微信公众号:命运探知之魔眼
如有问题或建议,请后台留言,我会尽力解决你的问题。

前言
我是人工智障,一名程序猿。做过嵌入式、爬虫,目前在自学计算机视觉 。注册 「命运探知之魔眼」(名字取自影视作品「命运石之门」)这个公号已有些日子,真正有心将它运营起来是看到朋友狗哥运营它的公号「一个优秀的废人」之后。注册这个号的初衷是分享我的 计算机视觉 学习笔记,希望更多的人加入我的行业。
PS:之前我装 tensorflow 的时候把 Python 版本切换到 3.5 了,所以之前装了 2.7 的同学可能我写的代码直接 copy 的话会用不了,目前带来的变化是 print 的时候 Python3 是需要加括号的,还有就是整除符号在 Python3 是 //,而在 Python2 中是靠类型判断的。
PPS: 本篇内容很多,建议上班时偷偷看。
HOG特征简介
HOG 全称为 Histogram of Oriented Gradients ,即方向梯度的直方图。HOG 是由 Navneet Dalal & Bill Triggs 在 CVPR 2005发表的论文中提出来的,目的是为了更好的解决行人检测的问题。先来把这几个字拆开介绍,首先,梯度的概念和计算梯度的方法已经在前一篇文章中介绍了,方向梯度就是说梯度的方向我们也要利用上,在前一篇中我们只是用到了梯度大小,直方图是个新的概念,所以下面先来介绍直方图。
直方图
直方图类似于小学(初中?)时学过的频率分布图,是用来表达图像的一种统计特征的,它的图形跟条形图一样。

横轴取了一定间隔的值的范围,纵轴表示某个区间的值有多少个(频数),举个简单的例子我们来动手算一次。
假如有这么一个3x3的矩阵:

要算它的直方图,我们先要选定一个取值的间隔,比如取10,那么0-9看成一类、10-19看成一类,如此类推,那么0-9有{6、5、9} 3个,10-19有{12、17}两个,用excel画出来看看。
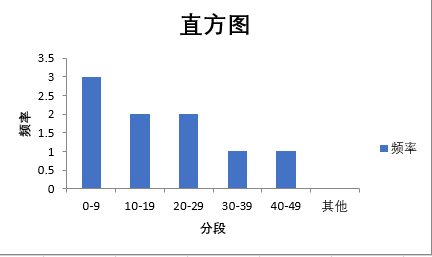
那么方向梯度的直方图,统计的就是某个方向区间内的梯度的大小(voting vector,不知道怎么翻译,投票向量?)。
HOG详解
先从 《Concise Computer Vision》上盗个图方便我介绍计算过程。(这是一本好书,需要的朋友可以私聊我)

左边的原图是个疑似是双马尾萝莉塔装的妹子的灰度图,也别问我为何这么熟练,最右边的就是我们上一期使用的 Sobel 算子对原图卷积以后得到的梯度图。
先看红色的格子:
红色的格子称为 cell(细胞、监牢),是计算直方图的基本单位,也是个固定大小的格子,典型值是 8x8 个像素。在这些所有的 8x8 的 cell 上单独计算直方图,我们知道直方图要自己指定 x 轴设置多少个区间,典型值是 9,x 轴表示的是梯度的方向,也就是把梯度方向割成 9 个区间,梯度方向的范围我们指定为 0 ~ 180°,也就是每个区间范围是 20°,像这样:

这样子我们就把梯度方向的粒度变粗了,有利于适应方向的变化。
我们来计算一个退化的情况,假设 cell 的大小是 3x3,bin(直方图区间)设为 9 个,
梯度幅值是这样的:

梯度方向是这样的:

各个区间先列出来,分别是:0-20、20-40、40-60、60-80、80-100、100-120、120-140、140-160、160-180,区间的右端点是不包含的。
我们计算的时候先看方向矩阵,首先左上角的值是 90度,那就落在了 80-100 的区间,幅值矩阵对应位置的值是 6,因此 80-100 这个区间的 y 轴值加 6。再看方向矩阵的第一行第二列,也是 90,幅值矩阵对应值是 12,于是 80-100 这个区间再加 12,现在总的值是 18 了,相信到这里你已经看懂了,如此类推继续算下来,就可以得到这样一个直方图:

