从贝叶斯到卡尔曼
背景介绍
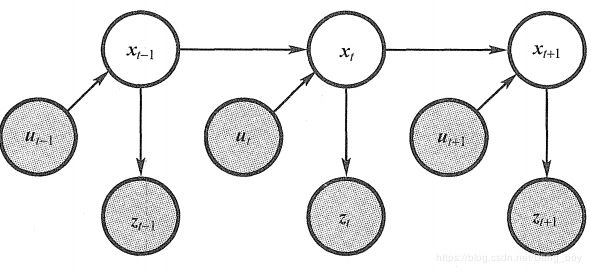
假设我们的模型是这个样子的
{ x k = f ( x k − 1 , u k ) + w k 预 测 方 程 z k = h ( x k ) + v k 观 测 方 程 \begin{cases} \ x_k=f(x_{k-1},u_k)+w_k & 预测方程 \\ \ z_k=h(x_k)+v_k& 观测方程 \end{cases} { xk=f(xk−1,uk)+wk zk=h(xk)+vk预测方程观测方程
已知条件有在0时刻的分布 x 0 x_0 x0,所有时刻的运动输入 u 1 : k u_{1:k} u1:k,所有时刻的观测 z 1 : k z_{1:k} z1:k,然后我们要计算在k时刻的 x k x_k xk的分布
P ( x k ∣ x 0 , u 1 : k , z 1 : k ) P(x_k|x_0,u_{1:k},z_{1:k}) P(xk∣x0,u1:k,z1:k)
求解过程(贝叶斯滤波)
- 将 P ( x k ∣ x 0 , u 1 : k , z 1 : k ) P(x_k|x_0,u_{1:k},z_{1:k}) P(xk∣x0,u1:k,z1:k)通过贝叶斯展开
P ( x k ∣ x 0 , u 1 : k , z 1 : k ) = P ( x k , x 0 , u 1 : k , z 1 : k ) P ( x 0 , u 1 : k , z 1 : k ) = P ( z k ∣ x k , x 0 , u 1 : k , z 1 : k − 1 ) P ( x k ∣ x 0 , u 1 : k , z 1 : k − 1 ) P ( x 0 , u 1 : k , z 1 : k − 1 ) P ( z k ∣ x 0 , u 1 : k , z 1 : k − 1 ) P ( x 0 , u 1 : k , z 1 : k − 1 ) = P ( z k ∣ x k , x 0 , u 1 : k , z 1 : k − 1 ) P ( x k ∣ x 0 , u 1 : k , z 1 : k − 1 ) P ( z k ∣ x 0 , u 1 : k , z 1 : k − 1 ) \begin{aligned} & \ \ \ \ \ P(x_k|x_0,u_{1:k},z_{1:k})\\ & = \frac{P(x_k,x_0,u_{1:k},z_{1:k})}{P(x_0,u_{1:k},z_{1:k})} \\ &= \frac{P(z_k|x_k,x_0,u_{1:k},z_{1:k-1})P(x_k|x_0,u_{1:k},z_{1:k-1})P(x_0,u_{1:k},z_{1:k-1})}{P(z_k|x_0,u_{1:k},z_{1:k-1})P(x_0,u_{1:k},z_{1:k-1})} \\ &=\frac{P(z_k|x_k,x_0,u_{1:k},z_{1:k-1})P(x_k|x_0,u_{1:k},z_{1:k-1})}{P(z_k|x_0,u_{1:k},z_{1:k-1})} \\ \end{aligned} P(xk∣x0,u1:k,z1:k)=P(x0,u1:k,z1:k)P(xk,x0,u1:k,z1:k)=P(zk∣x0,u1:k,z1:k−1)P(x0,u1:k,z1:k−1)P(zk∣xk,x0,u1:k,z1:k−1)P(xk∣x0,u1:k,z1:k−1)P(x0,u1:k,z1:k−1)=P(zk∣x0,u1:k,z1:k−1)P(zk∣xk,x0,u1:k,z1:k−1)P(xk∣x0,u1:k,z1:k−1) - 我们假设世界是马尔可夫的,即当前的状态只和上一刻有关,这样的话在 x k x_k xk已知的情况下,就已经包含了 x 0 , u 1 : k , z 1 : k − 1 x_0,u_{1:k},z_{1:k-1} x0,u1:k,z1:k−1的所有信息,即符合条件独立(此时的 x k x_k xk是已知的了,是一个确定的状态了) P ( z k ∣ x k , x 0 , u 1 : k , z 1 : k − 1 ) = P ( z k ∣ x k ) P(z_k|x_k,x_0,u_{1:k},z_{1:k-1})=P(z_k|x_k) P(zk∣xk,x0,u1:k,z1:k−1)=P(zk∣xk)
- 由于分母与 x k x_k xk的取值无关,即不管 x k x_k xk取什么值,分母都是定值,可以看成一个常量,即
