【阅读】ShuffleNet和MobileNetv1, v2
最近在考虑通道融合的事情,记得之前看了微软亚洲研究院出的一篇文章有相关信息,但是突然找不到了。暂时先研究一下shuffle net把。
【简介】ShuffleNet是Face++孙健博士团队的成果,目标是减少网络参数的同时也能够获得较好的精度。和MobileNet是一路网络。论文:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices,实现:Github
ShuffleNet
1、核心思想
文章的思想很简单,在group之后增加通道信息的融合。
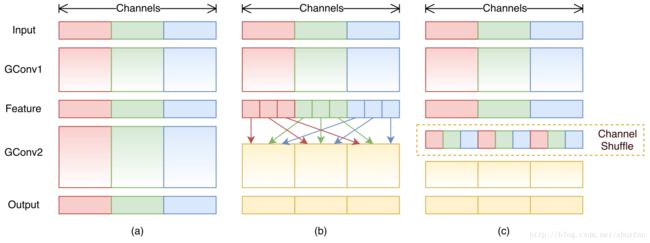
图a是使用group的网络结构,假设groups=3,通道会被等分分开卷积,但是次序并不会被打乱,从而导致groups之间的特征无法进行融合。对于groups=3的卷积层,假设inputs为CxHxW, outputs为OxHxW,那么inputs会被拆分为C/3xHxW,outputs也会被拆分成O/3xHxW,然后分开卷积之后Concate。ResNext使用的就是这种操作,其实这种结构在Alexnet中已经出现,可以通过caffe的prototxt比较下。
图b就是文章的proposal,在不同的group中进行shuffe操作方式很简单,类似于MapReduce框架数据的shuffle。
图c就是shuffle之后的数据分布图。
2、网络结构
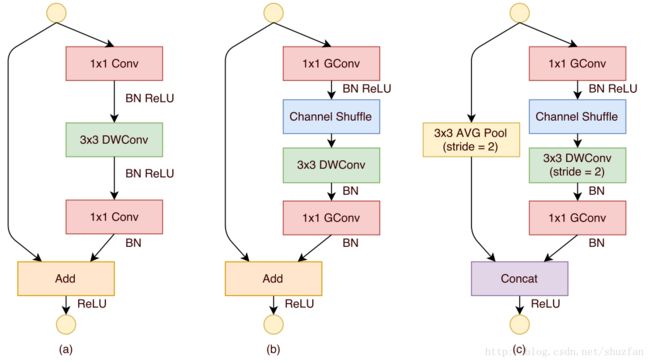
图a是类似resnet v1的网络module,采用bottleneck的方式,先用1x1 conv降低通道数,之后3x3 conv,再之后是1x1 conv增加通道数。这种结构也能够增加通道之间的数据的融合。不过这里3x3 conv 使用的是类似MobileNet的depthwise conv,Details看下面的MobileNet部分。
图b中,把两个1x1conv中替换成了group conv, 并且插入了Channel Shuffle Layer,另外一个调整就是少了一个Relu(这个不知道为啥?MobileNet里面的结构?)。
图c类resnet v1中down sample结构。和resnet不同的是,resnet是使用3x3 stride2 conv 而这里是 3x3 AVG Pooling。
网络结构
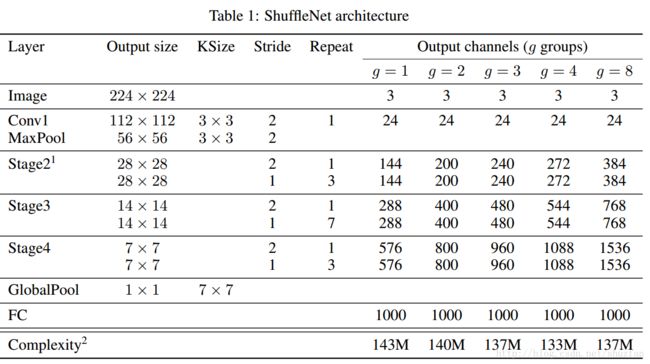
前面的conv 和 pooling遵行了resnet的设计思想,stride等于2,迅速降低feature map的大小。但是网络中stage对比resnet少了一个。
实验对比
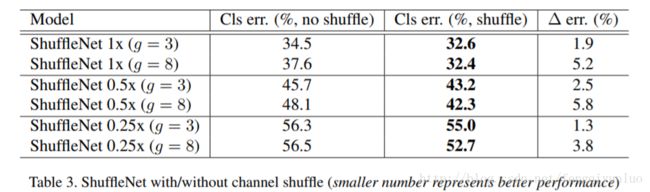
为了方便描述,这里引入一个参数s用来改变从通道数,模型的通道数表示s乘以上表中原始结构的通道数。从图中可以看出。通道越多,g越大结果越好。
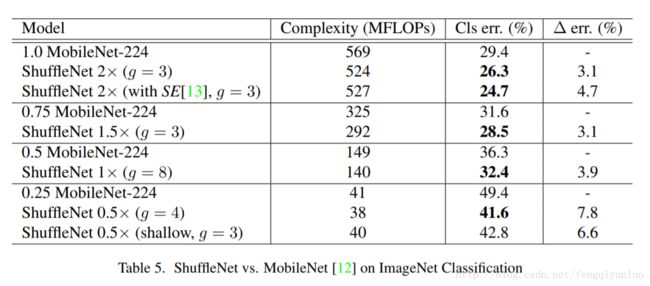
这里是和MobileNet的比较,自然效果也挺好的,而且作者比较的时候使用了SENet的网络结构。下过又好了一些。可以SENet的网络结构确实有帮助。
ShuffleNet相对于Xception和MobileNet,在精度上有了提升,但是在速度上提升则不太明显。因为shuffle步骤的计算量。
