思考
现在有如下需求,设计一种数据结构,用来存放整数,要求提供3个接口
- 添加元素
- 获取最大值
- 删除最大值
通过我们前面介绍的几种数据结构,我们可以用以下的一些数据结构来实现

其中普通的动态数组\双向链表保存数据如所示
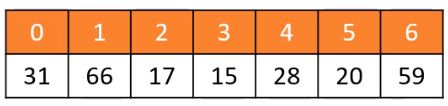
有序动态数组\双线链表保存数据如下所示
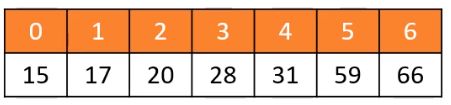
我们发现,以上的数据结构,都有不同的优缺点,那么有没有更优的数据结构来完成这样的需求呢?
那就是堆,其中堆在处理以上任务的时候,的时间复杂度分别为
获取最大值:O(1)
删除最大值:O(logn)
添加元素:O(logn)
-
Top K问题
什么叫Top K问题?
即:从海量数据中找出前K个数据
比如:要求从100万个整数中找出最大的100个整数
Top K问题的解法之一:可以用数据结构“堆”来解决
-
堆(Heap)
堆(Heap)也是一种树状的数据结构(不要与内存模型中的“堆空间”混淆),常见的堆实现有
- 二叉堆(Binary Heap,完全二叉堆)
- 多叉堆(D-heap,D-ary Heap)
- 索引堆(Index Heap)
- 二项堆(Binomial Heap)
- 斐波那契堆(Fibonacci Heap)
- 斜堆(Skew Heap)
堆有一个重要的性质:任意节点的值总数≥(≤)子节点的值,其中
如果任意节点的值总是≥子节点的值,称为:最大堆,大根堆,大顶堆。如
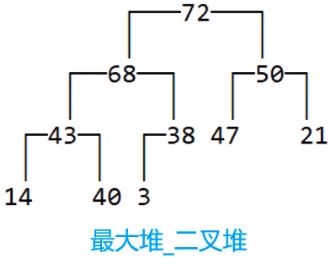
如果任意节点的值总是≤子节点的值,称为:最小堆,小根堆,小顶堆。如
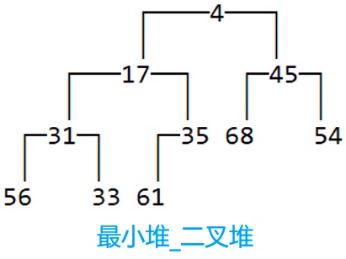
通过以上结论,我们可以发现,堆中的元素必须具备可比较性(跟二叉搜索树一样)
-
堆的基本接口设计
int size();//元素的数量
boolean isEmpty();//是否为空
void clear();//清空
void add(E element);//添加元素
E get();//获取堆顶元素
E remove();//删除堆顶元素
E replace(E element);//删除堆顶元素的同时插入一个新元素
-
二叉堆
二叉堆的逻辑结构就是一颗完全二叉树,所以也叫做完全二叉堆。如下图
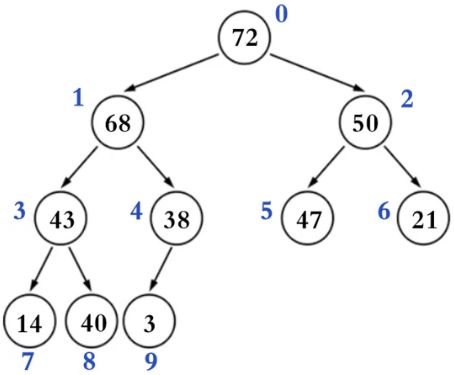
鉴于完全二叉树的一些性质,二叉堆的底层(物理结构)一般用数组实现即可

