SVDiff: Compact Parameter Space for Diffusion Fine-Tuning——【论文笔记】
本文发表于ICCV 2023
论文地址:ICCV 2023 Open Access Repository (thecvf.com)
官方代码:mkshing/svdiff-pytorch: Implementation of "SVDiff: Compact Parameter Space for Diffusion Fine-Tuning" (github.com)
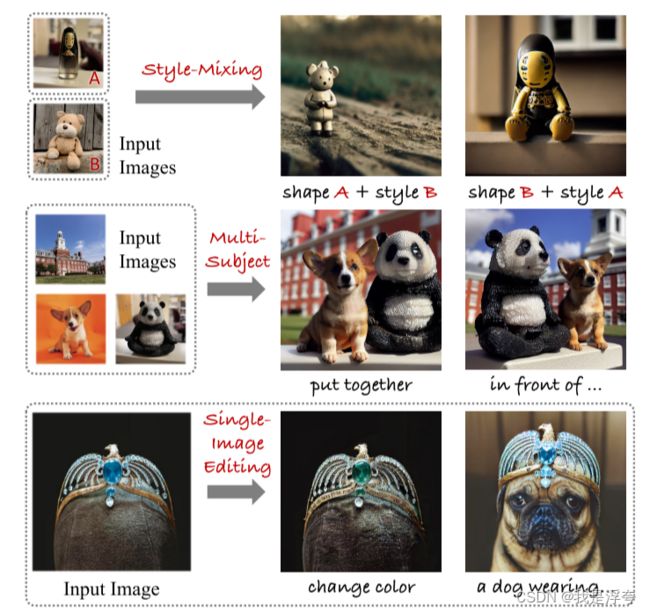
一、Introduction
最近几年,基于扩散的文本到图像生成模型取得了快速发展,使得简单的文本提示可以生成高质量的图像。这些模型具有现实主义和多样性,引发了研究人员对于图像编辑的兴趣。一些最近的作品如Textual-Inversion、DreamBooth和Custom Diffusion进一步发掘了大规模文本到图像扩散模型的潜力。这些方法通过微调预训练模型的参数,实现了模型适应特定任务或个人用户偏好。然而,微调大规模文本到图像扩散模型仍然面临一些限制。一个限制是参数空间过大可能导致过拟合或泛化能力下降。另一个挑战是学习多个个性化概念的困难,尤其当它们属于相似类别时。
为了解决这些问题,作者从GAN文献中得到启发,提出了一种紧凑而有效的参数空间,称为谱移。谱移通过仅微调模型权重矩阵的奇异值,减小了参数空间的规模,从而有助于缓解过拟合和语言漂移问题。此外,作者还提出了一种数据增强技术,即剪切-混合-分解方法,用于增强模型学习多个个性化概念的能力。通过这些方法,作者展示了基于文本的单图像编辑框架的应用,并为进一步研究提供了有前景的起点。
总而言之,这项工作的主要贡献是提出了一个紧凑而有效的参数空间,用于微调大规模文本到图像扩散模型,并提出了一种数据增强技术,为图像个性化和定制开辟了新的途径。
二、Related Work
这部分主要介绍了基于扩散模型的文本生成图像、个性化图像生成、图像编辑相关的知识,并引入论文所提出的方法SVDiff。
基于扩散的文本到图像生成模型通过微调文本嵌入、全权重、交叉注意力层或适配器等方式,使用少量个性化图片进行了模型的个性化调整。其他研究也探索了用于快速适应的无需训练的方法。在GAN领域,FSGAN引入了仅微调权重矩阵奇异值的概念,NaviGAN进一步通过无监督方法在这个紧凑参数空间中发现语义方向。我们的方法称为SVDiff,将这一概念引入到文本到图像扩散模型的微调中,并设计用于少样本迁移学习。LoRA是另一种类似的方法,探索了用于文本到图像扩散微调的低秩适配,而我们的SVDiff优化了权重矩阵的所有奇异值,从而得到了更小的模型检查点。类似的想法也在少样本分割中得到了探索。 除了文本到图像生成,扩散模型还显示出在语义编辑方面的巨大潜力。这些方法通常集中在通过优化空文本嵌入或过度拟合给定图像进行反演和重建。我们提出的方法SVDiff是基于DreamBooth的单图像编辑框架,展示了SVDiff在单图像编辑和减少过拟合方面的潜力。
三、Method
3.1 Preliminary
这部分讲述了本文是基于Stable-Diffusion来实现的,然后介绍了FSGAN,FSGAN基于奇异值分解(SVD)技术,并提出了一种有效的方法来适应少数设置中的GAN。它利用奇异值分解来学习一个紧凑的更新,用于在GAN的参数空间中进行域自适应,作者就是从此汲取的灵感。
