opengl着色器shader介绍
1. Shader
Shader其实就是一段执行在GPU上的程序,此程序使用OpenGL ES SL语言来编写。它是一个描述顶点或像素特性的简单程序。在opengles中常用的shader有两种:vertex shader和fragment shader。Geometry Shader(几何着色器)是继Vertex Shader和Fragment Shader之后,由Shader Model 4引入的新的着色器。还有一个compute Shader由Shader Model 5引入的提供通用计算能力的着色器。
不同阶段的着色器可以对应不同版本的GLSL
1.1 Vertex Shader
对于发送给GPU的每一个Vertex(顶点),都要执行一次Vertex Shader。其功能是把每个顶点在虚拟空间中的三维坐标变换为可以在屏幕上显示的二维坐标,并带有用于z-buffer的深度信息。Vertex Shader可以操作的属性有:位置、颜色、纹理坐标,但是不能创建新的顶点。
vertex shader主要完成以下工作:1).基于点操作的矩阵乘法位置变换;2).根据光照公式计算每点的color值;3).生成或者转换纹理坐标。
Vertex Shader输入数据如下:
1).Attributes:由 vertext array 提供的顶点数据,如空间位置,法向量,纹理坐标以及顶点颜色,它是针对每一个顶点的数据。属性只在顶点着色器中才有,片元着色器中没有属性。属性可以理解为针对每一个顶点的输入数据。OpenGL ES 2.0 规定了所有实现应该支持的最大属性个数不能少于 8 个。
注:Vertex Attributes 是每点的属性数据。与一个index序号绑定。外部程序可通过 glBindAttribLocation将一个attribute 名与一个index绑定起来。当然,OPENGL ES 内部会自动绑定所有attributes.外部程序只需通过 glGetAttribLocation获取指定attribute名的index。 给Attribute传值可以通过 glVertexAttribPointer函数或者glVertexAttrib4fv
2).Uniforms:uniforms保存由应用程序传递给着色器的只读常量数据。在顶点着色器中,这些数据通常是变换矩阵,光照参数,颜色等。由 uniform 修饰符修饰的变量属于全局变量,该全局性对顶点着色器与片元着色器均可见,也就是说,这两个着色器如果被连接到同一 个program Object,则它们共享同一份 uniform 全局变量集。因此如果在这两个着色器中都声明了同名的 uniform 变量,要保证这对同名变量完全相同:同名+同类型,因为它们实际是同一个变量。此外,uniform 变量存储在常量存储区,因此限制了 uniform 变量的个数,OpenGL ES 2.0 也规定了所有实现应该支持的最大顶点着色器 uniform 变量个数不能少于 128 个,最大的片元着色器 uniform 变量个数不能少于 16 个。
3).Samplers:一种特殊的 uniform,在vertex shader中是可选的,用于呈现纹理。sampler 可用于顶点着色器和片元着色器。
4).Shader program:由 main 声明的一段程序源码,描述在顶点上执行的操作:如坐标变换,计算光照公式来产生 per-vertex 颜色或计算纹理坐标。
Vertex Shader输出为:
1).Varying:varying 变量用于存储顶点着色器的输出数据,当然也存储片元着色器的输入数据,varying 变量最终会在光栅化处理阶段被线性插值。顶点着色器如果声明了 varying 变量,它必须被传递到片元着色器中才能进一步传递到下一阶段,因此顶点着色器中声明的 varying 变量都应在片元着色器中重新声明同名同类型的 varying 变量。OpenGL ES 2.0 也规定了所有实现应该支持的最大 varying 变量个数不能少于 8 个。
2).在顶点着色器阶段至少应输出位置信息-即内建变量:gl_Position,是每个点固有的Varying,表示点的空间位置。其它两个可选的变量为:gl_FrontFacing 和 gl_PointSize。
1.2 Fragment Shader
Pixel Shader(像素着色器)就是众所周知的Fragment Shader(片元着色器),它计算每个像素的颜色和其它属性。它通过应用光照值、凹凸贴图,阴影,镜面高光,半透明等处理来计算像素的颜色并输出。它也可改变像素的深度(z-buffering)或在多个渲染目标被激活的状态下输出多种颜色。一个Pixel Shader不能产生复杂的效果,因为它只在一个像素上进行操作,而不知道场景的几何形状。
Fragment Shader输入数据如下:
1).Varyings:这个在前面已经讲过了,顶点着色器阶段输出的 varying 变量在光栅化阶段被线性插值计算之后输出到片元着色器中作为它的输入,即上图中的 gl_FragCoord,gl_FrontFacing 和 gl_PointCoord。OpenGL ES 2.0 也规定了所有实现应该支持的最大 varying 变量个数不能少于 8 个。
2).Uniforms:前面也已经讲过,这里是用于片元着色器的常量,如雾化参数,纹理参数等;OpenGL ES 2.0 也规定了所有实现应该支持的最大的片元着色器 uniform 变量个数不能少于 16 个。
3).Samples:一种特殊的 uniform,用于呈现纹理。
4).Shader program:由 main 申明的一段程序源码,描述在片元上执行的操作。
FragmentShader输出为:
在顶点着色器阶段只有唯一的 varying 输出变量-即内建变量:gl_FragColor
1.3 Geometry Shader
可选着色器。Geometry Shader(几何着色器)是继Vertex Shader和Fragment Shader之后,由Shader Model 4(第四代显卡着色架构)正式引入的第三个着色器。它在Driect3D 10和OpenGL 3.2中开始引入,在OpengGL 2.0+中作为扩展使用,在OpenGL3.x中也成为核心。它的输入为:点、线和三角形;其输出为点、线带和三角形带。
在Geometry Shader里,我们处理的单元是Primative。虽然根本上都是顶点的处理,但进入vertex shader里的是一次一个的顶点,而进入Geometry Shader的是一次一批的顶点,Geometry Shader掌握着这些顶点所组成的图元的信息。Geometry Shader的处理阶段处于流水线的栅格化之前,也在视锥体裁剪和裁剪空间坐标归一化之前。虽说裁剪过程会剔除部分图元也会分割某些图元, 但就目前来说,不会有其他流水线的可编程阶段会在Geometry Shader之后提供出影响图元的性质(形式和数量)——这是Geometry Shader鉴于其位置的特殊性而拥有的一个重要特点。
Geometry Shader程序在Vertex Shader程序执行之后执行。
1.4 曲面细分着色器
可选着色器。包括曲面细分控制着色(TCS,Tessellation Control Shader)和曲面细分评估着色(TES,Tessellation Evaluation Shader)。
TCS作用于一组叫做控制点(CP,Control Points)的顶点组。控制点并不是被定义成像三角形、矩形、五边形等多边形形式,而是定义为一个几何表面,这个表面通常由多项式来定义,而且移动其中一个控制点将会影响整个表面。这个通常在一些图形软件中,用户可以通过移动一组控制点来随意改变模型表面或者曲线形状,一组控制点通常称为一个Patch。下图中的黄色表面就是通过一个16个控制点的patch来定义的: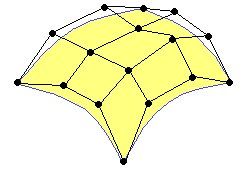
