OpenGL4.0教程 计算着色器简介
reference:https://antongerdelan.net/opengl/compute.html
本篇文章给出了OpenGL计算着色器的实用介绍,并且我们将要开始制作一个玩具光线追踪渲染器。在阅读本教程前,你需要具备一定的OpenGL基础,并且知道如何将纹理渲染到全屏四边形上。
我之所以推迟编写OpenGL计算着色器的教程,是因为我希望先总结足够多的坑,以便可以帮助人们避免常见错误,并有足够多的经验来给出一些有用的建议。我想到我之前从未写过关于光线追踪或路径追踪的demo。光线追踪渲染是非常有趣的,也并不算特别难,是图形学中一个非常值得研究的领域。每个图形学程序都应该有自己的玩具光线追踪器。当然,你可以完全使用C语言来编写一个光线追踪器,或者使用片元着色器,但这看起来是一个很好的机会去同时尝试这两个主题,让我们都试一试。
背景
计算着色器是一个通用着色器——意味着它使用GPU做一些非渲染三角形的任务,即GPGPU编程。有一些独立的工具和库使用GPU来完成通用计算。我们常常使用Nvidia的CUDA和OpenGL来处理需要用到GPU并行浮点计算能力的任务。计算着色器常用于物理模拟、图像处理,以及其它一些较小的可并行的任务或批处理。我们期望能同时访问通用3d渲染着色器和GPGPU着色器——因为这样他们能够共享一些信息。这正是OpenGL中的计算着色器所能做到的。微软的Direct3D 11 在2009年引入了计算着色器。在2012年中,OpenGL4.3版本将计算着色器纳入标准。
概述
由于计算着色器不适用于标准渲染管线,我们需要设置不同类型的输入和输出。我们仍然可以使用uniform变量,大多数的任务也是相似的:
1.定义固定大小的工作数量来完成一系列功任务——工作组计数。OpenGL将其定义为全局工作组。它们可以是类似于需要写入的2d图像的总维度这样的数据。之后,我们需要再次将这些工作细分成更小的工作组——即局部工作组。
2.编写一个计算着色器来处理工作组内的任一任务。例如,每个像素的颜色。在着色器中,你也需要定义全局工作组将如何细分成更小的局部工作组(这样做有些奇怪,因为它并不影响我们编写着色器代码的方式)
3.设置计算着色器读或写的存储块或图像。同样也可以像往常一样使用uniforms,例如,创建一个2D的纹理。
4.调用glDispatchCompute(),OpenGL将会根据设置的工作组数量多次调用计算着色器。这些调用将尽可能并行,并且没有固定的顺序。
计划
光线追踪渲染
光线追踪和我们的光栅化图形管线工作方式不一样。我们无需空间变换、给由三角形组成的几何体填色,而是使用更接近于真实光线物理性质的方式(光学)。光线将被建模为数学上的射线,并根据数学方法来测试不同表面上的反射)。这意味着我们可以将场景中的每个物体用数学公式来表达,而不是将其细分成多个三角形,这样我们就能得到更加真实的曲线和球体。
光线追踪比光栅化渲染计算上更加昂贵,因此我们之前不将其用于实时渲染。这通常是动画电影中使用的渲染方法,因为它能产出高质量的结果。全分辨率的光线追踪动画通常需要数日完成渲染,工作室通常使用集群计算。
我们将从一个非常简单的例子开始,以后在此基础上可以非常容易地根据需要逐步添加功能。
● 我们并不直接从光源发出光线,相反,我们直接从眼睛发出光线(输出图像上的每个像素)。
● 如果假设为正交投影,那么所有光线都只会沿着视线方向直线前进。
● 对于每条光线,我们将在简单场景中对其与所有物体进行相交测试。
● 如果不考虑反射,当光线与第一个物体相交后,我们取其颜色作为像素颜色。
计算着色器GLSL变量
计算着色器有一些新的内建变量,我们可以利用它们来判断当前着色器正在处理哪个工作组。如果我们需要写入图像,并定义了一个2d的工作组,那么我们能够比较容易地知道写入的是哪个像素。
uvec3 gl_NumWorkGroups 全局工作组大小(在glDispatchCompute()中设置)
uvec3 gl_WorkGroupSize 局部工作组大小(在layout中设置)
uvec3 gl_WorkGroupID 全局工作组的当前调用位置
uvec3 gl_LocalInvocationID 局部工作组的当前调用位置
uvec3 gl_GlobalInvocationID 全局工作组的当前调用唯一下标
uint gl_LocalInvocationIndex gl_LocalInvocationID的一维下标表示
在确定像素写入图像或1维数组的哪个位置时,这些变量非常有用。
我们也可以在计算着色器之间使用shared关键字设置共享内存实现,但我们不会在这篇教程中讨论这一内容。
实现
首先创建一个简单的OpenGL程序,使用4.3或者更新的版本,然后渲染一个全屏的四边形。具体的细节将不再阐述。
创建纹理/图像
我们设置一个标准的OpenGL纹理,并在我们的计算着色器中写入。记住你传递给glTexImage2D()的内部参数格式,因为我们需要在着色器代码中设置相同的格式。我们同样需要记住纹理的维度。
// dimensions of the image
int tex_w = 512, tex_h = 512;
Gluint tex_output;
glGenTextures(1, &tex_output);
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_2D, tex_output);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WARP_T, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA32F, tex_w, tex_h, 0, GL_RGBA, GL_FLOAT, NULL);
glBindImageTexture(0, tex_output, 0, GL_FALSE, 0, GL_WRITE_ONLY, GL_RGBA32F);为了写入纹理,我们需要在着色器代码中使用图像存储函数。对于OpenGL而言,图像单位和纹理是不同的概念,所以我们需要调用glBindImageTexture()函数来创建链接。现在我们可以将其设置为“只读”模式了。
