CUDA入门笔记(一)GPU设计思路、背景知识
参考:
优达学城:https://classroom.udacity.com/courses/cs344/lessons/55120467/concepts/670611900923
CUDA Zone:https://www.nvidia.cn/object/cuda_education_cn_old.html
一、GPU如何提高运算速率
提高运算速率的思路有三:
1.使用更高的时钟
2.每个时钟周期进行更多的运算
3.使用多个处理器并行计算(GPU的思想)
If you were plowing a field, which would you rather use? Two strong oxen or 1024 chicken?
——超级计算机之父 Seymour Cray
*Solve big problems by breaking them to smaller pieces and then run these smaller pieces at the same time.
*每一个小的工作称为“thread”,线程
二、CPU速度提升遇到瓶颈
1.晶体管体积逐年递减,处理器体积因此随之递减
下图2.1:处理器特征尺寸随时间变化
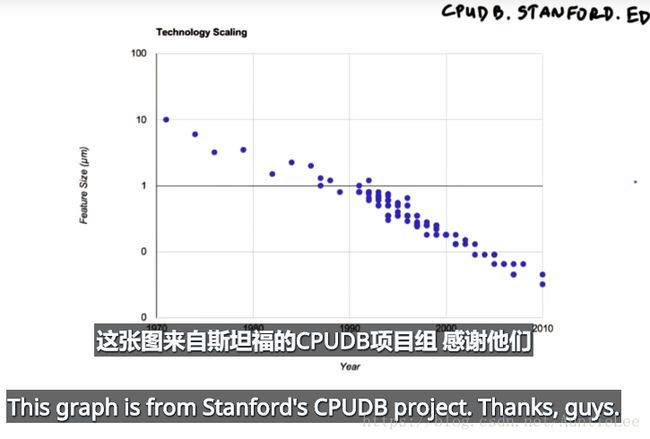 图2.1 处理器体积减小
图2.1 处理器体积减小
更小。更快、更低功耗、可以集成更多处理单元,因此得到了更多可以计算的资源。
然而,计算速度更快的另一个因素是,时钟频率一直在上升(如图2.2)。而近几年时钟频率趋于平缓,因此并不是一件好事情。即,时钟频率没有在变快,只是处理单元变多,导致运算速度加快。
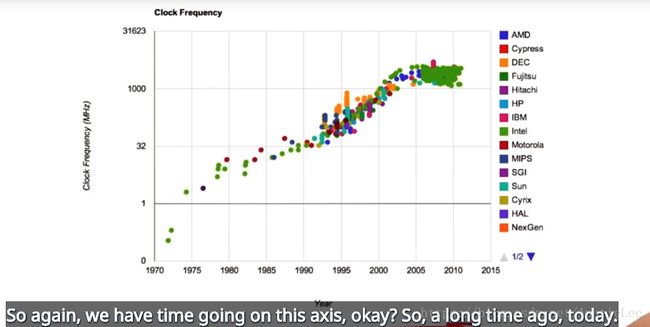 图2.2 时钟频率上升
图2.2 时钟频率上升
三、需求
1.加速硬件需求
CPU硬件控制复杂=>性能灵活,电力消耗、设计复杂度高
因此,要设计简单的控制结构,supporting more computation in the data path.
GPU<=>建造大量并行简单控制结构的单元
2.运行效率目标衡量标准
1)执行时间
2)吞吐量(单位时间执行工作量)
*有时两个标准并不一致,在图像处理领域,我们更在乎吞吐量。
四、核GPU设计原则
1.利用很多简单的计算单元计算复杂的问题,用更简单的控制单元达成更多计算
*这导致在GPU编程的时候,程序员面临着更多限制
2.GPU有显式并行编程模型
*必须以多处理器的形式进行编程,不能当作只有一个处理器
3.GPU的目的是最优化吞吐量,而非最优化计算时长
五、从软件开发者角度
并行运算的重要性->牺牲复杂度换取计算效率是很值的