《FreeAnchor: Learning to Match Anchors for Visual Object Detection》笔记
Introduction
在目标检测中,从图片上预测出一些region proposals,这些region proposals会与预先设置好的anchors进行匹配,匹配的方式是nms,超过给定IoU阈值就匹配,否则不匹配。这种通过IoU指标进行匹配有缺点:在空间上对齐的region proposal,从它提取出来的特征不一定能够很好地预测object的类别和位置。论文给出了例子,对于长条形状的物体,非中心化的物体,比如牙刷,空间上对齐的region proposal包含许多背景信息,导致特征的表征能力变弱,而牙刷的最具表征的部位是牙刷头部。针对这个问题,有许多论文研究尝试去掉anchor,这些方法称为anchor free方法。论文方法没有去掉anchor,而是能够让物体灵活地匹配anchor,从而能够学习到对分类和定位最具有表征能力的特征。
什么样的匹配方式是最好的呢?首先保证算法有高的召回率。检测器要保证对于每个object,至少有一个anchor对应的预测接近gt。或者说每个gt对应的anchor都要有一个proposal与之匹配。第二,算法要有高的预测精度。检测器需要把定位错误的proposal分类成背景类。定位错误的proposal预测的结果一般预测的不准,把false position去掉,能够提高预测精度。第三,anchor的匹配预测要与最后一步NMS兼容,例如,分类分数越高,定位要越准确。否则,定位准确但分类分数低的proposal会在nms中抛弃掉。
论文把object-anchor匹配问题定义成最大似然估计问题。具体的描述请看下文。
Detector Training as Maximum Likelihood Estimation
检测问题可以设计成极大似然估计问题,具体如下。
以一阶CNN-based目标检测算法为例。给定一张图片 I I I,gt是 B B B,其中一个gt box b i ∈ B b_i \in B bi∈B,对应类别 b i c l s b_i^{cls} bicls和位置 b i l o c b_i^{loc} biloc。在网络中,每个anchor a j ∈ A a_j \in A aj∈A 有类别预测 a j c l s ∈ R k a_j^{cls} \in \mathcal{R}^k ajcls∈Rk和位置预测 a j l o c ∈ R 4 a_j^{loc} \in \mathcal{R}^4 ajloc∈R4,k表示有k个分类类别。
在训练过程,nms方法会把anchors与objects对齐,如下图
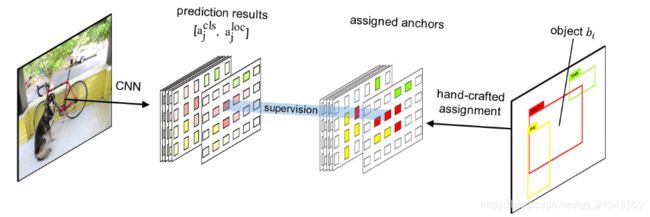
有一个矩阵 C i j ∈ { 0 , 1 } C_{ij} \in \{0, 1\} Cij∈{0,1},定义object b i b_i bi是否匹配anchor a j a_j aj。当 b i b_i bi和 a j a_j aj的IoU大于一个阈值时, b i b_i bi和 b j b_j bj匹配, C i j = 1 C_{ij}=1 Cij=1,否则 C i j = 0 C_{ij}=0 Cij=0。特别地,当多个object的IoU大于阈值时,有最大IoU的object匹配这个anchor,保证每个anchor只和最匹配的一个object配对,例如 ∑ i C i j ∈ 0 , 1 , ∀ a j ∈ A \sum_{i}C_{ij} \in {0, 1}, \forall a_j \in A ∑iCij∈0,1,∀aj∈A。
假设有3个box b 1 , b 2 , b 3 b_1, b_2, b_3 b1,b2,b3,有4个anchor a 1 , a 2 , a 3 , a 4 a_1, a_2, a_3, a_4 a1,a2,a3,a4,两两配对的IoU值如下
| a 1 a_1 a1 | a 2 a_2 a2 | a 3 a_3 a3 | a 4 a_4 a4 | |
|---|---|---|---|---|
| b 1 b_1 b1 | 0.3 | 0.2 | 0.7 | 0.1 |
| b 2 b_2 b2 | 0.8 | 0.4 | 0.2 | 0.7 |
| b 3 b_3 b3 | 0.1 | 0.3 | 0.2 | 0.9 |