TCS输入一组patch并处理后输出一组新的patch,开发者在shader中可以对控制点进行变换,也可以删除或者新增控制点(类似于几何着色器可以修改或增删顶点)。另外,出了输出patch,着色器还会计算输出一组称作曲面细分级别(Tessellation Levels,TL)的数据。TL决定了曲面细分的细节程度,即每组patch需要生成多少三角形。上面的操作都发生在着色器中,因此开发者可以使用任意的算法来计算细分等级TL。例如,我们可以定义TL的值为3,如果光栅化三角形覆盖的像素数低于100,像素数在101-500之间TL值为7,再多的TL的值就定义为12.5了(后面会介绍TL的值如何控制曲面细分的精细程度)。另外的算法还有根据离相机的距离来计算细分程度的,都可以使得每组patch根据其自身的特点得到不同的TL值。
CS结束后进入PG固定功能着色阶段,进行真正的细分操作。这里新手会很容易疑惑,PG并没有真正的对TCS输出的patch进行细分,事实上它甚至没有访问patch的权限。相反,它根据TL的值在特定的空间中进行曲面细分,该空间可以是单位化的2维矩形或者是由三维质心坐标定义的等边三角形: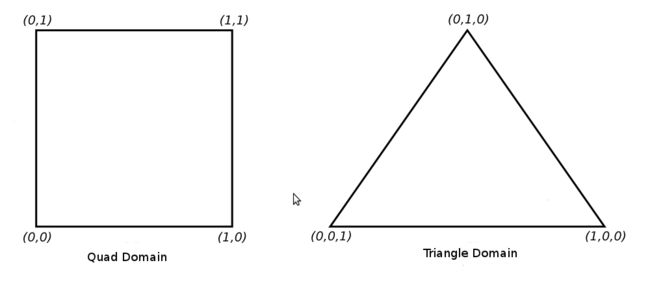
三角形的质心坐标系是一个综合三角形的三个顶点的权值来定义三角形内部位置的方法。三角形的顶点由U、V以及W三个分量确定。三角形中的某一个点的位置越靠近一个顶点,则这个顶点的权值就越大,相应的其他两个顶点的权值就会减小。如果这个点正好位于一个顶点上,那么对应这个顶点的权值为1,另外两个顶点的权值都为0。例如质心坐标系的U为(1,0,0),V为(0,1,0)、W为(0,0,1),此时三角形的中心用质心坐标系表示就是(1/3,1/3,1/3)。质心坐标系的一个有趣的特点是,如果将三角形内部一点的三个分量相加得到的结果将总是1。为了简单,之后我们将专注于三角形空间。
PG根据TL的值在三角形内部生成一系列的点,每个点都是由这个三角形的质心坐标系确定的。开发者可以选择输出的拓扑结构为点或者是三角形。如果选择的是拓扑关系为点,那么PG会直接将其传入渲染管线的下一阶段并按照点来进行光栅化。如果选择的是三角形,PG会将所有顶点连起来这样整个三角面就被细分成了多个小的三角面:
整体上TL会告诉PG三角形外边缘上的分段的数量以及三角形边到中心之间环的个数,从而进行三角形的构造。所以上面图片中的这些小三角形与我们之前看到的patch有什么关系呢?事实上这就主要取决于你想使用曲面细分技术去做什么。其中一个非常简单的用法(此教程中我们要用到的)就是跳过曲面的多项式表示,简单说就是让模型中的三角形面直接简单地映射到patch上。那种情况下组成三角形的3个顶点就成了3个控制点,而原始的三角形既是TCS的输入patch也是输出patch。我们用PG来对三角形区域进行曲面细分并且生成由质心坐标表示的“普通”三角形并对这些坐标进行线性组合(例如将他们与原始三角形的属性相乘)来对原始模型的三角形面进行细分。在下一节中我们我们将会介绍patch在几何曲面上的实际应用。要牢记PG在意的不是TCS的输入和输出patch,而是每个patch的TL值。
至此PG完成了对三角形域的曲面细分,我们还需要使用细分的结果进行进一步的处理,毕竟PG自己无法访问patch,它唯一的输出就是质心坐标和他们的连通性。进入TES着色器阶段后,TES有权限去访问TCS中输出的patch和PG生成的质心坐标。PG对每一个质心坐标都会执行TES着色器,而TES的功能就是为在PG中生成的每一个位于质心坐标系下的顶点都生成一个真正的可用的顶点。因为可以访问patch,TES可以从中获取诸如位置、法线等信息,并且通过这些信息来生成顶点。在PG对一个“小”三角形的三个质心坐标系下的顶点执行TES之后,由TES生成的这三个顶点会被传递到渲染管线的下一阶段传递并把他们当做一个完整的三角形进行光栅化。
TES与顶点着色器十分相似,总是只有一个输入(质心坐标)和一个输出(顶点)。TES在每次调用过程中只能生成一个顶点,而且它不能丢弃顶点。OpenGL中曲面细分阶段的TES着色器的主要目的就是借助于PG阶段生成的坐标来生成曲面。简单来说就是将质心坐标变换到表示曲面的多项式中并计算出最终结果。结果就是新的顶点的位置,之后这些顶点就能与普通顶点一样进行变换和投影了。如你所见,在处理几何曲面的时候,如果我们选择的TL值越高,我们获得的区域位置就越多,而且通过在TES中对他们进行计算我们得到的顶点就会更多,这样我们就能更好的表示精细的表面。在这一节中表面的计算公式我们简单的使用一个线性组合公式来代替。
在TES着色器执行之后,产生的新的顶点会被作为三角形传递到渲染管线的下一阶段。在TES之后接下来不管是GS还是光栅化阶段,都和之前的一样了。
总结一下整个渲染管线的过程:
- patch中的每一个顶点都会执行顶点着色器,每个patch中都包含顶点缓存中的多个控制点(CP)(控制点的最大值由驱动和GPU定义);
- TCS着色器以顶点处理器处理之后的数据作为输入并生成和输出patch,除此之外它也会产生TLs;
- 基于配置好的细分空间,通过获取TCS着色器中的TL(细分层级)及其输出的拓扑结构,PG会生成这个空间下的顶点位置和它们的连通性信息;
- 所有生成的位于细分空间下的位置都会经过TES着色器进行处理;
在第3步中生成的图元会沿着渲染管线继续传递,这些图元的具体数据来自于TES着色器,然后流程会继续推进到后面的GS阶段和光栅化阶段。
2.顶点着色与片元着色在编程上的差异
1).精度上的差异
着色语言定了三种级别的精度:lowp, mediump, highp。我们可以在 glsl 脚本文件的开头定义默认的精度。如下代码定义在 float 类型默认使用 highp 级别的精度
precision highp float;
在顶点着色阶段,如果没有用户自定义的默认精度,那么 int 和 float 都默认为 highp 级别;而在片元着色阶段,如果没有用户自定义的默认精度,那么就真的没有默认精度了,我们必须在每个变量前放置精度描述符。此外,OpenGL ES 2.0 标准也没有强制要求所有实现在片元阶段都支持 highp 精度的。我们可以通过查看是否定义 GL_FRAGMENT_PRECISION_HIGH 来判断具体实现是否在片元着色器阶段支持 highp 精度,从而编写出可移植的代码。当然,通常我们不需要在片元着色器阶段使用 highp 级别的精度,推荐的做法是先使用 mediump 级别的精度,只有在效果不够好的情况下再考虑 highp 精度。
2).attribute 修饰符只可用于顶点着色。这个前面已经说过了。
3).或由于精度的不同,或因为编译优化的原因,在顶点着色和片元着色阶段同样的计算可能会得到不同的结果,这会导致一些问题(z-fighting)。因此 glsl 引入了 invariant 修饰符来修饰在两个着色阶段的同一变量,确保同样的计算会得到相同的值。
OpenGL ES着色语言是两种紧密关联的语言。这些语言用来在OpenGL ES处理管线的可编程处理器创建着色器。 在本文档中,除非另外说明,一个语言功能适用于所有语言,并且通用用法将把他们当做一个语言来看待。特定语言将指出它们的目标处理器:顶点(vertext)或片元(fragment)。
任何被着色器使用的OpenGL ES状态值都会自动地被跟踪并且作用于着色器上。这个自动状态跟踪机制允许应用程序为状态管理而使用OpenGL ES状态命令,并且这些状态值自动地应用在着色器上。
2.1顶点处理器
顶点处理器是一个处理输入顶点和相关数据的可编程单元。OpenGL ES着色语言中运行这个处理器的编译单元叫做顶点着色器(vertex shader)。
一个顶点着色器同时只能处理一个顶点。
2.2片元处理器
片元处理器是一个处理片元和相关数据的可编程单元。OpenGL ES着色语言中运行这个处理器的编译单元叫做片元着色器(fragment shader)。
片元着色器不能更改片元的位置。访问相邻的片元也是不允许的。片元着色器计算的值最终用在更新帧缓冲区内存或纹理内存,这要取决于当前OpenGL ES状态以及产生片元的命令。
3.1字符集
OpenGL ES着色语言的源字符集是ASCII编码的一个子集,包含以下字符:
字符 a-z, A-Z, and下划线 ( _ ).
