ELK集群部署(五)
ELK集群部署(五)
ELK 是 elastic 公司旗下三款产品ElasticSearch、Logstash、Kibana的首字母组合,也即Elastic Stack包含ElasticSearch、Logstash、Kibana、Beats。ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用,是目前主流的一种日志系统。
ElasticSearch 一个基于 JSON 的分布式的搜索和分析引擎,作为 ELK 的核心,它集中存储数据,
用来搜索、分析、存储日志。它是分布式的,可以横向扩容,可以自动发现,索引自动分片
Logstash 一个动态数据收集管道,支持以 TCP/UDP/HTTP 多种方式收集数据(也可以接受 Beats 传输来的数据),
并对数据做进一步丰富或提取字段处理。用来采集日志,把日志解析为json格式交给ElasticSearch
Kibana 一个数据可视化组件,将收集的数据进行可视化展示(各种报表、图形化数据),并提供配置、管理 ELK 的界面
Beats 一个轻量型日志采集器,单一用途的数据传输平台,可以将多台机器的数据发送到 Logstash 或 ElasticSearch
X-Pack 一个对Elastic Stack提供了安全、警报、监控、报表、图表于一身的扩展包,不过收费
官网:https://www.elastic.co/cn/ ,中文文档:https://elkguide.elasticsearch.cn/
下载elk各组件的旧版本:
https://www.elastic.co/downloads/past-releases
环境准备
- 角色划分:
系统:CentOS 7
es主节点/es数据节点/kibana/head 192.168.100.128
es主节点/es数据节点 192.168.100.129
es主节点/es数据节点 192.168.100.130
kafka集群/zookeeper集群/logstash 192.168.100.131
kafka集群/zookeeper集群/logstash 192.168.100.132
kafka集群/zookeeper集群/logstash 192.168.100.133
日志测试/logstash/filebeat 192.168.100.134
- 全部关闭防火墙和selinux:
# systemctl stop firewalld && systemctl disable firewalld
# sed -i 's/=enforcing/=disabled/g' /etc/selinux/config && setenforce 0
- 全部配置系统环境:
# vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
# vim /etc/sysctl.conf
vm.max_map_count=655360
# sysctl -p
- 全部安装Java环境:
# tar zxf jdk-8u191-linux-x64.tar.gz && mv jdk1.8.0_191/ /usr/local/jdk
# vim /etc/profile
JAVA_HOME=/usr/local/jdk
PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib
export JAVA_HOME PATH CLASSPATH
# source !$
# java -version
# ln -s /usr/local/jdk/bin/java /usr/local/bin/java
ELK结合Kafka
生产初期,Service服务较少,访问量较少,使用ELFK集群就可以满足生产需求。但随着业务量的不断增加,日志量成倍增长,针对此情况,需要对ELK增加消息队列,以减轻前端ES集群的压力。
那么选择redis还是kafka作为消息队列呢?从以下三点考虑:
* 消息推送的可靠性:
Redis 消息推送(基于分布式 Pub/Sub)多用于实时性较高的消息推送,并不保证可靠。
Redis-Pub/Sub 断电就会清空数据,而使用 Redis-List 作为消息推送虽然有持久化,也并非完全可靠不会丢失。
Kafka 虽然有一些延迟但保证可靠。
* 订阅功能的分组:
Redis 发布订阅除了表示不同的 topic 外,并不支持分组。
Kafka 中发布一个内容,多个订阅者可以分组,同一个组里只有一个订阅者会收到该消息,这样可以用作负载均衡。
* 集群资源的消耗:
Redis 3.0之后个有提供集群ha机制,但是要为每个节点都配置一个或者多个从节点,从节点从主节点上面拉取数据,主节点挂了,从节点顶替上去成为主节点,但是这样对资源比较浪费。
Kafka 作为消息队列,能充分的运用集群资源,每个应用相当于一个topic,一个topic可拥有多个partition,并且partition能轮询分配到每个节点上面,并且生产者生产的数据也会均匀的放到partition中,
即使上层只有1个应用kafka集群的资源也会被充分的利用到,这样就避免了redis集群出现的数据倾斜问题,并且kafka有类似于hdfs的冗余机制,一个broker挂掉了不影响整个集群的运行。
这里,我们选择kafka作为消息队列,配置kafka集群,结合ELFK集群收集应用日志。
ELK集群安装参考这里:ELK集群搭建(一)
kafka集群安装
Apache kafka是消息中间件的一种,是一种分布式的、基于发布/订阅的消息系统。能实现一个为处理实时数据提供一个统一、高吞吐、低延迟的平台,且拥有分布式的,可划分的,冗余备份的持久性的日志服务等特点。
- 整体架构:
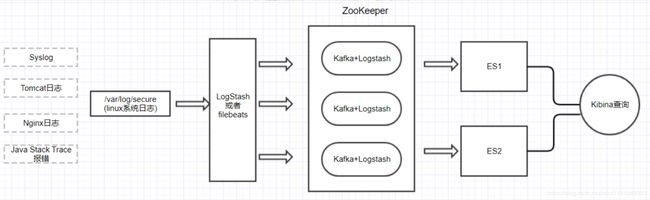
- 环境准备:
kafka集群/zookeeper集群/logstash 192.168.100.131
kafka集群/zookeeper集群/logstash 192.168.100.132
kafka集群/zookeeper集群/logstash 192.168.100.133
