题目:卷积神经网络中的每一个过滤器提取一个特定的特征
![[译] Every Filter Extracts A Specific Texture In Convolutional Neural Networks_第1张图片](http://img.e-com-net.com/image/info10/39d042efde5a40e9adbc1d49f2ac1084.jpg)
- 文章地址:《Every Filter Extracts A Specific Texture In Convolutional Neural Networks》 arXiv.1608.04170
- Github链接:https://github.com/xzqjack/FeatureMapInversion
(转载请注明出处:http://www.jianshu.com/p/20b854ffab02 ,谢谢!)
Abstract
摘要: 许多作品都集中在通过产生图像(激活一些特定神经元)来可视化并理解卷积神经网络(CNN)的内在机制,这称为深度可视化。然而,目前依旧尚不能直观的了解到过滤器从图像中提取了些什么。在本文中,我们提出了一种改进的代码的反演算法,称为特征映射反演,以助了解CNN的过滤功能。我们发现,每一个过滤器提取一个特定的纹理。从更高的层提取出的纹理包含更多的颜色和更复杂的结构。我们还表明,图像的风格可以是这些纹理基元的组合。两个方法被提出用于重新随机且有意图的分配特征映射。然后,我们逆转了修改后的代码,并生成不同风格的图像。有了这些结果,我们提供了一个解释:为什么特征图谱组成的梯度矩阵(Gram Matrix)可以代表图像风格。
关键词: 特征图谱, 有趣的滤镜,代码反转,原始纹理,风格化
一.简介
卷积神经网络在许多模式识别任务上达成了惊人的成就,特别是大规模的图片识别问题[2,3,4,5],然而,在一方面,CNN依旧很容易犯错。[6]表明,给图片添加人类无法识别的对抗噪声能导致CNN对图像的判定产生重大失误。[7]展示了一些相关的结果:我们很容易能通过进化算法来生成一些人类无法分辨的图片,但一些先进的CNN可以分辨图片到特定的类别(99.99%的置信度),另一方面,现在仍不是很清楚CNN到底是怎样从训练集中学习适合的特征,以及一个特征图谱到底代表着什么[8,9]。这种对CNN机制的不清晰敦促着最新的研究,将CNN可视化的研究,也称为深度可视化[10,11,12,13,14,15,16]。深度可视化目标是通过激活特定神经元来生成一个图片,解释CNN的内部机制,这可以给研究者们提供有意义、有帮助的见解,促进大家设计出更有效的网络结构。
这里有一些能用来理解CNN的深度可视化的技巧。也许最简单的方法就是展示一个确定层的响应,或者一些确定的特征映射。然而这些特征图谱仅提供了有限和直观的信息(针对滤镜和映射),例如,虽然他是可能找到一些针对特定对象响应的过滤器。比如[19]中的,这种方法是启发式的,而不是通用的。
一个主要的深度可视化技术是激活最大化[10],它找出一个图像,激活一些特定神经元,最深度的解释这些神经元对应的特征响应。[20]展示了通过alexnet在最后一层做激活最大化学习到的对象概念。[21]生成了相似的结果,通过把激活最大化应用在单个特征图谱上,[22]生成了一些有吸引力的图片,通过加强输入图像的在高层次的激活神经元,和低层次一样。这称为“深度的梦”。然而生成的图像是粗糙的,所以一系列子工作也集中在提升生成图片的质量(通过增加天然的先验例如L2正则化[20],全局方差范数[13])偏差[22],高斯模糊[21],数据驱动的补丁[13] ,除此之外,还有[24]也揭示了输入图片用不同的神经元学习出不同类型的特征。
另一个主要的深度可视化技术叫做编码反转[23],它产生的图像的激活代码和目标激活码在细节层非常相似。它揭示了哪些特征是从输入图像中用滤镜提取出来的。代码反转可以通过训练另一个神经网络,直接预测重建图片[25],或通过迭代优化一个初始噪声图像[26],或者把CNN的项目特征激活回输入像素的空间(用反卷积[18])这些反演方法也可以扩展到代码的统计属性。[27]设想了特征映射矩阵Gram matrix并发现它代表了图像的纹理。[1,28,29]利用gram matrix去做了图像风格化的工作。和激活最大化相比,代码反转更直观的揭示了从给定图像中用过滤器提取的确定的特征。
深度可视化方面,许多以前的工作揭示了一些有价值的揭示(对于不同层中的单个神经元[20,7],一个特征映射[21],或者代码[22]),卷积神经网络不再是一个完完全全的黑盒子。然而,我们最好的知识,仍然无法做到可视化每一个过滤器到底抓住了图像中的哪些因素。深入了解过滤器可以帮助改进现有神经网络的结构。
