本文原作者:梁源
BERT (Bidirectional Encoder Representations from Transformers) 官方代码库 包含了BERT的实现代码与使用BERT进行文本分类和问题回答两个demo。本文对官方代码库的结构进行整理和分析,并在此基础上介绍本地数据集使用 BERT 进行 finetune 的操作流程。BERT的原理介绍见参考文献[3]。
BERT是一种能够生成句子中词向量表示以及句子向量表示的深度学习模型,其生成的向量表示可以用于词级别的自然语言处理任务(如序列标注)和句子级别的任务(如文本分类)。
从头开始训练BERT模型所需要的计算量很大,但Google公开了在多种语言(包括中文)上预训练好的BERT模型参数,因此可以在此基础上,对自定义的任务进行finetune。相比于从头训练BERT模型的参数,对自定义任务进 行finetune所需的计算量要小得多。
本文的第一部分对BERT的官方代码结构进行介绍。第二部分以文本分类任务为例,介绍在自己的数据集上对BERT模型进行 finetune 的操作流程。
1. BERT实现代码
BERT官方项目的目录结构如下图所示:
下文中将分别介绍项目中各模块的结构和功能。
1.1 modeling.py
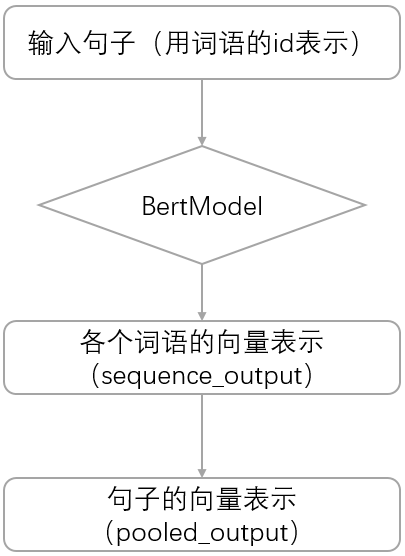
如下图所示,modeling.py定义了BERT模型的主体结构,即从input_ids(句子中词语id组成的tensor)到sequence_output(句子中每个词语的向量表示)以及pooled_output(句子的向量表示)的计算过程,是其它所有后续的任务的基础。如文本分类任务就是得到输入的input_ids后,用BertModel得到句子的向量表示,并将其作为分类层的输入,得到分类结果。
modeling.py的31-106行定义了一个BertConfig类,即BertModel的配置,在新建一个BertModel类时,必须配置其对应的BertConfig。BertConfig类包含了一个BertModel所需的超参数,除词表大小vocab_size外,均定义了其默认取值。BertConfig类中还定义了从python dict和json中生成BertConfig的方法以及将BertConfig转换为python dict 或者json字符串的方法。
107-263行定义了一个BertModel类。BertModel类初始化时,需要填写三个没有默认值的参数:
- config:即31-106行定义的BertConfig类的一个对象;
- is_training:如果训练则填true,否则填false,该参数会决定是否执行dropout。
- input_ids:一个
[batch_size, seq_length]的tensor,包含了一个batch的输入句子中的词语id。
另外还有input_mask,token_type_ids和use_one_hot_embeddings,scope四个可选参数,scope参数会影响计算图中tensor的名字前缀,如不填写,则前缀为”bert”。在下文中,其余参数会在使用时进行说明。
BertModel的计算都在__init__函数中完成。计算流程如下:
- 为了不影响原config对象,对config进行deepcopy,然后对is_training进行判断,如果为False,则将config中dropout的概率均设为0。
- 定义input_mask和token_type_ids的默认取值(前者为全1,后者为全0),shape均和input_ids相同。二者的用途会在下文中提及。
- 使用embedding_lookup函数,将input_ids转化为向量,形状为
[batch_size, seq_length, embedding_size],这里的embedding_table使用tf.get_variable,因此第一次调用时会生成,后续都是直接获取现有的。此处use_one_hot_embedding的取值只影响embedding_lookup函数的内部实现,不影响结果。 - 调用embedding_postprocessor对输入句子的向量进行处理。这个函数分为两部分,先按照token_type_id(即输入的句子中各个词语的type,如对两个句子的分类任务,用type_id区分第一个句子还是第二个句子),lookup出各个词语的type向量,然后加到各个词语的向量表示中。如果token_type_id不存在(即不使用额外的type信息),则跳过这一步。其次,这个函数计算position_embedding:即初始化一个shape为
[max_positition_embeddings, width]的position_embedding矩阵,再按照对应的position加到输入句子的向量表示中。如果不使用position_embedding,则跳过这一步。最后对输入句子的向量进行layer_norm和dropout,如果不是训练阶段,此处dropout概率为0.0,相当于跳过这一步。 - 根据输入的input_mask(即与句子真实长度匹配的mask,如batch_size为2,句子实际长度分别为2,3,则mask为
[[1, 1, 0], [1, 1, 1]]),计算shape为[batch_size, seq_length, seq_length]的mask,并将输入句子的向量表示和mask共同传给transformer_model函数,即encoder部分。 - transformer_model函数的行为是先将输入的句子向量表示reshape成
[batch_size * seq_length, width]的矩阵,然后循环调用transformer的前向过程,次数为隐藏层个数。每次前向过程都包含self_attention_layer、add_and_norm、feed_forward和add_and_norm四个步骤,具体信息可参考transformer的论文。 - 获取transformer_model最后一层的输出,此时shape为
