图解强化学习 原理 超详解 (一)
强化学习
一.背景
机器学习是人工智能的一个分支,在近30多年已发展为一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、计算复杂性理论等的学科。强化学习(RL)作为机器学习的一个子领域,其灵感来源于心理学中的行为主义理论,即智能体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。它强调如何基于环境而行动,以取得最大化的预期利益。通俗的讲:就是根据环境学习一套策略,能够最大化期望奖励。由于它具有普适性而被很多领域进行研究,例如自动驾驶,博弈论、控制论、运筹学、信息论、仿真优化、多主体系统学习、群体智能、统计学以及遗传算法。
二.强化学习定义
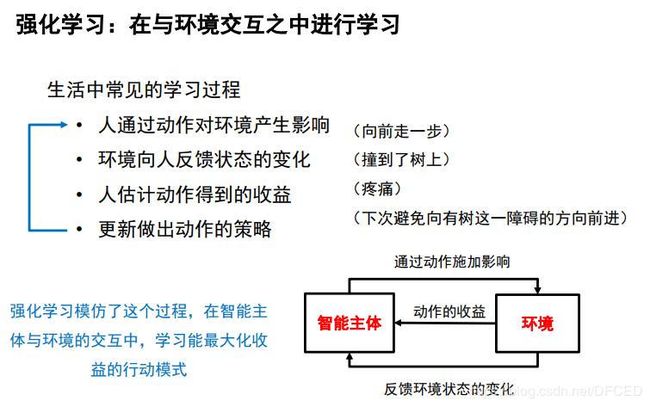
强化学习是智能体(Agent)以“试错”的方式进行学习,通过与环境进行交互获得的奖赏指导行为,目标是使智能体获得最大的奖赏,强化学习不同于连接主义学习中的监督学习,主要表现在强化信号上,强化学习中由环境提供的强化信号是对产生动作的好坏作一种评价(通常为标量信号),而不是告诉强化学习系统RLS(reinforcement learning system)如何去产生正确的动作。由于外部环境提供的信息很少,RLS必须靠自身的经历进行学习。通过这种方式,RLS在行动-评价的环境中获得知识,改进行动方案以适应环境。
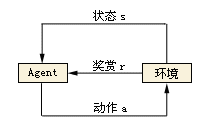
2.1 智能主体
智能体,顾名思义:就是具有智能的实体,英文名是Agent。
智能体是人工智能领域中一个很重要的概念。任何独立的能够思想并可以同环境交互的实体都可以抽象为智能体。
Agent是一个英文单词,agent指能自主活动的软件或者硬件实体。在人工智能领域,中国科学界把其译为中文"智能体"。曾被译为"代理"、“代理者”、"智能主体"等,中国科学界已经趋向于把之翻译为:智能体,艾真体(蔡自兴2002年提出)。
定义
智能体是指驻留在某一环境下,能持续自主地发挥作用,具备驻留性、反应性、社会性、主动性等特征的计算实体。
其实,智能体有很多种定义:
智能体在某种程度上属于人工智能研究范畴,因此要想给智能体下一个确切的定义就如同给人工智能下一个确切的定义一样困难。在分布式人工智能和分布式计算领域争论了很多年,也没有一个统一的认识。
研究人员从不同的角度给出了智能体的定义,常见的主要有以下几种:
-
FIPA(Foundation forIntelligent Physical 智能体),一个致力于智能体技术标准化的组织给智能体下的定义是:“智能体是驻留于环境中的实体,它可以解释从环境中获得的反映环境中所发生事件的数据,并执行对环境产生影响的行动。” 在这个定义中,智能体被看作是一种在环境中"生存"的实体,它既可以是硬件(如机器人),也可以是软件。
-
著名智能体理论研究学者Wooldridge博士等在讨论智能体时,则提出"弱定义"和"强定义"二种定义方法:弱定义智能体是指具有自主 性、社会性、反应性和能动性等基本特性的智能体;强定义智能体是指不仅具有弱定义中的基本特性,而且具有移动性、通信能力、理性或其它特性的智能体;
-
Franklin和Graesser则把智能体描述为"智能体是一个处于环境之中并且作为这个环境一部分的系统,它随时可以感测环境并且执行相应的动作,同时逐渐建立自己的活动规划以应付未来可能感测到的环境变化";
-
著名人工智能学者、美国斯坦福大学的Hayes-Roth认为"智能智能体能够持续执行三项功能:感知环境中的动态条件;执行动作影响环境条件;进行推理以解释感知信息、求解问题、产生推断和决定动作";
-
智能体研究的先行者之一,美国的Macs则认为"自治或自主智能体是指那些宿主于复杂动态环境中,自治地感知环境信息,自主采取行动,并实现一系列预先设定的目标或任务的计算系统"。
智能主体的特性
由以上定义可知,智能体具有下列基本特性:
(1)自治性(Autonomy ) : 智能体能根据外界环境的变化,而自动地对自己的行为和状态进行调整,而不是仅仅被动地接受外界的刺激,具有自我管理自我调节的能力。
(2)反应性(Reactive):能对外界的刺激作出反应的能力、
(3)主动性(Proactive):对于外界环境的改变,智能体能主动采取话动的能力。
(4)社会性(Social ) : 智能体具有与其它智能体或人进行合作的能力,不同的智能体可根据各自的意图与其它智能体进行交互,以达到解决问题的目的。
(5)进化性:智能体能积累或学习经验和知识,并修改自己的行为以适应新环境。
2.2 环境