在这篇文章中我们提出了“特征映射反演”FMI,来解决前文提到的那些问题。对于一个有趣的滤波器,FMI同时增强了相关的特征映射,并削弱了其他的特征映射。然后将经典的代码反演算法应用于修改后的代码,并生成反演图像。我们的实验结果表明,在CNN每个滤波器提取特定的纹理。更高层次的纹理包含更多的颜色和更复杂的结构(图3)。另外,我们发现一个图像的风格是多层纹理基元的组合,两个方法被提出反转代码用来生成不同风格的图片,主要来说,我们改变代码,重新随机分配各特征映射的和,根据目标代码的目的来做。有了这些结果,我们提出了一个解释:为什么特征映射梯度矩阵能够代表图像的风格。因为每一个滤镜都提取出一个特定搞得纹理,各个特征映射相结合时的权重决定了图像的风格。就像特征映射沿通道轴的特征映射的综合,梯度矩阵也领导着各个特征映射在生成图片上的能力。
我们的实验建立在开源的深度学习框架mxnet[30],可以在https://github.com/xzqjack/FeatureMapInversion上看。
二. 方法
2.1.特征映射反演
![[译] Every Filter Extracts A Specific Texture In Convolutional Neural Networks_第2张图片](http://img.e-com-net.com/image/info10/16b7621388504268b79922ada024c8ca.jpg)
在这一节中,我们用FMI来回答这个问题:“CNN中一个滤镜到底从输入图像中获取了什么”,这里给出一个输入图片X(shape = 3 x H x W),一个训练过的CNN:φ 把输入图像编码成φ(x)(C x M x N)编码反转方法旨在找到一个新的图像X*,编码 **φ(X*) **和 φ(X) 要非常相似。就像图1中所示的,如果选择一个层(如VGG-19里的relu5_1)编码是一个3维Tensor。共有512个特征映射,每个映射的尺寸都是14 x 14,为了可视化的观察到第 l 个过滤器提取出了什么东西,我们应该加大第 l 层的特征映射到一定程度,并削弱其他的。在这篇论文中,我们把第L个特征映射设置成了沿通道轴线特征映射的和,其他的都设置成了0。最后,我们将采用经典的编码反转[23]应用给修改过的编码 ψ(φ(X),l)
![[译] Every Filter Extracts A Specific Texture In Convolutional Neural Networks_第3张图片](http://img.e-com-net.com/image/info10/4fbcef1a193d499c923b181b8d2bdf50.jpg)
这儿φ(X)_k,m,n表示第k个特征映射在位置(m,n)处激活。ψ(φ(X),l)增强了φ(X)的第 l 个特征映射,削弱了其他的。
2.2 修改编码反转
我们知道每一个过滤器能提取一个特定纹理,我们假设一个图片的风格可以被认为是多种纹理基元的结合。如果是这样,我们可以结合纹理基元,通过随机且有意图的修改特征映射的分布。那么如果我们把反转编码应用到修改过的编码中, 我们会得到不同种的 风格图。
随机修改的方法保证了神经元激活的状态(激活或者非激活)不变,但重新分配了每个特征映射的综合。我们最先生成了一个随机向量v
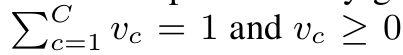
然后我们重新分配了每个特征映射向量v的权重。修改后的编码为:
![[译] Every Filter Extracts A Specific Texture In Convolutional Neural Networks_第4张图片](http://img.e-com-net.com/image/info10/531aa27c98dd47aa872713f4abbfdb4d.jpg)
我们把修改后的编码当成目标,保证图片的内容不变但是风格多样化的生成一张图片,如图4:
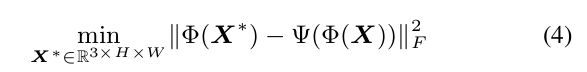
进一步,我们修改每个特征映射的比例,使得每个特征映射的和与目标代码相似。主要来说,假设我们有两个输入图片,内容图Xc(3 x Hc x Wc)风格图Xs(3 x Hs x Ws)。Xc 和 Xs 在某一层的特征映射被重构结构φ(Xc)=(C x Mc x Nc )和 φ(Xs)=(C x Ms x Ns )。我们用内容编码φ(Xc)作为内容约束,特征映射在通道轴上求和φ(Xs)作为风格约束。最后,我们产生一张风格图,通过下式:
![[译] Every Filter Extracts A Specific Texture In Convolutional Neural Networks_第5张图片](http://img.e-com-net.com/image/info10/88b3ce7948eb47a0995aacad0af5a89e.jpg)
内容和风格有着不同的权重
三.实验
3.1实验设置
我们把我们的实验建立在一个很有名的CNN网络上,名叫VGG19,这个网络被训练用来识别1000多种分类的物体,用于1.2亿图像ILSVRC 2014 Imagenet数据集。它包含了16个卷积层,16个relu层,5个池化层,总共5504个滤镜。所有的过滤器都是3x3的。我们不用任何的全连接层。在实验的过程中,我们把α设成10 β设成1,利用金门大桥和某大学作为内容图,在所有情况下结果如图2
3.2 特征映射反转
我们在图三中展示了有质量的FMI结果,最上的反演结果来自输入图像金门大桥,下面的反演来自于某大学,从上到下每行显示了特征映射反演(分别来自于5个不同的卷几层,relu1_2,relu2_2,relu3_2,relu4_2,relu5_2)在每行中,从左到右的列展示了第1~5个特征的反演结果。
数值结果表明,每一个过滤器提取一个特定的纹理。像图3所示的,不同的特征映射在不同的层的反演结果有不同的纹理,而相应的反演结果(a)和(b)有相同的纹理,包括颜色和基本结构。低层次的FMI比如relu1_2和relu2_2,生成图像的色彩比较单调,局部结构简单。随着层数的增加如relu4,relu5,色彩变得丰富,局部结构变得更加复杂。这个现象是合理的,因为更高层的特征映射可以被视为前面特征映射的非线性组合。例如,在低层的特征映射代表低层的语义属性,如边缘和角,然后高层的过滤器组装不同的边缘模式和角模式,组成更复杂的纹理。
![[译] Every Filter Extracts A Specific Texture In Convolutional Neural Networks_第6张图片](http://img.e-com-net.com/image/info10/4ecd7726a4bc4aa492bdab21cfda9001.jpg)
![[译] Every Filter Extracts A Specific Texture In Convolutional Neural Networks_第7张图片](http://img.e-com-net.com/image/info10/221e45e4444c45cbac02ab391a920c0b.jpg)
![[译] Every Filter Extracts A Specific Texture In Convolutional Neural Networks_第8张图片](http://img.e-com-net.com/image/info10/ae68039d7e784fb5bca1c9cb66791b7d.jpg)
3.3生成多种风格的图片
由于每个特征图谱代表一个特定的纹理,我们可以改变图像的风格,通过随机修改层次纹理的组合权重。图4显示了定性随机修改的编码反演结果。我们随机分配每个特征映射的总和(在relu1_1,relu2 1,relu3_1,relu4_1和relu5_1。对于每一层,我们产生两个随机反演结果。随机变化改变了激活神经元的激活程度,但未激活的保持了不变。同一列的两个生成的图像有不同的纹理。与输入图像相比,颜色在低层relu1_2, relu2_2有主要区别,结构是在1层relu4_1,relu5_1有主要区别,这支撑了我们的发现。
我们发现这很有趣,在高层次的反演结果中,包含更少的内容细节和更多的纹理。原因是,纹理重复块在高层次中包含了更多的复杂结构。然后内容图像是由许多独特的子结构组成,当子图像的结构与纹理不同时,部分内容信息被毁坏。最后整图的内容信息变得稀缺,许多复杂纹理出现。
此外,我们还实验了有目的地修改编码转化(PMCI)。图5中所生成的图像结合目标内容图像的编码和按一定分布的目标样式图的特征映射。特别是,我们选择4个风格的图像做实验:A Self Portrait with Necklace of Thorns, Femme nue assise, The Starry Night and Der Schrei.
