Matrix Factorization
①linearNetwork Hypothesis
机器学习的作用就是要从一堆数据中学习到学习到某种能力,然后用这种skill来预测未来的结果。比如一个电影推荐的例子,我们手上有很多的电影数据,现在就需要训练一个机器学习的模型来使得这个模型可以预测一个新来的用户会喜欢什么电影,然后推荐过去。或者是对用户没有看过的电影进行评分预测。

Nefix公司曾经举办过一场比赛,包含了大量的电影数据信息和近一亿个排名信息。用

仔细看一下这些ID特征,通常就是数字表示,比如1126,5566,6211等。这些数字编号并没有什么太大的意义,都只是一种ID编号而已。这类特征,被称为类别特征,比如:ID号,blood type,programming languages等等,而许多机器学习模型都是数值特征,比如linear model,都是一串的数据,决策树例外,可以是类别区分。 所以要建立一个推荐系统的机器学习模型,就要把用户的ID号这些categorical features转换成numerical features,这种转换其实就是一个编码的过程了。

一种比较简单的就是binary vector encode。也就是说,如果输入样本有N个,就构造一个维度为N的向量。对应第n个样本那么第n个位置就是1其他都是0,比如下面的一个例子:

有点像one-hot向量,但不是。编码之后,那么用户的ID就是binary vector了。要注意的是用户是不一定对每一个电影都会进行评分,可以就是评了一部分而已:

我们就是要预测那些没有被评分的电影。 对于这个过程,我们要做的就是掌握每一个用户对于不同电影的喜爱程度,掌握这个电影的各种特征factor,比如有多少的喜剧,有多少的悬疑等等。这其实就是一个特征提取的过程。这里使用的是
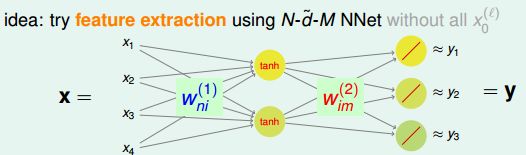
中间还有一个小问题,中间有一个非线性的函数,目的就是要使得整个模型nonlinear化,可以处理非线性的数据,但是在这里需不需要呢?其实是不需要的,因为输入的向量是encoding得到的,大部分是0,小部分是1,那么就意味着这后面乘上的W权值其实就是只用一行有用,其他都是0,相当于只有一个权重值进入到tanh函数进行运算。从效果上来说,tanh(x)与x是无差别的,只是单纯经过一个函数的计算,并不影响最终的结果,修改权重值即可得到同样的效果。因为进入计算之后,修改权值就可以达到效果了,而之前需要的原因是,之前的结果都是需要多个权值就行组合,不加tanh就是线性组合了,所以加来变成非线性。这里就只有一个,不存在什么组合,所以直接使用即可。
改进一下,就是下面的图像了:

对于这种结构,自然就是linearNetwork了,这个网络结构里面:就是Nxd,用V来表示,其实应该是V的转置,隐藏层到输出层:是dxM,所以进行线性模型之后:
如果是单个用户,那么其他的都是0,只有第n个位置才是1,所以,输出的hypothesis:
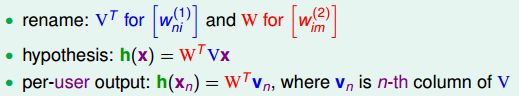
②Basic Matrix Factorization
上面的变换VX我们看做是一种特征转换,φ(x),那么就可以变成这样:
如果是对于单部电影:

我们需要做的就是看看排名WV和y的结果要差不多,也就是做拟合,所以error function就是square error function:

上式中,灰色的部分是常数,并不影响最小化求解,所以可以忽略。接下来,我们就要求出Ein最小化时对应的V和W解。
根据上式的分解:
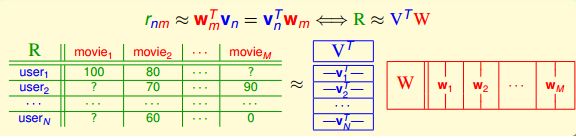
所以一个电影的评分是可以分成两个部分的,一个是V的部分,一个就是W的部分,V可以看做是用户的部分,W是电影的部分,抽象一下其实就是:V这一行矩阵里面其实就是各种用户的feature,也就是分解出来的factorization,比如这个用户有多喜欢喜剧呀,有多喜欢打戏呀,有多喜欢剧情等等,当然这只是抽象化了而已,毕竟numerical features转成类别特征是需要想象力的,比如男生女生转成0和1,但是0和1想成男生女生就有点难了。对应回上面的,那么W矩阵自然就是有多少喜剧内容,有多少打戏,有多少剧情了。
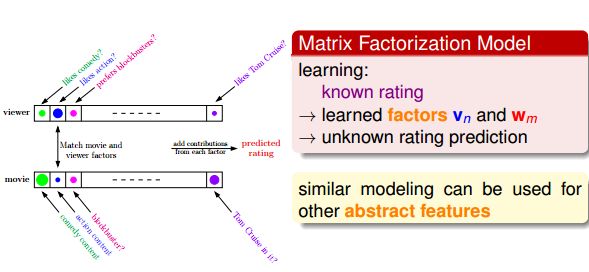
最小化Ein函数:

这里包含了两组优化的参数,一个是W,一个是V,这种情况有点像SVM的SMO算法,继续沿用它的想法,固定一个W选择更新V。
固定W的时候,对每一个用户做linear regression即可。
固定V的时候,对每一部做linear regression即可。VW在结构上对称的,所以这两个东西的优化式子是差不多的,调换一下位置即可。

所以这样就得到了算法流程:

对于alternating least squares algorithm有两点要注意的:
①intintialize不能选择初始化为0的,因为矩阵是相乘得到,如果是0,那么全部都是0了,优化也是0,没有任何作用。
②converge,收敛性,对于每一步的优化都是冲着减小Ein去的,这就保证了这个算法的收敛性。

④对于Matrix Factorization和Linear Autoencode的比较

可以看出这两者是有很强的相似性的,所以linear antoencode可以看做是matrix fatorization的一种形式的。
⑤SGD做优化
之前的迭代是所有的一起,SGD就是随机梯度下降,随机找一笔资料,只在这个资料上下做优化,效率很高,程序简单也容易实现,同时扩展到其他的错误也是很简单的。

对于每一笔资料如上图
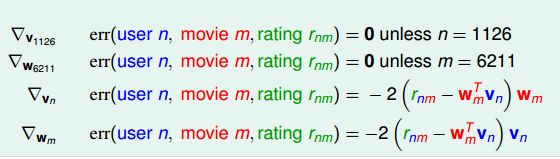
如果这个用户没有评价过这部电影,那么就是0,优化也会是0的,这就是为什么initial不能为0的原因。从上述的图片也可以看出W和V是对称的,第一项都是residual。所以当我们使用了SGD之后,那么这个算法的流程就改变了:

还有一个需要知道的,在推荐的过程中,用户的习惯是可能发生改变的,比如三年前喜欢DC,三年后就喜欢漫威了,所以随着时间的变化,数据也应该随着时间的变化,所以在使用SGD的过程中,最后的T次迭代我们可以使用时间比较靠近的样本放入optimization中作为优化数据,相对来说结果也会比较准。