- 全部下载安装kafka:
# cd /software
# wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.2.0/kafka_2.11-2.2.0.tgz
# tar zxf kafka_2.11-2.2.0.tgz && mv kafka_2.11-2.2.0 /usr/local/kafka
- 全部修改zookeeper配置:
# vim /usr/local/kafka/config/zookeeper.properties
dataDir=/usr/local/kafka/zookeeper
clientPort=2181
maxClientCnxns=1024
tickTime=2000
initLimit=20
syncLimit=10
server.1=192.168.100.131:2888:3888
server.2=192.168.100.132:2888:3888
server.3=192.168.100.133:2888:3888
说明:
tickTime : 这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
2888 端口:表示的是这个服务器与集群中的 Leader 服务器交换信息的端口。
3888 端口:表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader ,而这个端口就是用来执行选举时服务器相互通信的端口。
- 创建所需目录、文件:
在zookeeper目录下创建myid文件,里面的内容为数字,用于标识主机,如果这个文件没有的话,zookeeper是没法启动的。
# mkdir /usr/local/kafka/zookeeper
# echo 1 > /usr/local/kafka/zookeeper/myid #另两台机器分别输入2/3,每台机器id不同即可
- 修改kafka配置:
# vim /usr/local/kafka/config/server.properties
broker.id=1 #ID唯一,填数字,本文中分别为1/2/3
port=9092
host.name=192.168.100.131 #本机ip
log.dirs=/data/kafka/kafka-logs #数据存放目录,不是日志目录
num.partitions=16 #每个topic的默认分区数
log.retention.hours=168 #过期时间,默认为1周
zookeeper.connect=192.168.100.131:2181,192.168.100.132:2181,192.168.100.133:2181 #zookeeper ip及端口
# mkdir -p /data/kafka
其它两台机器照着上面配置即可,此处过程省略。
- 配置zookeeper服务:
# vim /usr/bin/zk_kafka
#!/bin/bash
#chkconfig: 2345 55 24
#description: zookeeper and kafka service manager
BASE_DIR=/usr/local/kafka
SERVICE=$1
START_ZK()
{
cd $BASE_DIR
nohup $BASE_DIR/bin/zookeeper-server-start.sh $BASE_DIR/config/zookeeper.properties &>/dev/null &
}
STOP_ZK()
{
cd $BASE_DIR
nohup $BASE_DIR/bin/zookeeper-server-stop.sh &>/dev/null &
}
START_KAFKA()
{
cd $BASE_DIR
nohup $BASE_DIR/bin/kafka-server-start.sh $BASE_DIR/config/server.properties &>/dev/null &
}
STOP_KAFKA()
{
cd $BASE_DIR
nohup $BASE_DIR/bin/kafka-server-stop.sh &>/dev/null &
}
if [ -z "$1" ];
then
echo $"Usage: $0 {zookeeper|kafka} {start|stop|restart}"
exit 0
else
if [ "$1" != "zookeeper" ] && [ "$1" != "kafka" ];
then
echo $"Usage: $0 {zookeeper|kafka} {start|stop|restart}"
exit 1
fi
fi
START()
{
if [ "$SERVICE" = "zookeeper" ];
then
START_ZK
if [ $? -eq 0 ];
then
echo -e "\033[32m Start $SERVICE OK. \033[0m"
fi
else
START_KAFKA
if [ $? -eq 0 ];
then
echo -e "\033[32m Start $SERVICE OK. \033[0m"
fi
fi
}
STOP()
{
if [ "$SERVICE" = "zookeeper" ];
then
STOP_ZK
if [ $? -eq 0 ];
then
echo -e "\033[32m Stop $SERVICE OK. \033[0m"
fi
else
STOP_KAFKA
if [ $? -eq 0 ];
then
echo -e "\033[32m Stop $SERVICE OK. \033[0m"
fi
fi
}
case "$2" in
start)
START
;;
stop)
STOP
;;
restart)
STOP
sleep 2
START
;;
*)
echo $"Usage: $0 {zookeeper|kafka} {start|stop|restart}"
exit 1
;;
esac
exit 0
- 全部启动zookeeper:
这里先要启动zookeeper集群,才能启动kafka。