[batch_size, seq_length, hidden_size]。如果要进行句子级别的任务,如句子分类,需要将其转化为[batch_size, hidden_size]的tensor,这一步通过取第一个token的向量表示完成。这一层在代码中称为pooling层。 - BertModel类提供了接口来获取不同层的输出,包括:
- embedding层的输出,shape为
[batch_size, seq_length, embedding_size] - pooling层的输出,shape为
[batch_size, hidden_size] - sequence层的输出,shape为
[batch_size, seq_length, hidden_size] - encoder各层的输出
- embedding_table
- embedding层的输出,shape为
modeling.py的其余部分定义了上面的步骤用到的函数,以及激活函数等。
1.2 run_classifier.py
这个模块可以用于配置和启动基于BERT的文本分类任务,包括输入样本为句子对的(如MRPC)和输入样本为单个句子的(如CoLA)。
模块中的内容包括:
- InputExample类。一个输入样本包含id,text_a,text_b和label四个属性,text_a和text_b分别表示第一个句子和第二个句子,因此text_b是可选的。
- PaddingInputExample类。定义这个类是因为TPU只支持固定大小的batch,在eval和predict的时候需要对batch做padding。如不使用TPU,则无需使用这个类。
- InputFeatures类,定义了输入到estimator的model_fn中的feature,包括input_ids,input_mask,segment_ids(即0或1,表明词语属于第一个句子还是第二个句子,在BertModel中被看作token_type_id),label_id以及is_real_example。
- DataProcessor类以及四个公开数据集对应的子类。一个数据集对应一个DataProcessor子类,需要继承四个函数:分别从文件目录中获得train,eval和predict样本的三个函数以及一个获取label集合的函数。如果需要在自己的数据集上进行finetune,则需要实现一个DataProcessor的子类,按照自己数据集的格式从目录中获取样本。注意!在这一步骤中,对没有label的predict样本,要指定一个label的默认值供统一的model_fn使用。
- convert_single_example函数。可以对一个InputExample转换为InputFeatures,里面调用了tokenizer进行一些句子清洗和预处理工作,同时截断了长度超过最大值的句子。
- file_based_convert_example_to_features函数:将一批InputExample转换为InputFeatures,并写入到tfrecord文件中,相当于实现了从原始数据集文件到tfrecord文件的转换。
- file_based_input_fn_builder函数:这个函数用于根据tfrecord文件,构建estimator的input_fn,即先建立一个TFRecordDataset,然后进行shuffle,repeat,decode和batch操作。
- create_model函数:用于构建从input_ids到prediction和loss的计算过程,包括建立BertModel,获取BertModel的pooled_output,即句子向量表示,然后构建隐藏层和bias,并计算logits和softmax,最终用cross_entropy计算出loss。
- model_fn_builder:根据create_model函数,构建estimator的model_fn。由于model_fn需要labels输入,为简化代码减少判断,当要进行predict时也要求传入label,因此DataProcessor中为每个predict样本生成了一个默认label(其取值并无意义)。这里构建的是TPUEstimator,但没有TPU时,它也可以像普通estimator一样工作。
- input_fn_builder和convert_examples_to_features目前并没有被使用,应为开放供开发者使用的功能。
- main函数:
- 首先定义任务名称和processor的对应关系,因此如果定义了自己的processor,需要将其加入到processors字典中。
- 其次从FLAGS中,即启动命令中读取相关参数,构建model_fn和estimator,并根据参数中的do_train,do_eval和do_predict的取值决定要进行estimator的哪些操作。
1.3 run_pretraining.py
这个模块用于BERT模型的预训练,即使用masked language model和next sentence的方法,对BERT模型本身的参数进行训练。如果使用现有的预训练BERT模型在文本分类/问题回答等任务上进行fine_tune,则无需使用run_pretraining.py。
1.4 create_pretraining_data.py
此处定义了如何将普通文本转换成可用于预训练BERT模型的tfrecord文件的方法。如果使用现有的预训练BERT模型在文本分类/问题回答等任务上进行fine_tune,则无需使用create_pretraining_data.py。
1.5 tokenization.py
此处定义了对输入的句子进行预处理的操作,预处理的内容包括:
- 转换为Unicode
- 切分成数组
- 去除控制字符
- 统一空格格式
- 切分中文字符(即给连续的中文字符之间加上空格)
- 将英文单词切分成小片段(如[“unaffable”]切分为[“un”, “##aff”, “##able”])
- 大小写和特殊形式字母转换
- 分离标点符号(如 [“hello?”]转换为 [“hello”, “?”])