数字 0-9.
点 (.), 加号(+), 分割线(-), 斜线(/), 星号(*), 百分号(%),大于小于号 (< and >), 方括号 ( [ and ] ),小括号 ( ( and ) ), 大括号( { and } ), 插入符号(^), 竖线 ( | ), and(&), 波浪号(~), 等于号(=), 叹号 (!), 冒号(:), 分号(;), 逗号(,), 问好 (?).
井号 (#)用作预处理器.
空格: 空格字符,水平制表符,垂直制表符,换页符,回车符,换行符。
行连接符(\)不是语言的一部分。
总之,语言使用的这个字符集都是大小写敏感的。
没有字符和字符串类型,因此字符集中不包含引号。
也没有文件结束符。编译器通过字符串长度判断字符串结束,而不是通过特定的字符判断。
3.2源字符串
一个着色器的源是一个由字符集中字符构成的字符串的数组。着色器通过这些字符串连接而成。每个字符串可以跨越多行。单行可以包含多个字符串。
在这个版本的着色语言中,仅一个顶点着色器和一个片元着色器可以链接在一起。
3.3编译的逻辑阶段
编译处理是基于标准C++的一个子集。顶点和片元处理器的编译单元在编译的最后阶段——链接之前是分开处理的。编译的逻辑阶段如下:
1.源字符串链接
2.源字符串被转换成预处理符号序列。这些符号包括预处理数字,标示符和操作符。注释被替换成一个空格,而换行符保留。
3.预处理器执行。
4.GLSL ES语法解析转换后的符号。
5.链接uniform, verying, fixed 功能变量。
3.4预处理器
#define
#undef
#if
#ifdef
#ifndef
#else
#elif
#endif
#error
#pragma
#extension
#version
#line
defined
__LINE__ 行号
__FILE__ 文件名
__VERSION__ 版本号
GL_ES 值为1,表示使用的是ES OpenGL渲染语言
操作符的优先级和结合性:
defined操作符的用法:
defined identifier
defined ( identifier )
#error // 将诊断信息保存到着色器对象的信息日志中
#pragma //允许实现从属的编译控制。#pragma后面的符号不是预处理宏定义扩展的一部分。如果#pragma后面的符号无法识别,那么将忽略这个#pragma。可
以使用的pragma如下:
#pragma STDGL //STDGL pragma是预留的pragma,用来将来的语言修订。如果没有这个宏的实现将使用以其开头的宏定义
#pragma optimize(on)
#pragma optimize(off) //用来开启和关闭开发和调试着色器的优化操作,默认情况下,所有的着色器的优化操作都是开启的,它只能在函数定义的外部使用。
#pragma debug(on)
#pragma debug(off) //编译和注释一个着色器,并输出调试信息,因此可以用作一个调试器。只能用在函数外部,默认是关闭的。
#version number //返回当前着色语言的版本号
默认情况下,着色语言编译器必须发布编译时句法、文法和语义错误。任何扩展的行为必须被首先激活。控制编译器扩展行为的指令是#extension:
#extension extension_name : behavior
#extension all :: behavior
extension_name是扩展的名称,在这个说明文档中并没有录入。符号all意味着行为作用于编译器支持的所有扩展。behavior的值如下:require, enable, warn, disable 。
3.5注释
/* 注释一个模块 */
// 注释一行
3.6符号
着色语言是一个符号序列,可以包含以下符号:
关键字, 标示符, 整型常量, 浮点型常量, 操作数
3.7关键字
以下是着色语言已经在使用的关键字:
attribute const uniform varying
break continue do for while
if else
in out inout
float int void bool true false
lowp mediump highp precision invariant
discard return
mat2 mat3 mat4
vec2 vec3 vec4 ivec2 ivec3 ivec4 bvec2 bvec3 bvec4
sampler2D samplerCube
struct
以下是保留关键字:
asm
class union enum typedef template this packed
goto switch default
inline noinline volatile public static extern external interface flat
long short double half fixed unsigned superp
input output
hvec2 hvec3 hvec4 dvec2 dvec3 dvec4 fvec2 fvec3 fvec4
sampler1D sampler3D
sampler1DShadow sampler2DShadow
sampler2DRect sampler3DRect sampler2DRectShadow
sizeof cast
namespace using
3.8标识符
标识符用作变量名, 函数名, 结构体名和域选择器名(选择向量和矩阵的元素,类似结构体域)。标识符命名规则:
(1)不能以数字开头, 只能以字母和下划线开头
(2)不能以“gl_”开头,这是被OpenGL预留的
所有变量和函数在使用前必须声明。变量和函数名是标识符。
没有默认类型,所有变量和函数声明必须包含一个声明类型以及可选的修饰符。变量在声明的时候首先要标明类型,后边可以跟多个变量,之间用逗号隔开。很多情况下,变量在声明的时候可以使用等号“=”进行初始化。
用户定义类型可以使用struct,在结构体中所有变量类型都必须是OpenGL ES着色器语言定义的关键字。OpenGL ES着色语言是类型安全的,因此不支持隐式类型转换。
4.1 基本数据类型

4.1.1 void
函数没有返回值必须声明为void,没有默认的函数返回值。关键字void不能用于其他声明,除了空形参列表外。
4.1.2 Booleans
布尔值,只有两个取值true或false。
bool success, done = false;
4.1.3 Integers
整型主要作为编程的援助角色。在硬件级别上,真正地整数帮助有效的实现循环和数组索引,纹理单元索引。然而,着色语言没必要将整型数映射到硬件级别的整数。我们并不赞成底层硬件充分支持范围广泛的整数操作。OpenGL ES着色语言会把整数转化成浮点数进行操作。整型数可以使用十进制(非0开头数字),八进制(0开头数组)和十六进制表示(0x开头数字)。
int i, j = 42;
4.1.4 Floats
浮点型用于广泛的标量计算。可以如下定义一个浮点数:
float a, b = 1.5;
4.1.5 Vectors
OpenGL ES着色语言包含像2-,3-, 4-浮点数、整数、booleans型向量的泛型表示法。浮点型向量可以保存各种有用的图形数据,如颜色,位置,纹理坐标。
vec2 texCoord1, texCoord2;
vec3 position;
vec4 rgba;
ivec2 textureLookup;
bvec3 lessThan;
向量的初始化工作可以放在构造函数中完成。
4.1.6 Matrices
矩阵是另一个在计算机图形中非常有用的数据类型,OpenGL ES着色语言支持2*2, 3*3, 4*4浮点数矩阵。
mat2 mat2D;
mat3 optMatrix;
mat4 view, projection;