关于数组索引(i)的规律(n是元素数量)
- 如果i = 0,它的根节点
- 如果i > 0,它的父节点的索引为floor(( i - 1 ) / 2)
- 如果2i +1 ≤ n - 1,它的左子节点的索引为2i +1
- 如果2i + 1 > n - 1,它没有左子节点
- 如果2i + 2 ≤ n - 1,它的右子节点的索引为2i + 2
- 如果2i + 2 > n- 1,它没有右子节点
-
最大堆的添加
假设现在有如下的一个最大堆,往堆中假如一个新的元素80,一般情况是这样添加的
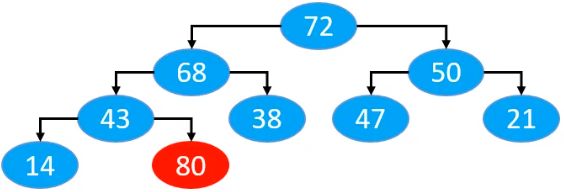
对应在数组中的位置,默认是放最后面

此时,我们发现,现在是不满足最大堆的性质的,此时我们将当前节点与父节点比较大小,发现如果比父节点大,则和父节点交换位置。
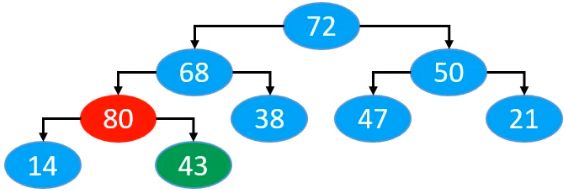
对应在数组中的交换位置是这样的

然后循环与父节点进行比较,最终比较到比父节点小为止,因此现在与68进行比较,调换顺序后的结果为

对应在数组中的结果为

接下来80再与72进行比较,调换顺序后的结果为
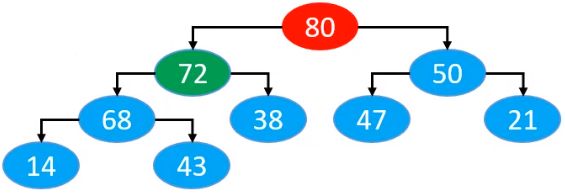
对应数组中的结果为

此时,发现80已经不能往上,就完成了。
最大堆添加总结
循环执行以下操作(上图中的节点80简称为node)
- 如果node > 父节点
- 与父节点交换位置
- 如果node≤父节点,或者node没有父节点
- 退出循环
这整个过程,叫做上滤(Sift Up),其时间复杂度为O(logn)
添加中上滤的实现
/*
* 让index位置的元素上滤
* */
private void siftUp(int index) {
E element = elements[index];
while (index > 0) {
int parentIndex = (index - 1) >> 1;
E parent = elements[parentIndex];
if (compare(element,parent) <= 0) {
return;
}
//交换p,element
E tmp = elements[index];
elements[index] = elements[parentIndex];
elements[parentIndex] = tmp;
index = parentIndex;//更新当前节点的索引
}
}
上滤交换位置的优化
一般交换位置需要3行代码,可以进一步优化,可以将新添加的节点备份,确定最终位置才摆放上去。如下图,我们新添加80时是这样的。
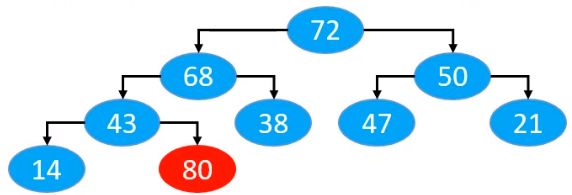
此时80与父节点进行比较,比较后,将父节点移下来,但是新添加的节点,不去覆盖父节点的位置,我们只需要记录80的位置即可,即

然后80再与父节点68进行比较,比较后,68往下移动,并且记录节点80的新位置,即
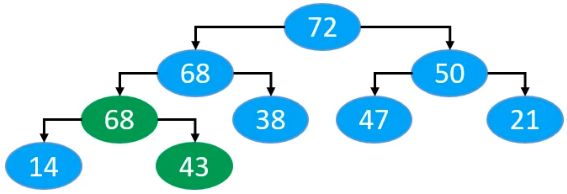
直到比较到最后,到达根节点或者比父节点小时,记录当前新节点的位置,停止遍历,即

