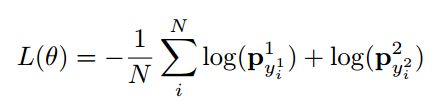简介
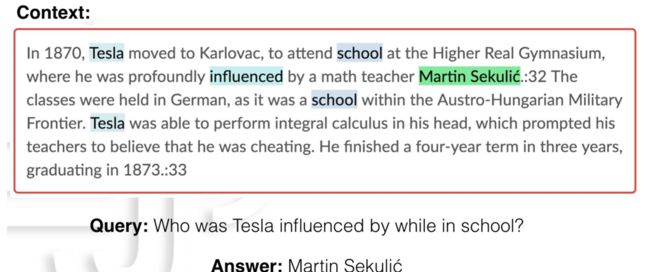
抽取式QA是要在文档中定位问题的答案。模型输入是【Passage,Question】,模型输出是【start_idx,end_idx】∈ [ 0, len(passage) ]。
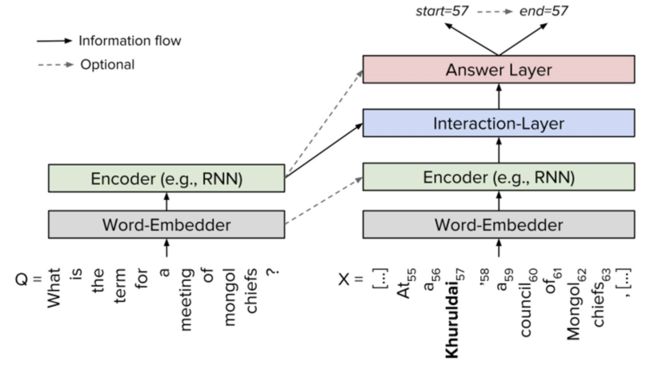
QA模型主要包括 Embeeding层、Encoder编码层层、Interaction交互层、Answer作答层。
Match-LSTM
-
预处理
文档和问题在输入模型前,需要进行 token 和 padding 操作。
-
模型结构
1. Embedding层
对 Passage 和 Question 分别进行Word Embedding
2. LSTM层
将 Passage 和 Question 分别带入一个BiLSTM,获取所有Hidden states,这样可以使得 Passage 和 Question 都带有上下文信息
3. Match-LSTM层【Attention + LSTM】
这一层的主要作用是获取 Question 和 Passage 交互信息。
获取 Passage 中每一个单词对于 Question 中的注意力权重α,然后将 α 与 Question Embedding相乘求和,获得 Passage 每个单词基于 Question 的新的表示方式。
这个时候再将 Passage 带入LSTM中,每个位置上就都具有 Question信息 、上下文信息(比上一层更丰富的上下文信息)。
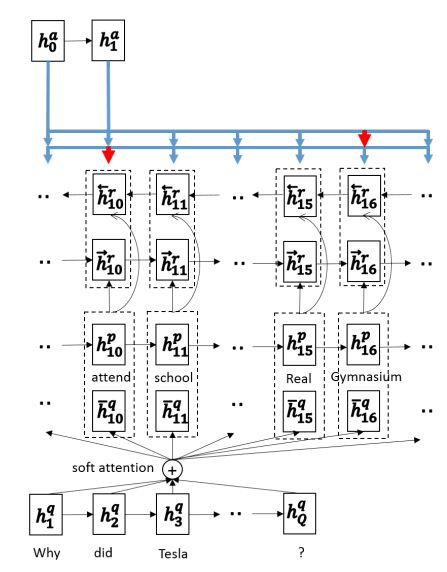
下面来看看Match-LSTM中权重的计算方式,如下图所示。这里的Hq是Question带入LSTM输出的hidden states,hp_i是PassageLSTM输出的hidden states的第i个值,L 是上一层LSTM的隐藏层数目。