矩阵的初始化工作可以放在构造函数中完成。
4.1.7 Sampler
采样器类型(如sampler2D)实际上是纹理的不透明句柄。它们用在内建的纹理函数来指明要访问哪一个纹理。它们只能被声明为函数参数或uniforms。除了纹理查找函数参数, 数组索引, 结构体字段选择和圆括号外,取样器不允许出现在表达式中。取样器不能作为左值,也不能作为函数的out或inout参数。这些限制同样适用于包含取样器的的结构体。作为uniforms时,它们通过OpenGL ES API初始化。作为函数参数,仅能传入匹配的采样器类型。这样可以在着色器运行之前进行着色器纹理访问和OpenGL ES纹理状态的一致性检查。
4.1.8 Structures
通过结构体用户可以创建自己的数据类型。
struct light{
float intensity;
vec3 position;
}lightVar;
结构体不支持内部匿名结构体对象,也不支持内部嵌入结构体,但可以声明另一个结构体的变量。

4.1.9 Arrays
同种类型的变量可以放在一个数组中保存和管理。数组长度必须是大于0的常整型数。用负数或大于等于数组程度的索引值索引数组是不合法的。数组作为函数形参必须同时指明数组长度。仅支持一维数组,基本数据类型和结构体类型都可以作为数组元素。
float frequencies[3];
uniform vec4 lightPosition[4];
const int numLights = 2;
light lights[bumLights];
不能在着色器中声明数组的同时进行初始化。
4.2 Scopes
声明的范围决定了变量的可见性。GLSL ES使用了静态嵌套范围,允许在着色器内重定义一个变量。
4.2.1术语的定义
术语scope说明程序的一个特定的区域,在这个区域定义的变量时可见的。
4.2.2范围类型


4.2.3 重声明变量
在一个编译单元,具有相同名字的变量不能重声明在同一个范围。可以在不同的范围内声明同名的变量,但没有办法访问外层范围的同名变量。
4.2.4共享全局变量
共享全局变量是指可以在多个编译单元访问的变量。在GLSL ES中仅uniform变量可以作为全局共享变量。varying变量不能作为全局共享变量因为在片元着色器能读取它们之前必须通过光栅化传递。
共享全局变量必须有相同的名字, 存储和精度修饰符。它们必须有如下相同等价的规则:必须具有相同的精度,基本类型和尺寸。标量必须有一样的类型名称和类型定义,而且字段名称必须为相同类型。
4.3存储修饰符

本地变量只能使用存储修饰符const。
函数参数只能用const。函数返回值类型和结构体字段不要使用const。
从一个运行时着色器到下一个运行时着色器之间进行数据类型通信是不存在的。这阻止了同一个着色器在多个顶点和片元之间同时执行。
没有存储修饰符或仅仅使用const修饰符的全局变量,可能在main()执行前进行初始化。Uniforms, attributes和varyings可能没有初始化器。
4.3.1默认存储修饰符
如果在全局变量前没有修饰符,那么它们就与应用程序和其他处理器上的着色器没有关联。对于全局或本地的无修饰符变量,声明都会在其所属的那个处理器上分配内存。这个变量将提供对分配的内存的读写访问。
4.3.2常量修饰符
命名的编译时常量可以用const声明。任何使用const声明的变量在其所属的着色器中均是只读的。将变量声明为常量可以减少使用硬连线的数字常数。const可以用来修饰任何基本数据类型。通常const变量在声明的同时要进行初始化:
const vec3 zAxis = vec3 (0.0, 0.0, 1.0);
结构体字段不能使用const修饰吗,但是变量可以,并通过构造器进行初始化。包含数组的数组和结构体不能声明为常量,因为它们不能被初始化。
4.3.3 Attribute
attribute修饰符用于声明通过OpenGL ES应用程序传递到顶点着色器中的变量值。在其它任何非顶点着色器的着色器中声明attribute变量是错误的。在顶点着色器被程序使用之前,attribute变量是只读的。attribute变量的值通过OpenGL ES顶点API或者作为顶点数组的一部分被传进顶点着色器。它们传递顶点属性值到顶点着色器,并且在每一个运行的顶点着色器中都会改变。attribute修饰符只能修饰float, vec2, vec3, vec4,mat2,mat3,mat4。attribute变量不能声明为数组或结构体。如:
attribute vec4 position;
attribute vec3 normal;
attribute vec2 texCoord;
大家可能希望图形硬件有极少量的固定位置来传递顶点属性。所以,OpenGL ES为每一个非矩阵变量赋予了升级到4个浮点数值的空间,如vec4。在OpenGL ES中,可以使用的属性变量个数是有限制的,如果超过这个限制,将会引起链接错误。(声明了但没有使用的属性变量不会受到这个限制。)一个浮点数属性也要受到这个限制,所以你应该尽量将四个毫不相关的float变量打包成一个pack,以优化底层硬件的兼容性。一个mat4和使用4个vec4变量是一致的,同理,一个mat3和使用3个vec3变量是一致的,一个mat2和使用2个vec2变量是一致的。着色语言和API隐藏了到底这些空间是如何被矩阵使用的。属性变量需要被声明为全局变量。
4.3.4 Uniform
uniform修饰符用来修饰那些在整个图元被处理的过程中保持不变的全局变量。所有的uniform变量都是只读的,可以通过应用程序调用API命令初始化,或者通过OpenGL ES间接初始化。
uniform vec4 lightPosition;
uniform修饰符可以和任意基本数据类型一起使用,或者包含基本数据类型元素的数组和结构体。每种类型的着色器的uniform变量的存储数量是有限制的,如果超过这个限制,将会引起编译时或链接时错误。声明了但是没有被静态使用的uniform变量不会受到这个限制。静态使用(static use)是指着色器包含变量在预处理以后的一个引用。用户定义的uniform变量和着色器中被静态使用的内建uniform变量将共同决定有没有超出可用uniform存储范围。
当顶点着色器和片元着色器被链接到一起,它们将共享同一个名称空间。这就意味着,所有被连接到同一个可执行程序的着色器中的同名变量必须也同时具有相同的类型和精度。
4.3.4 Varying
varying变量提供了顶点着色器,片元着色器和二者通讯控制模块之间的接口。顶点着色器计算每个顶点的值(如颜色,纹理坐标等)并将它们写到varying变量中。顶点着色器也会从varying变量中读值,获取和它写入相同的值。如果从顶点着色器中读取一个尚未被写入的varying变量,将返回未定义值。
通过定义,每个顶点的varying变量以一种透视校正的方式被插入到正在渲染的图元上。如果是单采样,插值为片元中心。如果是多采样,插值可以是像素中的任何地方,包括片元中心或者其中一个片元采样。
片元着色器会读取varying变量的值,并且被读取的值将会作为插值器,作为图元中片元位置的一个功能信息。varying变量对于片元着色器来说是只读的。
在顶点和片元着色器中都有声明的同名varying变量的类型必须匹配,否则将引起链接错误。
下表总结了顶点和片元着色器匹配的规则:

术语“静态使用”意思是在预处理之后,着色器至少包含一个访问varying变量的语句,即使这个语句没有真正执行过。
varying vec3 normal;
varying修饰符只能用在float, vec2, vec3, vec4, mat2, mat3, mat4和包含这些类型元素的数组上,不能用于修饰结构体。
varying变量需要声明为全局变量。
4.4参数修饰符
函数参数修饰符有如下几种:
(1)
(2)in,作为函数的传入参数
(3)out,作为函数的传出参数