# chmod +x /usr/bin/zk_kafka
# zk_kafka zookeeper start
# netstat -lntp | grep -E "2181|2888|3888" #检查端口,拥有2888端口为leader
tcp6 0 0 192.168.100.132:2888 :::* LISTEN 6787/java
tcp6 0 0 192.168.100.132:3888 :::* LISTEN 6787/java
tcp6 0 0 :::2181 :::* LISTEN 6787/java
- 全部启动kafka:
zookeeper集群已经启动起来了,下面启动kafka。
# zk_kafka kafka start
- 创建一个topic(192.168.100.131上):
任选一台机器,这里我是192.168.100.131
# /usr/local/kafka/bin/kafka-topics.sh --create --zookeeper 192.168.100.131:2181 --replication-factor 3 --partitions 1 --topic test #注意:factor大小不能超过broker的个数
Created topic test.
- 查看已创建的topic:
任选一台机器,这里我是192.168.100.132
# /usr/local/kafka/bin/kafka-topics.sh --list --zookeeper 192.168.100.132:2181
test
查看topic test的详情
# /usr/local/kafka/bin/kafka-topics.sh --describe --zookeeper 192.168.100.132:2181 --topic test
Topic:test PartitionCount:1 ReplicationFactor:3 Configs:
Topic: test Partition: 0 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
上面,
#主题名称:test
#Partition:只有一个,从0开始
#leader :id为1的broker
#Replicas 副本存在于broker id为1,2,3的上面
#Isr:活跃状态的broker
- 发送消息,使用生产者角色:
任选一台机器,这里我是192.168.100.131
# /usr/local/kafka/bin/kafka-console-producer.sh --broker-list 192.168.100.131:9092 --topic test
>This is a test message for kafka producer
>welcome
>let's go
- 接收消息,使用消费者角色:
任选一台机器,这里我是192.168.100.133
# /usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.100.133:9092 --topic test --from-beginning # --from-beginning表示从开始接收,否则只接收新产生的消息
This is a test message for kafka producer
welcome
let's go

可以看到,以上是Kafka生产者和消费者的测试,基于Kafka的Zookeeper集群没有问题。
安装logstash+filebeat
- 需要安装:
192.168.100.131 logstash
192.168.100.132 logstash
192.168.100.133 logstash
192.168.100.134 logstash+filebeat
- 安装logstash:
# cd /software
# tar zxf logstash-6.7.1.tar.gz && mv logstash-6.7.1/ /usr/local/logstash
# mkdir /usr/local/logstash/conf.d
# useradd elk
# vim /usr/local/logstash/config/logstash.yml
http.host: "192.168.100.131" #填本机ip
http.port: 9600
xpack.monitoring.enabled: true
xpack.monitoring.elasticsearch.username: logstash_system
xpack.monitoring.elasticsearch.password: elk-2019
xpack.monitoring.elasticsearch.hosts: ["http://192.168.100.128:9200","http://192.168.100.129:9200","http://192.168.100.130:9200"]
xpack.monitoring.collection.interval: 10s
- 配置logstash服务:
服务配置文件
# vim /etc/default/logstash
LS_HOME="/usr/local/logstash"
LS_SETTINGS_DIR="/usr/local/logstash"
LS_PIDFILE="/usr/local/logstash/run/logstash.pid"
LS_USER="elk"
LS_GROUP="elk"
LS_GC_LOG_FILE="/usr/local/logstash/logs/gc.log"
LS_OPEN_FILES="16384"
LS_NICE="19"
SERVICE_NAME="logstash"
SERVICE_DESCRIPTION="logstash"
服务文件
# vim /etc/systemd/system/logstash.service
[Unit]
Description=logstash
[Service]