3.2. Compact Parameter Space for Diffusion Fine-tuning
论文的核心思想就是把FSGAN中的谱移概念移入扩散模型的参数空间中,所以,首先要对预训练扩散模型的权重矩阵执行奇异值分解(SVD),具体过程如下图:

对于这幅图,我的理解是这样的:
a. Convolution:SVDiff操作在模型的中间层执行,Wtensor即模型的卷积层的权重矩阵。
b. Matrix Multiplication:在模型的中间层中,卷积权重起到了关联记忆的作用,这意味着它能够捕捉输入数据中的某些关联模式或特征。
c. 奇异值分解(SVD):这部分就是对权重矩阵进行奇异值分解。
首先获得模型中间层的卷积权重矩阵Wtensor,然后对Wtensor进行重塑,将其转换为一个二维矩阵W,以便执行奇异值分解。然后对W进行奇异值分解,将W分解成三个矩阵的乘积:U、Σ 和 V^T。其中,U 和 V 是正交矩阵,Σ 是一个对角矩阵,其对角线上的元素称为奇异值。
接下来,我们只微调奇异值,而不是整个权重矩阵。这样可以减少参数空间的大小,从而减少过拟合的风险,并提高模型的泛化能力。最后,我们将微调后的奇异值与原始的正交矩阵和对角矩阵相乘,得到新的权重矩阵。通过这种方式,SVDiff方法能够有效地优化模型的参数空间,提高模型的性能和效率。
执行奇异值分解后,将变形后的权重矩阵与变形后的特征贴片相乘,实现了f_out = W*f_in的操作。这个操作的目的是利用奇异值分解后得到的新的权重矩阵来对输入特征贴片进行变换,从而获得更具有表征能力的特征表示。这种操作可以帮助模型学习到数据中的更复杂的模式和结构,从而提高模型的泛化能力和生成能力。通过奇异值分解和权重更新,SVDiff方法能够有效地优化模型的参数空间,提高模型的性能和效率。
3.3 Cut-Mix-Unmix for Multi-Subject Generation
在使用StableDiffusion模型同时训练多个概念时,我们发现在一些困难的合成或相似类别的主题上,模型往往会在渲染图像时混合它们的风格。为了明确告诉模型不要混合个性化风格,提出了一种简单的技巧,称为Cut-Mix-Unmix。
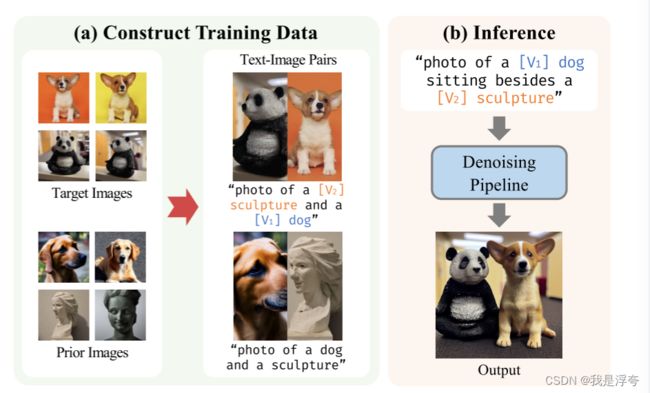
通过构建和呈现“正确”切割和混合的图像样本,我们指导模型进行风格分离。这个方法的主要原理就是:手动创建类似于CutMix的图像样本和相应的提示(例如“左边是一个[V1]的狗和右边是一个[V2]的雕塑”或者“左边是[V2]的雕塑和右边是一个[V1]的狗”)。先验损失样本以类似的方式生成。在训练时,Cut-Mix-Unmix数据增强被以预定义的概率应用(通常设为0.6)。这个概率没有设为1,因为这样做会让模型在区分主题时变得困难。在推断阶段,我们使用与训练时不同的提示,例如“一只坐在[V1]的狗旁边的[V2]的雕塑”。然而,如果模型过度拟合了Cut-Mix-Unmix样本,即使使用不同的提示,它可能仍会生成带有拼接伪影的样本。然后论文中提到,使用负面提示有时可以缓解这些伪影。