η = P ( z k ∣ x 0 , u 1 : k , z 1 : k − 1 ) − 1 \eta ={P(z_k|x_0,u_{1:k},z_{1:k-1})}^{-1} η=P(zk∣x0,u1:k,z1:k−1)−1
综上,可以得到
P ( x k ∣ x 0 , u 1 : k , z 1 : k ) = η P ( z k ∣ x k ) P ( x k ∣ x 0 , u 1 : k , z 1 : k − 1 ) P(x_k|x_0,u_{1:k},z_{1:k})=\eta P(z_k|x_k)P(x_k|x_0,u_{1:k},z_{1:k-1}) P(xk∣x0,u1:k,z1:k)=ηP(zk∣xk)P(xk∣x0,u1:k,z1:k−1)
将 P ( z k ∣ x k ) P(z_k|x_k) P(zk∣xk)称为似然,将 P ( x k ∣ x 0 , u 1 : k , z 1 : k − 1 ) P(x_k|x_0,u_{1:k},z_{1:k-1}) P(xk∣x0,u1:k,z1:k−1)称为先验。到现在,我们可以通过观测方程求得似然,但是先验部分还没有办法直接求,接下来使用全概率公式引进 x k − 1 x_{k-1} xk−1
P ( x k ∣ x 0 , u 1 : k , z 1 : k − 1 ) = ∑ x k − 1 P ( x k , x k − 1 , u 1 : k , z 1 : k − 1 ) P ( x 0 , u 1 : k , z 1 : k − 1 ) = ∑ x k − 1 P ( x k ∣ x k − 1 , x 0 , u 1 : k , z 1 : k − 1 ) P ( x k − 1 ∣ x 0 , u 1 : k , z 1 : k − 1 ) P ( x 0 , u 1 : k , z 1 : k − 1 ) P ( x 0 , u 1 : k , z 1 : k − 1 ) = ∑ x k − 1 P ( x k ∣ x k − 1 , x 0 , u 1 : k , z 1 : k − 1 ) P ( x k − 1 ∣ x 0 , u 1 : k , z 1 : k − 1 ) 离 散 形 式 = ∫ P ( x k ∣ x k − 1 , x 0 , u 1 : k , z 1 : k − 1 ) P ( x k − 1 ∣ x 0 , u 1 : k , z 1 : k − 1 ) d x k − 1 连 续 形 式 \begin{aligned} & \ \ \ \ \ P(x_k|x_0,u_{1:k},z_{1:k-1})\\ & = \frac{\sum_{x_k-1} P(x_k,x_{k-1},u_{1:k},z_{1:k-1} )}{P(x_0,u_{1:k},z_{1:k-1})}\\ &= \sum_{x_k-1} \frac{P(x_k|x_{k-1},x_0,u_{1:k},z_{1:k-1})P(x_{k-1}|x_0,u_{1:k},z_{1:k-1})P(x_0,u_{1:k},z_{1:k-1})}{P(x_0,u_{1:k},z_{1:k-1})} \\ &=\sum_{x_k-1} P(x_k|x_{k-1},x_0,u_{1:k},z_{1:k-1})P(x_{k-1}|x_0,u_{1:k},z_{1:k-1}) \ 离散形式\\ &=\smallint P(x_k|x_{k-1},x_0,u_{1:k},z_{1:k-1})P(x_{k-1}|x_0,u_{1:k},z_{1:k-1})dx_{k-1} \ 连续形式 \end{aligned} P(xk∣x0,u1:k,z1:k−1)=P(x0,u1:k,z1:k−1)∑xk−1P(xk,xk−1,u1:k,z1:k−1)=xk−1∑P(x0,u1:k,z1:k−1)P(xk∣xk−1,x0,u1:k,z1:k−1)P(xk−1∣x0,u1:k,z1:k−1)P(x0,u1:k,z1:k−1)=xk−1∑P(xk∣xk−1,x0,u1:k,z1:k−1)P(xk−1∣x0,u1:k,z1:k−1) 离散形式=∫P(xk∣xk−1,x0,u1:k,z1:k−1)P(xk−1∣x0,u1:k,z1:k−1)dxk−1 连续形式
综合上式,既可以得到贝叶斯滤波的表达式,记
b e l ( x k ) = P ( x k ∣ z 1 : k , u 1 : k , x 0 ) bel(x_k)=P(x_k|z_{1:k},u_{1:k},x_0) bel(xk)=P(xk∣z1:k,u1:k,x0)
b e l ‾ ( x k ) = P ( x k ∣ z 1 : k − 1 , u 1 : k , x 0 ) \overline{ bel}(x_k)= P(x_k|z_{1:k-1},u_{1:k},x_0) bel(xk)=P(xk∣z1:k−1,u1:k,x0)