Type=simple
User=elk
Group=elk
# Load env vars from /etc/default/ and /etc/sysconfig/ if they exist.
# Prefixing the path with '-' makes it try to load, but if the file doesn't
# exist, it continues onward.
EnvironmentFile=-/etc/default/logstash
EnvironmentFile=-/etc/sysconfig/logstash
ExecStart=/usr/local/logstash/bin/logstash "--path.settings" "/usr/local/logstash/config" "--path.config" "/usr/local/logstash/conf.d"
Restart=always
WorkingDirectory=/
Nice=19
LimitNOFILE=16384
[Install]
WantedBy=multi-user.target
管理服务:
# mkdir /usr/local/logstash/{run,logs} && touch /usr/local/logstash/run/logstash.pid
# touch /usr/local/logstash/logs/gc.log && chown -R elk:elk /usr/local/logstash
# systemctl daemon-reload
# systemctl enable logstash
- 安装filebeat:
# tar zxf filebeat-6.7.1-linux-x86_64.tar.gz && mv filebeat-6.7.1-linux-x86_64 /usr/local/filebeat
- 配置filebeat服务:
服务文件
# vim /usr/lib/systemd/system/filebeat.service
[Unit]
Description=Filebeat sends log files to Logstash or directly to Elasticsearch.
Documentation=https://www.elastic.co/products/beats/filebeat
Wants=network-online.target
After=network-online.target
[Service]
ExecStart=/usr/local/filebeat/filebeat -c /usr/local/filebeat/filebeat.yml -path.home /usr/local/filebeat -path.config /usr/local/filebeat -path.data /usr/local/filebeat/data -path.logs /usr/local/filebeat/logs
Restart=always
[Install]
WantedBy=multi-user.target
管理服务:
# mkdir /usr/local/filebeat/{data,logs}
# systemctl daemon-reload
# systemctl enable filebeat
结合kafka
这里,我们以收集nginx访问日志/var/log/nginx/access.log和系统日志/var/log/messages为例,测试ELFK与kafka结合。
192.168.100.134上配置nginx和logstash
- nginx日志配置:
# yum install -y nginx
# vim /etc/nginx/nginx.conf #默认设置
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
# access_log /var/log/nginx/access.log main;
# vim /etc/nginx/conf.d/elk.conf
server {
listen 80;
server_name elk.test.com;
location / {
proxy_pass http://192.168.100.128:5601;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
access_log /var/log/nginx/elk.log main;
}
电脑 hosts文件添加一行:192.168.100.134 elk.test.com。
- 配置filebeat:
# vim /usr/local/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/messages #系统日志
fields:
log_topics: sys_messages-log
- type: log
enabled: true
paths:
- /var/log/nginx/elk.log #nginx访问日志
fields:
log_topics: nginx_access-log
output.kafka:
enabled: true
hosts: ["192.168.100.131:9092","192.168.100.132:9092","192.168.100.133:9092"]
topic: '%{[fields][log_topics]}'
- 配置logstash(可选部分):
除了使用filebeat收集日志输出到kafka之外,还可以通过logstash收集日志到kafka,这一步不需要过滤。
# vim /usr/local/logstash/conf.d/test.conf
input {
file {
path => "/var/log/messages"
#start_position => "beginning"
type => "sys_messages"
sincedb_path => "/dev/null"
}
file {
path => "/var/log/nginx/elk.log"
#start_position => "beginning"
type => "nginx_access"
sincedb_path => "/dev/null"
}
}
output {
if [type] == "sys_messages" {
kafka {
bootstrap_servers => "192.168.100.131:9092,192.168.100.132:9092,192.168.100.133:9092"
topic_id => "sys_messages-log"
compression_type => "snappy" #消息压缩模式
}
}
if [type] == "nginx_access" {
kafka {
bootstrap_servers => "192.168.100.131:9092,192.168.100.132:9092,192.168.100.133:9092"
topic_id => "nginx_access-log"
compression_type => "snappy"
}
}
}
# chown -R elk:elk /usr/local/logstash
# /usr/local/logstash/bin/logstash-plugin install logstash-output-kafka
# /usr/local/logstash/bin/logstash -f /usr/local/logstash/conf.d/test.conf -t #显示OK说明配置文件没问题
- kafka集群创建topic:
任选一台机器创建
# /usr/local/kafka/bin/kafka-topics.sh --create --zookeeper 192.168.100.131:2181 --replication-factor 3 --partitions 1 --topic sys_messages-log
Created topic sys_messages-log.