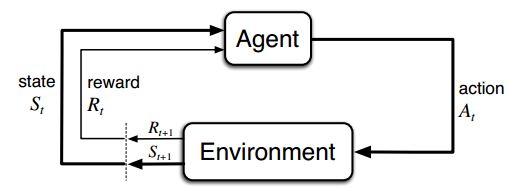
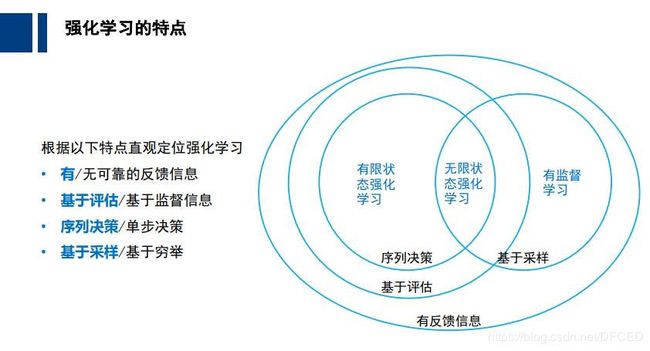
2.3 强化学习的特点

2.4 强化学习示例



强化学习在游戏中的博弈
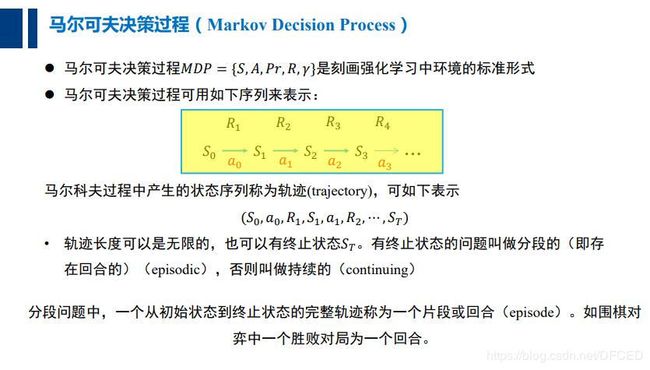
3.马尔可夫过程
3.1 什么是马尔可夫过程?
马尔可夫过程(Markov process)是一类随机过程。它的原始模型马尔可夫链,由俄国数学家A.A.马尔可夫于1907年提出。该过程具有如下特性:在已知目前状态 (现在)的条件下,它未来的演变 (将来)不依赖于它以往的演变 ( 过去 ) 。 例如森林中动物头数的变化构成–马尔可夫过程 。在现实世界中,有很多过程都是马尔可夫过程,如液体中微粒所作的布朗运动、传染病受感染的人数、车站的候车人数等,都可视为马尔可夫过程。关于该过程的研究,1931年A.H.柯尔莫哥洛夫在《概率论的解析方法》一文中首先将微分方程等分析的方法用于这类过程,奠定了马尔可夫过程的理论基础。

3.2 马尔可夫性(无后效性)
过程或(系统)在时刻t0所处的状态为已知的条件下,过程在时刻t > t0所处状态的条件分布,与过程在时刻t0之前处的状态无关的特性称为马尔可夫性或无后效性。
即:已知过程“现在”的情况,过程“将来”的情况与“过去”的情况是无关的。
3.3 马尔可夫过程定义
具有马尔可夫性的随机过程称为马尔可夫过程。
用分布函数表述马尔可夫过程:
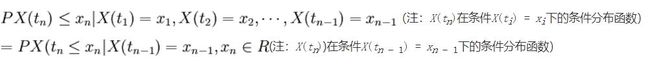
或写成:

这时称过程X(t),t\in T具马尔可夫性或无后性,并称此过程为马尔可夫过程。
3.4马尔可夫链的定义
时间和状态都是离散的马尔可夫过程称为马尔可夫链, 简记为![]()