假设IoU阈值设置为0.5,则可以去掉一些匹配选项
| a 1 a_1 a1 | a 2 a_2 a2 | a 3 a_3 a3 | a 4 a_4 a4 | |
|---|---|---|---|---|
| b 1 b_1 b1 | 0 | 0 | 0.7 | 0 |
| b 2 b_2 b2 | 0.8 | 0 | 0 | 0.7 |
| b 3 b_3 b3 | 0 | 0 | 0 | 0.9 |
对于 a 4 a_4 a4那列,只选择最匹配的一项,即 b 3 b_3 b3
| a 1 a_1 a1 | a 2 a_2 a2 | a 3 a_3 a3 | a 4 a_4 a4 | |
|---|---|---|---|---|
| b 1 b_1 b1 | 0 | 0 | 1 | 0 |
| b 2 b_2 b2 | 1 | 0 | 0 | 0 |
| b 3 b_3 b3 | 0 | 0 | 0 | 1 |
所以 ∑ i C i j ∈ 0 , 1 , ∀ a j ∈ A \sum_{i}C_{ij} \in {0, 1}, \forall a_j \in A ∑iCij∈0,1,∀aj∈A。定义 A + ⊆ A A_{+} \subseteq A A+⊆A为 { a j ∣ ∑ i C i j = 1 } \{a_j | \sum_i C_{ij} = 1\} {aj∣∑iCij=1}, A − ⊆ A A_{-} \subseteq A A−⊆A为 { a j ∣ ∑ i C i j = 0 } \{a_j | \sum_i C_{ij} = 0\} {aj∣∑iCij=0}。看上例,则 a 1 , a 3 , a 4 ∈ A + a_1, a_3, a_4 \in A_{+} a1,a3,a4∈A+, a 2 ∈ A − a_2 \in A_{-} a2∈A−。
算法(一阶算法)的损失函数是
L ( θ ) = ∑ a j ∈ A + ∑ b i ∈ B C i j L ( θ ) i j c l s + β ∑ a j ∈ A + ∑ b i ∈ B C i j L ( θ ) i j l o c + ∑ a j ∈ A − L ( θ ) j b g \mathcal{L}(\theta) = \sum_{a_j \in A_+} \sum_{b_i \in B} C_{ij} \mathcal{L}(\theta)_{ij}^{cls} + \beta \sum_{a_j \in A_+} \sum_{b_i \in B} C_{ij} \mathcal{L}(\theta)_{ij}^{loc} + \sum_{a_j \in A_-} \mathcal{L}(\theta)_j^{bg} L(θ)=aj∈A+∑bi∈B∑CijL(θ)ijcls+βaj∈A+∑bi∈B∑CijL(θ)ijloc+aj∈A−∑L(θ)jbg
上式3项分别表示objects的分类损失,objects的定位损失和背景类的分类损失。没和object匹配的anchors都划分为背景类。 θ \theta θ表示模型参数。 L ( θ ) i j c l s = B C E ( a j c l s , b i c l s , θ ) \mathcal{L}(\theta)_{ij}^{cls} = BCE(a_j^{cls}, b_i^{cls}, \theta) L(θ)ijcls=BCE(ajcls,bicls,θ), L ( θ ) i j l o c = S m o o t h L 1 ( a j l o c , b i l o c , θ ) \mathcal{L}(\theta)_{ij}^{loc} = SmoothL1(a_j^{loc}, b_i^{loc}, \theta) L(θ)ijloc=SmoothL1(ajloc,biloc,θ), L ( θ ) j b g = B C E ( a j c l s , 0 ⃗ , θ ) \mathcal{L}(\theta)_{j}^{bg} = BCE(a_j^{cls}, \vec{0}, \theta) L(θ)jbg=BCE(ajcls,0,θ)。BCE表示二元交叉熵损失。 β \beta β表示正则化参数。
损失 L ( θ ) \mathcal{L}(\theta) L(θ)可以转成最大似然问题
