YOLOv3训练KITTI数据集
YOLOv3训练KITTI数据集——Wiznote笔记
部分参考SSD: Single Shot MultiBox Detector 训练KITTI数据集(1),感谢博主的贡献。
目录
- 1 获取KITTI数据集及标签
- 2 将KITTI的标签格式转换为VOC数据格式的标签xxx.xml
- 2-1 使用modify_annotations_txt.py调整原来的8类为现在的3类
- 2-2 将原来KITTI标注的txt格式转换为PASCAL VOC的xml格式
- 3 将VOC格式的标签转换为YOLO格式的标签xxx.txt
- 4 生成train.txt和val.txt
- 5 准备数据的配置文件
- 5-1 准备kitti.names
- 5-2 准备kitti.data
- 5-3 准备yolov3-kitti.cfg
- 6 下载ImageNet预训练的网络参数
- 7 训练模型
- 8 测试
- 9 中断训练后继续训练
1 获取KITTI数据集及标签
打开KITTI官方网址,出现以下网页:

由于我们只做2D的对象检测,只需要下载第一项Download left color images of object data set (12 GB)和对应的标签Download training labels of object data set (5 MB)。下载并解压完毕后,我们可以发现文件夹data_object_image_2存放了训练集和测试集图片,其中训练集有7481张,测试集有7518张,共有 8个类别:Car(小轿车),Van(面包车),Truck(卡车),Tram(电车),Pedestrain(行人),Person(sit-ting)(行人),Cyclist(骑行人),Misc(杂项)。还有一项DontCare为不关心的物体,文件夹training存放了训练集的标签,而测试集没有给出标签。文件目录树分布如下:
├── data_object_image_2
│ ├── testing
│ │ └── image_2
├── 000000.png
├── 000001.png
│ └── training
│ │ └── image_2
├── 000000.png
├── 000001.png
│ └── image_2
└── training
└── label_2
├── 000000.txt
├── 000001.txt
├── 000002.txt
我们这里用全部的7481张图片用来训练。
2 将KITTI的标签格式转换为VOC数据格式的标签xxx.xml
我们创建一个PASCAL VOC结构的文件夹目录形式,原来PASCAL VOC目录结构如下:

其中,Annotations文件夹存放标签文件xxxx.xml,ImageSets文件夹存放了各种任务(Action,Segmentation,Detection)需要的训练集和验证集的图片名汇总,我们这里不需要这个文件夹,JPEGImages文件夹存放了所有的图片,labels文件夹存放了darknet框架的标签格式文件xxxx.txt。同一张图片的xml标签格式和txt标签格式如下所示:
2008_000003.jpg

2008_000003.txt:
# class_id x y w h
18 0.546 0.5165165165165165 0.908 0.9669669669669669
14 0.145 0.6501501501501501 0.042 0.15915915915915915
2008_000003.xml
<annotation>
<folder>VOC2012folder>
<filename>2008_000003.jpgfilename>
<source>
<database>The VOC2008 Databasedatabase>
<annotation>PASCAL VOC2008annotation>
<image>flickrimage>
source>
<size>
<width>500width>
<height>333height>
<depth>3depth>
size>
<segmented>0segmented>
<object>
<name>trainname>
<pose>Unspecifiedpose>
<truncated>1truncated>
<occluded>0occluded>
<bndbox>
<xmin>46xmin>
<ymin>11ymin>
<xmax>500xmax>
<ymax>333ymax>
bndbox>
<difficult>0difficult>
object>
<object>
<name>personname>
<pose>Rightpose>
<truncated>1truncated>
<occluded>0occluded>
<bndbox>
<xmin>62xmin>
<ymin>190ymin>
<xmax>83xmax>
<ymax>243ymax>
bndbox>
<difficult>0difficult>
object>
annotation>
txt格式里面的x,y,w,h对于xml的转换公式如下:
x = ( x m i n + x m a x ) / ( 2 ∗ w i d t h ) x=(xmin+xmax)/(2*width) x=(xmin+xmax)/(2∗width)
y = ( y m i n + y m a x ) / ( 2 ∗ h e i g h t ) y=(ymin+ymax)/(2*height) y=(ymin+ymax)/(2∗height)
w = ( x m a x − x m i n ) / ( w i d t h ) w=(xmax-xmin)/(width) w=(xmax−xmin)/(width)
这里的w为整个对象的宽度的占图片总宽度的比,在darknet中,一般还要把w除以2
h = ( y m a x − y m i n ) / ( h e i g h t ) h=(ymax-ymin)/(height) h=(ymax−ymin)/(height)