(4)inout,即作为传入参数,又作为传出参数
4.5精度和精度修饰符
4.5.1范围和精度
用于存储和展示浮点数、整数变量的范围和精度依赖于数值的源(varying,uniform,纹理查找,等等),是不是顶点或者片元着色器,还有其他一些底层实现的细节。最低存储需要通过精度修饰符来声明。典型地,精度操作必须要保留变量包含的精度存储。仅有的例外是需要大量复杂计算的内建函数,如atan(),返回值的精度低于声明的精度。
强烈建议顶点语言提供一种匹配IEEE单精度浮点数或更高精度的浮点数的浮点范围和精度。这就需要顶点语言提供浮点变量的范围至少是(-2^62, 2^62),精度至少是65536。
顶点语言必须提供一种至少16位,加上一个符号位的整数精度。
片元语言提供与顶点着色器相同的浮点数范围和精度是很有必要的,但不是必须的。这就需要片元语言提供的浮点数的范围至少是(-16384,+16384),精度至少是1024。
片元语言必须提供一种至少10为,加上一个符号位的整数精度。
4.5.2精度修饰符
任何浮点数或者整数声明前面都可以添加如下精度修饰符:

举例:
lowp float color;
varying mediump vec2 Coord;
lowp ivec2 foo(lowp mat3);
highp mat4 m;
精度修饰符声明了底层实现存储这些变量必须要使用的最小范围和精度。实现可能会使用比要求更大的范围和精度,但绝对不会比要求少。
一下是精度修饰符要求的最低范围和精度:

Floating Point Magnitude Range是非零值量级的范围。对于Floating Point Precision,relative意思是任何度量的值的精度都是相对于这个值的。对于所有的精度级别,0必须被精确的表示出来。任何不能提供着色器存储变量所声明的精度的实现都会引起一个编译或链接错误。
对于高精度和中级精度,整型范围必须可以准确地转化成相应的相同精度修饰符所表示的float型。这样的话,highp int 可以被转换成highp float, mediump int 可以被转换成mediump float,但是lowp int 不能转换成相应的lowp float。
顶点语言要求编译和链接任何lowp, mediump和highp应用都不能出现错误。
片元语言要求编译和链接任何lowp, mediump应用都不能出现错误。但是highp支持是可选的。
字符常量和布尔型没有精度修饰符.当浮点数和整数构造器不含带有精度修饰符的参数时也不需要精度修饰符。
在这段文档中,操作包含运算符,内建函数和构造器,操作数包含函数参数和构造器参数。
对于精度没有定义的常量表达式或子表达式,评估的精度结果是所有操作数中的最高精度(mediump或者highp) 。带评估的常量表达式必须是固定不变的,并且在编译期进行。
另外,对于没有精度修饰符的操作数,精度将来自于其他操作数。如果所有的操作数都没有精度,那么接着看使用计算结果的其他表达式。这个操作是递归的,直到找到一个有精度的操作符为止。如果必要,这个操作也包含赋值运算的左值,初始化声明的变量,函数形参,函数返回值.如果这样依然不能决定精度,如果组成表达式的所有操作数都没有精度,如果结果没有被赋值,也没有当作参数传进函数,那么将使用默认或更大的类型.当这种情况出现在片元着色器中,默认的精度必须被定义.
比如:
uniform highp float h1;
highp float h2 = 2.3*4.7;操作和结果都是高精度
mediump float m;
m = 3.7*h1*h2;//所有操作都是高精度
h2 = m * h1;//操作是高精度
m = h2 - h1;//操作是高精度
h2 = m + m;//加法和结果都是mediump精度
void f(highp p);
f(3.3);//3.3将作为高精度值传入函数
4.5.3默认精度修饰符
precision precision-qualifier type;
precision可以用来确定默认精度修饰符。type可以是int或float或采样器类型,precision-qualifier可以是lowp, mediump, 或者highp。任何其他类型和修饰符都会引起错误。如果type是float类型,那么该精度(precision-qualifier)将适用于所有无精度修饰符的浮点数声明(标量,向量,矩阵)。如果type是int类型,那么该精度(precision-qualifier)将适用于所有无精度修饰符的整型数声明(标量,向量)。包括全局变量声明,函数返回值声明,函数参数声明,和本地变量声明等。没有声明精度修饰符的变量将使用和它最近的precision语句中的精度。
在顶点语言中有如下预定义的全局默认精度语句:
precision highp float;
precision highp int;
precision lowp sampler2D;
precision lowp samplerCube;
在片元语言中有如下预定义的全局默认精度语句:
precision mediump int;
precision lowp sampler2D;
precision lowp samplerCube;
片元语言没有默认的浮点数精度修饰符。因此,对于浮点数,浮点数向量和矩阵变量声明,要么声明必须包含一个精度修饰符,要不默认的精度修饰符在之前已经被声明过了。
4.5.4可用的精度修饰符
内建宏GL_FRAGMENT_PRECISION_HIGH在支持highp精度的片元语言中是定义过的,但在不支持的系统中是未定义的。一旦定义以后,在顶点和片元语言中都可以使用。
#defien GL_FRAGMENT_PRECISION_HIGH 1;
4.6变异和invariant修饰符
在这部分中,变异是指在不同的着色器中的相同语句返回不同的值的可能性.举个例子,两个顶点着色器都使用相同的表达式来设置gl_Position,并且当着色器执行时传进表达式的值也是一样的.完全有可能,由于两个着色器独立的编译环境,当着色器运行时赋给gl_Position的值不一定会相同.在这个例子中,会引起多路算法的几何对齐问题.
通常,着色器之间的这种变异是允许的.如果想避免这种变异的发生,变量可以使用invariant来声明.
4.6.1invariant修饰符
为确保一个特定的输出变量是不变的,可以使用invariant修饰符.它可以修饰之前已经定义过的变量,如:
invariant gl_Position;
也可以用在变量的声明当中:
invariant varying mediump vec3 Color;
仅如下变量可以声明为invariant:
(1)顶点着色器中内建的特定输出变量
(2)顶点着色器中输出varying变量
(3)片元着色器中特定的输入变量
(4)片元着色器中的输入varying变量
(5)片元着色器中内建的输出变量
invariant后面还可以跟一个用逗号隔开的之前声明的标识符列表.
为了确保两个着色器中特定的输出变量不发生变异.还应遵循以下规则:
(1)顶点和片元着色器中的输出变量都声明为invariant
(2)相同的值必须输入到赋给输出变量的表达式或控制流的所有着色器输入变量.
(3)输出变量上的任何纹理函数调用在使用纹理格式,纹理像素值和纹理过滤时都需要设置成相同的方式.
(4)所有的输入变量都以相同的方式操作.
初始时,默认的所有输出变量被允许变异.如果想强制所有输出变量都不可变,那么在着色器所有的变量声明之前使用
#pragma STDGL invariant(all)
4.6.2着色器中的不变体
当一个值被存到一个变量中,我们通常假设它是一个常量,除非显示的去更改它的值.然而,在优化处理期间,编译期可能会重新计算一个值而不是将它存到寄存器中.因为操作的精度没有被完全指定(如,低精度的操作会被转成中等精度或高精度),重新计算的值有可能就和原来的值不一致.