假设在这个世界是马尔可夫的,也就是当前的状态之和之前的状态有关,与之后的状态无关,且 x k − 1 x_{k-1} xk−1已经包含了过去的所有信息,则
b e l ( x ) = P ( x k ∣ x 0 , u 1 : k , z 1 : k ) = η P ( z k ∣ x k ) P ( x k ∣ x 0 , u 1 : k , z 1 : k − 1 ) = η P ( z k ∣ x k ) ∫ P ( x k ∣ x k − 1 , x 0 , u 1 : k , z 1 : k − 1 ) P ( x k − 1 ∣ x 0 , u 1 : k , z 1 : k − 1 ) d x k − 1 = η P ( z k ∣ x k ) ∫ P ( x k ∣ x k − 1 , u k ) P ( x k − 1 ∣ x 0 , u 1 : k − 1 , z 1 : k − 1 ) d x k − 1 用 到 了 上 面 的 假 设 = η P ( z k ∣ x k ) ∫ P ( x k ∣ x k − 1 , u k ) b e l ( x k − 1 ) d x k − 1 = η P ( z k ∣ x k ) b e l ‾ ( x k ) \begin{aligned} & \ \ \ \ \ bel(x)=P(x_k|x_0,u_{1:k},z_{1:k}) \\ & =\eta P(z_k|x_k)P(x_k|x_0,u_{1:k},z_{1:k-1})\\ &=\eta P(z_k|x_k)\smallint P(x_k|x_{k-1},x_0,u_{1:k},z_{1:k-1})P(x_{k-1}|x_0,u_{1:k},z_{1:k-1})dx_{k-1} \\ &=\eta P(z_k|x_k)\smallint P(x_k|x_{k-1},u_k)P(x_{k-1}|x_0,u_{1:k-1},z_{1:k-1})dx_{k-1} \ 用到了上面的假设\\ &=\eta P(z_k|x_k) \smallint P(x_k|x_{k-1},u_k)bel(x_{k-1})dx_{k-1}\\ &=\eta P(z_k|x_k) \overline{ bel}(x_k) \end{aligned} bel(x)=P(xk∣x0,u1:k,z1:k)=ηP(zk∣xk)P(xk∣x0,u1:k,z1:k−1)=ηP(zk∣xk)∫P(xk∣xk−1,x0,u1:k,z1:k−1)P(xk−1∣x0,u1:k,z1:k−1)dxk−1=ηP(zk∣xk)∫P(xk∣xk−1,uk)P(xk−1∣x0,u1:k−1,z1:k−1)dxk−1 用到了上面的假设=ηP(zk∣xk)∫P(xk∣xk−1,uk)bel(xk−1)dxk−1=ηP(zk∣xk)bel(xk)
到这里已经成功的推导出了贝叶斯滤波算法。
接下来举一个例子来帮助理解
一只机器人在门的前面检测距离门的距离,估算门开或关,已知在没有任何条件的情况下,门打开或者关闭概率都是0.5。此时机器人检测到距离门的距离是0.5m,已知门打开的情况下,距离门0.5m的概率是0.6,门关闭的情况下,距离门0.5m的概率是0.3,求此时门打开的概率
这个问题比较简单,就是直接利用贝叶斯即可
P ( x 1 = o p e n ∣ z 1 = 0.5 m ) = P ( z 1 ∣ x 1 ) P ( x 1 ) P ( z 1 ∣ x 1 ) P ( x 1 ) + P ( z 1 ∣ ¬ x 1 ) P ( ¬ x 1 ) = 0.6 ∗ 0.5 0.6 ∗ 0.5 + 0.3 ∗ 0.5 = 2 3 \begin{aligned} & \ \ \ \ \ P(x_1=open|z_1=0.5m) \\ &=\frac{P(z_1|x_1)P(x_1)}{P(z_1|x_1)P(x_1)+P(z_1|\lnot x_1)P(\lnot x_1)} \\ &=\frac{0.6*0.5}{0.6*0.5+0.3*0.5}=\frac{2}{3} \end{aligned} P(x1=open∣z1=0.5m)=P(z1∣x1)P(x1)+P(z1∣¬x1)P(¬x1)P(z1∣x1)P(x1)=0.6∗0.5+0.3∗0.50.6∗0.5=32
也可以利用上述的结论