P ( θ ) = e − L ( θ ) = e − ∑ a j ∈ A + ∑ b i ∈ B C i j L ( θ ) i j c l s − β ∑ a j ∈ A + ∑ b i ∈ B C i j L ( θ ) i j l o c − ∑ a j ∈ A − L ( θ ) j b g = e − ∑ a j ∈ A + ∑ b i ∈ B C i j L ( θ ) i j c l s e − β ∑ a j ∈ A + ∑ b i ∈ B C i j L ( θ ) i j l o c e − ∑ a j ∈ A − L ( θ ) j b g = ∏ a j ∈ A + e − ∑ b i ∈ B C i j L ( θ ) i j c l s ∏ a j ∈ A + e − ∑ b i ∈ B C i j L ( θ ) i j l o c ∏ a j ∈ A − e − L ( θ ) j b g \begin{aligned} \mathcal{P}(\theta) & = e^{-\mathcal{L}(\theta)} \\ & = e^{-\sum_{a_j \in A_+} \sum_{b_i \in B} C_{ij} \mathcal{L}(\theta)_{ij}^{cls} - \beta \sum_{a_j \in A_+} \sum_{b_i \in B} C_{ij} \mathcal{L}(\theta)_{ij}^{loc} - \sum_{a_j \in A_-} \mathcal{L}(\theta)_j^{bg} } \\ & = e^{-\sum_{a_j \in A_+} \sum_{b_i \in B} C_{ij} \mathcal{L}(\theta)_{ij}^{cls}} e^{- \beta \sum_{a_j \in A_+} \sum_{b_i \in B} C_{ij} \mathcal{L}(\theta)_{ij}^{loc} } e^{ -\sum_{a_j \in A_-} \mathcal{L}(\theta)_j^{bg} } \\ & = \prod_{a_j \in A_+} e^{-\sum_{b_i \in B} C_{ij} \mathcal{L}(\theta)_{ij}^{cls}} \prod_{a_j \in A_+} e^{-\sum_{b_i \in B} C_{ij} \mathcal{L}(\theta)_{ij}^{loc}} \prod_{a_j \in A_-} e^{- \mathcal{L}(\theta)_{j}^{bg}} \end{aligned} P(θ)=e−L(θ)=e−∑aj∈A+∑bi∈BCijL(θ)ijcls−β∑aj∈A+∑bi∈BCijL(θ)ijloc−∑aj∈A−L(θ)jbg=e−∑aj∈A+∑bi∈BCijL(θ)ijclse−β∑aj∈A+∑bi∈BCijL(θ)ijloce−∑aj∈A−L(θ)jbg=aj∈A+∏e−∑bi∈BCijL(θ)ijclsaj∈A+∏e−∑bi∈BCijL(θ)ijlocaj∈A−∏e−L(θ)jbg
因为 C i j ∈ { 0 , 1 } C_{ij} \in \{0, 1\} Cij∈{0,1},而且 A + ⊆ A A_{+} \subseteq A A+⊆A为 { a j ∣ ∑ i C i j = 1 } \{a_j | \sum_i C_{ij} = 1\} {aj∣∑iCij=1},所以可以把 C i j C_{ij} Cij移动e的外面
P ( θ ) = e − L ( θ ) = ∏ a j ∈ A + e − ∑ b i ∈ B C i j L ( θ ) i j c l s ∏ a j ∈ A + e − ∑ b i ∈ B C i j L ( θ ) i j l o c ∏ a j ∈ A − e − L ( θ ) j b g = ∏ a j ∈ A + ( ∑ b i ∈ B C i j e − L ( θ ) i j c l s ) ∏ a j ∈ A + ( ∑ b i ∈ B C i j e − L ( θ ) i j l o c ) ∏ a j ∈ A − e − L ( θ ) j b g \begin{aligned} \mathcal{P}(\theta) & = e^{-\mathcal{L}(\theta)} \\ & = \prod_{a_j \in