这种 attention 被称为 BahdanauAttention。 Passage 中第 t 个上下文向量会根据 所有 Question 的隐向量 & Passage 中 t-1 时刻的上下文向量 来确定对Question 每个 token 的权重。可以把下图的 Y 理解为 passage,把 X 理解为question。
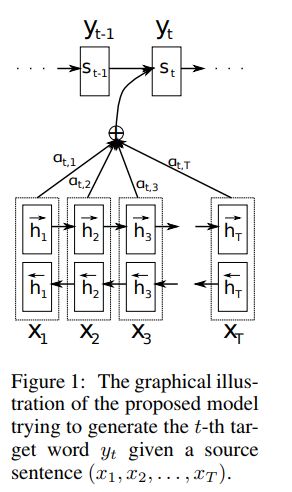
获得了权重以后就要对上一层LSTM输出的 Passage 的上下文动手了,给每个位置上添加各自对应的 Question 信息:Hq*α。也就是将attention向量与原问题编码向量点乘,得到passage中第i个token的question关联信息。接着再与passage中第i个token的编码向量做concat,粘贴为一个向量。

将上述concat后的结构再次带入一个LSTM,以便获得加入了 Question 后更丰富的上下文信息。
将上面 attention + LSTM 的操作再反向来一遍,最终将两个方向的结果拼接起来。
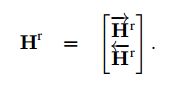
4. Pointer层
这里将 Match-LSTM的输出Hr作为这一层的输入,输出为answer。
首先要说明的是,实际上Match-LSTM在预测最终的答案有两种模式,一种是预测出句子里的所有单词【构建语言模型求概率】,一种是只预测句子的起点和终点。论文证明,后一种方式快好省。
预测机制源于Pointer Network,这实际上还是一个BahdanauAttention机制。我们再看看刚刚那个图,这里要将 X 理解为Passage,将 Y理解Answer就可以了。预测值基于上一刻的值和passage全文来决定。
也可以说这里将attention向量作为匹配概率输出,这个attention的大小等同于passage的长度。
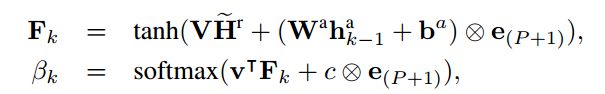
-
损失函数
交叉熵,Pn是Passage,Qn是Question,a_n是预测序列中的单词。
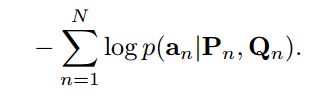
BiDAF
-
创新点
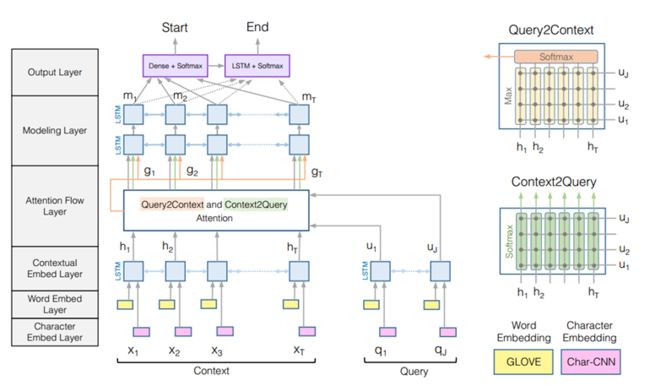
同时引入了Char 和 Word Embdeeing.
在interaction交互层引入了双向注意力机制。Match-LSTM只有Passage对Question的注意力,Passage中每个单词关注Question中的哪些单词。这里引入了Question看Passage的注意力在哪,这样可以计算得到Question眼中的Passage哪些单词重要哪些不重要。
-
模型结构