这里的h为整个对象的高读的占图片总高度的比,在darknet中,一般还要把h除以2
我们这里模仿PASCAL VOC目录格式,创建一个VOC_KITTI文件夹,里面分别创建Annotations文件夹(用于存放将要生成的标签文件xxxx.xml),JPEGImages文件夹(用于存放KITTI所有的训练图片),Labels文件夹(用于存放了KITTI的标签格式文件xxxx.txt),还有两个脚本文件modify_annotations_txt.py和kitti_txt_to_xml.py,具体用法下面再讲。如下图所示:

这里Annotations有14962项的原因是生成了xml和下面要讲的生成的darknet格式的标签文件。
2-1 使用modify_annotations_txt.py调整原来的8类为现在的3类
以下提供一个脚本modify_annotations_txt.py来将原来的8类物体转换为我们现在需要的3类:Car,Pedestrain,Cyclist。我们把原来的Car、Van、Truck,Tram合并为Car类,把原来的Pedestrain,Person(sit-ting)合并为现在的Pedestrain,原来的Cyclist这一类保持不变。
# modify_annotations_txt.py
import glob
import string
txt_list = glob.glob('./Labels/*.txt') # 存储Labels文件夹所有txt文件路径
def show_category(txt_list):
category_list= []
for item in txt_list:
try:
with open(item) as tdf:
for each_line in tdf:
labeldata = each_line.strip().split(' ') # 去掉前后多余的字符并把其分开
category_list.append(labeldata[0]) # 只要第一个字段,即类别
except IOError as ioerr:
print('File error:'+str(ioerr))
print(set(category_list)) # 输出集合
def merge(line):
each_line=''
for i in range(len(line)):
if i!= (len(line)-1):
each_line=each_line+line[i]+' '
else:
each_line=each_line+line[i] # 最后一条字段后面不加空格
each_line=each_line+'\n'
return (each_line)
print('before modify categories are:\n')
show_category(txt_list)
for item in txt_list:
new_txt=[]
try:
with open(item, 'r') as r_tdf:
for each_line in r_tdf:
labeldata = each_line.strip().split(' ')
if labeldata[0] in ['Truck','Van','Tram']: # 合并汽车类
labeldata[0] = labeldata[0].replace(labeldata[0],'Car')
if labeldata[0] == 'Person_sitting': # 合并行人类
labeldata[0] = labeldata[0].replace(labeldata[0],'Pedestrian')
if labeldata[0] == 'DontCare': # 忽略Dontcare类
continue
if labeldata[0] == 'Misc': # 忽略Misc类
continue
new_txt.append(merge(labeldata)) # 重新写入新的txt文件
with open(item,'w+') as w_tdf: # w+是打开原文件将内容删除,另写新内容进去
for temp in new_txt:
w_tdf.write(temp)
except IOError as ioerr:
print('File error:'+str(ioerr))
print('\nafter modify categories are:\n')
show_category(txt_list)
执行命令python modify_annotations_txt.py运行脚本,将原来的8类物体转换为现在的3类。这里以000010.txt为例,展示原来的8类标签格式和现在的3类标签格式。
# 原来的标签
Car 0.80 0 -2.09 1013.39 182.46 1241.00 374.00 1.57 1.65 3.35 4.43 1.65 5.20 -1.42
Car 0.00 0 1.95 354.43 185.52 549.52 294.49 1.43 1.70 3.95 -2.39 1.66 11.80 1.76
Pedestrian 0.00 2 1.41 859.54 159.80 879.68 221.40 1.96 0.72 1.09 8.33 1.55 23.51 1.75
Car 0.00 0 -1.78 819.63 178.12 926.85 251.56 1.51 1.60 3.24 5.85 1.64 16.50 -1.44
Car 0.00 2 -1.69 800.54 178.06 878.75 230.56 1.45 1.74 4.10 6.87 1.62 22.05 -1.39
Car 0.00 0 1.80 558.55 179.04 635.05 230.61 1.54 1.68 3.79 -0.38 1.76 23.64 1.78
Car 0.00 2 1.77 598.30 178.68 652.25 218.17 1.49 1.52 3.35 0.64 1.74 29.07 1.79