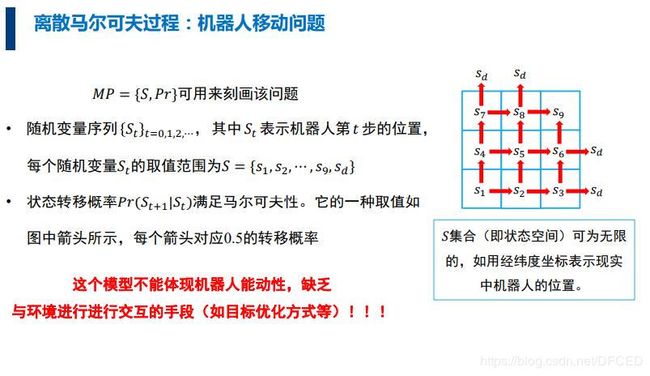
3.5 马尔可夫奖励过程
引入奖励
为了增加智能体与环境进行交互的手段,引入了奖励机制
马尔科夫奖励过程在马尔科夫过程的基础上增加了奖励R和衰减系数γ:
R是一个奖励函数。S状态下的奖励是某一时刻(t)处在状态s下在下一个时刻(t+1)能获得的奖励期望,如下:
![]()
奖励过程
为了比较不同奖励序列的好坏,定义了反馈(return),来反映累加奖励
定义:收获 ![]() 为在一个马尔科夫奖励链上从t时刻开始往后所有的奖励的有衰减的收益总和。
为在一个马尔科夫奖励链上从t时刻开始往后所有的奖励的有衰减的收益总和。
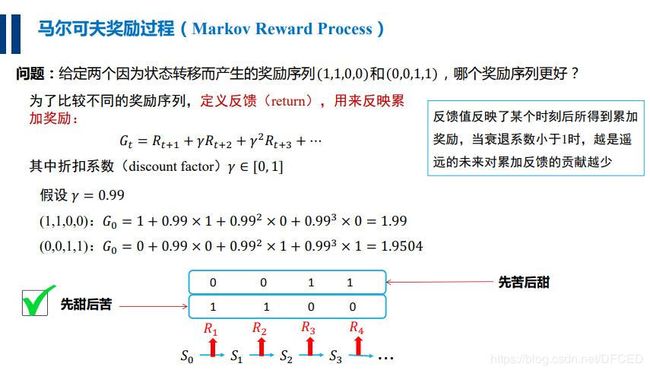
其中的 ![]() 指的是衰减因子,体现了未来的奖励在当前时刻的价值比例,这样要注意的就是Gt并不只是一条路径,从t时刻到终止状态,可能会有多条路径,后面的例子会体现到。
指的是衰减因子,体现了未来的奖励在当前时刻的价值比例,这样要注意的就是Gt并不只是一条路径,从t时刻到终止状态,可能会有多条路径,后面的例子会体现到。
![]() 接近0,则表明趋向于“近视”性评估; 接近1则表明偏重考虑远期的利益
接近0,则表明趋向于“近视”性评估; 接近1则表明偏重考虑远期的利益
为什么要用折扣系数?

3.6 马尔可夫决策过程
虽然引入了奖励机制,但是仍然不能体现智能体的能动性,仍然缺乏与环境的交互手段,于是引入了 动作
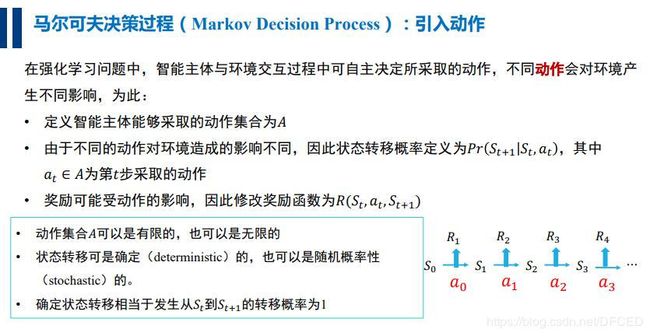
一个马尔可夫决策过程是一个元组 (S, A, {Psa}, γ, R),其中(以自主直升飞机驾驶为例):
- S是状态(states)集合,例:直升飞机的所有可能的位置和方向的集合。
- A是动作(actions)集合,例:可以控制直升飞机方向的方向集合
- Psa是状态转移概率,例:对于每个状态s∈ S,动作a∈ A,Psa是在状态空间的一个分布。之后我们会详细介绍,简而言之Psa给出了在状态s下采取动作a,我们会转移到其他状态的概率分布情况。
- γ ∈ [0, 1),称之为折现因子(discount factor)
- R:S × A → R是回报函数。有些时候回报函数也可以仅仅是S的函数。
MDP动态过程如下:我们的学习体(agent)以某状态s0开始,之后选择了一些动作a0 ∈ A并执行,之后按照Psa概率随机转移到下一个状态s1,其中s1 ∼ Ps0a0。之后再选择另一个动作a1 ∈ A并执行,状态转移后得到s2∼ Ps1a1,之后不断的继续下去。即如下图所示:
![]()