Fine-tuning
原文地址 https://blog.csdn.net/xinrui_zhuang/article/details/79017750
论文阅读:Fine-tuning Convolutional Neural Networks forBiomedical Image Analysis: Actively and Incrementally
本篇论文发表于CVPR2017,作者为美国亚利桑那州立大学着的在读博士生周纵苇。它主要解决的仍然是生物医学图像在用于深度学习时数据量过少的问题:如何使用尽可能少的标签数据来训练一个效果promising的分类器。作者提出了一个AIFT (active,incremental fine-tuning)网络,能够节约标注的时间和成本,把主动学习和迁移学习集成到一个框架。AIFT算法开始是直接使用一个预训练从未标注数据里找一些比较值得标注的样本,然后模型持续的加入新标注的数据,一直做微调。
AIFT方法是在CAD(计算机辅助诊断)系统的环境下使用,CAD可以生成候选集U,都是未标注数据,其中每一个候选样本(candidate)通过数据增强可以生成一系列的patches,由于这些patches来自于同一个候选样本,所以它们的标签跟该候选样本一致。
(一)AIFT方法的优势
1、 从一个完全未标注的数据集开始,不需要初始的种子标注数据。
训练的初期不需要使用打好标签的数据对预训练的CNN模型进行训练,而是通过直接把未标注的数据导入预训练好的CNN网络中,得到预测值,挑出最难的,或者说是对于模型来说最不容易判断属于哪一类的图像来(文中采用的是熵和多样性的大小),人工打上标签再放进网络中进行训练。
2、通过持续的fine-tuning而不是重复的重新训练来一步一步改善学习器。
3、通过挖掘每一个候选样本的补丁的一致性来选择值得标注的候选集。
4、自动处理噪音
5、只对每个候选集中小数量的补丁计算熵和KL距离,节约了计算,也大大节省了计算损耗。
(二) AIFT的创新点
1. 持续性的fine-tuning
一开始标注数据集L是空的,我们拿一个已经训练好了的CNN(比如AlexNet),让它在未标注数据集U中选b个候选集来找医生标注,这新标注的候选集将会放到标注数据集L中,来持续的增量式fine-tune那个CNN直到合格,通过实验发现,持续的fine-tuning CNN相比在原始的预训练中重复性的fine-tuning CNN,可以让数据集收敛更快。
2. 通过Active learning选择候选样本
主动学习的关键是找到一个标准来评判候选样本是否值得标注,在当前CNN中,一个候选样本生成的所有patches都应该是有差不多的预测。所以我们可以先通过这个CNN来对每个候选样本的每个patch进行预测,然后对每个候选样本,通过计算patch的熵和patch之间KL距离来衡量这个候选样本。如果熵越高,说明包含更多的信息,如果KL距离越大,说明patch间的不一致性大,所以这两个指标越高,越有可能对当前的CNN优化越大。对每个矩阵都可以生成一个包含patch的KL距离和熵的邻接矩阵R。
既然用了迁移学习,那么一开始的CNN测试的效果肯定是一团糟,因为这个CNN是从自然图像中学过来的,没有学习过CT这种医学影像,所以这个loop的启动阶段,Active Learning的效果会没有random selecting好。不过很快,随着CNN慢慢地在labeled的CT上训练,Active Learning的效果会一下子超过random selecting。