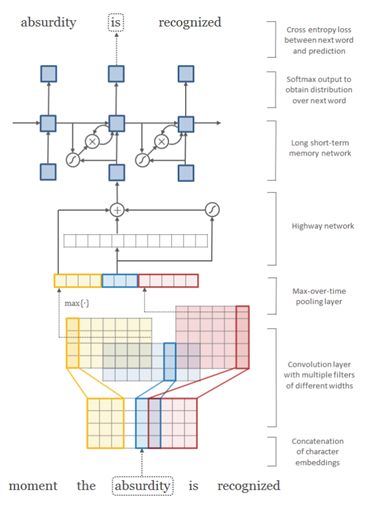
1. Character Embedding Layer
Character embedding组成一个word的话是一个matrix,对这个matrix进行卷积+池化操作就可以得到对应word的embedding了。
2. Word Embedding Layer
正常Word Embedding操作。论文中使用了Glove预训练向量。
完成以上两个embedding之后,将两者拼接。 然后输入一个两层的 Highway Network,这个最终得到的结果就是Passage和Question文本表示。
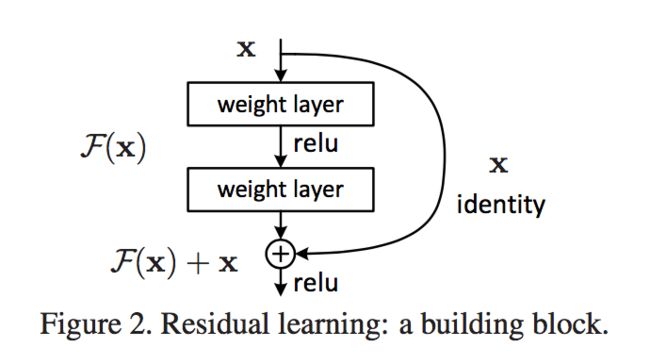
对于Highway Network可以这么理解:
原本是y=f(x)
现在是y=αf(x)+(1-α)x
类似于一个Residual,据说ResNet有抄袭Highway Network之嫌。
 Residual
Residual
Highway Network使得所有原始信息部分激活进入下一层、部分不激活直接进入下一层,保留了更多原始信息。同时反向传播的时候,可以避免梯度消失。
Highway Network的结构一般用在将char embedding卷积成word embedding时候,可以获得更好地词向量。
3. Contextual Embedding Layer
与Match-LSTM类似,这是一个BiLSTM,输入上述embedding,输出hidden states,使得每个位置上获得上下文信息。
步骤1、2、3使得Passage和Question同时具备了Word、Char、Sentence三层信息。
4. Attention Flow Layer
交互层,用于融合Paasge和Question的信息。包括从文本看问题视角的Context2Query和从问题视角看文本的Query2Context,前者用于获取文本单词关注哪些单词,后者用于获取针对这个答案文本中哪些单词更重要。

首先计算H(Passgae)和Question(U)的相似度矩阵S
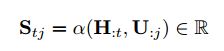
Context2Query对每列计算Softmax然后与U点乘。参照完整结构图绿色线。:
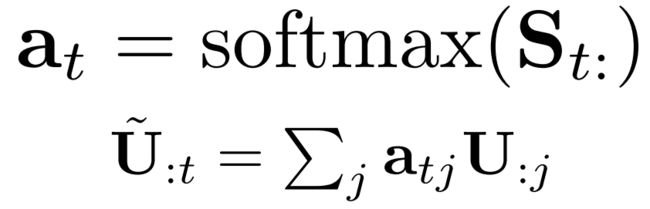
Query2Context对每列取最大值(每个h最大相似度能有多大),再对取出的所有h计算softmax。最后将获得的h_hat重复T遍得到H_hat。参照完整结构图橙色线。:
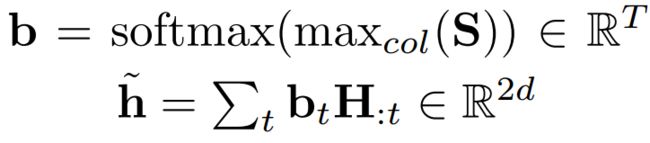
最后将上述两者联合从3. Contextual Embedding Layer获得的H拼接起来得到G,作为下一层的输入。
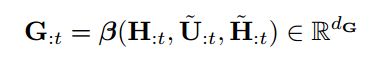
5. Modeling Layer.
M = BiLSTM(G)
6. Output Layer
Strat_index:

End_index:
首先先将M过一层双向LSTM:M2 = BiLSTM(M)

-
损失函数