Car 0.00 1 -1.67 784.59 178.04 839.98 220.10 1.53 1.65 4.37 7.88 1.75 28.53 -1.40
Car 0.00 1 1.92 663.74 175.36 707.21 204.15 1.64 1.45 3.48 4.50 1.80 42.85 2.02
DontCare -1 -1 -10 737.69 163.56 790.86 197.98 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 135.60 185.44 196.06 202.15 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 796.02 162.52 862.73 183.40 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 879.35 165.65 931.48 182.36 -1 -1 -1 -1000 -1000 -1000 -10
# 现在生成的标签
Car 0.80 0 -2.09 1013.39 182.46 1241.00 374.00 1.57 1.65 3.35 4.43 1.65 5.20 -1.42
Car 0.00 0 1.95 354.43 185.52 549.52 294.49 1.43 1.70 3.95 -2.39 1.66 11.80 1.76
Pedestrian 0.00 2 1.41 859.54 159.80 879.68 221.40 1.96 0.72 1.09 8.33 1.55 23.51 1.75
Car 0.00 0 -1.78 819.63 178.12 926.85 251.56 1.51 1.60 3.24 5.85 1.64 16.50 -1.44
Car 0.00 2 -1.69 800.54 178.06 878.75 230.56 1.45 1.74 4.10 6.87 1.62 22.05 -1.39
Car 0.00 0 1.80 558.55 179.04 635.05 230.61 1.54 1.68 3.79 -0.38 1.76 23.64 1.78
Car 0.00 2 1.77 598.30 178.68 652.25 218.17 1.49 1.52 3.35 0.64 1.74 29.07 1.79
Car 0.00 1 -1.67 784.59 178.04 839.98 220.10 1.53 1.65 4.37 7.88 1.75 28.53 -1.40
Car 0.00 1 1.92 663.74 175.36 707.21 204.15 1.64 1.45 3.48 4.50 1.80 42.85 2.02
2-2 将原来KITTI标注的txt格式转换为PASCAL VOC的xml格式
原来一张图片的KITTI标注格式如下:
Car 0.00 0 -1.67 642.24 178.50 680.14 208.68 1.38 1.49 3.32 2.41 1.66 34.98 -1.60
Car 0.00 0 -1.75 685.77 178.12 767.02 235.21 1.50 1.62 3.89 3.27 1.67 21.18 -1.60
具体含义如下:
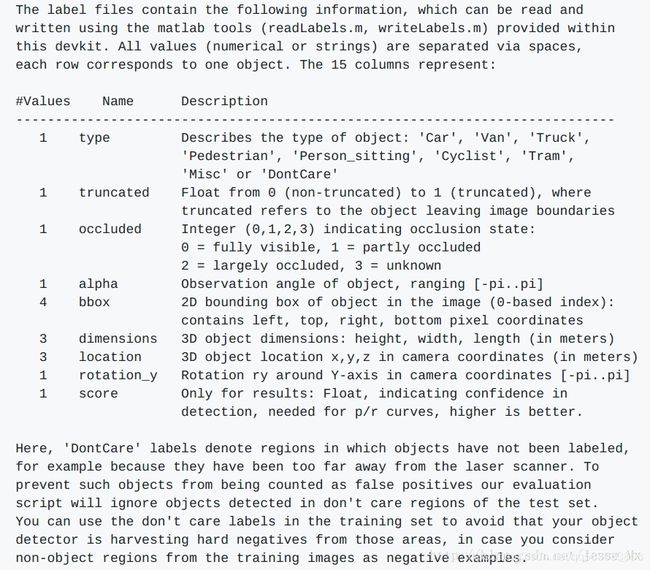
我们现在只需要该标签的type、bbox等五项,还需要把float类型转换为int类型,最后将生成的xml文件存放于Annotations文件夹中,使用脚本kitti_txt_to_xml.py。
# kitti_txt_to_xml.py
# encoding:utf-8
# 根据一个给定的XML Schema,使用DOM树的形式从空白文件生成一个XML
from xml.dom.minidom import Document
import cv2
import os
def generate_xml(name,split_lines,img_size,class_ind):
doc = Document() # 创建DOM文档对象
annotation = doc.createElement('annotation')
doc.appendChild(annotation)
title = doc.createElement('folder')
title_text = doc.createTextNode('KITTI')
title.appendChild(title_text)
annotation.appendChild(title)
img_name=name+'.png'
title = doc.createElement('filename')
title_text = doc.createTextNode(img_name)
title.appendChild(title_text)
annotation.appendChild(title)
source = doc.createElement('source')
annotation.appendChild(source)
title = doc.createElement('database')
title_text = doc.createTextNode('The KITTI Database')
title.appendChild(title_text)
source.appendChild(title)
title = doc.createElement('annotation')
title_text = doc.createTextNode('KITTI')
title.appendChild(title_text)
source.appendChild(title)
size = doc.createElement('size')
annotation.appendChild(size)
title = doc.createElement('width')
title_text = doc.createTextNode(str(img_size[1]))
