Linux Ubuntu 16.04系统Tensorflow-GPU安装和配置(以使用PointCNN开源代码为例)
之前文章介绍了在win10安装linux子系统,方便我们跑一些支持Linux环境的开源代码。但如果要用到Nvidia的GPU和CUDA,我们最好找个服务器,目的是方便自己快速训练模型;如果只是想跑跑模型,不训练的话,可以在双系统上配置tensorflow环境(虚拟机实在太慢)。
为什么不在子系统配置呢?最主要的原因是,目前win10支持的linux子系统还比较简单,找不到Nvidia的GPU(给你们泼了一盆冷水吧,hahahaha ~~ )
那接下来,我以开源代码PointCNN为例,讲一下Tensorflow的安装。最重要的一点,不要总想着安装最新版本的CUDA或cudnn,因为很可能你要跑的开源代码根本不支持你安装的版本。 所以,要先从仔细阅读开源代码开始,尽可能地避免返工重装。
一、明确安装软件版本

源代码需要安装Tensorflow1.6和python3。于是找到和Tensorflow对应的CUDA版本,cudnn。
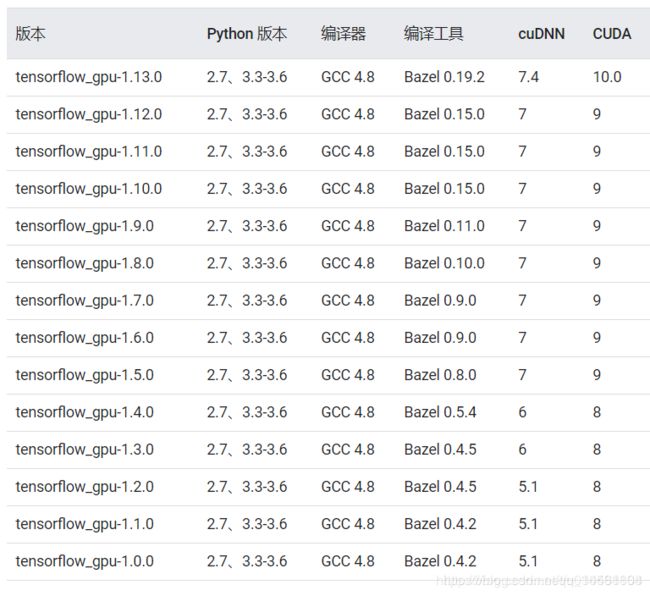
注意,这里cudnn的版本是9,我们最好选择9.0。如果是10,最好选择10.0。 亲测:安装了CUDA9.2版本,会报错:找不到需要的9.0版本的动态库
二、安装Nvidia驱动
一般双系统安装好后,默认使用nouveau,需要我们手动安装Nvidia驱动。安装步骤:
3.1 禁用nouveau
sudo gedit /etc/modprobe.d/blacklist.conf
在最后添加:
blacklist nouveau
options nouveau modeset=0
保存退出编辑。
执行下面的操作:
sudo update-initramfs -u
重启后执行:
lsmod | grep nouveau
若没有输出则表示屏蔽nouveau成功。
3.2安装驱动
进入电脑的设备管理器,找到自己的显卡

登录 https://www.geforce.cn/drivers, 根据自己的显卡下载可用驱动
注意:根据新旧版本不同,下载2~3个驱动。因为,nvidia驱动对双系统下的linux支持并不是很完美。有时候安装完驱动,重启后进不去系统。这时候需要进入控制台卸载,然后装另外一个驱动试试。
ctrl+alt+f1 进入控制台,然后登录账号和密码
然后依次输入:
sudo service lightdm stop
sudo apt-get purge nvidia-*
sudo chmod a+x NVIDIA-Linux-x86_64-410.93.run
sudo ./NVIDIA-Linux-x86_64-410.93.run –no-opengl-files -no-x-check -no-nouveau-check
必选参数解释:因为NVIDIA的驱动默认会安装OpenGL,而Ubuntu的内核本身也有OpenGL、且与GUI显示息息相关,一旦NVIDIA的驱动覆写了OpenGL,在GUI需要动态链接OpenGL库的时候就引起问题。
安装过程中一些选项:
The distribution-provided pre-install script failed! Are you sure you want to continue? yes
Would you like to register the kernel module souces with DKMS? This will allow DKMS to automatically build a new module, if you install a different kernel later? No
Nvidia’s 32-bit compatibility libraries? No
Would you like to run the nvidia-xconfigutility to automatically update your x configuration so that the NVIDIA x driver will be used when you restart x? Any pre-existing x confile will be backed up. Yes
显示成功安装之后,
sudo service lightdm start
ctrl+alt+f7进入图形界面,验证驱动是否安装好:
nvidia-smi

如果显示上图,并且重启能正常进入linux界面,意味着驱动安装成功。
三、CUDA安装
最重要的还是前面提到的,选好自己的版本
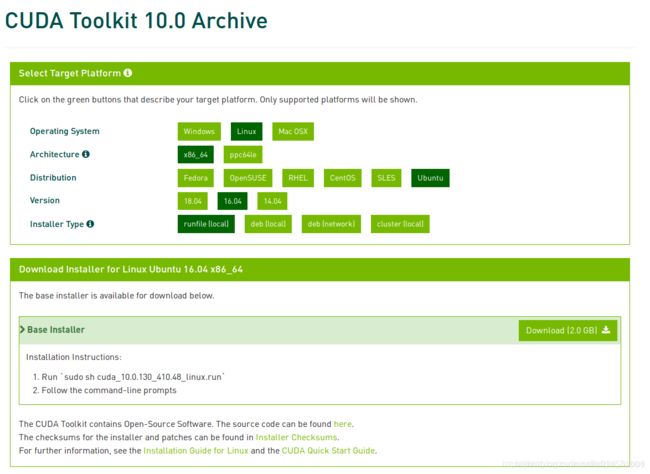
命令行:
sudo chmod a+x cuda_9.0.176_384.81_linux.run
sudo ./cuda_9.0.176_384.81_linux.run --no-opengl-libs
Do you accept the previously read EULA?
accept/decline/quit: accept
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 410.48?
(y)es/(n)o/(q)uit:n
Install the CUDA 10.0 Toolkit?
(y)es/(n)o/(q)uit:y
Enter Toolkit Location
[ default is /usr/local/cuda-10.0 ]: 直接回车
Do you want to install a symbolic link at /usr/local/cuda?
(y)es/(n)o/(q)uit: y
Install the CUDA 10.0 Samples?
(y)es/(n)o/(q)uit: n
配置环境变量:
sudo gedit ~/.bashrc
在最后添加:
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64:$LD_LIBRARY_PATH
export PATH=/usr/local/cuda-9.0/bin:$PATH
执行:
source ~/.bashrc
验证cuda安装是否成功:
nvcc -V
或者:
cd /usr/local/cuda-9.0/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
若出现如下信息,则证明安装成功:
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "GeForce GTX TITAN X"
CUDA Driver Version / Runtime Version 10.0 / 10.0
CUDA Capability Major/Minor version number: 5.2
Total amount of global memory: 12210 MBytes (12802785280 bytes)
(24) Multiprocessors, (128) CUDA Cores/MP: 3072 CUDA Cores
GPU Max Clock rate: 1076 MHz (1.08 GHz)
Memory Clock rate: 3505 Mhz
Memory Bus Width: 384-bit
L2 Cache Size: 3145728 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(65536), 2D=(65536, 65536), 3D=(4096, 4096, 4096)
Maximum Layered 1D Texture Size, (num) layers 1D=(16384), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(16384, 16384), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: No
Supports Cooperative Kernel Launch: No
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 10.0, CUDA Runtime Version = 10.0, NumDevs = 1
Result = PASS
四、安装cudnn
这里,我一开始选择了7600版本,发现在编译源代码时报错:要使用7000,提示做cudnn的降级。
下载,解压,命令行:
tar xvf cudnn-9.0-linux-x64-v7.tgz
复制到cuda目录
sudo cp cuda/include/* /usr/local/cuda/include
sudo cp cuda/lib64/* /usr/local/cuda/lib64
检测cuDNN是否安装成功,运行/usr/src/cudnn_samples_v7 中的mnistCUDNN sample
cd /usr/src/cudnn_samples_v7
cp -r /usr/src/cudnn_samples_v7/ $HOME
cd $HOME/cudnn_samples_v7/mnistCUDNN
make clean && make
./mnistCUDNN
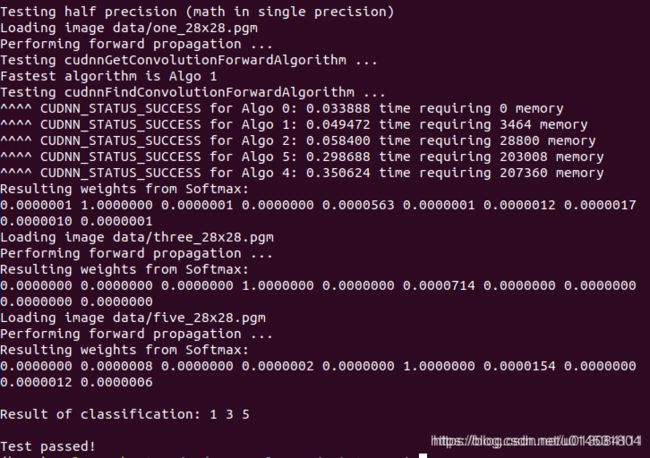
如果出现 Test passed! 则说明安装成功,结果如图
五、python3和pip3安装
依次输入命令行安装:
sudo apt install python3
sudo apt install python3-pip
查看版本号:
pip3 --version
六、tensorflow安装
也是一条命令行安装:
pip3 install tensorflow-gpu==1.6.0
注意:在跑源代码时,会显示有些软件包没有安装,使用
sudo pip3 install 包名
基本都能解决。