在着色器中变体是允许的.如果要避免变体,可以使用invariant修饰符或invariant pragma.
precision mediump;
vec4 col;
vec2 a = ...;
........
col = texture2D(tex, a);//此时a的值假设为a1
..............
col = texture2D(tex, a);//此时a的值假设为a2,但是有可能a1不等于a2
如果强制成常量,可以使用:
#pragma STDGL invariant(all)
例子二:
vec2 m = ...;
vec2 n = ...;
vec2 a = m + n;
vec2 b = m + n;//没法保证a和b完全相等
4.6.3常量表达式的不变体
常量表达式必须要保证是不变体.一个特定的表达式在相同的还是不同的着色器中都必须有相同的结果.这包括同一个表达式出现在同一个顶点和片元着色器中,或出现在不同的顶点和片元着色器中.
如果满足以下条件,常量表达式必须得出相同的值:
(1)表达式的输入值相同
(2)执行的操作相同并且顺序也相同
(3)所有操作均以相同的精度执行
4.6.4不变体和链接装置
在顶点和片元着色器中声明的不变体varying变量必须要匹配.对于内建的特定变量,当且仅当gl_Position被声明为invariant时,gl_FragCoord才可以被声明为invariant.同样的,当且仅当gl_PositionSize被声明为invariant时,gl_PointCoord才可以被声明为invariant.将gl_FrontFacing声明为invariant是错误的.gl_FrontFacing的不变体和gl_Position的不变体是一样的.
4.7修饰顺序
当需要使用多个修饰时,它们必须遵循严格的顺序:
(1)invariant-qualifier storage-qualifier precision-qualifier
(2)storage-qualifier parameter-qualifier precision-qualifier
varying
修饰符只能用在float, vec2, vec3, vec4, mat2, mat3, mat4和包含这些类型元素的数组上,不能用于修饰结构体。
uniform
修饰符可以和任意基本数据类型一起使用,或者包含基本数据类型元素的数组和结构体。
attribute
修饰符只能修饰float, vec2, vec3, vec4,mat2,mat3,mat4。attribute变量不能声明为数组或结构体
static use
在OpenGL ES中有一个术语叫静态使用(static use),什么叫静态使用呢?
在写代码中,对于一个变量可能具有以下三种情况:
(1)不声明,不引用(No Reference),呵呵,那就没有这个变量了,如一个空语句:
;
(2)声明,但是不使用(Declared, NO used)
attribute vec4 position;
(3)声明,并使用(static use)
attribute vec4 position;
...
gl_Position = position;//静态使用,static use
因此,在官方文档中,对于静态变量的定义为:在着色器中预处理之后至少有一个语句在使用声明过的变量,哪怕这一句代码从来没有真正执行过。
着色器的预处理过程
着色器的预处理过程是指在着色代码真正开始在内存中执行之前的整个过程。那么预处理过程包含哪些工作呢?
-----------------------------------------------------------------------------------------------------------------------------------------------
(1)创建一个空着色器
(2)链接源代码字符串
(3)将源代码字符串替换空着色器中的源码
(4)编译着色器(顶点、片元着色器)
(5)创建一个空的可执行程序
(6)链接着色器
-----------------------------------------------------------------------------------------------------------------------------------------------
以上即为OpenGL ES的预处理过程
5.1操作数
OpenGL ES着色器语言包含如下操作符.
5.2数组下标
数组元素通过数组下标操作符([ ])进行访问.这是操作数组的唯一操作符,举个访问数组元素的例子:
diffuseColor += lightIntensity[3] * NdotL;
5.3函数调用
如果一个函数有返回值,那么通常这个函数调用会用在表达式中.
5.4构造器
构造器使用函数调用语法,函数名是一个基本类型的关键字或者结构体名字,在初始化器或表达式中使用.参数被用来初始化要构造的值.构造器可以将一个数据标量类型转换为另一个标量类型,或者从较小的类型转换为较大的类型,或者从较大的类型转为较小的类型.
5.4.1 转换和标量构造器
标量之间转换:
int (bool) //将布尔型值转换成整数
int (float) //将浮点数值转换成整数
float (bool) //将布尔型值转换成浮点数
float(int) //将整型值转换成浮点数
bool(int) //将整数值转换成布尔型值
bool(float) //将浮点数值转换成布尔型值
当构造器将一个float转换成int时,浮点数的小数部分将被自动舍弃掉.
当int和float转换成bool时,0和0.0被转换成false,非0值将被转换成true.当构造器将bool值转换成int或float时,false被转换成0或0.0, true被转换成1或1.0.
等价构造器,如float(float)也是合法的,但很少使用到.
如果构造器的参数不是标量,如向量,那么构造器将取其第一个元素.如float (vec3)构造器将取vec3中的第一个值.
5.4.2向量和矩阵构造器
构造器也可以用来从标量集合,向量,矩阵中创建向量和矩阵.同时可以缩短向量长度.
如果使用一个单一的标量来初始化向量,那么向量的所有值均使用该值进行初始化.如果使用一个单一的标量来初始化矩阵,那么矩阵的对角线的所有元素均会被初始化为该值,但其他元素将会被初始化为0.0
如果一个向量通过多个标量,向量或矩阵或这几种的混合来构造,那么向量的元素将按照参数列表的顺序来初始化.构造器将从参数列表中按从左到右的顺序去取参数,如果参数有多个值,那么再依次从这个参数中将值取出.构造矩阵也是类似的.矩阵元素将按照列为主要顺序来构造.构造器将依次从参数列表中取出参数值来构造矩阵的元素.如果参数列表中的值的个数超过矩阵或向量的元素个数的话,将会引起错误.
如果使用一个矩阵来构造矩阵的话,那么,参数矩阵中的元素值将放置到新矩阵的相应位置.
如果基本类型(int , float, bool)作为参数传进构造器,但是要构造的元素类型和传进来的数据类型不同,那么将会使用类型转换.
vec3(float) // initializes each component of with the float
vec4(ivec4) // makes a vec4 with component-wise conversion
vec2(float, float) // initializes a vec2 with 2 floats
ivec3(int, int, int) // initializes an ivec3 with 3 ints
bvec4(int, int, float, float) // uses 4 Boolean conversions
vec2(vec3) // drops the third component of a vec3
vec3(vec4) // drops the fourth component of a vec4
vec3(vec2, float) // vec3.x = vec2.x, vec3.y = vec2.y, vec3.z = float
vec3(float, vec2) // vec3.x = float, vec3.y = vec2.x, vec3.z = vec2.y
vec4(vec3, float)
vec4(float, vec3)
vec4(vec2, vec2)
vec4 color = vec4(0.0, 1.0, 0.0, 1.0);
vec4 rgba = vec4(1.0); // sets each component to 1.0
vec3 rgb = vec3(color); // drop the 4th component
mat2(float)
mat3(float)
mat4(float)
mat2(vec2, vec2);
mat3(vec3, vec3, vec3);
mat4(vec4, vec4, vec4, vec4);
mat2(float, float,
float, float);
mat3(float, float, float,
float, float, float,
float, float, float);
mat4(float, float, float, float,
float, float, float, float,
float, float, float, float,
float, float, float, float);
5.4.3结构体构造器
一旦结构体被定义,并给了一个类型名,那么和其同名的构造器就可以使用了.
struct light {
float intensity;
vec3 position;
};
light lightVar = light(3.0, vec3(1.0, 2.0, 3.0));
传进构造器的参数必须和结构体里面声明的具有相同的顺序和类型.
结构体构造器可以用于初始化器或者用在表达式中.