title.appendChild(title_text)
size.appendChild(title)
title = doc.createElement('height')
title_text = doc.createTextNode(str(img_size[0]))
title.appendChild(title_text)
size.appendChild(title)
title = doc.createElement('depth')
title_text = doc.createTextNode(str(img_size[2]))
title.appendChild(title_text)
size.appendChild(title)
for split_line in split_lines:
line=split_line.strip().split()
if line[0] in class_ind:
object = doc.createElement('object')
annotation.appendChild(object)
title = doc.createElement('name')
title_text = doc.createTextNode(line[0])
title.appendChild(title_text)
object.appendChild(title)
bndbox = doc.createElement('bndbox')
object.appendChild(bndbox)
title = doc.createElement('xmin')
title_text = doc.createTextNode(str(int(float(line[4]))))
title.appendChild(title_text)
bndbox.appendChild(title)
title = doc.createElement('ymin')
title_text = doc.createTextNode(str(int(float(line[5]))))
title.appendChild(title_text)
bndbox.appendChild(title)
title = doc.createElement('xmax')
title_text = doc.createTextNode(str(int(float(line[6]))))
title.appendChild(title_text)
bndbox.appendChild(title)
title = doc.createElement('ymax')
title_text = doc.createTextNode(str(int(float(line[7]))))
title.appendChild(title_text)
bndbox.appendChild(title)
# 将DOM对象doc写入文件
f = open('Annotations/'+name+'.xml','w')
f.write(doc.toprettyxml(indent = ''))
f.close()
if __name__ == '__main__':
class_ind=('Pedestrian', 'Car', 'Cyclist')
cur_dir=os.getcwd()
labels_dir=os.path.join(cur_dir,'Labels')
for parent, dirnames, filenames in os.walk(labels_dir): # 分别得到根目录,子目录和根目录下文件
for file_name in filenames:
full_path=os.path.join(parent, file_name) # 获取文件全路径
f=open(full_path)
split_lines = f.readlines()
name= file_name[:-4] # 后四位是扩展名.txt,只取前面的文件名
img_name=name+'.png'
img_path=os.path.join('./JPEGImages/',img_name) # 路径需要自行修改
img_size=cv2.imread(img_path).shape
generate_xml(name,split_lines,img_size,class_ind)
print('all txts has converted into xmls')
由于我们使用KITTI提供的共7481张训练集图片作为我们的训练集,因此,这里第86行代码为JPEGImages文件夹内的所有图片, 生成的xml文件存放于第72行的Annotations文件夹内。
执行命令python kitti_txt_to_xml.py,生成PASCAL VOC格式的xml文件。这里以000010.txt为例,展示原来的txt标签格式和现在xml标签格式。
# 步骤2-1生成的txt格式
Car 0.80 0 -2.09 1013.39 182.46 1241.00 374.00 1.57 1.65 3.35 4.43 1.65 5.20 -1.42
Car 0.00 0 1.95 354.43 185.52 549.52 294.49 1.43 1.70 3.95 -2.39 1.66 11.80 1.76
Pedestrian 0.00 2 1.41 859.54 159.80 879.68 221.40 1.96 0.72 1.09 8.33 1.55 23.51 1.75
Car 0.00 0 -1.78 819.63 178.12 926.85 251.56 1.51 1.60 3.24 5.85 1.64 16.50 -1.44
Car 0.00 2 -1.69 800.54 178.06 878.75 230.56 1.45 1.74 4.10 6.87 1.62 22.05 -1.39
Car 0.00 0 1.80 558.55 179.04 635.05 230.61 1.54 1.68 3.79 -0.38 1.76 23.64 1.78