计算直方图的函数代码实现是这样的:
'''
函数名称:calc_hist
功能:计算直方图
输入:
mag 幅值矩阵
angle 角度矩阵,范围在 0-180
bin_size 直方图区间大小
输出:
hist 直方图
'''
def calc_hist(mag, angle, bin_size=9):
hist = np.zeros((bin_size,), dtype=np.int32)
bin_step = 180 // bin_size
bins = (angle // bin_step).flatten()
flat_mag = mag.flatten()
for i,m in zip(bins, flat_mag):
hist[i] += m
return hist
有了这个函数就可以做计算 cell 的部分,对应这些代码:
# 将图像切成多个cell
cell_size = 8
bin_size = 9
img_h, img_w = gray.shape[:2]
cell_h, cell_w = (img_h // cell_size, img_w // cell_size)
cells = np.zeros((cell_h, cell_w, bin_size), dtype=np.int32)
for i in range(cell_h):
cell_row = cell_size * i
for j in range(cell_w):
cell_col = cell_size * j
cells[i,j] = calc_hist(mag[cell_row:cell_row+cell_size, cell_col:cell_col+cell_size],
angle[cell_row:cell_row+cell_size, cell_col:cell_col+cell_size], bin_size)
这样子就完成了 cell 部分的计算,接下来看黄格子。
黄色的格子称为 block,是由多个 cell 组合而成的,典型的组合方式是 2x2 个 cell 组成成一个 block,也就是跟图示的一样。我们知道每个 cell 上面都有一个 9 维的表示直方图大小的向量,那么一个 block 上就有 2x2x9 = 36维的向量,黄格子要做的操作就是把每一次选中的这 36 维向量做规范化(normalization),得到新的 36 维向量。
规范化的方法有多种可选:

我通常使用的是 L2-Norm, 也就是先对整个向量的各个元素都求平方然后求和、开根号 作为规范化因子,然后对原向量中每一个元素都除以这个规范化因子。
L2 规范化的函数是这样的:
# 归一化cells
def l2_norm(cells):
block = cells.flatten().astype(np.float32)
norm_factor = np.sqrt(np.sum(block**2) + 1e-6)
block /= norm_factor
return block
利用之前得到的 cells 和规范化函数就可以写 黄格子 实现的操作了:
# 多个cell融合成block
block_size = 2
block_h, block_w = (cell_h-block_size+1, cell_w-block_size+1)
blocks = np.zeros((block_h, block_w, block_size*block_size*bin_size), dtype=np.float32)
for i in range(block_h):
for j in range(block_w):
blocks[i,j] = l2_norm(cells[i:i+block_size, j:j+block_size])
把这么多个 block 的 36维向量拼起来就是 HOG 特征描述子(descriptor)了,在这里来说就是把 blocks 这个 3 维的矩阵摊平,也只要一行代码:
blocks = blocks.flatten()
我把整个 HOG 的计算过程封成了一个函数,是这样的:
# 计算HOG特征
def calc_hog(gray):
''' 计算梯度 '''
dx = cv2.Sobel(gray, cv2.CV_16S, 1, 0)
dy = cv2.Sobel(gray, cv2.CV_16S, 0, 1)
sigma = 1e-3
# 计算角度
angle = np.int32(np.arctan(dy / (dx + sigma)) * 180 / np.pi) + 90
dx = cv2.convertScaleAbs(dx)
dy = cv2.convertScaleAbs(dy)
# 计算梯度大小
mag = cv2.addWeighted(dx, 0.5, dy, 0.5, 0)
print('angle\n', angle[:8,:8])
print('mag\n', mag[:8,:8])
''' end of 计算梯度 '''
# 将图像切成多个cell
cell_size = 8
bin_size = 9
img_h, img_w = gray.shape[:2]
cell_h, cell_w = (img_h // cell_size, img_w // cell_size)
cells = np.zeros((cell_h, cell_w, bin_size), dtype=np.int32)
for i in range(cell_h):
cell_row = cell_size * i
for j in range(cell_w):
cell_col = cell_size * j
cells[i,j] = calc_hist(mag[cell_row:cell_row+cell_size, cell_col:cell_col+cell_size],
angle[cell_row:cell_row+cell_size, cell_col:cell_col+cell_size], bin_size)
# 多个cell融合成block
block_size = 2
block_h, block_w = (cell_h-block_size+1, cell_w-block_size+1)
blocks = np.zeros((block_h, block_w, block_size*block_size*bin_size), dtype=np.float32)
for i in range(block_h):
for j in range(block_w):
blocks[i,j] = l2_norm(cells[i:i+block_size, j:j+block_size])
return blocks.flatten()
假设输入的图片是 64 x 128 的,cell 就会有 8 x 16 = 128个,block 就有 (8-2+1) x (16 - 2 + 1) = 105 个,每个 block 有 36 维向量,总共就是 105 x 36 = 3780维向量,这个向量就是对应这张图片的 HOG 特征。用其他特征得到的东西也是大同小异,都是不同大小表示不同信息的特征。
特征相当于该物体的 ID,如果同类的物体的特征很相似,我们就说这个特征至少对于该类物体的区分度很好。拿现在很火的深度神经网络来说,用它做人脸识别的时候,也是输入图片,输出这么一个长长的向量,如果对于同一个人,这些产生的向量的距离很近,而对于不同人的距离则很远,就说这个神经网络精度很高,但本质的流程和这些人工设计的特征没有任何区别。
介绍完了 HOG特征,私以为徒有这堆向量也没什么卵用,所以想做个示范的应用,但是篇幅有限,知识点不能完全覆盖到,所以接下来讲的东西哪里不懂的另外搜索一下就好。
既然做行人识别,那就看看 HOG 特征对于行人的区分度怎么样。
特征区分度
做这个事情之前首先要介绍一下我使用的公开数据集 INRIA Person,这是一个公开的行人数据集,里面分为正样本和负样本,正样本几乎都是直立的老外行人,负样本是一些风景图片,可以给大家看一眼,这个数据集也能从网上直接下载。

