https://blog.csdn.net/u013010889/article/details/78722140
https://zhuanlan.zhihu.com/p/30970675
CNN的池化层旨在建立位置不变性。但是,池化引入了一个重要的问题,因为它迫使我们失去所有的位置数据(不论相对位置在左上右下还是哪里,只要在池化范围内都可以,这样就淡化了相对位置)。这是很不利的。
max pooling是CNN用来保持Invariance(不变性)的,比如一个物体轻微移动或旋转后,依然不改变它的类别。max pooling这样做丢失了空间等信息,虽然对分类影响不大,但是对检测分割等高级任务影响很大。(其实对重叠的多物体分类还是有影响的,因为它max pooling只保留主体最大响应了,把其他扔了,而后面介绍的capsule则不会把其他信息丢掉,重叠的部分是可以复用的)

详细的姿态信息(如精确的目标位置、旋转、厚度、倾斜、大小等)将在整个网络中被保存,而不是丢失了之后再恢复。
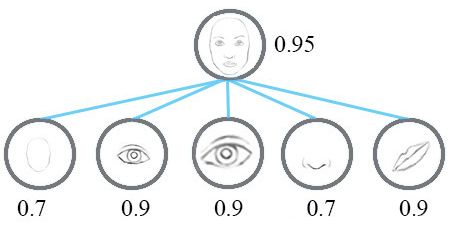
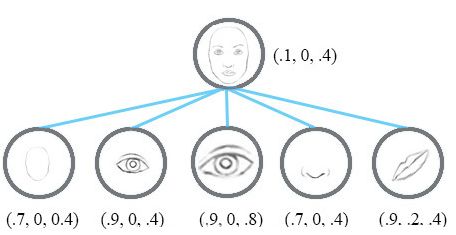
CapsNet也是由多层构成。处于最底层的胶囊被称为向量胶囊:它们每个都只用图片的一小部分区域作为输入(称为感知域),然后试图去探测某个特殊的模式(例如,一个矩形)是否存在,以及姿态如何。在更高层的胶囊(称为路由胶囊)则是探测更大和更复杂的物体,比如船等。

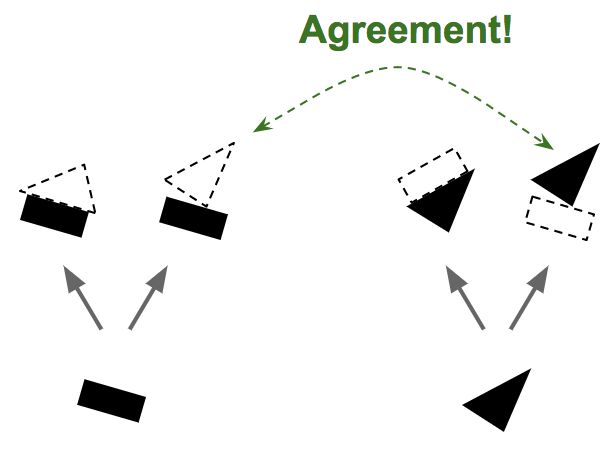
因为我们现在已经很有信心地知道矩形和三角形是船的一部分,所以把矩形和三角形的输出更多指向船的胶囊而更少指向房子的胶囊就顺理成章了。用这个方法,船的胶囊将会获得更多的有用输入信号,而房子的胶囊则接收更少的噪音。对每一个连接,按一致性路由算法会维护一个路由权重(见图6):它对于一致的会增加权重,而对于不一致的则降低权重。
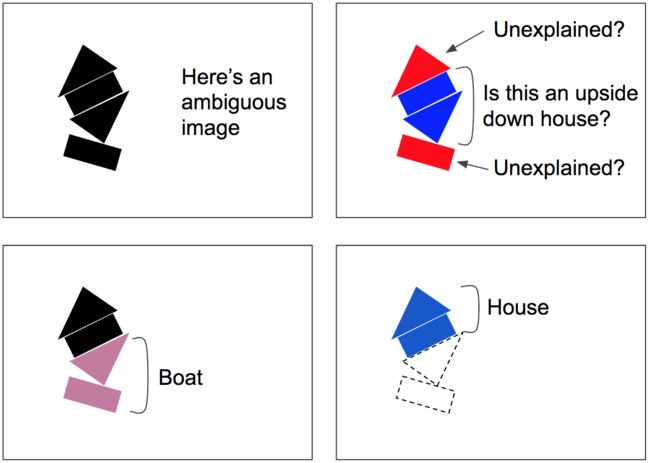
这个按一致性路由算法会涉及到一些循环:一致性检测和路由权重更新。这一算法对于拥挤的场景特别有用。例如图7里的场景是比较模糊的,因为你能看到中间有一个上下颠倒的房子,但这样会让上面的三角形和下面的矩形无法得到解释。按一致性路由算法更有可能收敛到一个更好的解释:下面是一条船,而上面是一个房子。这样模糊性就“可以被解释了”:下面的矩形最好是被看成一条船的一部分,同时这样也解释了下面的三角形。一旦下面的两个部分被解释好了,剩下的部分就很容易地被解释成一个房子。
简单网络结构介绍:
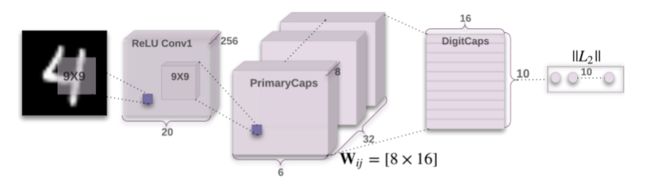
该架构非常浅显易懂,只有两个卷积层和一个全连接层。Conv1 有 256个9×9 卷积核,它的步长为 1,由 ReLU 激活。该层的作用是将像素强度转换为局部特征检测器的活动,然后将其作为 PrimaryCapsules 的输入。PrimaryCapsules 是一个 32 通道的卷积 capsule 层;每个主 capsule 包含 8 个卷积单元,带有一个 9×9 内核,步幅为 2
CNN与Capture中第一层生成第二层的区别:

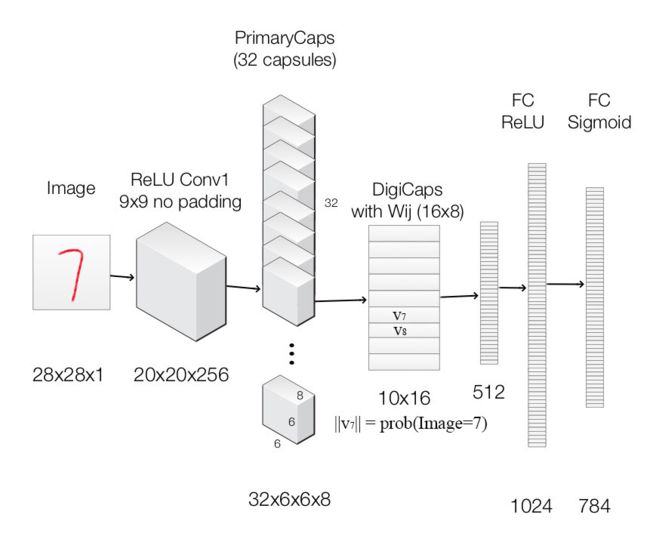
第一个卷积层使用 256 个 9×9 卷积核,深度为1,步幅为1,且使用了 ReLU 激活函数。输出的张量20×20×256。此外,CapsNet 的卷积核感受野使用的是 9×9。这两层间的权值数量应该为 9×9×1×256+256=20992,后面加256是偏置值。
第二个卷积层开始作为 Capsule 层的输入而构建相应的张量结构。使用32×8个9×9卷积核(深度为256),步幅为2。输出张量为6×6×8×32,即输出了6×6×32个维度为8的capsule向量。两层间的权值数量为9×9×256×8×32+8×32=5308672。
PrimaryCaps层有6×6×32个capsules。其中每个map含有6×6个capsule。不同的map代表不同的类型,而同一个map的不同capsule代表不同的位置。
第三层DigitCaps在第二层输出的向量基础上进行传播与Routing更新。第二层共输出 6×6×32=1152 个capsule,即i层共有1152个Capsule,第三层j层有10个Capsules(每个是16维的向量)。
流程
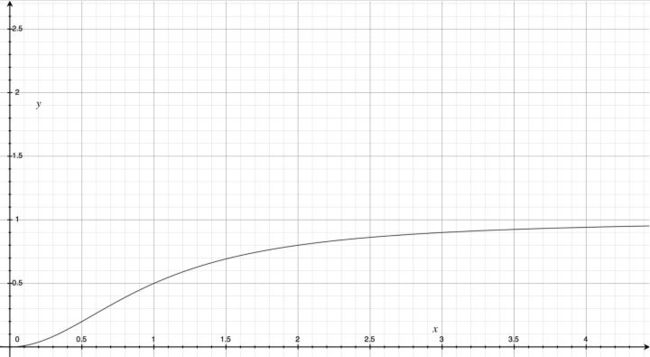
Capsule 是一个高维向量,向量的长度代表目标存在的概率估计,而且它对姿态参数(例如精确的位置,旋转,等等)定向编码(例如8D空间),方向表示属性。如果对象有轻微的变化(例如移位、旋转、改变大小等),那么胶囊将输出相同长度但方向略有不同的向量,因此,胶囊是等变化的。故Hinton采用Squashing的非线性函数作为capsule的激活函数。
其中为 Capsule j 的输出向量,为上一层所有 Capsule 输出到当前层 Capsule j 的向量加权和。 即为 Capsule j 的输入向量。
该非线性函数前一部分是输入向量的缩放尺度,后一部分是输入向量的单位向量
Capsule_j的输入向量 s_j的获取计算,是两层间的传播与联系方式。S_j计算过程分为两步,线性组合 和 Routing:
下图左式是Routing,右式是线性组合。
- 一致性Routing流程:

- 计算该层的第j个胶囊,先利用转换矩阵把上一层的胶囊转换一下维度,然后上一层共n个胶囊,得到n个,然后这n个u分别乘以各自的权重得到
- 注意没有偏置项
- 。在cnn中会使用ReLU激活函数,这里不是的,采用squash函数(挤压函数)把这个sj向量放缩到0到单位长度。sj模长很小时,它的平方和1比可以忽略,很大时,1和它的平方比可以忽略。
- 注: 这个转换矩阵编码low level的特征和high level的特征之间的空间或者其他联系。
损失函数和最优化:
耦合系数是通过一致性 Routing 进行更新的,但是整个网络其它的卷积参数和 Capsule 内的都需要根据损失函数进行反向更新。
作者采用了 SVM 中常用的 Margin loss,该损失函数的表达式为:
为(真实的解),使用one-hot编码,比如是第2类[0,1,0],vc的模长为预测值[0.3, 0.6, 0,1]的L2距离。m+ 为上margin,惩罚假阴性(没有预测到存在的分类的情况, m- 为下margin,惩罚假阳性(预测到不存在的分类的情况)注意Tc是一个one-hot的向量,第一个式子意味着gt中有的类,你要预测出来,没有预测出来要惩罚,第一个式子意味着gt中没有的类,你不能预测出来,预测出来了要惩罚。
重构与表征
利用预测出来的Capsules,重新构建出该类别的图像
文章中使用额外的重构损失(reconstruction loss)来促进 DigitCaps 层对输入数字图片进行编码:


原图片可能数字重叠覆盖,导致预测出来的10个Capsules中部分Capsules的模都很大,所以重构单个数字图片时候,需要将其他Capsule进行Mask遮住,让有代表的Capsules去重构图片。损失函数通过计算在最后的 FC Sigmoid 层采用的输出像素点与原始图像像素点间的欧几里德距离作为损失函数。
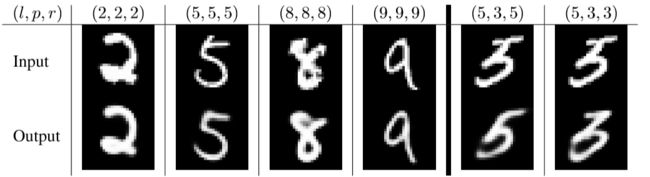
L:(l1,l2)表示图像中两个数字的标号,R:(r1,r2)表示用于重建的两个数字。最右边的两列显示了两个根据标签和预测(P)重建的分类错误的示例。带有(*)标记的两列显示了对既不是标签也不是预测的数字的重构。在(8,1)的情况下,8的循环没有触发0,因为它已经被8占据了。因此,它不会分配一个像素到两个数字,如果其中一个没有任何其他支持。

相比Softmax,Capsules不受多类别重叠的干扰,非常适合做单样本预测多类别的工作。
总结和对比:
