1) ,C表示物体检测的类别数,+1表示背景类。这个channel数是为了在经过PSROI Pooling以后展开直接得到P*P*(C+1)大小的feature map,这样直接经过global average pooling就可以预测每个类别的概率了。这段没有看懂的同学可以参考我详细写R-FCN的博客:【论文笔记】物体检测系列 R-FCN: Object Detection via Region-based Fully Convolutional Networks。那么R-FCN采用这种方式,它的R-CNN subnet其实是没有计算量的(但是这样没有ROI-wise计算层,也会导致R-FCN的精度没有R-CNN高),但是它的计算量也很明显,就是在生成 W∗H∗[P2(C+1)] 这么大的feature map的时候,所以总的来说R-FCN也还是time/memory consuming。
2. Light-Head R-CNN如何解决?
解释了上面的two-stage为什么比较慢的原因,那么如何解决?
Light-Head R-CNN结合了Faster R-CNN和R-FCN的优点:
1. 使用“薄”(thin)feature map(alpha * p * p, alpha <10),避免了R-FCN feature map太大,且随类别数C增加而增大的问题。
2. 在thin feature map后面接ROI Pooling,此时得到的ROI-wise feature map也薄,这样后面再接FC层,此时的计算量就小了,避免了Faster R-CNN在R-CNN subnet的第一个FC层计算量过大的问题。
下面讲一下Light-Head R-CNN的各个模块。
Backbone
在Head小了以后,Light-Head R-CNN就可以在速度和精度之间做权衡,可以选择性地使用大的或者小的backbone网络了。文章中给出了两种设置:
(1)”L”表示使用大的backbone network,更注重精度。这里用的L网络是resnet101;
(2)”S”表示使用小的backbone network,更注重速度。这里用的S网络是Xception-like model。
Thin feature maps
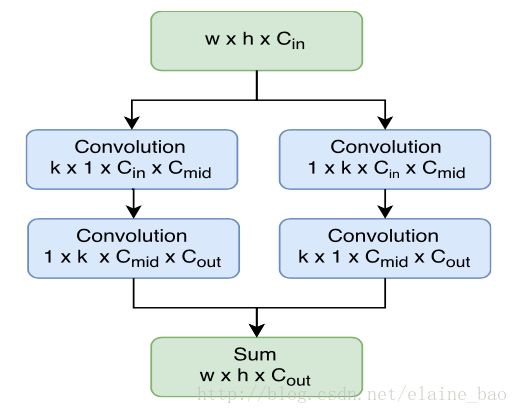
使用large seperable convolution,其结构如下。其中kernel大小k=15,很大,所以叫large conv,这主要是为了保证不丢失太多精度。因为这一层之前的feature map有2048 channel,这一层只有490 channel,这么多channel数的减少要通过large conv进行一定的补偿。另外,seperate conv能够减少计算量,Cmid=64 (for S) / 256 (for L),Cout=10*p*p,远小于R-FCN的#classes*p*p。
R-CNN subnet
使用单个FC层(2048 channel),因为上一层的feature map只有10*p*p大小,所以即使接FC也不会有太大的计算量。后面接两个并联的FC分别用于bbox的分类和回归。
RPN
aspect ratios使用了{1:2,1:1,2:1},scales使用了{ 322,642,1282,2562,5122 }。在RPN输出Proposal的时候也用了NMS (IOU thresh=0.7)。
3. 实验
Table2是R-FCN使用原来的大型feature map和使用thin feature map后的对比,其中B1表示的是R-FCN原作者实现的R-FCN,B2表示的是Light-Head作者重现的R-FCN,加了一些tricks,比如more balanced loss和large image size等,可以看出B2比B1有较大提升。然后各模型加thin feature map后,mmAP只减小了一点点,可以说效果相当。另外作者也提到,thin feature map的设计使得它可以更方便的整合FPN而没有内存的困扰。
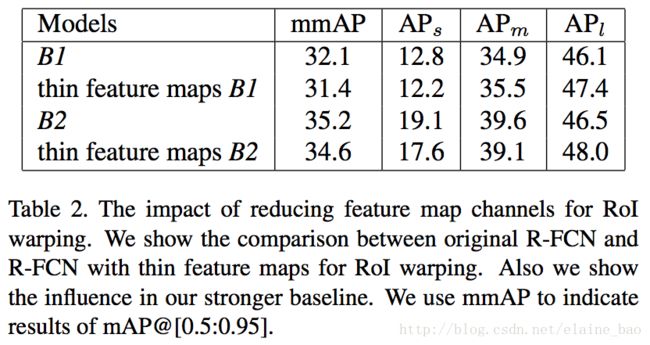
Table5是Light-Head R-CNN精度的体现,可以看出 Light-Head R-CNN的精度相比较于现有比较popular的two-stage物体检测框架来看,有了一些些提升。
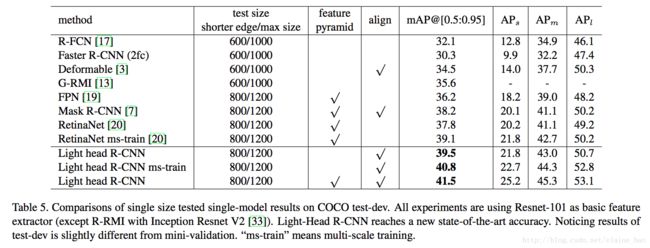
同时呢,它的速度还很快,达到了比one-stage物体检测框架还要快的地步,同时精度也比它们高。
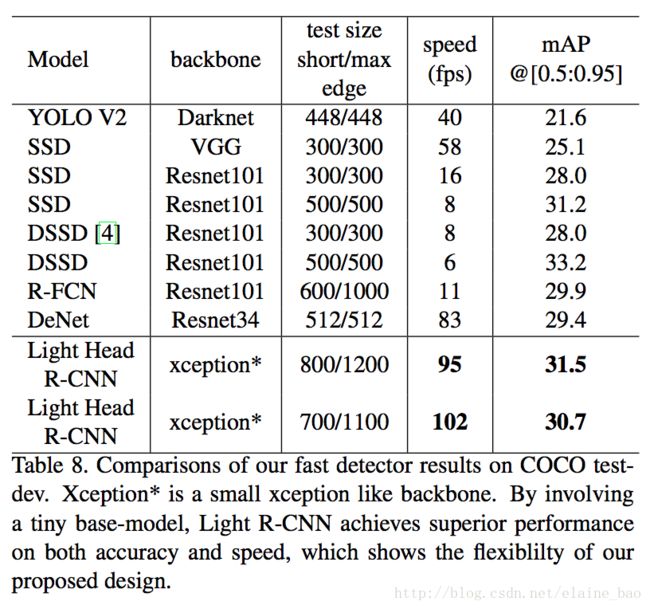
其他结果如果感兴趣的话看原文吧。