循环停止后,将新元素80保存到记录的位置即可
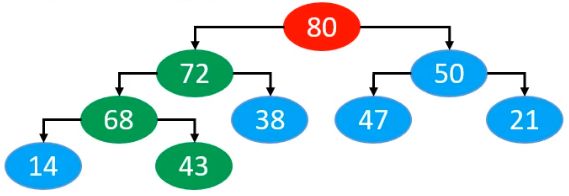
最终实现代码:
private void siftUp(int index) {
E element = elements[index];
while (index > 0) {
int parentIndex = (index - 1) >> 1;
E parent = elements[parentIndex];
if (compare(element,parent) <= 0) {
break;
}
//将父元素存储到index位置
elements[index] = parent;
index = parentIndex;//更新当前节点的索引
}
elements[index] = element;
}
仅从交换位置的代码角度看
可以由大概的3 * O(logn)优化到 1 * O(logn) +1
-
最大堆的删除
假设现在有如下的一棵二叉堆,我们要删除其堆顶元素80
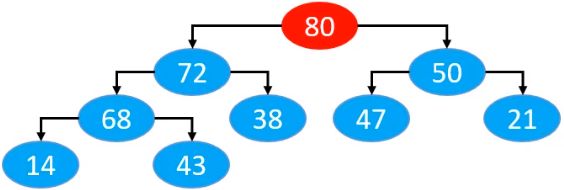
以上二叉堆对应在数组中的示意图如下

如果我们删除堆顶元素,直接将数组中的首元素删除的话,删除后需要将后面的所有元素往前面移动一个位置,此时,在移动的时间复杂度为O(n),因此这种方式并不是我们想要的。那么,我们应该怎么处理呢?
我们一般采用的方式是将堆中的最后一个元素,与堆顶元素进行位置交换,交换后,再将最后一个元素删掉,删除完成后,对应的二叉堆为
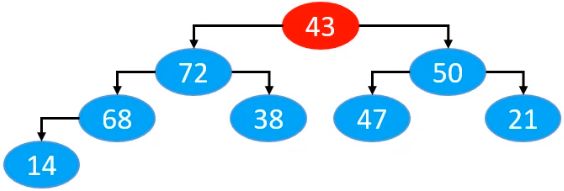
二叉堆对应的数组为

但是,这样做以后,就不满足最大堆的性质了。要如何才能满足最大堆的性质呢?我们前面讲到,当前节点的值,要大于等于子节点的值,既然这样,那么肯定需要进行比较。如果当前节点的值,已经大于等于子节点的值了,就不需要做任何操作。否则发现当前节点的值,小于子节点的值,就需要做交换操作。
由于我们现在是最大堆,因此在比较时,选择与值最大的子节点进行交换。比较一轮以后的结果为
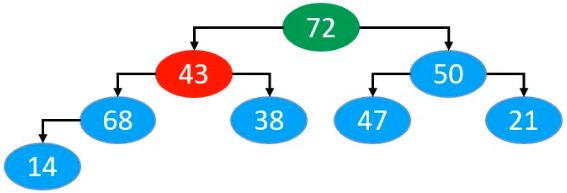
对应的数组为

交换位置以后,再进行下一轮的比较。如此循环,直到子节点均小于当前节点,此时,已经符合最大堆的性质,停止循环。最终交换完后的结果为
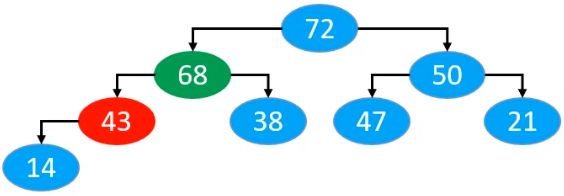
最终对应的数组为