# /usr/local/kafka/bin/kafka-topics.sh --create --zookeeper 192.168.100.131:2181 --replication-factor 3 --partitions 1 --topic nginx_access-log
Created topic nginx_access-log.
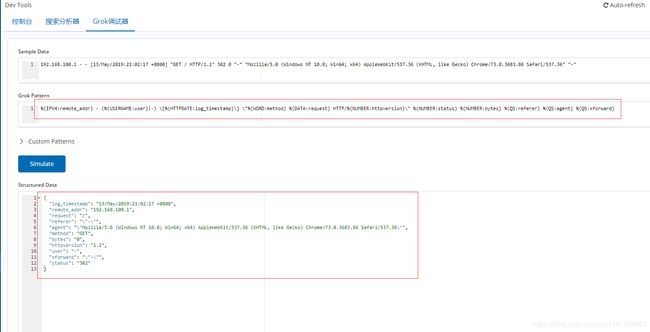
- grok过滤nginx访问日志:
%{IPV4:remote_addr} - (%{USERNAME:user}|-) \[%{HTTPDATE:log_timestamp}\] \"%{WORD:method} %{DATA:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:status} %{NUMBER:bytes} %{QS:referer} %{QS:agent} %{QS:xforward}
- kafka集群logstash配置:
所有kafka集群机器进行配置。作为kafka集群,所有消息的过滤(消费)在这里进行。
# vim /usr/local/logstash/conf.d/messages.conf
input {
kafka {
bootstrap_servers => "192.168.100.131:9092,192.168.100.132:9092,192.168.100.133:9092"
group_id => "system" #默认为logstash
topics => "sys_messages-log"
auto_offset_reset => "latest" #从最新的偏移量开始消费
consumer_threads => 5 #消费的线程数
decorate_events => true #在输出消息的时候回输出自身的信息,包括:消费消息的大小、topic来源以及consumer的group信息
type => "sys_messages"
}
}
output {
elasticsearch {
hosts => ["192.168.100.128:9200","192.168.100.129:9200","192.168.100.130:9200"]
user => "elastic"
password => "elk-2019"
index => "sys_messages.log-%{+YYYY.MM.dd}"
}
}
# vim /usr/local/logstash/conf.d/nginx.conf
input {
kafka {
bootstrap_servers => "192.168.100.131:9092,192.168.100.132:9092,192.168.100.133:9092"
group_id => "nginx"
topics => "nginx_access-log"
auto_offset_reset => "latest"
consumer_threads => 5
decorate_events => true
type => "nginx_access"
}
}
filter {
if [type] == "nginx_access" {
grok {
match => [ "message", "%{IPV4:remote_addr} - (%{USERNAME:user}|-) \[%{HTTPDATE:log_timestamp}\] \"%{WORD:method} %{DATA:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:status} %{NUMBER:bytes} %{QS:referer} %{QS:agent} %{QS:xforward}"]