Car 0.00 2 1.77 598.30 178.68 652.25 218.17 1.49 1.52 3.35 0.64 1.74 29.07 1.79
Car 0.00 1 -1.67 784.59 178.04 839.98 220.10 1.53 1.65 4.37 7.88 1.75 28.53 -1.40
Car 0.00 1 1.92 663.74 175.36 707.21 204.15 1.64 1.45 3.48 4.50 1.80 42.85 2.02
# 此时转换的xml格式
KITTI
000010.png
The KITTI Database
KITTI
1242
375
3
3 将VOC格式的xml标签转换为darknet格式的标签xxx.txt
我们现在已经有了VOC标签格式的xml文件,现在我们需要生成darknet中YOLO使用的txt标签格式。我们在VOC_KITTI文件夹内创建一个xml_to_yolo_txt.py文件,代码如下:
# xml_to_yolo_txt.py
# 此代码和VOC_KITTI文件夹同目录
import glob
import xml.etree.ElementTree as ET
# 这里的类名为我们xml里面的类名,顺序现在不需要考虑
class_names = ['Car', 'Cyclist', 'Pedestrian']
# xml文件路径
path = './Annotations/'
# 转换一个xml文件为txt
def single_xml_to_txt(xml_file):
tree = ET.parse(xml_file)
root = tree.getroot()
# 保存的txt文件路径
txt_file = xml_file.split('.')[0]+'.txt'
with open(txt_file, 'w') as txt_file:
for member in root.findall('object'):
#filename = root.find('filename').text
picture_width = int(root.find('size')[0].text)
picture_height = int(root.find('size')[1].text)
class_name = member[0].text
# 类名对应的index
class_num = class_names.index(class_name)
box_x_min = int(member[4][0].text) # 左上角横坐标
box_y_min = int(member[4][1].text) # 左上角纵坐标
box_x_max = int(member[4][2].text) # 右下角横坐标
box_y_max = int(member[4][3].text) # 右下角纵坐标
# 转成相对位置和宽高
x_center = float(box_x_min + box_x_max) / (2 * picture_width)
y_center = float(box_y_min + box_y_max) / (2 * picture_height)
width = float(box_x_max - box_x_min) / picture_width
height = float(box_y_max - box_y_min) / picture_height
print(class_num, x_center, y_center, width, height)
txt_file.write(str(class_num) + ' ' + str(x_center) + ' ' + str(y_center) + ' ' + str(width) + ' ' + str(height) + '\n')
# 转换文件夹下的所有xml文件为txt
def dir_xml_to_txt(path):
for xml_file in glob.glob(path + '*.xml'):
single_xml_to_txt(xml_file)
dir_xml_to_txt(path)
执行命令:python xml_to_yolo_txt.py,生成的txt文件在Annotations文件夹内。这里以000010.txt为例,展示原来的xml标签格式和现在darknet的txt标签格式。
# 原来的xml格式
KITTI
000010.png
The KITTI Database
KITTI
1242
375
3
# 现在darknet的txt文件格式
0 0.9074074074074074 0.7413333333333333 0.09178743961352658 0.256
0 0.3635265700483092 0.6386666666666667 0.0785024154589372 0.14533333333333334
2 0.6996779388083736 0.5066666666666667 0.008051529790660225 0.08266666666666667
0 0.7024959742351047 0.572 0.0430756843800322 0.09733333333333333
0 0.6755233494363929 0.544 0.03140096618357488 0.06933333333333333
0 0.48027375201288247 0.5453333333333333 0.030998389694041867 0.068
0 0.5032206119162641 0.528 0.021739130434782608 0.05333333333333334
0 0.6533816425120773 0.5306666666666666 0.02214170692431562 0.056
0 0.5515297906602254 0.5053333333333333 0.017713365539452495 0.03866666666666667
可以看出,原来的bbox数据现在已经全部归一化,原来的Car类型变成现在的索引0,原来的Pedestrain类型变成现在的索引2。