b e l ( x 1 = o p e n ) = P ( x 1 = o p e n ∣ x 0 , z 1 = 0.5 m ) 没 有 动 作 , 所 以 只 有 z = η P ( z 1 ∣ x 1 ) ∑ x 0 P ( x 1 ∣ x 0 ) b e l ( x 0 ) = η P ( z 1 ∣ x 1 ) ( P ( x 1 ∣ x 0 = o p e n ) P ( x 0 = o p e n ) + P ( x 1 ∣ ¬ x 0 ) P ( ¬ x 0 ) ) = η ∗ 0.6 ∗ ( 1 ∗ 0.5 + 0 ∗ 0.5 ) = 0.3 η \begin{aligned} & \ \ \ \ \ bel(x_1=open)\\ &=P(x_1=open|x_0,z_{1}=0.5m)\ 没有动作,所以只有z \\ &=\eta P(z_1|x_1) \sum_{x_0} P(x_1|x_{0})bel(x_{0}) \\ &=\eta P(z_1|x_1)(P(x_1|x_0=open)P(x_0=open)+P(x_1|\lnot x_0)P(\lnot x_0)) \\ &=\eta *0.6*(1*0.5+0*0.5)=0.3\eta \end{aligned} bel(x1=open)=P(x1=open∣x0,z1=0.5m) 没有动作,所以只有z=ηP(z1∣x1)x0∑P(x1∣x0)bel(x0)=ηP(z1∣x1)(P(x1∣x0=open)P(x0=open)+P(x1∣¬x0)P(¬x0))=η∗0.6∗(1∗0.5+0∗0.5)=0.3η
b e l ( x 1 = c l o s e d ) = P ( x 1 = c l o s e d ∣ x 0 , z 1 = 0.5 m ) 没 有 动 作 , 所 以 只 有 z = η P ( z 1 ∣ x 1 ) ∑ x 0 P ( x 1 ∣ x 0 ) b e l ( x 0 ) = η P ( z 1 ∣ x 1 ) ( P ( x 1 ∣ x 0 = o p e n ) P ( x 0 = o p e n ) + P ( x 1 ∣ ¬ x 0 ) P ( ¬ x 0 ) ) = η ∗ 0.3 ∗ ( 0 ∗ 0.5 + 1 ∗ 0.5 ) = 0.15 η \begin{aligned} & \ \ \ \ \ bel(x_1=closed)\\ &=P(x_1=closed|x_0,z_{1}=0.5m)\ 没有动作,所以只有z \\ &=\eta P(z_1|x_1) \sum_{x_0} P(x_1|x_{0})bel(x_{0}) \\ &=\eta P(z_1|x_1)(P(x_1|x_0=open)P(x_0=open)+P(x_1|\lnot x_0)P(\lnot x_0)) \\ &=\eta *0.3*(0*0.5+1*0.5)=0.15\eta \end{aligned} bel(x1=closed)=P(x1=closed∣x0,z1=0.5m) 没有动作,所以只有z=ηP(z1∣x1)x0∑P(x1∣x0)bel(x0)=ηP(z1∣x1)(P(x1∣x0=open)P(x0=open)+P(x1∣¬x0)P(¬x0))=η∗0.3∗(0∗0.5+1∗0.5)=0.15η
0.15 η + 0.3 η = 0.45 η = 1 b e l ( x 1 = o p e n ) = 0.3 η = 2 3 0.15\eta + 0.3\eta=0.45\eta=1\\ bel(x_1=open)=0.3\eta=\frac{2}{3} 0.15η+0.3η=0.45η=1bel(x1=open)=0.3η=32
两个方法求出来的结果是一样的。
同时注意这里的情况,这是只有观测,没有动作,所以世界是不会改变的,即原来的状态是什么样子的,便是什么样子的,所以先验部分只需要处理与 x 1 x_1 x1状态相同的情况即可。
在上面的基础,进行第二次观察,结果仍然是0.5m,求此时门开着的概率
b e l ( x 2 = o p e n ) = P ( x 2 = o p e n ∣ x 0 , z 1 = 0.5 m , z 2 = 0.5 m ) = η P ( z 2 ∣ x 2 ) ∑ x 1 P ( x 2 ∣ x 1 ) b e l ( x 1 ) = η P ( z 2 ∣ x 2 ) ( P ( x 2 ∣ x 1 = o p e n ) P ( x 1 = o p e n ) + P ( x 2 ∣ ¬ x 1 ) P ( ¬ x 1 ) ) = η ∗ 0.6 ∗ ( 1 ∗ 2 3 + 0 ∗ 1 3 ) = 0.4 η \begin{aligned} & \ \ \ \ \ bel(x_2=open)\\ &=P(x_2=open|x_0,z_{1}=0.5m,z_2=0.5m) \\ &=\eta P(z_2|x_2) \sum_{x_1} P(x_2|x_{1})bel(x_{1}) \\ &=\eta P(z_2|x_2)(P(x_2|x_1=open)P(x_1=open)+P(x_2|\lnot x_1)P(\lnot x_1)) \\ &=\eta *0.6*(1*\frac{2}{3}+0*\frac{1}{3})=0.4\eta \end{aligned} bel(x2=open)=P(x2=open∣x0,z1=0.5m,z2=0.5m)=ηP(z2∣x2)x1∑P(x2∣x1)bel(x1)=ηP(z2∣x2)(P(x2∣x1=open)P(x1=open)+P(x2∣¬x1)P(¬x1))=η∗0.6∗(1∗32+0∗31)=0.4η
b e l ( x 2 = c l o s e d ) = P ( x 2 = c l o s e d ∣ x 0 , z 1 = 0.5 m , z 2 = 0.5 m ) = η P ( z 2 ∣ x 2 ) ∑ x 1 P ( x 2 ∣ x 1 ) b e l ( x 1 ) = η P ( z 2 ∣ x 2 ) ( P ( x 2 ∣ x 1 = o p e n ) P ( x 1 = o p e n ) + P ( x 2 ∣ ¬ x 1 ) P ( ¬ x 1 ) ) = η ∗ 0.3 ∗ ( 0 ∗ 2 3 + 1 ∗ 1 3 ) = 0.1 η \begin{aligned} & \ \ \ \ \ bel(x_2=closed)\\ &=P(x_2=closed|x_0,z_{1}=0.5m,z_2=0.5m) \\ &=\eta P(z_2|x_2) \sum_{x_1} P(x_2|x_{1})bel(x_{1}) \\ &=\eta P(z_2|x_2)(P(x_2|x_1=open)P(x_1=open)+P(x_2|\lnot x_1)P(\lnot x_1)) \\ &=\eta *0.3*(0*\frac{2}{3}+1*\frac{1}{3})=0.1\eta \end{aligned} bel(x2=closed)=P(x2=closed∣x0,z1=0.5m,z2=0.5m)=ηP(z2∣x2)x1∑P(x2∣x1)bel(x1)=ηP(z2∣x2)(P(x2∣x1=open)P(x1=open)+P(x2∣¬x1)P(¬x1))=η∗0.3∗(0∗32+1∗31)=0.1η
0.4 η + 0.1 η = 0.5 η = 1 b e l ( x 2 = o p e n ) = 0.4 η = 0.8 0.4\eta + 0.1\eta=0.5\eta=1\\ bel(x_2=open)=0.4\eta=0.8 0.4η+0.1η=0.5η=1bel(x2=open)=0.4η=0.8
假设机器人执行关门的动作有0.1的概率失败,即原本门是开着,有0.9的概率门关上了,0.1的概率门还开着,如果原本门关闭着,执行完动作后,门还是关着。现在机器人在前面的基础上,执行了关门的动作,问此时门开着的概率是多少?
b e l ( x 3 = o p e n ) = P ( x 3 = o p e n ∣ x 0 , z 1 = 0.5 m , z 2 = 0.5 m , u 3 ) = η ∑ x 2 P ( x 3 ∣ x 2 , u 3 ) b e l ( x 2 ) = η ( P ( x 3 ∣ x 2 = o p e n , u 3 ) P ( x 2 = o p e n ) + P ( x 3 ∣ ¬ x 2 , u 3 ) P ( ¬ x 2 ) ) = η ∗ ( 0.1 ∗ 0.8 + 0 ∗ 0.2 ) = 0.08 η \begin{aligned} & \ \ \ \ \ bel(x_3=open)\\ &=P(x_3=open|x_0,z_{1}=0.5m,z_2=0.5m,u_3) \\ &=\eta \sum_{x_2} P(x_3|x_{2},u_3)bel(x_{2}) \\ &=\eta(P(x_3|x_2=open,u_3)P(x_2=open)+P(x_3|\lnot x_2,u_3)P(\lnot x_2)) \\ &=\eta *(0.1*0.8+0*0.2)=0.08\eta \end{aligned} bel(x3=open)=P(x3=open∣x0,z1=0.5m,z2=0.5m,u3)=ηx2∑P(x3∣x2,u3)bel(x2)=η(P(x3∣x2=open,u3)P(x2=open)+P(x3∣¬x2,u3)P(¬x2))=η∗(0.1∗0.8+0∗0.2)=0.08η