到此位置,删除操作就完成了。
最大堆删除总结
- 用最后一个节点覆盖根节点
- 删除最后一个节点
- 循环执行以下操作(上图中节点43简称为node)
- 如果node <子节点
- 与最大的子节点交换位置
- 如果node ≥ 子节点,或者node没有子节点
- 退出循环
- 如果node <子节点
这个过程,叫做下滤(Sift Down),时间复杂度为:O(logn)
同样的,交换位置的操作,可以像添加那样进行优化。
删除中下滤的实现
/*
* 让index位置的元素下滤
* */
private void siftDown(int index) {
E e = elements[index];
//必须保证index的位置是非叶子节点,即 index < 第一个非叶子节点的索引
//第一个叶子节点的索引,就是非叶子节点是数量
int half = size >> 1;//half为非叶子节点的数量
while (index < half){
//index的节点有2中情况
//1.只有左子节点
//2.同时有左有右
int childIndex = (index << 1) +1;//默认为左子节点的索引
E child = elements[childIndex];
//右子节点
int rightIndex = childIndex + 1;
//选出左右子节点最大的那个
if (rightIndex < size && compare(elements[rightIndex],child) > 0) {
child = elements[childIndex = rightIndex];
}
if (compare(e,child) > 0) break;
//将子节点存放到index的位置
elements[index] = child;
//重新设置index
index = childIndex;
}
elements[index] = e;
}
-
替换
说到替换,我们可能想到的操作是这样的。
- 先删除堆顶元素
- 将新元素添加到对中
是的,这种方法确实可以实现,但是有点浪费,我们知道,对在做添加删除操作时,它的复杂度为O(logn),因此整个操作所消耗的时间复杂度为2O(logn)。有没有更好的方法呢?
我们可以直接让将要添加到对堆中的元素替换堆顶的元素,这样我们就把堆顶元素删除掉了,然后再让现在的堆顶元素执行下滤的操作。下滤完成后,就恢复了最大堆的性质,这样操作,只需要O(logn)的时间复杂度
因此替换可以通过以下的代码进行实现
public E replace(E element) {
elementNotNullCheck(element);
E root = null;
if (size == 0) {
elements[0] = element;
size++;
} else {
root = elements[0];
elements[0] = element;
siftDown(0);
}
return root;
}
-
批量建堆(Heapify)
批量建堆:即给你一堆的数据,里面的数据顺序是乱七八糟的,要求 把这些数据快速建立成一个堆,这种操作叫做批量建堆
假设现在有这样一堆数据 {88, 44, 53, 41, 16, 6, 70, 18, 85, 98, 81, 23, 36, 43, 37},要求将这些数据变为一个堆。按照我们普通的做法可能是使用一个循环,遍历这些数据,然后一个一个的将其添加到堆中,最终变成一个堆。虽然这种方法也做到了,但是相对来讲,效率偏低。因此一般批量建堆有以下两种做法:
- 自上而下的上滤
- 自下而上的下滤
自上而下的上滤
假设我们现在数组中的数据是如下图这样的:

现在这个堆,我们发现,其明显不是我们想要的最大堆。我们希望将上面数组中的数据,变为最大堆
在我们的一般处理当中,由于根节点不用上滤,因此我们在选择上滤元素时,直接从索引为1的位置开始上滤。最终索引为1的节点上滤完成后的结果为
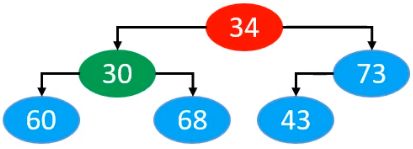
并且, 从30与34之间的关系来看, 此时两者已经满足最大堆的性质(仅看节点30与34)
34上滤完成后,由73开始上滤,最终73上滤完成后的结果为
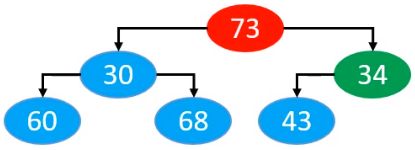
同样的,我们可以发现,从节点73,30,34的角度看,三者同样满足最大堆的性质
如此循环,此时60进行上滤,最终效果为
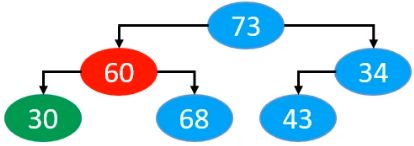
60上滤完成后68进行上滤
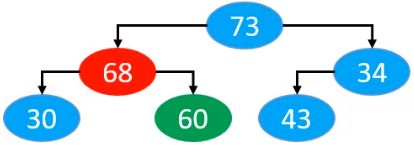
最后43进行上滤
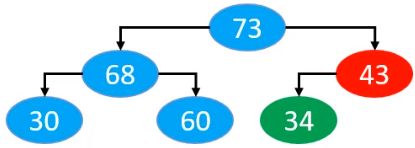
整个过程结束。
我们发现,自上而下的上滤,其实是一步一步的将堆变为一个最大堆,并且,在上滤的过程当中,凡是参与过上滤的元素,每一步完成后,都是一个局部的最大堆。
最终的实现代码也很简单
for (int i = 0; i < size; i++) {
siftUp(i);
}
自下而上的下滤
与自上而下的上滤相反,此时,我们就是从之后一个元素开始。而且由于是下滤,因此我们可以排除叶子节点后,进行下滤,即如果我们从下往上寻找的过程当中,发现当前节点为叶子节点,我们就不做下滤操作。
所以下图中的节点当中,红色的节点才需要进行下滤
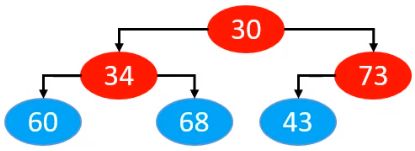
所以,从优化性能的角度出发,我们只需要从 (size >> 1) - 1的位置开始下滤即可
最终以上每个节点,下滤后的结果分别为