5.5向量组件
向量中每个组件的名称都使用一个单独的字符来表示.常用的位置,颜色,或者纹理坐标向量的组件直接和几个便利的数字相关联.访问向量中的组件可以使用向量名(.)组件名的方式.
支持的组件名称如下:
组件名称x,r,s在向量中是表示同一个组件的同义词.
注意,为了不和颜色向量中的r(红色)混淆,纹理向量中的第三个组件名称使用了p.
访问超出向量个数的组件会引起错误:
vec2 pos;
pos.x // is legal
pos.z // is illegal
组件选择语法可以一次选择多个组件:
vec4 v4;
v4.rgba; // is a vec4 and the same as just using v4,
v4.rgb; // is a vec3,
v4.b; // is a float,
v4.xy; // is a vec2,
v4.xgba; // is illegal - the component names do not come from
// the same set.
通过移动和替换组件可以产生不同的向量:
vec4 pos = vec4(1.0, 2.0, 3.0, 4.0);
vec4 swiz= pos.wzyx; // swiz = (4.0, 3.0, 2.0, 1.0)
vec4 dup = pos.xxyy; // dup = (1.0, 1.0, 2.0, 2.0)
组件组符号可以出现在左值中,也可以出现在右值中.
vec4 pos = vec4(1.0, 2.0, 3.0, 4.0);
pos.xw = vec2(5.0, 6.0); // pos = (5.0, 2.0, 3.0, 6.0)
pos.wx = vec2(7.0, 8.0); // pos = (8.0, 2.0, 3.0, 7.0)
pos.xx = vec2(3.0, 4.0); // illegal - 'x' used twice
pos.xy = vec3(1.0, 2.0, 3.0); // illegal - mismatch between vec2 and vec3
数组下标索引语法同样适用于向量.所以:
vec4 pos;
中pos[2]表示第三个元素,与使用pos.z是等价的。
5.6 矩阵组件
访问矩阵组件可以使用数组的下标索引语法。使用一维数组访问矩阵表示你要访问矩阵中对应的那一列组件,即返回相应列所有元素的向量。二位数组才是具体的访问某一个组件。由于矩阵是列优先的,因此,使用数组来索引矩阵元素的时候,数组的第一维表示列,第二维表示行。
mat4 m;
m[1] = vec4(2.0); // sets the second column to all 2.0
m[0][0] = 1.0; // sets the upper left element to 1.0
m[2][3] = 2.0; // sets the 4th element of the third column to 2.0
如果下标越界,将引起编译时错误。
5.7结构体和字段
结构体字段的访问也是要用到点操作符的(.)。
可用于结构体的操作有如下几种:
等于和赋值运算符只有两个操作数类型是同一个结构体时才有意义。即使两个结构体的名称和字段一模一样,他们也不是相等的。包含矩阵和采样器类型的结构体的赋值和等于操作是未定义的。
Struct S {int x;};
S a;
{
struct S {int x;};
S b;
a = b; // error: type mismatch
}
5.8 赋值
赋值表达式结构如下:
lvalue-expression = expression;
lvalue-expression 表示左值表达式,通过赋值运算符“=”将expression表达式的值赋给lvalue-expression;表达式和左值拥有相同的类型才会编译。所有的类型转换都必须显示地通过构造器来指定。左值必须是可写的。
支持 += 、 -= 、 *= 、 /=等运算符。
保留 %= 、<<= 、 >>=、 |=和^=等运算符以便后面修订用。
读取一个未被写入或初始化的变量是合法的,但其值是未定义的。
5.9 表达式
在着色语言中表达式由以下方式创建:
- bool. int, float型常量,所有向量类型,所有矩阵类型。
- 所有类型的构造器
- 所有类型的变量名,除了不跟下标的数组名外
- 带下标的数组名
- 不带下标的数组名。一般只用在函数参数传递中。
- 带返回值的函数调用。
- 组件字段选择器和数组下标返回值。
- 括号表达式。任何表达式都可以是括号表达式。
- 二进制运算符 + 、 - 、 * 、 /
- %保留修订用
- 一元负操作符(-),自加(++),自减(--)操作符。
- 比较运算符。大于(>),小于(<),大于等于(>=),小于等于(<=)。如果想比较向量,使用内建函数lessThan,lessThanEqual,greaterThan,greaterThanEqual。
- 等于(=)和不等于(!=)运算符。除了数组,包含数组的结构体,采样器,包含采样器的结构体外其他类型都可以使用。如果想让组件按位比较,使用内建的函数equal和notEqual。
- 逻辑二进制运算符(&&, ||, ^)。
- 逻辑一元运算符非(!)
- 逗号运算符。逗号运算符返回表达式序列中最后一个的结果。
- 三元选择运算符(?:)
- 运算符(&,|,^,~,>>,<<)保留修订用。
5.10 常量表达式
常量表达式可以是以下几种:
- 字符值(如5或true)
- 全局或本地使用const修饰的变量,函数参数除外
- 返回常量数组,常量矩阵的某个元素或常量结构体的某个字段
- 参数都是常量表达式的结构体
- 所有参数都是常量表达式的内建函数类型,除了纹理查找函数外。
以下不能用在常量表达式:
- 用户自定义的函数
- uniform,attribute,varying变量
数组变量不能使常量表达式,因为常量必须在声明时进行初始化,但是数组没有初始化机制
5.11 向量和矩阵操作
对矩阵和向量操作就是对向量和矩阵的每一个单独组建进行操作。举个例子
(1)向量和一个浮点数或整数相加,结果是向量的每一个元素都和该浮点数相加
vec3 v, u;
float f;
v = u + f;
等价于:
v.x = u.x + f;
v.y = u.y + f;
v.z = u.z + f;
(2)向量和向量相加,结果是两个向量的对应位置的组件分别相加
vec3 v, u, w;
w = v + u;
等价于:
w.x = v.x + u.x;
w.y = v.y + u.y;
w.z = v.z + u.z;
这对于大部分操作符和所有的整数、浮点数向量和矩阵类型都是类似的操作。例外是矩阵和向量的乘法,矩阵和矩阵的乘法。如:
(3)向量乘以矩阵,结果是
vec3 v, u;
mat3 m;
u = v * m;
等价于:
u.x = dot(v, m[0]); // m[0] is the left column of m
u.y = dot(v, m[1]); // dot(a,b) is the inner (dot) product of a and b
u.z = dot(v, m[2]);
(4)矩阵乘以向量,结果是矩阵的各行和向量相乘
u = m * v;
等价于:
u.x = m[0].x * v.x + m[1].x * v.y + m[2].x * v.z;
u.y = m[0].y * v.x + m[1].y * v.y + m[2].y * v.z;
u.z = m[0].z * v.x + m[1].z * v.y + m[2].z * v.z;
(5)矩阵乘以矩阵,前一个矩阵的行乘以后一个矩阵的列
mat m, n, r;
r = m * n;
等价于:
r[0].x = m[0].x * n[0].x + m[1].x * n[0].y + m[2].x * n[0].z;
r[1].x = m[0].x * n[1].x + m[1].x * n[1].y + m[2].x * n[1].z;
r[2].x = m[0].x * n[2].x + m[1].x * n[2].y + m[2].x * n[2].z;
r[0].y = m[0].y * n[0].x + m[1].y * n[0].y + m[2].y * n[0].z;
r[1].y = m[0].y * n[1].x + m[1].y * n[1].y + m[2].y * n[1].z;
r[2].y = m[0].y * n[2].x + m[1].y * n[2].y + m[2].y * n[2].z;
r[0].z = m[0].z * n[0].x + m[1].z * n[0].y + m[2].z * n[0].z;
r[1].z = m[0].z * n[1].x + m[1].z * n[1].y + m[2].z * n[1].z;
r[2].z = m[0].z * n[2].x + m[1].z * n[2].y + m[2].z * n[2].z;
从2.0开始,opengl es不再提供glRotate()等函数,因此MVP矩阵需要我们自己计算,并赋值给GLSL。
1) 先来看下opengl所用的矩阵的基本知识:
Opengl 使用的是列矩阵,即顶点向量等是用列向量的齐次坐标表示的。另外其矩阵存储方式是“列主序(column-major order)/列优先”线性代数意义的同一个矩阵,在d3d 和 opengl 中却有不同的存储顺序

矩阵x顶点(记住顺序!!矩阵左乘顶点,顶点用列向量表示)= 变换后的顶点

这里有粗略的介绍
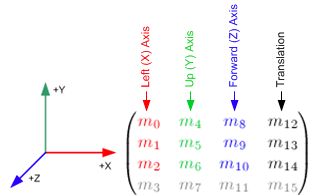
下面来分析一下:
如上图,3个元素集(m0, m1, m2),(m4, m5, m6)和(m8, m9, m10) 是用作欧拉变换和仿射变换,例如1.0中提供的函数glRotate(),缩放glScalef().