A_+} e^{-\sum_{b_i \in B} C_{ij} \mathcal{L}(\theta)_{ij}^{cls}} \prod_{a_j \in A_+} e^{-\sum_{b_i \in B} C_{ij} \mathcal{L}(\theta)_{ij}^{loc}} \prod_{a_j \in A_-} e^{- \mathcal{L}(\theta)_{j}^{bg}} \\ & = \prod_{a_j \in A_+} (\sum_{b_i \in B} C_{ij} e^{-\mathcal{L}(\theta)_{ij}^{cls}} )\prod_{a_j \in A_+} (\sum_{b_i \in B} C_{ij} e^{-\mathcal{L}(\theta)_{ij}^{loc}}) \prod_{a_j \in A_-} e^{- \mathcal{L}(\theta)_{j}^{bg}} \end{aligned} P(θ)=e−L(θ)=aj∈A+∏e−∑bi∈BCijL(θ)ijclsaj∈A+∏e−∑bi∈BCijL(θ)ijlocaj∈A−∏e−L(θ)jbg=aj∈A+∏(bi∈B∑Cije−L(θ)ijcls)aj∈A+∏(bi∈B∑Cije−L(θ)ijloc)aj∈A−∏e−L(θ)jbg
考虑上例的 a 1 a_1 a1
e − C 01 L ( θ ) 01 c l s − C 11 L ( θ ) 11 c l s − C 21 L ( θ ) 21 c l s = e − 0 L ( θ ) 01 c l s − 1 L ( θ ) 11 c l s − 0 L ( θ ) 21 c l s = e − L ( θ ) 11 c l s = 0 e − L ( θ ) 01 c l s + 1 e − L ( θ ) 11 c l s + e − L ( θ ) 21 c l s = ∑ b i ∈ B C i 1 e − L ( θ ) i 1 c l s \begin{aligned} & e^{-C_{01} \mathcal{L}(\theta)_{01}^{cls} -C_{11} \mathcal{L}(\theta)_{11}^{cls} -C_{21} \mathcal{L}(\theta)_{21}^{cls}} \\ &= e^{-0 \mathcal{L}(\theta)_{01}^{cls} -1 \mathcal{L}(\theta)_{11}^{cls} -0 \mathcal{L}(\theta)_{21}^{cls}} \\ &= e^{-\mathcal{L}(\theta)_{11}^{cls}} \\ &= 0 e^{-\mathcal{L}(\theta)_{01}^{cls}} + 1e^{-\mathcal{L}(\theta)_{11}^{cls}} + e^{-\mathcal{L}(\theta)_{21}^{cls}} \\ & = \sum_{b_i \in B} C_{i1} e^{-\mathcal{L}(\theta)_{i1}^{cls}} \end{aligned} e−C01L(θ)01cls−C11L(θ)11cls−C21L(θ)21cls=e−0L(θ)01cls−1L(θ)11cls−0L(θ)21cls=e−L(θ)11cls=0e−L(θ)01cls+1e−L(θ)11cls+e−L(θ)21cls=bi∈B∑Ci1e−L(θ)i1cls
令 P ( θ ) i j c l s = e − L ( θ ) i j c l s \mathcal{P}(\theta)_{ij}^{cls} = e^{-\mathcal{L}(\theta)_{ij}^{cls}} P(θ)ijcls=e−L(θ)ijcls为类别的置信度。 L \mathcal{L} L公式中有log函数,与外面的e函数抵消后,就是类别的置信度(概率)。对定位损失套用相同的公式, P ( θ ) i j l o c = e − L ( θ ) i j l o c \mathcal{P}(\theta)_{ij}^{loc} = e^{-\mathcal{L}(\theta)_{ij}^{loc}} P(θ)ijloc=e−L(θ)ijloc表示为定位的置信度。那么