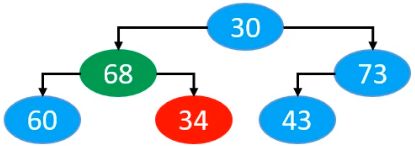
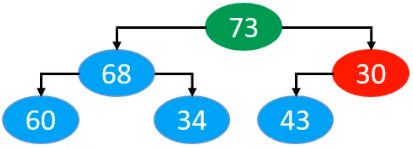
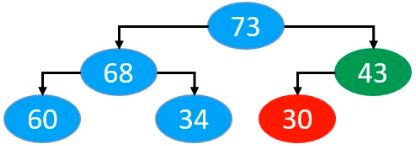
最终,我们发现,同样是满足最大堆性质的。
为什么这种自下而上的下滤,也会变成一个最大堆呢?前面自上而下的上滤我们发现,凡是参与过上滤的元素,每一步完成后,都是一个局部的最大堆。为什么这种自下而上的下滤也可以呢?其实我们认真观察的话,也可以发现,自下而上的下滤,也是每完成一部分下滤后,也会形成一个局部的最大堆,其本质就是先将当前节点的左右变成一个局部的最大堆,然后再将这个局部的最大堆与其他的最大堆组合,形成一个更大的最大堆。直到全部节点下滤完成,就形成了一个完整的最大堆
同样,最终的实现代码也很简单
for (int i = ((size >> 1) - 1); i >= 0; i--) {
siftDown(i);
}
那么我们来对比一下,以上的两种方式,那种方式效率更高了。我们从表面来看,发现自下而上的下滤循环的次数更少,下滤我们只需要对一半的元素进行下滤,而上滤则需要对size - 1个节点进行上滤,从数量来看, 自下而上的下滤效率会更高。
批量建堆效率对比
最终我们可以通过下图来得出结论
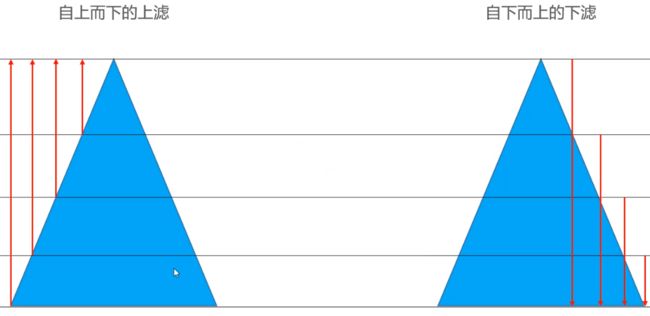
我们把三角形想象成为一个堆,顶部的元素最少,越往底部元素越来越多
每一个箭头,表示在当前层中,一个元素上滤或者下滤过程中,需要交换的次数,箭头越长,需要交换的次数
每一层的元素数量 * 当前层元素上滤/下滤需要交换的次数 = 当前层所有元素上滤/下滤完成交换的次数,最终我们发现,自下而上的下滤得到的乘积和最小,说明自下而上的上滤效率高于自上而下的上滤
所以,自上而下的上滤我们可以理解为有非常多的节点,在做工作量很大的事情,非常少的节点在做工作量非常小的是事情;而自下而上的下滤则恰恰相反。
最终他们两者的时间复杂度分别为:
自上而下的上滤:O(nlogn);为所有节点的深度之和
自下而上的下滤:O(n);为所以节点的高度之和
- 所有节点的深度之和
- 仅仅是叶子节点,就有近n / 2个,而且每一个叶子节点的深度都是O(logn)级别的
- 因此,在叶子节点这一块,就达到了O(nlogn)级别
- O(logn)的时间复杂度,注意利用排序算法对所有节点进行全排序
- 所有节点的高度之和
- 假设是满树,节点总数为n,树高为h,那么 n = 2^h - 1
- 所有节点的树高之和H(n) = 2^0 * (h - 0) + 2^1 * (h - 1) + 2^ * (h - 2) +... + 2^(h - 1) * (h - (h - 1))