设置工作组大小
如何在计算器着色器调用间定义、划分工作组大小是由我们自己决定的。首先,我们应该检查glDispatchCompute()的总工作组最大可以为多少。我们得到x,y和z的范围:
int work_grp_cnt[3];
glGetIntegeri_v(GL_MAX_COMPUTE_WORK_GROUP_COUNT, 0, &work_grp_cnt[0]);
glGetIntegeri_v(GL_MAX_COMPUTE_WORK_GROUP_COUNT, 1, &work_grp_cnt[1]);
glGetIntegeri_v(GL_MAX_COMPUTE_WORK_GROUP_COUNT, 2, &work_grp_cnt[2]);
printf("%max global(total) work group counts x:%i y:%i z:%i\n",
work_grp_cnt[0], work_grp_cnt[1], work_grp_cnt[2]);
我们同样也检查局部工作组的最大大小(总工作组数的细分),这是在计算着色器中用layout定义的。这两个限制将协助我们划分我们的工作组:
int work_grp_size[3];
glGetIntegeri_v(GL_MAX_COMPUTE_WORK_GROUP_SIZE, 0, &work_group_size[0]);
glGetIntegeri_v(GL_MAX_COMPUTE_WORK_GROUP_SIZE, 1, &work_group_size[1]);
glGetIntegeri_v(GL_MAX_COMPUTE_WORK_GROUP_SIZE, 2, &work_group_size[2]);
printf("max local (in one shader) work group sizes x:%i y:%i z:%i\n",
work_grp_size[0], work_grp_size[1], work_grp_size[2]);我们还可以确定允许在计算着色器使用的局部工作组的最大工作组单位数,这意味着,如果我们在一个局部工作组中处理32x32规模的任务,那么它们的乘积(1024)不应超过这一值:
glGetIntegerv(GL_MAX_COMPUTE_WORK_GROUP_INVOCATIONS, &work_grp_inv);
printf("max local work group invocations %i\n", work_grp_inv);局部工作组大小的最好平衡取决于你的设置。最好让用户调整局部工作组的大小,以获得更好的性能。
我们可以从如下设置开始,之后可以进行适当调整:
● 全局工作组大小和纹理维度相同——512x512
● 局部工作组大小为1像素——1x1
● 我们不需要z轴,所以将其定义为1
编写基本的计算着色器
计算着色器看起来很像其他GLSL着色器,但有一些重要的差异。首先,需要记得在着色器的最顶部定义GLSL 4.3或者更高的版本!
#version 430
layout(local_size_x = 1, local_size_y = 1) in;
layout(rgba32f, binding = 0) uniform image2D img_output;第一个layout限定符指定了局部工作组的大小——注意如果我们希望局部工作组更大,我们不需要调整我们的着色器。我们决定从像素1开始(1x1)。如果你的工作组有不同的结构,也可以将其设置为1维或3维。
第二个layout限定符指定了我们设置的图像的内部格式。注意到我们使用了uniform image2D,而不是纹理采样器。这使得我们可以任意写入像素。
void main() {
// base pixel color for image
vec4 pixel = vec4(0, 0, 0, 1);
// get index in global work group, ie: x,y position
ivec2 pixel_coords = ivec2(gl_GlobalInvocationID.xy);
// interesting stuff happens here later
// output to a specific pixel in the image
imageStore(img_output, pixel_coords, pixel);
}我们为图像设置基本颜色(黑色),之后可以进行写入。可以通过内置变量gl_GlobalInvocationID来查找调用在工作组空间的哪个位置,然后确定我们需要修改哪个像素,并将最终颜色写入图像的这个位置。
GLuint ray_shader = glCreateShader(GL_COMPUTE_SHADER);
glShaderSource(ray_shader, 1, &the_ray_shader_string, NULL);
glCompileShader(ray_shader);
// check for compilation errors as per normal here
GLuint ray_program = glCreateProgram();
glAttachShader(ray_program, ray_shader);
glLinkProgram(ray_program);
// check for linking errors and validate program as per normal here我们只需要一个着色器就可以编译程序。当然我们还需要另外一个着色器用于将最终的纹理渲染到四边形,并且可以从新纹理中读取它。
执行着色器
我的绘制循环如下所示。注意到计算着色器的调度看起来就像是另外一个绘制pass。我设置和我的纹理维度匹配的工作组大小,并把z轴设为1:
// drawing loop
while(!glfwWindowShouldClose(window)) {
{
// launch compute shaders !