P ( θ ) = e − L ( θ ) = ∏ a j ∈ A + ( ∑ b i ∈ B C i j e − L ( θ ) i j c l s ) ∏ a j ∈ A + ( ∑ b i ∈ B C i j e − L ( θ ) i j l o c ) ∏ a j ∈ A − e − L ( θ ) i j b g = ∏ a j ∈ A + ( ∑ b i ∈ B C i j P ( θ ) i j c l s ) ∏ a j ∈ A + ( ∑ b i ∈ B C i j P ( θ ) i j l o c ) ∏ a j ∈ A − P ( θ ) j b g \begin{aligned} \mathcal{P}(\theta) & = e^{-\mathcal{L}(\theta)} \\ & = \prod_{a_j \in A_+} (\sum_{b_i \in B} C_{ij} e^{-\mathcal{L}(\theta)_{ij}^{cls}} )\prod_{a_j \in A_+} (\sum_{b_i \in B} C_{ij} e^{-\mathcal{L}(\theta)_{ij}^{loc}}) \prod_{a_j \in A_-} e^{- \mathcal{L}(\theta)_{ij}^{bg}} \\ & = \prod_{a_j \in A_+} (\sum_{b_i \in B} C_{ij} \mathcal{P}(\theta)_{ij}^{cls}) \prod_{a_j \in A_+} (\sum_{b_i \in B} C_{ij} \mathcal{P}(\theta)_{ij}^{loc}) \prod_{a_j \in A_-} \mathcal{P}(\theta)_{j}^{bg} \end{aligned} P(θ)=e−L(θ)=aj∈A+∏(bi∈B∑Cije−L(θ)ijcls)aj∈A+∏(bi∈B∑Cije−L(θ)ijloc)aj∈A−∏e−L(θ)ijbg=aj∈A+∏(bi∈B∑CijP(θ)ijcls)aj∈A+∏(bi∈B∑CijP(θ)ijloc)aj∈A−∏P(θ)jbg
上述公式就是极大似然估计的公式。目标检测就转成了极大似然估计问题。
考虑如何把通过nms得到的匹配矩阵 C i j C_{ij} Cij去掉,通过学习得到匹配矩阵 C i j C_{ij} Cij。
Detection Customized Likelihood
现在的目标是让网络自己学到最优的object-anchor匹配,保证算法具有高的召回率和精度,同时和预测后的NMS操作兼容。论文的做法首先是构造 a bag of candidate anchors for each object b i b_i bi by selecting (n) top-ranked anchors A i ⊂ A A_i \subset A Ai⊂A in terms of their IoU with the object. 根据IoU为每个object选择top-n个anchor。接着,通过最大化自定义的似然来学习匹配的最佳的anchor。
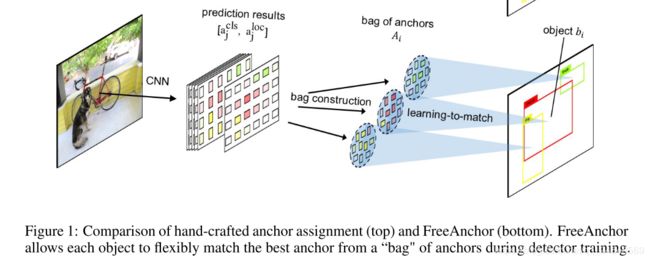
为了优化召回率,对于每个object b i ∈ B b_i \in B bi∈B,首先要保证至少有一个anchor a j ∈ A i a_j \in A_i aj∈Ai,它的预测( a j c l s a_j^{cls} ajcls和 a j l o c a_j^{loc} ajloc)接近gt。这个目标可以通过下面的公式来实现
P r e c a l l = ∏ i max a j ∈ A i ( P ( θ ) i j c l s P ( θ ) i j l o c ) \mathcal{P}_{recall} = \prod_i \max_{a_j \in A_i} (\mathcal{P}(\theta)_{ij}^{cls} \mathcal{P}(\theta)_{ij}^{loc}) Precall=i∏aj∈Aimax(P(θ)ijclsP(θ)ijloc)