这里提到SENet简单的总结一下我看过的网络结构的思想。feature map可以表示成CxHxW,早期的网络结构的设计的目的大多为了增加感受视野。例如Deeplab引入dialation参数和对不同的dialation的结果进行Pyramid,Inception不同的卷积结构(多个小卷积代替大的卷积核),还有PSPNet网络结构中的Pooling Pyramid,都是为了增加感受视野,加入全局信息。另外Attention机制,应该也是对feature map进行spatial的weight。可见上述方法主要集中的维度在于HxW。而最近的网络结构大多在Channel这个维度做文章,例如ResNext对Channel 进行 groups,SENet则对Channel进行weighted,ShuffleNet对Channel进行shuffle,感觉可以对Channel做的事情还可以更多(不知道可以做个Pyramids不,微笑脸)。当然还有3D cnn,也是对feature map增加为维度,还有bottleneck结构。上述方法都可以归结为增加feature map中的信息和进行信息的融了。像找创新点的同学可以从这里出发。
MobileNet V1
MobileNet是google的成果。目的是降低参数同时保持精度。 《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
【核心简介】MobileNet的核心思想很简答。1、Depthwise Separable Conv 分步卷积;2、引入表示Width 乘子,控制通道数;3、引入feature map乘子,控制分辨率 resolution。后面两个感觉只是为了控制模型的表示而引入的超参,就像ResNext的cardinality和densenet的bn_size和growth_rate,只不过这里是专门用来表示模型复杂度而已。
Depthwise Separable Conv
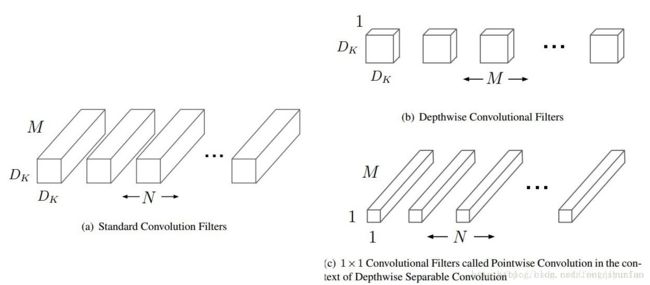
这个就是MobileNet的核心,也是减少参数量的关键所在。据说这种思想也不是MobileNet第一次提出,这个就不多说了。下面介绍原理:
卷积的实现方式主要分为两种
1、sliding window:caffe等大多框架使用的方法
2、傅立叶变换:ifft2(fft2(img)*fft2(filter))
caffe中卷积的实现,假设inputs feature map:MxHxW,outpu feature map: NxHxW。卷积和可以表示为NxMxKxK(对应上图左边)。使用im2col,MxHxW=>A (HxW)x(MxKxK), kernel NxMxKxK=>B Nx(MxKxK)。transpose(B)*A可以得到卷积后的结果。(猛戳知乎大神解答)
Depthwise Separable Conv 分为两部进行,先使用M个KxK filters,对输入进行逐个通道的卷积。然后再使用N个Mx1x1 filters对第一步结果再次进行卷积。这样,原来filters从原来的NxMxKxK变成了(Mx1xKxK+NxMx1x1),从而达到减少参数量的目的。
MobileNet V2
主要两个改进点:
1、inverted residual:resnet v1的bottleneck是降维、卷积、升维,而M V2变成了升维、卷积、降维;
2、linear bottleneck: 去掉最后的线性结构,跟resnetv2类似
http://blog.csdn.net/u014380165/article/details/75142710
更多阅读:
http://blog.csdn.net/Uwr44UOuQcNsUQb60zk2/article/details/78526448
http://blog.csdn.net/zchang81/article/details/73321202
http://blog.csdn.net/whz1861/article/details/78447167
http://blog.csdn.net/jianyuchen23/article/details/76996903
Reference
[1] http://blog.csdn.net/shuzfan/article/details/77141425
[2] http://blog.csdn.net/shuzfan/article/details/70940308