接下来讨论Continuous fine-tuning的细节,随着labeled data集变大,CNN需要一次次地被训练,有两种选择,一是每次都从ImageNetpretrained来的model来迁移,二是每次用当前的model上面迁移(ContinuousFine-tuning)。方法一的优点是模型的参数比较好控制,因为每次都是从头开始fine-tuning,但是缺点是随着labeled数据量大增加,GPU的消耗很大,相当于每次有新的标注数据来的时候,就把原来的model扔了不管,在实际应用中的代价还是很大的。第二种方法是从当前的model基础上做fine tune,在某种意义上knowledge是有记忆的,而且是连续渐进式的学习。问题在于参数不好控制,例如learning rate,需要适当的减小,而且比较容易在一开始掉入local minimum。
3. 通过少数服从多数来处理噪音
我们普遍都会使用一些自动的数据增强的方法,来提高CNN的表现,但是不可避免的给某些候选样本生成了一些难的样本,给数据集注入了一些噪音。所以为了显著的提高我们方法的鲁棒性,我们依照于当前CNN的预测,对每个候选样本只选择一部分的patch来计算熵和多样性。首先对每个候选样本的所有patch,计算平均的预测概率,如果平均概率大于0.5,我们只选择概率最高的部分patch,如果概率小于0.5,选最低的部分patch,再基于已经选择的patch,来构建得分矩阵R。
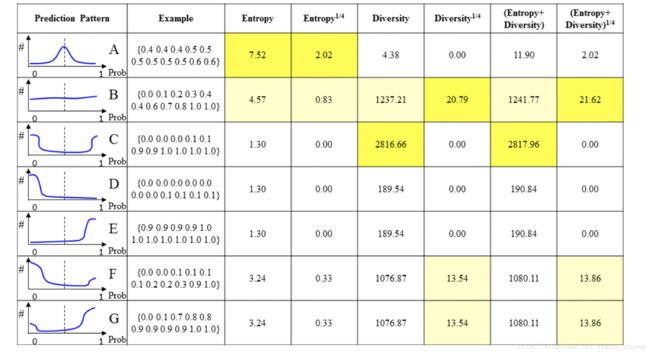
预测出的结果有不同的模式:
对每个候选样本进行计算所有补丁的概率分布直方图,对于概率的分布有以下几种模式:
1、Pattern A: patch大部分集中在0.5,不确定性很高,大多数的主动学习算法都喜欢这种候选集。
2、Pattern B:比a还更好,预测从0-1分布均匀,导致了更高的不确定性,因为所有的patch都是通过同一个候选集数据增强得到,他们理论上应该要有差不多的预测。这种类型的候选集有明显优化CNN模型的潜力。
3、Pattern C:预测分布聚集在两端,导致了更高的多样性,但是很有可能和patch的噪声有关,这是主动学习中最不喜欢的样本,因为有可能在fine-tuning的时候迷惑CNN,导致微调混乱。
4、Pattern D\E: 预测分布集中在一端(0或1),包含更高的确定性,这类数据的标注优先级要降低,因为当前模型已经能够很好的预测它们了。
5、Pattern F\G: 在某些补丁的预测中有更高的确定性,并且有些还和离群点有关联,这类候选集是有价值的,因为能够平滑的改善CNN的表现,尽管不能有显著的贡献,但对当前CNN模型不会有任何伤害。
(三) AIFT模型结构
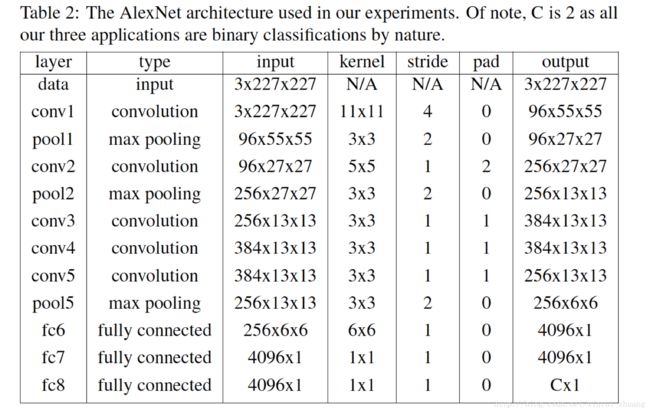
该算法在caffe框架下基于预训练的AlexNet模型下实现的,采用了6种评价图像难度的方式,同时在比较时也与没有进行主动学习的增量微调算法和没有预训练过程的网络进行了比较,考虑的比较全面。如下图所示,
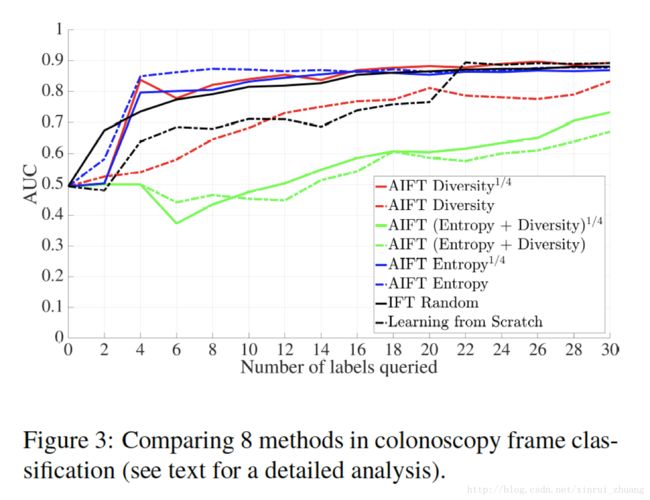
(四) AIFT算法的效果
上述方法被应用在了结肠镜视频帧分类和肺栓塞检测上,得到了比较好的效果。前者只用了800个候选样本就达到了最好的表现,只用了5%的候选样本就代表了剩下的候选样本,因为连续的视频帧通常都差不多。后者使用了1000个样本就达到了AlexNet做Fine-tune使用2200个随机样本的效果。
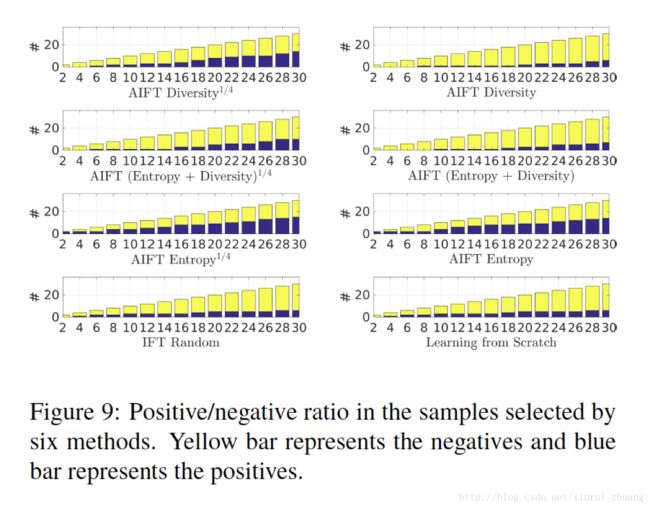
如Figure 9所示,作者最后对自己提出的6中不同的评价图像复杂度的方法进行了比较,AIFT Diversity1/4,AIFTEntropy1/4以及AIFT (Diversity +Entropy)1/4能够排除Pattern C/D/E对网络产生的不利影响,AIFT Entropy表现的也还可以,但是AIFT Diversity表现的比较差,将entropy anddiversity结合肯定是一个比较好的方法,但是就是很难找到这两个之间的比例关系。而且在训练的初始阶段,由于CNN网络没有经过微调,Pattern A/B占大多数,之后是Pattern C/D/E,在整个过程中Pattern B/F/G能够缓慢的提升训练效果。