我们用relu2_2层的编码当作内容项约束, 沿通道轴线relu1_1,和relu2_1,relu3_1,relu4_1,relu5_1作为风格的约束条件。第一列显示目标样式图像。第3,4列显示PMCI结果。我们还展示了Gatys等人风格化的图像[1]在第2和4列。
PMCI生成和风格目标相似的图像。我们可以直观的发现生成的图像在同一行上的风格很相似。这种相似性表明,特征映射的组合权重表示图像风格。因此,我们可以根据特征映射的能量分布,确定两个图像是不是相同的风格,有了这些结果,我们提供了一些见解,以理解为什么特征映射的梯度矩阵[1]可以代表图像风格。像沿通道轴的特征映射的总和,梯度矩阵也引导所生成的图像中每一个特征映射的占比。
四. 结论
我们提出了一个方法来可视化一个过滤器抓住了输入图像的哪个特征,通过反转感兴趣的特征映射。通过这个技术,我们证明了每一个过滤器提取一个特定的纹理。在更高层次上的反演结果包含更多的颜色和更复杂的结构。我们提出了两种方法来生成不同风格的图像。实验结果支持了我们的假设:一个图像的风格本质上是从CNN中获取的纹理基元的一种组合。除了产生不同风格的图像,我们还提供了一个解释:为什么特征映射组成的梯度矩阵[1]可以当作一个图像的风格表示。由于每一个过滤器提取一个特定的纹理,特征映射组合时的权重决定的图像的风格。像沿通道轴的特征映射的总和,梯度矩阵也引导着生成图像的每一个特征映射的分布。
References
[1] L.A. Gatys, A.S. Ecker, and M. Bethge, “Image style transfer using convolutional neural networks,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
[2] C. Szegedy, W. Liu, Y.Q. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 1–9.
[3] A. Krizhevsky, I. Sutskever, and G.E. Hinton, “Imagenet classification with deep convolutional neural networks,” in Advances in Neural Information Processing Systems (NIPS), 2012, pp. 1097–1105.
[4] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” CoRR, vol. abs/1409.1556, 2014.
[5] K.M. He, X.Y. Zhang, S.Q. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016.
[6] I.J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” International Conference on Learning Representations (ICLR), 2015.
[7] A. Nguyen, J. Yosinski, and J. Clune, “Deep neural networks are easily fooled: High confidence predictions for unrecognizable images,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2015, pp.427–436.
[8] J. Yosinski, C. Jeff, Y. Bengio, and H. Lipson, “How transferable are features in deep neural networks?,” in Advances in Neural Information Processing Systems (NIPS), 2014, pp. 3320–3328.
[9] Y.X. Li, J. Yosinski, J. Clune, H. Lipson, and J. Hopcroft, “Convergent learning: Do different neural networks learn the same representations?,” in Advances in Neural Information Processing Systems (NIPS), 2015, pp. 196–212.
[10] Dumitru Erhan, Yoshua Bengio, Aaron Courville, and Pascal Vincent, “Visualizing higher-layer features of a deep network,” University of Montreal, vol. 1341, 2009.
[11] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, “Intriguing properties of neural networks,” International Conference on Learning Representations (ICLR), 2014.
[12] J.T. Springenberg, A. Dosovitskiy, T. Brox, and M. Riedmiller, “Striving for simplicity: The all convolutional net,” International Conference on Learning Representations (ICLR), 2015.
[13] D.L. Wei, B.L. Zhou, A. Torrabla, and W. Freeman, “Understanding intra-class knowledge inside cnn,” arXiv preprint arXiv:1507.02379, 2015.