b e l ( x 3 = c l o s e d ) = P ( x 3 = c l o s e d ∣ x 0 , z 1 = 0.5 m , z 2 = 0.5 m , u 3 ) = η ∑ x 2 P ( x 3 ∣ x 2 , u 3 ) b e l ( x 2 ) = η ( P ( x 3 ∣ x 2 = o p e n , u 3 ) P ( x 2 = o p e n ) + P ( x 3 ∣ ¬ x 2 , u 3 ) P ( ¬ x 2 ) ) = η ∗ ( 0.9 ∗ 0.8 + 1 ∗ 0.2 ) = 0.92 η \begin{aligned} & \ \ \ \ \ bel(x_3=closed)\\ &=P(x_3=closed|x_0,z_{1}=0.5m,z_2=0.5m,u_3) \\ &=\eta \sum_{x_2} P(x_3|x_{2},u_3)bel(x_{2}) \\ &=\eta(P(x_3|x_2=open,u_3)P(x_2=open)+P(x_3|\lnot x_2,u_3)P(\lnot x_2)) \\ &=\eta *(0.9*0.8+1*0.2)=0.92\eta \end{aligned} bel(x3=closed)=P(x3=closed∣x0,z1=0.5m,z2=0.5m,u3)=ηx2∑P(x3∣x2,u3)bel(x2)=η(P(x3∣x2=open,u3)P(x2=open)+P(x3∣¬x2,u3)P(¬x2))=η∗(0.9∗0.8+1∗0.2)=0.92η
0.08 η + 0.92 η = η = 1 b e l ( x 2 = o p e n ) = 0.08 η = 0.08 0.08\eta + 0.92\eta=\eta=1\\ bel(x_2=open)=0.08\eta=0.08 0.08η+0.92η=η=1bel(x2=open)=0.08η=0.08
注意这一部分,是只有动作而没有观测,所以只需要计算先验部分即可。
贝叶斯的缺点
可以看到,每一次添加新的动作或者观测的时候,概率都会发生改变,如果事件的可能情况很多,则需要计算很多次,特别的,如果是连续的概率,则可能发生的情况会有无穷多种,此时是不可能计算所有情况的。
但是,只要我们做一些假设,那么情况就会不一样了,例如
1)状态转移概率 P ( x k ∣ u k , x k − 1 ) P(x_k|u_k,x_{k-1}) P(xk∣uk,xk−1)必须是带有随机高斯噪声的参数的线性函数,即运动方程必须是线性的,且上一个状态也是高斯分布
x k = A k x k − 1 + u k + w k x k − 1 ∼ N ( x ^ k − 1 , P ^ k − 1 ) w k ∼ N ( 0 , R ) x_k=A_kx_{k-1}+u_k+w_k \ \ \ x_{k-1}\sim N(\widehat{x}_{k-1},\widehat{P}_{k-1}) \ \ w_k\sim N(0,R) xk=Akxk−1+uk+wk xk−1∼N(x k−1,P k−1) wk∼N(0,R)
2)测量概率 P ( z k ∣ x k ) P(z_k|x_k) P(zk∣xk)也与带有高斯噪声的自变量呈线性关系,即观测方程也是线性的
z k = C k x k + v k x k ∼ N ( x ^ k , P ^ k ) v k ∼ N ( 0 , Q ) z_k=C_kx_k+v_k\ \ \ x_{k}\sim N(\widehat{x}_{k},\widehat{P}_{k}) \ \ v_k\sim N(0,Q) zk=Ckxk+vk xk∼N(x k,P k) vk∼N(0,Q)
3)结合第一条当k=1,的时候,也必须符合高斯分布
x 0 ∼ N ( x ^ 0 , P ^ 0 ) x_{0}\sim N(\widehat{x}_{0},\widehat{P}_{0}) x0∼N(x 0,P 0)
添加了上面的三个假设,那么可以证明,无论在什么时候 b e l ( x k ) bel(x_k) bel(xk)都是符合高斯分布的。接下来的推导按照《slam十四讲里》的推导,这样会和贝叶斯滤波的步骤对不上,如果完全按照贝叶斯滤波的那一套来,过程比较复杂,可以参考书《概率机器人》,也有博客细说kalman滤波。博客里面一些比较麻烦的推导没有写进来,如果感兴趣就直接看书吧,书里很全面,就是太复杂了。
卡尔曼滤波