我会把所有图片缩放到高度 128 和宽度 64,因此每张图片的 HOG 特征长度是 3780,如果我把所有这些 3780 维的向量都放在 3780 维空间上去看它们的分布,可能正样本会聚集在一堆,负样本聚在另一堆,这样是最好的,但是我们没办法可视化 3780 维的空间,所以我的做法是用 PCA(主成分分析)把它们压到二维,在二维平面上去看。
核心代码是这样的,需要 sklearn 和 scipy,可以通过 pip 安装:
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# PCA 降维
pca = PCA(n_components=2, copy=True)
data_size = 500
pos_features = pca.fit_transform(pos_features[:data_size])
neg_features = pca.fit_transform(neg_features[:data_size])
# 显示
plt.plot(pos_features[:,0], pos_features[:,1], 'ro')
plt.plot(neg_features[:,0], neg_features[:,1], 'bo')
plt.show()
但是得到的图形是这样的:

蓝色点是行人,红色点是背景。
emmmm, 好像打脸了,(逃
打脸的原因可能有两个,一个是降维降太多了,二维信息不足以表达原来的 3000 多维的结构;二是我们看这个图形的角度不对 ,正所谓横看成岭侧成峰。假设这是两坨饼,红色一坨蓝色一坨,现在看起来是红色的饼叠在了蓝色的饼上面,所以正确的看法应该是,我们把红色的饼拿起来,然后从侧面去看,就会变成这样:

这样子不就分成两坨了嘛~
虽然听起来像是在胡说八道,但是所谓什么 SVM 模型啊,深度学习、神经网络等等等等,干的就是这样一件事,改变我们看数据的角度,直到在我们看来是可以一刀切开的两坨,说得屌一点就是 线性可分。
SVM
所以下面就来训练一个 SVM 模型。
from sklearn import svm
# 合并特征
features = np.concatenate((pos_features[:data_size], neg_features[:data_size]))
labels = np.zeros((data_size*2,), dtype=np.int32)
labels[:data_size] = 1
# SVM分类器
lin_clf = svm.LinearSVC()
lin_clf.fit(features, labels)
features 是正样本和负样本的特征合并起来的一个大矩阵,labels 表示的是每个特征对应的是什么类别,这里我设置了 1 对应行人,0 对应背景。为什么需要 labels,因为训练模型要用,训练模型跟老师教学生学习很像,我们要先给学生一吨的题,并且告诉他们背后有答案,自己对,这些题就是 features,答案就是 labels,于是他们做完对完这些题以后我们就希望他们能够举一反三,看到新的题的时候不方。lin_clf 就是 SVM模型,使用 fit 方法训练,稍等几秒就训练完了。
下面就用我喜欢的知名舞见=咬人猫=的照片来测试一下吧,就是题图。

测试代码是:
miao = cv2.imread('miao2.jpg')
miao = cv2.resize(miao, (64,128))
miao = cv2.cvtColor(miao, cv2.COLOR_BGR2GRAY)
miao_feature = calc_hog(miao)
pred_result = lin_clf.predict(np.array([miao_feature]))
结果 pred_result 当然是 1 了,如果不是我就不会放上来了。
顺带一提,如果你们赞赏超过 2000 元,我就可以侵犯她 的俏像权了(笑)。
后语
我不是大神,不是什么牛人,于 计算机视觉 领域来说,我是菜鸡,但谁刚开始接触一个领域的时候不是菜鸡呢。 写这个号的目的是为了记录我自学 计算机视觉 的笔记。
如果本文对你哪怕有一丁点帮助请右下角点赞,否则忽略就好。平时工作也是在做计算机视觉,希望大家多多指教。
我一直认为学习不能有所见即所得的想法,一看就会,一做就错。千万不要偷懒,所谓大神都是一个一个坑踩过来的。
最后,如果对 计算机视觉 感兴趣请长按二维码关注一波,我会努力带给你们价值,赞赏就不必了,能力没到,受之有愧。