glUseProgram(ray_program);
glDispatchCompute((GLuint)tex_w, (GLuint)tex_h, 1);
}
// make sure writing to image has finished before read
glMemoryBarrier(GL_SHADER_IMAGE_ACCESS_BARRIER_BIT);
// normal drawing pass
{
glClear(GL_COLOR_BUFFER_BIT);
glUseProgram(quad_program);
glBindVertexArray(quad_vao);
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTGURE_2D, tex_output);
glDrawArrays(GL_TRIANGLE_STRIP, 0, 4);
}
glfwPollEvents();
if(GLFW_PRESS == glfwGetKey(window, GLFW_KEY_ESCAPE)) {
glfwSetWindowShouldClose(window, 1);
}
glfwSwapBuffers(window);
}为了确保在我们开始采样之前,计算着色器已经完成图像的写入,我们需要通过调用glMemoryBarrier加上图像访问位,来设置一个内存barrier。你可以使用GL_ALL_BARRIER_BITS来确保所有写入都是安全的。而在较大的项目中,应该选择更加匹配的采样纹理的barrier,以免引入任何不必要的等待。我绑定了我的新纹理,并将其绘制到全屏四边形。现在,如果编译通过,你可以修改基本颜色来测试它工作是否正常。如果正常,那么你已经掌握了计算着色器的基本工作原理。
光线追踪场景入门
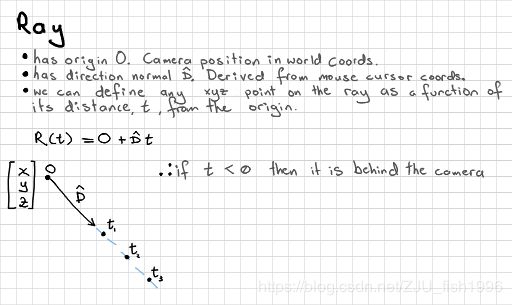 A ray expressed as origin O, direction D, and points as distances t along the ray.
A ray expressed as origin O, direction D, and points as distances t along the ray.
我们可以使用计算着色器硬编码我们的场景。首先,我们计算出光线的当前像素。一条光线由3d原点和3d方向定义。我们想要从原点延展得到所有的像素,并且可以将其标准化为x和y上-5.0到5.0的任意视野大小。我们知道在平视投影中,所有的光线都指向前方,所以我们可以认为光线为-z方向。
float max_x = 5.0;
float max_y = 5.0;
ivec2 dims = imageSize(img_output); // fetch image dimensions
float x = (float(pixel_coords.x * 2 - dims.x) / dims.x);
float y = (float(pixel_coords.y * 2 - dims.y) / dims.y);
vec3 ray_o = vec3(x * max_x, y * max_y, 0.0);
vec3 ray_d = vec3(0.0, 0.0, -1.0); // ortho我希望在场景中有一个球体,它由3d中心点和半径定义:
vec3 sphere_c = vec3(0.0, 0.0, -10.0);
float sphere_r = 1.0;我们可以在视线中心看到它,只占据部分场景,并在我们的眼前。
 The equation for determining and intersection between a ray and a sphere.
The equation for determining and intersection between a ray and a sphere.
我们可以进行射线-球体的相交测试来判断每个像素点处能否“看见”这个球体。在更复杂的场景中,你需要测试更多可能的情况——球体可能在相机后面。
vec3 omc = ray_o - sphere_c;
float b = dot(ray_d, omc);
float c = dot(omc, omc) - sphere_r * sphere_r;
float bsqmc = b * b - c;
// hit one or both sides
if(bsqmc >= 0.0) {
pixel = vec4(0.4, 0.4, 1.0, 1.0);
}其中,bsqmc是指“b squared, minus c"(b的平方减去c),下图是测试的结果:
 You should see something like this now, which is a start!
You should see something like this now, which is a start!
升级思路
 I added a few more features, a plane, and some animation to my demo.
I added a few more features, a plane, and some animation to my demo.
你可以考虑加入Phong或者更加真实的光照模型、反射、折射(可能具有最大反弹次数)、灯光、阴影、动画、透视,或者渲染图像序列输出到视频。
维护一个可交互式的光线追踪器(例如,使用用户控制的相机)将是一项优化挑战,您能否找到在实时光栅化渲染中添加光线追踪效果的方法?
分块渲染可能会提升你的渲染效率。