先说一下, b e l ‾ ( x k ) = P ( x k ∣ z 1 : k − 1 , u 1 : k , x 0 ) \overline{ bel}(x_k)= P(x_k|z_{1:k-1},u_{1:k},x_0) bel(xk)=P(xk∣z1:k−1,u1:k,x0)和 P ( x k ∣ x k − 1 , u k ) P(x_k|x_{k-1},u_k) P(xk∣xk−1,uk)是不一样的,虽然我们前面做了假设说 x k − 1 x_{k-1} xk−1已经包含了k-1时刻和之前的所有信息 z 1 : k − 1 , u 1 : k − 1 , x 0 z_{1:k-1},u_{1:k-1},x_0 z1:k−1,u1:k−1,x0,但是这并不等价于 x k − 1 x_{k-1} xk−1和前面的信息是等价的,事实上,应该是 x k − 1 {x_{k-1}} xk−1在过去所有信息的影响下的所有可能的值都加上,才和过去所有的信息是等价,这一问题其实在推导的过程中也是已经出现了的
b e l ‾ ( x k ) = ∫ P ( x k ∣ x k − 1 , u k ) b e l ( x k − 1 ) d x k − 1 \overline{ bel}(x_k)=\smallint P(x_k|x_{k-1},u_k)bel(x_{k-1})dx_{k-1} bel(xk)=∫P(xk∣xk−1,uk)bel(xk−1)dxk−1
也就是把 x k − 1 x_{k-1} xk−1加进条件里的话,就是假设 x k − 1 x_{k-1} xk−1已经发生了,此时的 x k − 1 x_{k-1} xk−1已经是个确定的状态了,而不是代表一个概率密度。《概率机器人》里面是把 x k − 1 x_{k-1} xk−1当成了一个确定的状态,直接利用代进 b e l ‾ ( x k ) = ∫ P ( x k ∣ x k − 1 , u k ) b e l ( x k − 1 ) d x k − 1 \overline{ bel}(x_k)=\smallint P(x_k|x_{k-1},u_k)bel(x_{k-1})dx_{k-1} bel(xk)=∫P(xk∣xk−1,uk)bel(xk−1)dxk−1表达式里,直接计算积分推导出 b e l ‾ ( x k ) \overline{ bel}(x_k) bel(xk),而《slam十四讲》里是直接把 x k − 1 x_{k-1} xk−1当成了一个概率分布,而整个概率分布的就包含了过去的所有信息。
我觉得《概率机器人》里面的推导是比较直接的,逻辑比较好理解,和贝叶斯滤波一步步对应起来求解就好了,但是数学部分比较难看懂(例如积分怎么求),而《slam十四讲》里面的推导比较容易看懂(数学部分)。
卡尔曼滤波的推导
先给出一个成立的例子
考虑随机变量 x ∼ N ( μ x , Σ x x ) x\sim N(\mu_x,\Sigma_{xx}) x∼N(μx,Σxx),另一个变量y满足 y = A x + b + w y=Ax+b+w y=Ax+b+w其中 A,b 为线性变量的系数矩阵和偏移量, w 为噪声项,为零均值的高斯分布: w ∼N(0,R)。我们来看 y 的分布。根据前面的介绍,可以推出
p ( y ) = N ( A µ x + b , A Σ x x A T + R ) p (y) = N (Aµ_x + b, AΣ_{xx}AT + R) p(y)=N(Aµx+b,AΣxxAT+R)
已知 x k = A k x k − 1 + u k + w k x k − 1 ∼ N ( x ^ k − 1 , P ^ k − 1 ) w k ∼ N ( 0 , R ) x_k=A_kx_{k-1}+u_k+w_k \ \ \ x_{k-1}\sim N(\widehat{x}_{k-1},\widehat{P}_{k-1})\ \ w_k\sim N(0,R) xk=Akxk−1+uk+wk xk−1∼N(x k−1,P k−1) wk∼N(0,R)
求 x k x_k xk的概率分布,直接代进上面的例子,直接就可以得到先验部分
b e l ‾ ( x k ) = P ( x k ∣ z 1 : k − 1 , u 1 : k , x 0 ) ∼ N ( A k x ^ k − 1 + u k , A k P ^ k − 1 A k T + R ) \overline{ bel}(x_k)=P(x_k|z_{1:k-1},u_{1:k},x_0)\sim N (A_k\widehat{x}_{k−1} + u_k,A_k\widehat{P}_{k−1}A^T_k + R) bel(xk)=P(xk∣z1:k−1,u1:k,x0)∼N(Akx k−1+uk,AkP k−1AkT+R)
同时记 x ‾ k = A k x ^ k − 1 + u k P ‾ k = A k P ^ k − 1 A k T + R \overline{x}_k=A_k\widehat{x}_{k−1} + u_k \\ \overline{P}_k=A_k\widehat{P}_{k−1}A^T_k + R xk=Akx k−1+ukPk=AkP k−1AkT+R