}
}
}
output {
elasticsearch {
hosts => ["192.168.100.128:9200","192.168.100.129:9200","192.168.100.130:9200"]
user => "elastic"
password => "elk-2019"
index => "nginx_access.log-%{+YYYY.MM.dd}"
}
}
# chown -R elk:elk /usr/local/logstash
# /usr/local/logstash/bin/logstash-plugin install logstash-input-kafka
# /usr/local/logstash/bin/logstash -f /usr/local/logstash/conf.d/messages.conf -t #显示OK说明配置文件没问题
# /usr/local/logstash/bin/logstash -f /usr/local/logstash/conf.d/nginx.conf -t
- 启动相关服务:
# systemctl start nginx #192.168.100.134
# systemctl start filebeat #192.168.100.134
或者 systemctl start logstash
# systemctl start logstash #kafka集群
可以查看logstash日志
# tail -f /usr/local/logstash/logs/logstash-plain.log
- kibana页面查看:
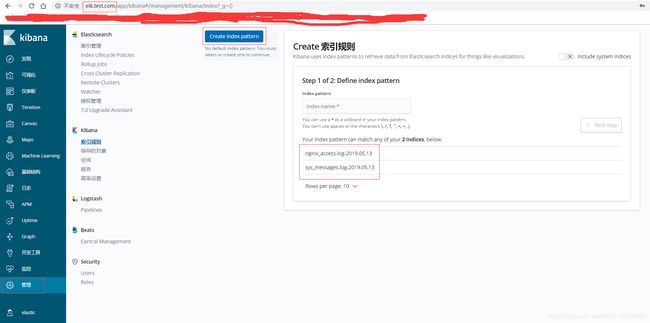
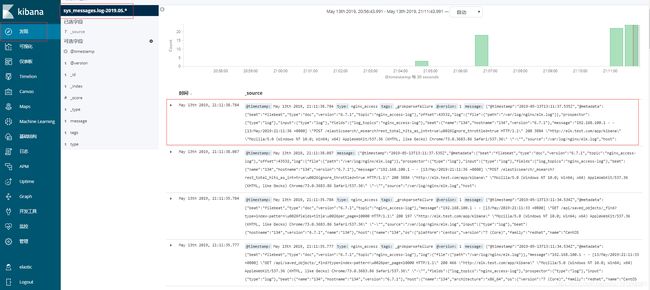
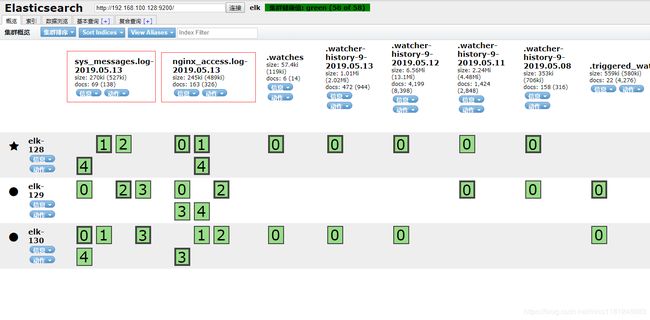
var/log/messages输入数据:
# echo "该消息是通过Kafka队列到达ES集群!!!" >> /var/log/messages
# echo "该消息是通过Kafka队列到达ES集群!!!" >> /var/log/messages
# echo "该消息是通过Kafka队列到达ES集群!!!" >> /var/log/messages
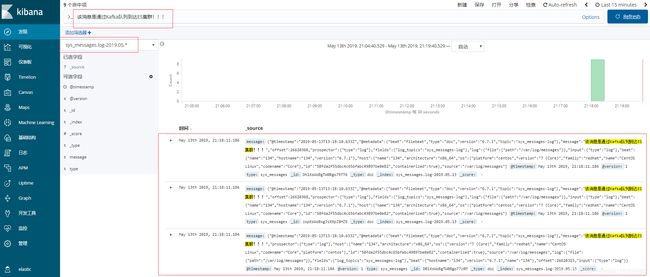
可以看到,filebest与kafka结合收集的系统日志是没有问题的。
/var/log/nginx/access.log输入数据:
浏览器访问elk.test.com,以产生访问日志。
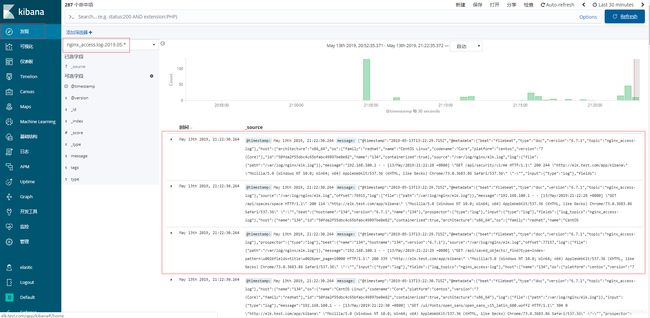
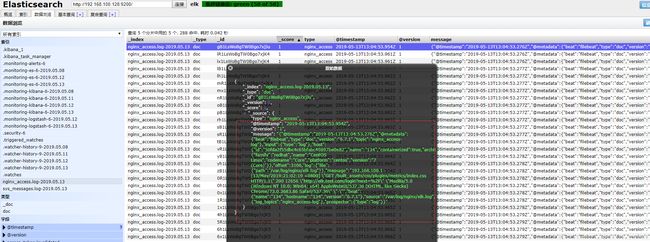
# echo "该消息是NGINX日志通过Kafka队列到达ES集群!!!" >> /var/log/nginx/elk.log
# echo "该消息是NGINX日志通过Kafka队列到达ES集群!!!" >> /var/log/nginx/elk.log
# echo "该消息是NGINX日志通过Kafka队列到达ES集群!!!" >> /var/log/nginx/elk.log
至此,ELFK集群结合kafka集群收集日志完成。
可以看到,过滤条件没有完全设置好,因为是以json格式传输的,可以在配置文件中添加一行:codec => json,不过logstash和filebeat结合kafka输出日志到elasticsearch集群是没有问题的。