python和机器学习 第十三章 集成学习和随机森林
一、什么是集成学习
voting classifier
由多种算法共同来解决一个问题,最终进行投票得出结果
y_predict1 = log_clf.predict(X_test)
y_predict2 = svm_clf.predict(X_test)
y_predict3 = dt_clf.predict(X_test)
y_predict = np.array((y_predict1 + y_predict2 + y_predict3)>=2,dtype=int)
from sklearn.metrics import accuracy_score
accuracy_score(y_test,y_predict)scikit-learn中的Voting Classifier
Hard Voting

from sklearn.ensemble import VotingClassifier
voting_clf = VotingClassifier(estimators=[
('log_clf',LogisticRegression()),
('svm_clf',SVC()),
('dt_clf',DecisionTreeClassifier())
],voting='hard')
#少数服从多数
voting_clf.fit(X_train,y_train)
voting_clf.score(X_test,y_test)Soft Voting
要求每个模型都能估计概率 predict_proba
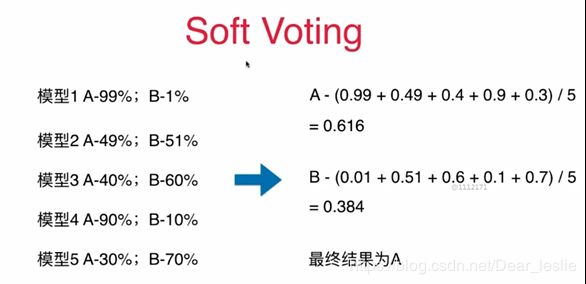
from sklearn.ensemble import VotingClassifier
voting_clf = VotingClassifier(estimators=[
('log_clf',LogisticRegression()),
('svm_clf',SVC(probability=True)),
('dt_clf',DecisionTreeClassifier(random_state=666))
],voting='soft')
#少数服从多数
voting_clf.fit(X_train,y_train)
voting_clf.score(X_test,y_test)能估计概率的模型:逻辑回归(本身就是基于概率模型)、KNN、决策树、SVM、
二、Bagging and Pasting
1、创建更多的子模型。子模型之间要有差异性
如:一共500个样本,每个子模型只看100个样本数据
2、每个子模型不需要太高的准确率。
随着子模型数量的增加,整体的准确率也会增加
3、如何创造差异性?
1、每个子模型只看样本数据的一部分
2、取样:
放回取样Bagging(更常用、没有那么强烈地依赖于随机),
不放回取样Pastingfrom sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import BaggingClassifier #500个子模型、每个子模型看100个样本数据、放回取样 bagging_clf = BaggingClassifier(DecisionTreeClassifier(), n_estimators=500,max_samples=100, bootstrap=True) bagging_clf.fit(X_train,y_train) bagging_clf.score(X_test,y_test)
三、OOB Out-of-Bag
放回取样导致一部分样本很可能没有取到;
平均约有37%的样本没有取到;
不使用测试数据集,而使用这部分没有取到的样本做测试;
bagging_clf = BaggingClassifier(DecisionTreeClassifier(),
n_estimators=500,max_samples=100,
bootstrap=True,oob_score=True
n_jobs=-1,
max_features=1,bootstrap_features=True)
bagging_clf.fit(X,y)
bagging_clf.oob_score_
Random Patches
既对特征随机取样,又对样本随机取样
参数:
n_estimators:生成多少个子模型
max_samples:每个子模型取几个样本
bootstrap:放回取样/不放回取样
oob_score:是否采用数据集
n_jobs:使用几个核来处理
max_features:每次随机取几个特征
bootstrap_features:对特征采用放回取样的方式
四、随机森林
基于决策树的采用随机取样的方式来创建诸多子模型的方式都可以称作随机森林。
scikit-learn中的随机森林
- 增加了随机性
- 决策树在节点划分上,在随机的特征子集上寻找最优划分特征
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(n_estimators=500,#创建多少棵决策树
random_state=666,
oob_score=True,
n_jobs=-1,
max_leaf_nodes=16)
rf_clf.fit(X,y)
rf_clf.oob_score_Extra-Trees
- 决策树在节点划分上,使用随机的特征和随机的阈值
- 提供了额外的随机性,抑制过拟合,但增大了bias(偏差)
- 比随机森林更快的训练速度
from sklearn.ensemble import ExtraTreesClassifier
et_clf = ExtraTreesClassifier(n_estimators=500,random_state=666,oob_score=True,n_jobs=-1,max_leaf_nodes=16,bootstrap=True)
et_clf.fit(X,y)
et_clf.oob_score_集成学习解决回归问题
from sklearn.ensemble import BaggingRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import ExtraTreesRegressor五、
- 集成多个模型
- 每个模型都在尝试增强(boosting)整体模型的效果
- 如下图,每个子模型都在弥补上一个子模型所犯的错误。上一个模型没有模拟到的点,在下一个子模型中增加该点的权重。

from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
ada_clf = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2),n_estimators=500)
ada_clf.fit(X_train,y_train)
ada_clf.score(X_test,y_test)
from sklearn.ensemble import GradientBoostingClassifier
gd_clf = GradientBoostingClassifier(max_depth=2, n_estimators=30)
gd_clf.fit(X_train,y_train)
gd_clf.score(X_test,y_test)