[14] K. Lenc and A. Vedaldi, “Understanding image representations by measuring their equivariance and equivalence,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 991–999.
[15] A. Karpathy, J. Johnson, and F.F. Li, “Visualizing and understanding recurrent networks,” International Conference on Learning Representations (ICLR), 2016.
[16] M. Liu, J.X. Shi, Z. Li, C.X. Li, J. Zhu, and S.X. Liu, “Towards better analysis of deep convolutional neural networks,” arXiv preprint arXiv:1604.07043, 2016.
[17] W.L. Shang, K. Sohn, D. Almeida, and H. Lee, “Understanding and improving convolutional neural networks via concatenated rectified linear units,” International Conference on Machine Learning (ICML), 2016.
[18] M.D. Zeiler and R. Fergus, “Visualizing and understanding convolutional networks,” in European Conference on Computer Vision (ECCV). Springer, 2014, pp. 818–833.
[19] Y. Sun, X.GWang, and X.O. Tang, “Deeply learned face representations are sparse, selective, and robust,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015, pp. 2892–2900.
[20] K. Simonyan, A. Vedaldi, and A. Zisserman, “Deep inside convolutional networks: Visualising image classification models and saliency maps,” in International Conference on Learning Representations (ICLR), 2014.
[21] Y. Jason, C. Jeff, N. Anh, F. Thomas, and L. Hod, “Understanding neural networks through deep visualization,” in Deep Learning Workshop, International Conference on Machine Learning (ICML), 2015.
[22] A. Mordvintsev, C. Olah, and M. Tyka, “Inceptionism: Going deeper into neural networks,” Google Research Blog. Retrieved June, vol. 20, 2015.
[23] A. Mahendran and A. Vedaldi, “Visualizing deep convolutional neural networks using natural pre-images,” International Journal of Computer Vision (IJCV), pp. 1–23, 2016.
[24] A. Nguyen, J. Yosinski, and J. Clune, “Multifaceted feature visualization: Uncovering the different types of features learned by each neuron in deep neural networks,” Visualization for Deep Learning workshop, International Conference in Machine Learning(ICML), 2016.
[25] A. Dosovitskiy and T. Brox, “Inverting convolutional networks with convolutional networks,” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[26] A. Mahendran and A. Vedaldi, “Understanding deep image representations by inverting them,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2015, pp. 5188–5196.
[27] L. Gatys, A.S. Ecker, and M. Bethge, “Texture synthesis using convolutional neural networks,” in Advances in Neural Information Processing Systems (NIPS), C. Cortes, N. D. Lawrence, D. D. Lee, M. Sugiyama, and R. Garnett, Eds., pp. 262–270.Curran Associates and Inc., 2015.
[28] D. Ulyanov, V. Lebedev, A. Vedaldi, V. Lempitsky, A. Gupta, A. Vedaldi, A. Zisserman, H. Bilen, B. Fernando, and E. Gavves, “Texture networks: Feed-forward synthesis of textures and stylized images,” in International Conference on MachineLearning, (ICML), 2016.
[29] J. Johnson, A. Alahi, and F.F. Li, “Perceptual losses for realtime style transfer and super-resolution,” European Conference on Computer Vision (ECCV), 2016.
[30] T.Q. Chen, M. Li, Y.T Li, M. Lin, N.Y. Wang, M.J. Wang, T.J. Xiao, B. Xu, C.Y. Zhang, and Z.Zhang, “Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems,” Advances in Neural Information Processing Systems (NIPS), 2015.
[31] R. Olga, D. Jia, S. Hao, K. Jonathan, S. Sanjeev, M. Sean, Z.H. Huang, K. Andrej, K. Aditya, B. Michael, C.B. Alexander, and F.F. Li, “Imagenet large scale visual recognition challenge,” International Journal of Computer Vision (IJCV), vol. 115, no.3, pp. 211–252, 2015.
(注:感谢您的阅读,希望本文对您有所帮助。如果觉得不错欢迎分享转载,但请先点击 这里 获取授权。本文由 版权印 提供保护,禁止任何形式的未授权违规转载,谢谢!)