- H(n) = h * (2^0 + 2^01+ 2^2 + ... + 2^(h - 1)) - [1 * 2^1 + 2 * 2^2 + 3 * 2^3 + ... + (h - 1) * 2^(h - 1)]
- H(n) = h * (2^h - 1) - [(h - 2) * 2^h +2]
- H(n) = h * 2^h - h - h * 2^h + 2^(h +1) - 2
- H(n) = 2^(h +1) - h - 2 = 2 * (2^h - 1) - h = 2n - h = 2n - log(n - 1) = O(n)
公式推导
S(h) = 1 * 2^1 + 2 * 2^2 + 3 * 2^3 + ... + (h - 1) * 2^(h - 1)
2S(h) = 1 * 2^2 + 2 * 2^3 + 3 * 2^4 + ... + (h - 1) * 2^h
S(h) - 2S(h) = [2^1 + 2^2 + 2^3 + ... + 2^(h - 1)] - (h - 1) * 2^h = (2^h - 2) - (h - 1) * 2^h
S(h) = (h - 1) * 2^h - (2^h - 2) = (h - 2) * 2^h +2
疑惑
以下两种方法可以批量建堆吗?
- 自上而下的下滤
- 自下而上的上滤
上述两种方法不可信,为什么?
我们可以认真思考[自上而下的上滤],[自下而上的下滤]的本质
-
如何构建一个小顶堆
我们可以直接使用我们现在所写大顶堆来实现一个小顶堆,因为我们现在是使用默认的Comparator来比较两个值的大小,因此我们可以自定义比较两个值的大小,我们可以认为两个值当中,值大的结果最小,这样就可以通过大顶堆实现小顶堆。
-
Top K问题
从n个整数中,找出最大的前K个数(K远远小于n)
我们可以使用以下的一些方法来解决
- 使用排序算法进行全排序,此时需要的时间复杂度为O(nlogn)
- 使用二叉堆来解决,此时需要的时间复杂度为O(nlogk)
这里我们就以效率更高的二叉堆来实现,实现流程
- 新建一个小顶堆
- 扫描n个整数
- 先将遍历到的前k个数放入堆中
- 从第k + 1个数开始,如果大于堆顶元素,就使用replace操作(删除堆顶元素,将第k + 1个数添加到堆中)
- 扫描完毕后,堆中剩下的就是最大的前k个数
同理,如果是找出最小的前k个数,则利用相反的方式实现即可
- 新建一个大顶堆
- 如果小于堆顶元素,就使用replace操作
关于Top K问题的实现代码,可以参照demo中的代码实现。
-
练习
- 了解和实现堆排序
- 使用堆排序将一个无需数组转换为一个升序数组
- 空间复杂度能否下降至O(1)
GitHub地址
本节完!