4 生成train.txt和val.txt
现在我们需要生成train.txt文件,里面存放了每一张训练图片的路径,由于我们没有测试,可以先不生成val.txt。这里我们在darknet安装目录下创建一个kitti_train_val.py文件,代码如下:
# kitti_train_val.py
# 此代码和data文件夹同目录
import glob
path = 'kitti_data/'
def generate_train_and_val(image_path, txt_file):
with open(txt_file, 'w') as tf:
for jpg_file in glob.glob(image_path + '*.png'):
tf.write(jpg_file + '\n')
generate_train_and_val(path + 'train_images/', path + 'train.txt') # 生成的train.txt文件所在路径
# generate_train_and_val(path + 'val_images/', path + 'val.txt') # 生成的val.txt文件所在路径
根据代码可以看出,我们需要在daeknet安装目录下创建一个kitti_data文件夹,里面需要创建train_images文件夹和val_images文件夹,此外我们还需要创建train_labels和val_labels文件夹,我们把VOC_KITTI/JPEGImages文件夹里面的图片剪切或复制到kitti_data/train_images下,把VOC_KITTI/Annotaations下的txt文件剪切或复制到kitti_data/train_labels下,可以执行命令:
# 剪切图片
mv VOC_KITTI/JPEGImages/* darknet/kitti_data/train_images
# 剪切标签
mv VOC_KITTI/Annotaations/*.txt darknet/kitti_data/train_labels
接着在darknet路径下打开终端,执行命令:python kitti_train_val.py,最终在kitti_data目录下生成train.txt和val.txt。
如下所示:
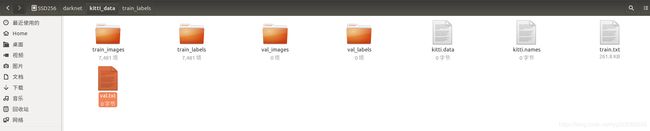
这里的kitti.data和kitti.names即将创建。
5 准备数据的配置文件
现在我们需要准备kitti.data、kitti.names和网络模型配置文件yolov3-kitti.cfg。
5-1 准备kitti.names
kitti.names存放了每一类的类名,这个将在测试一张图片时显示一个物体的标签名。文件内容如下(注意顺序要与xml_to_yolo_txt.py文件里面的顺序一致。):
Car
Pedestrian
Cyclist
5-2 准备kitti.data
kitti.data内容如下,其中classes表示类的数目,train和val表示第4步生成的train.txt和val.txt的存放路径,backup表示训练的yolo权重存放的位置。
classes= 3
train = kitti_data/train.txt
valid = kitti_data/val.txt
names = kitti_data/kitti.names
backup = backup/
5-3 准备yolov3-kitti.cfg
在darknet/cfg目录下,创建一个文件yolov3-kitti.cfg,里面的内容可以先拷贝yolov3.cfg,在修改以下几个部分:
- 三处classes=80修改为classes=3
- 三处filters=255(注意只需要修改[yolo]上面的[convolutional]的filters)修改为filters=24( filters=3*(classes+5) ),如下:
[convolutional]
size=1
stride=1
pad=1
filters=255 # 此处需要修改为filters=24
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=80
num=9
注意,这里的yolov3的filters的计算公式为 filters=3*(classes+5),yolov2的filter的计算公式为 filters=num*(classes+coords+1),yolov1的计算公式为 filters=sideside(num*5+classes)。
- 还可以修改batch,subdivisions和max_batches等参数。其中batch表示一个批次训练的图片数目,一个epoch=total_train_images/batch,而subdivisions表示将一个batch分为subdivisions个组进行分别训练,每个组有batch/subdivisions个图片。max_batches表示最大的批次数,而iterations=max_batches/batch。
6 下载ImageNet预训练的网络参数
yolov3默认的训练权重为darknet53,我们可以在darknet路径下打开终端,输入命令下载权重:
wget https://pjreddie.com/media/files/darknet53.conv.74
7 训练模型
./darknet detector train kitti_data/kitti.data cfg/yolov3-kitti.cfg darknet53.conv.74
在训练中,终端会打印输出
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000000, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: 0.879770, Class: 0.999963, Obj: 0.999019, No Obj: 0.000455, .5R: 1.000000, .75R: 1.000000, count: 2