则 b e l ‾ ( x k ) = P ( x k ∣ z 1 : k − 1 , u 1 : k , x 0 ) ∼ N ( x ‾ k , P ‾ k ) \overline{ bel}(x_k)=P(x_k|z_{1:k-1},u_{1:k},x_0)\sim N (\overline{x}_k,\overline{P}_k) bel(xk)=P(xk∣z1:k−1,u1:k,x0)∼N(xk,Pk)
接下来,通过观测方程,计算似然部分
z k = C k x k + v k x k ∼ N ( x ^ k , P ^ k ) v k ∼ N ( 0 , Q ) z_k=C_kx_k+v_k\ \ \ x_{k}\sim N(\widehat{x}_{k},\widehat{P}_{k}) \ \ v_k\sim N(0,Q) zk=Ckxk+vk xk∼N(x k,P k) vk∼N(0,Q)
似然 P ( z k ∣ x k ) P(z_k|x_k) P(zk∣xk)里面, x k x_k xk是已知的,所以此时的 x k x_k xk是一个确定的值,而不是一个概率,可以得到
P ( z k ∣ x k ) ∼ N ( C k x k , Q ) P(z_k|x_k)\sim N(C_kx_k,Q) P(zk∣xk)∼N(Ckxk,Q)
接下来是用了点小技巧,就是我们已知结果会是一个高斯函数,我们直接设结果为 b e l ( x k ) ∼ N ( x ^ k , P ^ k ) bel(x_k)\sim N(\hat{x}_k,\hat{P}_k) bel(xk)∼N(x^k,P^k)
则带进贝叶斯滤波器可以得到
N ( x ^ k , P ^ k ) = η N ( C k x k , Q ) ⋅ N ( x ‾ k , P ‾ k ) N(\hat{x}_k,\hat{P}_k)=\eta N(C_kx_k,Q)·N (\overline{x}_k,\overline{P}_k) N(x^k,P^k)=ηN(Ckxk,Q)⋅N(xk,Pk)
接下来只要得到解这个式子然后通过对比指数部分,就可以得到 x ^ k , P ^ k \hat{x}_k,\hat{P}_k x^k,P^k,具体过程直接《slam十四讲》,接下来直接截图书里的内容(因为公式太多了,而且基本是照书里打)


可以得到卡尔曼滤波的迭代公式
预测部分
b e l ‾ ( x k ) { x ‾ k = A k x ^ k − 1 + u k P ‾ k = A k P ^ k − 1 A k T + R \overline{ bel}(x_k)\begin{cases} \ \overline x_k=A_k\widehat{x}_{k−1} + u_k\\ \ \overline P_k=A_k\widehat{P}_{k−1}A^T_k + R \\ \end{cases} bel(xk){ xk=Akx k−1+uk Pk=AkP k−1AkT+R
卡尔曼增益
K = P ‾ k C k T ( C k P ‾ k C k T + Q ) − 1 K= \overline P_kC_k^T (C_k \overline P_kC_k^T + Q)^{−1} K=PkCkT(CkPkCkT+Q)−1
后验部分
b e l ( x k ) { x ^ k = x ‾ k + K ( z k − C k x ‾ k ) P ^ k = ( I − K C k ) P ‾ k { bel}(x_k)\begin{cases} \ \hat x_k=\overline x_k+K(z_k-C_k\overline x_k)\\ \ \hat P_k= (I − KC_k) \overline P_k \\ \end{cases} bel(xk){ x^k=xk+K(zk−Ckxk) P^k=(I−KCk)Pk
到这里就成功的推导出了卡尔曼滤波了
opencv实现例子
#include 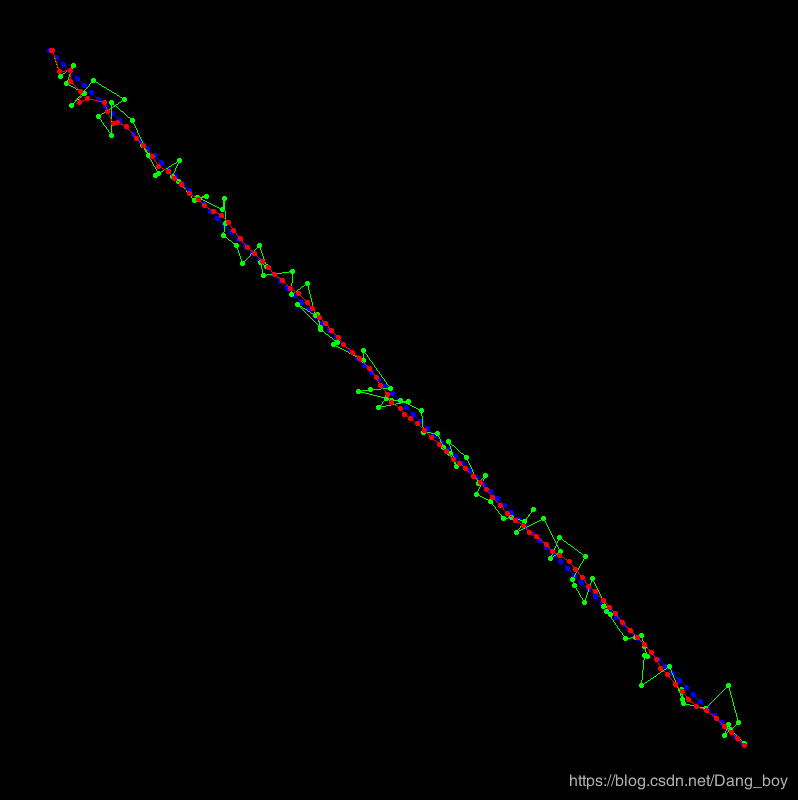
蓝色的线是不带噪声的
绿色的线是带噪声的
红色的线是用待噪声的数据滤波出来的结果
可以看到红色的线一开始波动比较大,到最后基本稳定在蓝色的线周围小幅度的摆动,比起绿色的线,效果已经好了很多了。
参考资料:
《slam十四讲》
《概率机器人》
(一). 细说贝叶斯滤波:Bayes filters
(二). 细说Kalman滤波:The Kalman Filter