为了提升检测的精度,检测器需要把定位差的anchor分类成背景类。令 P { a j → b i } P\{a_j \to b_i\} P{aj→bi}表示anchor a j a_j aj 正确预测object b i b_i bi的概率。anchor a j a_j aj最后匹配的是object b i , i = arg max P { a j → b i } b_i, i = \arg \max P\{a_j \to b_i\} bi,i=argmaxP{aj→bi}。因此,anchor a j a_j aj有匹配object的概率是 max i P { a j → b i } \max_i P\{a_j \to b_i\} maxiP{aj→bi}, 而 P { a j ∈ A − } = 1 − max i P { a j → b i } P\{a_j \in A_-\} = 1 - \max_i P\{a_j \to b_i\} P{aj∈A−}=1−maxiP{aj→bi}表示 a j a_j aj没有与任何object匹配的概率。如果anchor a j a_j aj没有与任何object匹配,那么anchor a j a_j aj的类别是背景类,它的背景类的预测置信度要高。论文的公式是
P ( θ ) p r e c i s i o n = ∏ j ( 1 − P { a j ∈ A − } ( 1 − P ( θ ) j b g ) ) \mathcal{P}(\theta)_{precision} = \prod_j (1 - P\{a_j \in A_-\}(1-\mathcal{P}(\theta)_j^{bg})) P(θ)precision=j∏(1−P{aj∈A−}(1−P(θ)jbg))
我认为是这样的,匹配为背景的anchor的预测类别不是背景类的概率要低。这个公式是为了提高精度,精度的定义是precision = TP/(TP + FP)。这个公式的作用是通过降低FP来提高精度。FP是指没有与任何一个gt box匹配,但是预测出其他类别(非背景类)的概率却很高的anchor。只要预测出其他类别(非背景类)的概率变低(这个公式的目的),这些没有和任何一个gt box匹配的anchor就不会是FP。
对于 P { a j → b i } P\{a_j \to b_i\} P{aj→bi},它应该具备以下性质。(1) P { a j → b i } P\{a_j \to b_i\} P{aj→bi}对于 a j l o c a_j^{loc} ajloc和 b i b_i bi,或者说 I o U i j l o c IoU_{ij}^{loc} IoUijloc,是一个单调递增函数。(2)当 I o U i j l o c IoU_{ij}^{loc} IoUijloc小于阈值 t t t, P { a j → b i } P\{a_j \to b_i\} P{aj→bi}要接近0。(3)对于一个object b i b_i bi,存在并且只存在一个 a j a_j aj满足 P { a j → b i } = 1 P\{a_j \to b_i\} = 1 P{aj→bi}=1。满足这些性质的公式是
Saturated linear ( x , t 1 , t 2 ) = { 0 , x ≤ t 1 x − t 1 t 2 − t 1 , t 1 < x < t 2 1 , x ≥ t 2 \text{Saturated linear}(x, t_1, t_2) = \begin{cases} 0, & x \le t_1 \\ \frac{x - t_1}{t_2 - t_1}, & t_1 \lt x \lt t_2 \\ 1, & x \ge t_2 \end{cases} Saturated linear(x,t1,t2)=⎩⎪⎨⎪⎧0,t2−t1x−t1,1,x≤t1t1<x<t2x≥t2
如下图所示
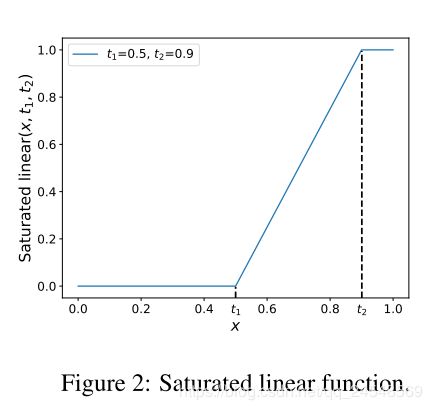
因此 P { a j → b i } = Saturated linear ( x , t , max j ( I o U i j l o c ) ) P\{a_j \to b_i\} = \text{Saturated linear}(x, t, \max_j (IoU_{ij}^{loc})) P{aj→bi}=Saturated linear(x,t,maxj(IoUijloc))。
最终,目标检测的自定义似然定义为