Region 106 Avg IOU: 0.726660, Class: 0.981278, Obj: 0.848324, No Obj: 0.000362, .5R: 0.933333, .75R: 0.600000, count: 15
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000000, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000001, .5R: -nan, .75R: -nan, count: 0
Region 106 Avg IOU: 0.739621, Class: 0.999773, Obj: 0.788386, No Obj: 0.000512, .5R: 0.937500, .75R: 0.625000, count: 16
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000000, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000000, .5R: -nan, .75R: -nan, count: 0
Region 106 Avg IOU: 0.842399, Class: 0.999971, Obj: 0.978920, No Obj: 0.000325, .5R: 1.000000, .75R: 1.000000, count: 11
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000000, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000012, .5R: -nan, .75R: -nan, count: 0
Region 106 Avg IOU: 0.705575, Class: 0.949637, Obj: 0.893539, No Obj: 0.000549, .5R: 0.888889, .75R: 0.555556, count: 18
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000220, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: 0.885422, Class: 0.999904, Obj: 0.996486, No Obj: 0.000944, .5R: 1.000000, .75R: 1.000000, count: 5
Region 106 Avg IOU: 0.685692, Class: 0.999810, Obj: 0.818832, No Obj: 0.000441, .5R: 0.866667, .75R: 0.400000, count: 15
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000000, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: 0.917769, Class: 0.999986, Obj: 0.999057, No Obj: 0.000483, .5R: 1.000000, .75R: 1.000000, count: 2
Region 106 Avg IOU: 0.734660, Class: 0.999783, Obj: 0.806102, No Obj: 0.000853, .5R: 0.857143, .75R: 0.500000, count: 28
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000290, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: 0.883034, Class: 0.999598, Obj: 0.952420, No Obj: 0.000755, .5R: 1.000000, .75R: 1.000000, count: 5
Region 106 Avg IOU: 0.763281, Class: 0.999828, Obj: 0.776274, No Obj: 0.000371, .5R: 0.857143, .75R: 0.642857, count: 14
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000000, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000002, .5R: -nan, .75R: -nan, count: 0
Region 106 Avg IOU: 0.788140, Class: 0.999921, Obj: 0.805065, No Obj: 0.000677, .5R: 1.000000, .75R: 0.761905, count: 21
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000000, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: 0.823024, Class: 0.999452, Obj: 0.746079, No Obj: 0.000631, .5R: 1.000000, .75R: 0.600000, count: 5
Region 106 Avg IOU: 0.734842, Class: 0.999643, Obj: 0.771043, No Obj: 0.000651, .5R: 0.950000, .75R: 0.500000, count: 20