注意这三个元素集实际上指得是3个正交坐标系:
(m0, m1, m2): +X 轴,向左的向量(left vector)(估计是相对屏幕自己),默认为(1,0,0)
(m4, m5, m6) : +Y轴,向上的向量(up vector),默认为(0,1,0)
(m8, m9, m10): +Z轴,向前的向量,默认为(0,0,1).
因为使用的是左乘,所以变换的顺序是相对于乘法是逆向的,即最后的变换出现在矩阵相乘之前,最先的变换在最后出现。:
![]()
TransformedVector = TranslationMatrix * RotationMatrix * ScaleMatrix * OriginalVector;
这行代码最先执行缩放,接着旋转,最后才是平移。
用GLSL表示:
mat4 transform = projectionMat* viewMat * modeMat;
vec4 out_vec = transform * in_vec;
因为model矩阵变换比较简单。所以在这里不再讲解,主要讲解View(又叫相机)矩阵和投影(projection)矩阵的构建
流水线概述
下图描述了一个简化的图形处理流水线,虽然简略但仍然可以展示着色器编程(shader programming)的一些重要概念。
一个固定流水线包括如下功能:
顶点变换(Vertex Transformation)
这里一个顶点是一个信息集合,包括空间中的位置、顶点的颜色、法线、纹理坐标等。这一阶段的输入是独立的顶点信息,固定功能流水线在这一阶段通常进行如下工作:
·顶点位置变换
·为每个顶点计算光照
·纹理坐标的生成与变换
图元组合和光栅化(Primitive Assembly and Rasterization)
此阶段的输入是变换后的顶点和连接信息(connectivity information)。连接信息告诉流水线顶点如何组成图元(三角形、四边形等)。此阶段还负责视景体(view frustum)裁剪和背面剔除。
光栅化决定了片断(fragment),以及图元的像素位置。这里的片断是指一块数据,用来更新帧缓存(frame buffer)中特定位置的一个像素。一个片断除了包含颜色,还有法线和纹理坐标等属性,这些信息用来计算新的像素颜色值。
本阶段的输出包括:
·帧缓存中片断的位置
·在顶点变换阶段计算出的信息对每个片断的插值
这个阶段利用在顶点变换阶段算出的数据,结合连接信息计算出片断的数据。例如,每个顶点包含一个变换后的位置,当它们组成图元时,就可以用来计算图元的片断位置。另一个例子是使用颜色,如果多边形的每个顶点都有自己的颜色值,那么多边形内部片断的颜色值就是各个顶点颜色插值得到的。
片断纹理化和色彩化(Fragment Texturing and Coloring)
此阶段的输入是经过插值的片断信息。在前一阶段已经通过插值计算了纹理坐标和一个颜色值,这个颜色在本阶段可以用来和纹理元素进行组合。此外,这一阶段还可以进行雾化处理。通常最后的输出是片断的颜色值以及深度信息。
光栅操作(Raster Operations)
此阶段的输入:
·像素位置
·片断深度和颜色值
在这个阶段对片断进行一系列的测试,包括:
·剪切测试(scissor test)
·Alpha测试
·模版测试
·深度测试
如果测试成功,则根据当前的混合模式(blend mode)用片断信息来更新像素值。注意混合只能在此阶段进行,因为片断纹理化和颜色化阶段不能访问帧缓存。帧缓存只能在此阶段访问。
一幅图总结固定功能流水线(Visual Summary of the Fixed Functionality)
下图直观地总结了上述流水线的各个阶段:
取代固定的功能(Replacing Fixed Functionality)
现在的显卡允许程序员自己编程实现上述流水线中的两个阶段:
·顶点shader实现顶点变换阶段的功能
·片断shader替代片断纹理化和色彩化的功能
顶点处理器
顶点处理器用来运行顶点shader(着色程序)。顶点shader的输入是顶点数据,即位置、颜色、法线等。
下面的OpenGL程序发送数据到顶点处理器,每个顶点中包含一个颜色信息和一个位置信息。
glBegin(...);
glColor3f(0.2,0.4,0.6);
glVertex3f(-1.0,1.0,2.0);
glColor3f(0.2,0.4,0.8);
glVertex3f(1.0,-1.0,2.0);
glEnd();
一个顶点shader可以编写代码实现如下功能:
·使用模型视图矩阵以及投影矩阵进行顶点变换
·法线变换及归一化
·纹理坐标生成和变换
·逐顶点或逐像素光照计算
·颜色计算
不一定要完成上面的所有操作,例如你的程序可能不使用光照。但是,一旦你使用了顶点shader,顶点处理器的所有固定功能都将被替换。所以你不能只编写法线变换的shader而指望固定功能帮你完成纹理坐标生成。
从上一节已经知道,顶点处理器并不知道连接信息,因此这里不能执行拓扑信息有关的操作。比如顶点处理器不能进行背面剔除,它只是操作顶点而不是面。
顶点shader至少需要一个变量:gl_Position,通常要用模型视图矩阵以及投影矩阵进行变换。顶点处理器可以访问OpenGL状态,所以可以用来处理材质和光照。最新的设备还可以访问纹理。
片断处理器
片断处理器可以运行片断shader,这个单元可以进行如下操作:
·逐像素计算颜色和纹理坐标
·应用纹理
·雾化计算
·如果需要逐像素光照,可以用来计算法线
片断处理器的输入是顶点坐标、颜色、法线等计算插值得到的结果。在顶点shader中对每个顶点的属性值进行了计算,现在将对图元中的每个片断进行处理,因此需要插值的结果。
如同顶点处理器一样,当你编写片断shader后,所有固定功能将被取代,所以不能使用片断shader对片断材质化,同时用固定功能进行雾化。程序员必须编写程序实现需要的所有效果。
片断处理器只对每个片断独立进行操作,并不知道相邻片断的内容。类似顶点shader,我们必须访问OpenGL状态,才可能知道应用程序中设置的雾颜色等内容。
一个片断shader有两种输出:
·抛弃片断内容,什么也不输出
·计算片断的最终颜色gl_FragColor,当要渲染到多个目标时计算gl_FragData。
还可以写入深度信息,但上一阶段已经算过了,所以没有必要。
需要强调的是片断shader不能访问帧缓存,所以混合(blend)这样的操作只能发生在这之后。