1.6 run_squad.py
这个模块可以配置和启动基于BERT在squad数据集上的问题回答任务。
1.7 extract_features.py
这个模块可以使用预训练的BERT模型,生成输入句子的向量表示和输入句子中各个词语的向量表示(类似ELMo)。这个模块不包含训练的过程,只是执行BERT的前向过程,使用固定的参数对输入句子进行转换。
1.8 optimization.py
这个模块配置了用于BERT的optimizer,即加入weight decay功能和learning_rate warmup功能的AdamOptimizer。
2. 在自己的数据集上finetune
BERT官方项目搭建了文本分类模型的model_fn,因此只需定义自己的DataProcessor,即可在自己的文本分类数据集上进行训练。
训练自己的文本分类数据集所需步骤如下:
- 下载预训练的BERT模型参数文件,如(https://storage.googleapis.com/bert_models/2018_10_18/uncased_L-12_H-768_A-12.zip ),解压后的目录应包含
bert_config.json,bert_model.ckpt.data-00000-of-00001,bert_model.ckpt.index,bert_model_ckpt.meta和vocab.txt五个文件。 - 将自己的数据集统一放到一个目录下。为简便起见,事先将其划分成
train.txt,eval.txt和predict.txt三个文件,每个文件中每行为一个样本,格式如下(可以使用任何自定义格式,只需要编写符合要求的DataProcessor子类即可): simplistic , silly and tedious . __label__0 即句子和标签之间用__label__划分,句子中的词语之间用空格划分。 - 修改
run_classifier.py,或者复制一个副本,命名为run_custom_classifier.py或类似文件名后进行修改。 - 新建一个DataProcessor的子类,并继承三个get_examples方法和一个get_labels方法。三个get_examples方法需要从数据集目录中获得各自对应的InputExample列表。以get_train_examples方法为例,该方法需要传入唯一的一个参数data_dir,即数据集所在目录,然后根据该目录读取训练数据,将所有用于训练的句子转换为InputExample,并返回所有InputExample组成的列表。get_dev_examples和get_test_examples方法同理。get_labels方法仅需返回一个所有label的集合组成的列表即可。本例中get_train_examples方法和get_labels方法的实现如下(此处省略get_dev_examples和get_test_examples): class RtPolarityProcessor(DataProcessor): """Processor of the rt-polarity data set""" @staticmethod def read_raw_text(input_file): with tf.gfile.Open(input_file, "r") as f: lines = f.readlines() return lines def get_train_examples(self, data_dir): """See base class""" lines = self.read_raw_text(os.path.join(data_dir, "train.txt")) examples = [] for i, line in enumerate(lines): guid = "train-%d" % (i + 1) line = line.strip().split("__label__") text_a = tokenization.convert_to_unicode(line[0]) label = line[1] examples.append( InputExample(guid=guid, text_a=text_a, label=label) ) return examples def get_labels(self): return ["0", "1"]
- 在main函数中,向main函数开头的processors字典增加一项,key为自己的数据集的名称,value为上一步中定义的DataProcessor的类名: processors = { "cola": ColaProcessor, "mnli": MnliProcessor, "mrpc": MrpcProcessor, "xnli": XnliProcessor, "rt_polarity": RtPolarityProcessor, }
- 执行python run_custom_classifier.py,启动命令中包含必填参数data_dir,task_name,vocab_file,bert_config_file,output_dir。参数do_train,do_eval和do_predict分别控制了是否进行训练,评估和预测,可以按需将其设置为True或者False,但至少要有一项设为True。
- 为了从预训练的checkpoint开始finetune,启动命令中还需要配置init_checkpoint参数。假设BERT模型参数文件解压后的路径为
/uncased_L-12_H-768_A-12,则将init_checkpoint参数配置为/uncased_L-12_H-768_A-12/bert_model.ckpt。其它可选参数,如learning_rate等,可参考文件中FLAGS的定义自行配置或使用默认值。 - 在没有TPU的情况下,即使使用了GPU,这一步有可能会在日志中看到
Running train on CPU字样。对此,官方项目的readme中做出了解释:”Note: You might see a messageRunning train on CPU. This really just means that it’s running on something other than a Cloud TPU, which includes a GPU. “,因此无需在意。
如果需要训练文本分类之外的模型,如命名实体识别,BERT的官方项目中没有完整的demo,因此需要设计和实现自己的model_fn和input_fn。以命名实体识别为例,model_fn的基本思路是,根据输入句子的input_ids生成一个BertModel,获得BertModel的sequence_output(shape为[batch_size,max_length,hidden_size]),再结合全连接层和crf等函数进行序列标注。
这是BERT介绍的第一篇文章。后续我们会将BERT整合进智能钛机器学习平台,并基于智能钛机器学习平台,讲解BERT用于文本分类、序列化标注、问答等任务的细节,并对比其他方法,给出benchmark。