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000000, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: 0.832970, Class: 0.999085, Obj: 0.915872, No Obj: 0.000134, .5R: 1.000000, .75R: 1.000000, count: 1
Region 106 Avg IOU: 0.647650, Class: 0.999931, Obj: 0.914428, No Obj: 0.000316, .5R: 0.818182, .75R: 0.363636, count: 11
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000000, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000000, .5R: -nan, .75R: -nan, count: 0
Region 106 Avg IOU: 0.647275, Class: 0.998951, Obj: 0.835732, No Obj: 0.000277, .5R: 1.000000, .75R: 0.200000, count: 10
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000000, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: 0.859042, Class: 0.999873, Obj: 0.920159, No Obj: 0.001146, .5R: 1.000000, .75R: 1.000000, count: 8
Region 106 Avg IOU: 0.760058, Class: 0.999575, Obj: 0.829456, No Obj: 0.000763, .5R: 0.950000, .75R: 0.650000, count: 20
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000000, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: 0.780092, Class: 0.999876, Obj: 0.873641, No Obj: 0.000480, .5R: 1.000000, .75R: 0.500000, count: 2
Region 106 Avg IOU: 0.714661, Class: 0.998230, Obj: 0.930809, No Obj: 0.000893, .5R: 0.862069, .75R: 0.551724, count: 29
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000000, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: 0.748140, Class: 0.999394, Obj: 0.698991, No Obj: 0.000304, .5R: 0.666667, .75R: 0.666667, count: 3
Region 106 Avg IOU: 0.661677, Class: 0.999870, Obj: 0.814655, No Obj: 0.000667, .5R: 0.818182, .75R: 0.318182, count: 22
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000000, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: 0.839435, Class: 0.994511, Obj: 0.497955, No Obj: 0.000293, .5R: 1.000000, .75R: 1.000000, count: 2
Region 106 Avg IOU: 0.697895, Class: 0.999256, Obj: 0.669627, No Obj: 0.000654, .5R: 0.958333, .75R: 0.333333, count: 24
Region 82 Avg IOU: -nan, Class: -nan, Obj: -nan, No Obj: 0.000000, .5R: -nan, .75R: -nan, count: 0
Region 94 Avg IOU: 0.858090, Class: 0.999985, Obj: 0.999754, No Obj: 0.000153, .5R: 1.000000, .75R: 1.000000, count: 1
Region 106 Avg IOU: 0.664703, Class: 0.989184, Obj: 0.793579, No Obj: 0.000681, .5R: 0.791667, .75R: 0.458333, count: 24
13202: 0.830514, 0.765624 avg, 0.001000 rate, 4.867255 seconds, 844928 images
Loaded: 0.000038 seconds
8 测试
我们把batch设为64,经过13200iterations后,我们可以把KITTI的测试集中找一些图片放在darknet/data/目录下,输入以下命令在一张图片进行测试
./darknet detector test kitti_data/kitti.data cfg/yolov3-kitti.cfg backup/yolov3-kitti.backup data/000005.png

可以看出,预测对象及其种类的精度还可以,但是定位误差较大,还需要再训练一段时间看看。
9 中断训练后继续训练
./darknet detector train kitti_data/kitti.data cfg/yolov3-kitti.cfg backup/yolov3-kitti.backup -gpus 0,1,2,3