由于微调后的模型中,狗的特殊标记往往在熊猫的区域上增加了关注度。为了强制两个主题之间的分离,我们在交叉注意力图的非对应区域上使用均方误差(MSE)。这个损失鼓励狗的特殊标记只关注狗,而熊猫的特殊标记只关注熊猫。这个扩展的结果显示出了明显减少的拼接伪影,这就是通过在交叉注意力图上加入“分离”正则化。
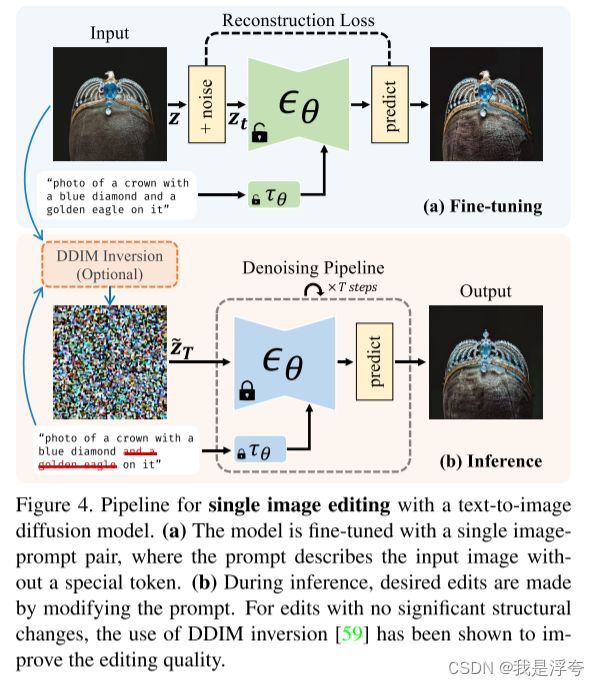
3.4. Single-Image Editing
针对单张图片的编辑,基于SVDiff方法,论文提出了一个编辑框架,在这个框架中,使用单图像编辑的方式来实现对图像的编辑。我们通过将图像和相应的文本对输入到一个扩散模型中,通过微调模型来实现所需的编辑。在推理时,通过修改提示来获得所需的编辑效果。
为了减轻微调过程中的过拟合问题,使用频谱转移参数空间而不是完整的权重。对于不需要进行大量结构变化的编辑,使用DDIM反演来改善结果。对于需要较大结构变化的编辑,可以在去噪过程中注入更多的噪声。
四、Experiment
实验评估了SVDiff在各种任务上的作用,例如单/多受试者生成、单个图像编辑和消融。DDIM 采样器(η = 0)用于所有生成的样本。
下图将SVDiff方法与当前几个流行方法在单个对象的个性化图像生成上进行比较的结果:
下图是在多个对象的个性化图像生成上所做的比较,主要是看论文所提出的数据增强技术Cut-Mix-Unmix的效果,Full的意思是更新整个权重矩阵(SVD方法只需要更新奇异值矩阵即可,无需更新整个权重矩阵)。
下图是利用论文所提的方法实现的图像编辑

接下来就是消融实验:
下表分析了微调UNet中的12个参数子集及其相应的模型大小,论文中提到:
(1)与优化关键和值投影相比,优化交叉注意(CA)层通常会更好地保留主题身份。(2)单独优化UNet的上、下或中间块不足以保持同一性,这就是为什么我们没有进一步隔离每个部分的子集。然而,看起来上块表现出最好的身份保护。(3)在维度方面,2D权重表现出最大的影响力,并提供比UNet-CA更好的身份保护。

下图(a)中的分析旨在研究在SVDiff方法中,不同主题之间的光谱偏移在模型微调过程中的表现。通过比较不同主题之间的光谱偏移相关性,以了解模型在学习和区分不同主题时的表现如何。
为了计算光谱偏移的相关性,作者首先对每一层的权重矩阵进行奇异值分解,得到奇异值矩阵。然后,通过计算不同主题之间的奇异值矩阵的余弦相似度的平均值评估它们之间的相关性。 余弦相似度是一种常用的相似度度量方法,用于衡量两个向量方向的相似程度。在这种情况下,奇异值矩阵可以看作是一个向量,因此可以使用余弦相似度来比较不同主题之间的奇异值矩阵。通过计算奇异值矩阵的余弦相似度,可以得出不同主题之间的光谱偏移相关性。如果余弦相似度接近1,表示两个主题之间的奇异值矩阵非常相似,相关性较高;如果余弦相似度接近0,表示两个主题之间的奇异值矩阵差异很大,相关性较低。
通过计算不同主题之间的光谱偏移的余弦相似度,可以评估模型在微调过程中是否能够有效地区分不同主题,并且能否保持主题之间的独特性。如果不同主题之间的光谱偏移相关性较低,说明模型在学习和区分不同主题时表现良好,能够保持主题之间的差异性。
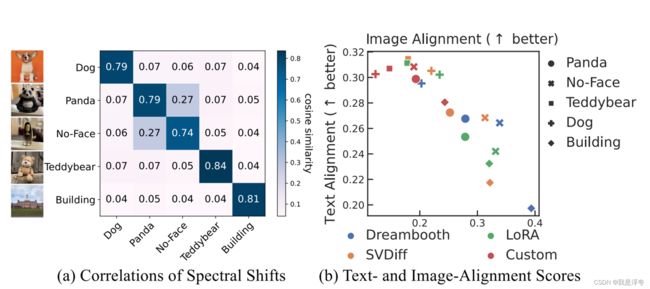
上图中,图(b) 则是针对论文所提出的方法和其他方法在单个对象个性化图像生成上,针对文本相关性和图像相关性所做的图表,从图中可知,论文所提出的方法有着更好的表现。