⑥summary
总结一下所学过的提取特征:
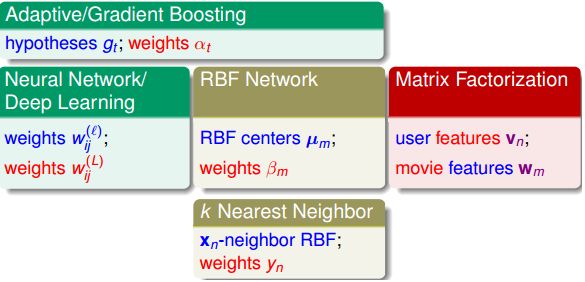
Adaboost是通过每一次选择最好的特征进行划分,也是一种Extraction Model,Network肯定是了,隐藏层就是一个提取的方法,k近邻是用距离作为特征提取的工具,MF就是刚刚说的矩阵分解了。
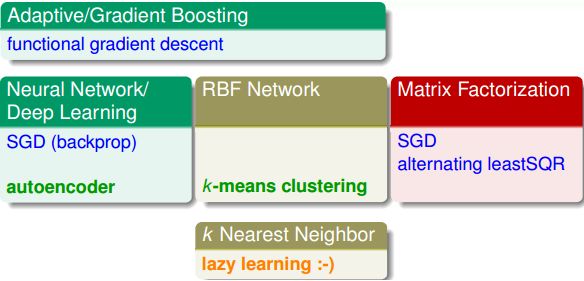
以上就是对应的技巧了。
优缺点
优点:简单,机器可以自动化的提取特征。powerful,可以处理各种复杂的问题,比如神经网络。
缺点:hard:比较难,有时候会遇到non-convex的问题,容易得到局部最优。overfit:过拟合的问题,其实上面的矩阵分解还是需要正则化处理的。后面的代码实现加上了。

⑦代码实现
1.数据的获取
我们处理的数据是一个矩阵,先找到一些movie的数据:

电影的ID名字,事实上名字我们倒不是特别关心。
还有一个评分的csv:

我们要看的其实就是123列而已了。我们要做的就是合成一个矩阵:
def load_Data(moves_name, ratings_name):
print('loading data ......')
movies = pd.read_csv('../Data/' + moves_name)
ratings = pd.read_csv('../Data/' + ratings_name)
n_movies = len(movies)
n_ratings = len(ratings)
last_movies = int(movies.iloc[-1].movieId)
last_users = int(ratings.iloc[-1].userId)
dataMat = np.zeros((last_users, last_movies))
for i in range(len(ratings)):
rating = ratings.loc[i]
dataMat[int(rating.userId) - 1, int(rating.movieId) - 1] = rating['rating']
pass
return dataMat
要注意的是,这里电影的ID不是连在一起的,有点坑。
2.梯度上升做optimization
def gradDscent(dataMat, k, alpha, beta, maxIter):
'''
:param dataMat:dataSet
:param k: params of the matrix fatorization
:param alphs: learning rate
:param beta: regularization params
:param maxIter: maxiter
:return:
'''
print('start training......')
m, n = np.shape(dataMat)
p = np.mat(np.random.random((m, k)))
q = np.mat(np.random.random((k, n)))
for step in range(maxIter):
for i in range(m):
for j in range(n):
if dataMat[i, j] > 0:
error = dataMat[i, j]
for r in range(k):
error = error - p[i, r]*q[r, j]
for r in range(k):
p[i, r] = p[i, r] + alpha * (2 * error * q[r, j] - beta * p[i, r])
q[r, j] = q[r, j] + alpha * (2 * error * p[i, r] - beta * q[r, j])
loss = 0.0
for i in range(m):
for j in range(n):
if dataMat[i, j] > 0:
error = 0.0
for r in range(k):
error = error + p[i, r] * q[r, j]
loss = np.power((dataMat[i, j] - error), 2)
for r in range(k):
loss = loss + beta * (p[i, r]*p[i, r] + q[r, j]*q[r, j])/2
if loss < 0.001:
break
print('step : ', step, ' loss : ', loss)
return p, q
并没有使用SGD,只是完全迭代。k就是分解的因子了,可以5个10个等等。中间都是按部就班的根据公式来即可。但是中间加入的正则化,求导也是很容易得到结果的。
p, q = gradDscent(dataMat, 10, 0.0002, 0.02, 100000)
跑的太慢了,使用直接看loss就好了,毕竟很简单而已。

都是不断减小的。
附上GitHub代码:https://github.com/GreenArrow2017/MachineLearning/tree/master/MachineLearning/MatrixFactorization