P ( θ ) = P ( θ ) r e c a l l × P ( θ ) p r e c i s i o n \mathcal{P}(\theta) = \mathcal{P}(\theta)_{recall} \times \mathcal{P}(\theta)_{precision} P(θ)=P(θ)recall×P(θ)precision
Anchor Matching Mechanism
上述的自定义依然转换成损失函数为
L = − log P ( θ ) = − ∑ i log ( max a j ∈ A i ( P ( θ ) i j c l s P ( θ ) i j l o c ) ) − ∑ j log ( 1 − P { a j ∈ A − } ( 1 − P ( θ ) j b g ) ) \begin{aligned} \mathcal{L} &= -\log \mathcal{P}(\theta) \\ &= -\sum_{i} \log (\max_{a_j \in A_i}(\mathcal{P}(\theta)_{ij}^{cls} \mathcal{P}(\theta)_{ij}^{loc})) - \sum_j \log (1 - P\{a_j \in A_-\}(1 - \mathcal{P}(\theta)_j^{bg})) \end{aligned} L=−logP(θ)=−i∑log(aj∈Aimax(P(θ)ijclsP(θ)ijloc))−j∑log(1−P{aj∈A−}(1−P(θ)jbg))
其中 max \max max函数用来为每个object选择最好的anchor。
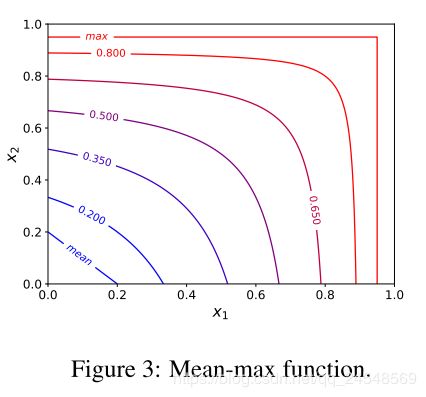
在训练早期,对于随机初始化网络参数,所有的anchors的置信度很小。高置信度的anchor对于检测器的训练来说不充足。论文提出了Mean-max函数
Mean-max X = ∑ x j ∈ X x j 1 − x j ∑ x j ∈ X 1 1 − x j \text{Mean-max}{X} = \frac{\sum_{x_j \in X} \frac{x_j}{1 - x_j}}{\sum_{x_j \in X} \frac{1}{1 - x_j}} Mean-maxX=∑xj∈X1−xj1∑xj∈X1−xjxj
用来选择anchors。但训练不充分时,Mean-max函数表现的像mean函数,意味着所有anchors都用来训练。随着训练增加,一些anchors的置信度增加,Mean-max函数表现像max函数,如下图
然后,损失函数变成
L ′ ( θ ) = − w 1 ∑ i log ( Mean-max ( X i ) ) + w 2 ∑ j FL_ ( P { a j ∈ A } ( 1 − P ( θ ) j b g ) ) \mathcal{L}'(\theta) = - w_1 \sum_{i} \log(\text{Mean-max}(X_i)) + w_2 \sum_j \text{FL\_}(P\{a_j \in A_\}(1 - \mathcal{P}(\theta)_j^{bg})) L′(θ)=−w1i∑log(Mean-max(Xi))+w2j∑FL_(P{aj∈A}(1−P(θ)jbg))
其中 X i = { P ( θ ) i j c l s P ( θ ) i j l o c ∣ a j ∈ A i } X_i = \{\mathcal{P}(\theta)_{ij}^{cls}\mathcal{P}(\theta)_{ij}^{loc} | a_j \in A_i\} Xi={P(θ)ijclsP(θ)ijloc∣aj∈Ai}。继承focal loss的参数 α \alpha α和 γ \gamma γ,设置 w 1 = α ∥ B ∥ w_1 = \frac{\alpha}{\lVert B \rVert} w1=∥B∥α, w 2 = 1 − α n ∥ B ∥ w_2 = \frac{1 - \alpha}{n\lVert B \rVert} w2=n∥B∥1−α。 FL_ ( p ) = − p γ log ( 1 − p ) \text{FL\_}(p)=-p^{\gamma} \log (1-p) FL_(p)=−pγlog(1−p)。
Experiments
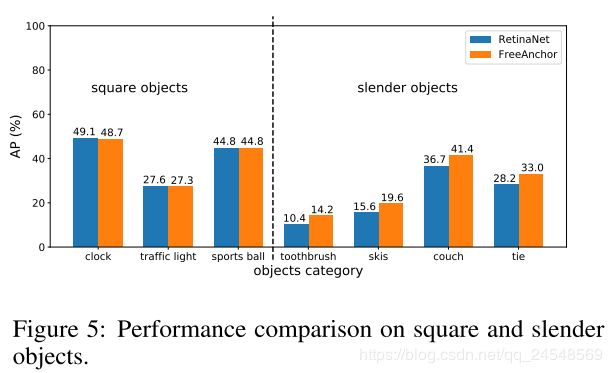
使用coco数据集,对于非中心化的类别,实验效果有提升,如
与其他模型的比较:
