三角测量与PNP
一、三角测量

在深度估计中,双目视觉可以通过极限约束找到对应的三维点信息,在雷达中可以通过TOF找到深度信息,那么在单目视觉中,如何获得深度信息呢?
这就需要三角测量。
> 三角测量在三角学与几何学上是一借由测量目标点与固定基准线的已知端点的角度,测量目标距离的方法。而不是直接测量特定位置的距离(三边量测法)。当已知一个边长及两个观测角度时,观测目标点可以被标定为一个三角形的第三个点。
三角量测亦可意指为超大三角形系统的精确测量,称作三角量测网络。这源自于威理博·司乃耳于1615-17的作品,他展现出一个点如何能够从附属于三个已知点的角度来被定位,是在新的一未知点上量测而不是在先前固定的点上,这样的问题叫做重新区块化。调查误差可被最小化,当大量三角形已建立在最大适当的规模。借此参考方法,所有在三角内的点皆可被准确地定位。直至1980年代全球卫星导航系统崛起之前,此三角量测方法被用来准确化大规模的土地测量。
和极限约束类似,三角测量的平面也是有极限约束的。
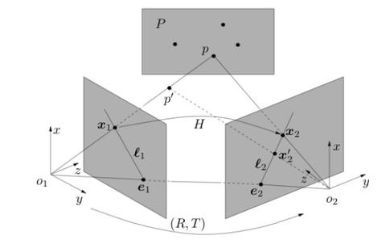
由于噪声的影响,这会导致两个视角的交线不是一个点P,往往有一些误差,这么处理这种无法相交的情况呢?
这就需要最小二乘估计了。
我们知道了匹配的特征点、知道了旋转矩阵和平移矩阵,那么计算深度就显得轻而易举了,用三角法即可。
二、三角测量的代码
#include detector = FeatureDetector::create ( "ORB" );
// Ptr descriptor = DescriptorExtractor::create ( "ORB" );
Ptr<descriptormatcher> matcher = DescriptorMatcher::create("BruteForce-Hamming");
//-- 第一步:检测 Oriented FAST 角点位置
detector->detect(img_1, keypoints_1);
detector->detect(img_2, keypoints_2);
//-- 第二步:根据角点位置计算 BRIEF 描述子
descriptor->compute(img_1, keypoints_1, descriptors_1);
descriptor->compute(img_2, keypoints_2, descriptors_2);
//-- 第三步:对两幅图像中的BRIEF描述子进行匹配,使用 Hamming 距离
vector<dmatch> match;
// BFMatcher matcher ( NORM_HAMMING );
matcher->match(descriptors_1, descriptors_2, match);
//-- 第四步:匹配点对筛选
double min_dist = 10000, max_dist = 0;
//找出所有匹配之间的最小距离和最大距离, 即是最相似的和最不相似的两组点之间的距离
for (int i = 0; i < descriptors_1.rows; i++) {
double dist = match[i].distance;
if (dist < min_dist) min_dist = dist;
if (dist > max_dist) max_dist = dist;
}
printf("-- Max dist : %f \n", max_dist);
printf("-- Min dist : %f \n", min_dist);
//当描述子之间的距离大于两倍的最小距离时,即认为匹配有误.但有时候最小距离会非常小,设置一个经验值30作为下限.
for (int i = 0; i < descriptors_1.rows; i++) {
if (match[i].distance <= max(2 * min_dist, 30.0)) {
matches.push_back(match[i]);
}
}
}
void pose_estimation_2d2d(
const std::vector<keypoint> &keypoints_1,
const std::vector<keypoint> &keypoints_2,
const std::vector<dmatch> &matches,
Mat &R, Mat &t) {
// 相机内参,TUM Freiburg2
Mat K = (Mat_<double>(3, 3) << 520.9, 0, 325.1, 0, 521.0, 249.7, 0, 0, 1);
//-- 把匹配点转换为vector的形式
vector<point2f> points1;
vector<point2f> points2;
for (int i = 0; i < (int) matches.size(); i++) {
points1.push_back(keypoints_1[matches[i].queryIdx].pt);
points2.push_back(keypoints_2[matches[i].trainIdx].pt);
}
//-- 计算本质矩阵
Point2d principal_point(325.1, 249.7); //相机主点, TUM dataset标定值
int focal_length = 521; //相机焦距, TUM dataset标定值
Mat essential_matrix;
essential_matrix = findEssentialMat(points1, points2, focal_length, principal_point);
//-- 从本质矩阵中恢复旋转和平移信息.
recoverPose(essential_matrix, points1, points2, R, t, focal_length, principal_point);
}
void triangulation(
const vector<keypoint> &keypoint_1,
const vector<keypoint> &keypoint_2,
const std::vector<dmatch> &matches,
const Mat &R, const Mat &t,
vector<point3d> &points) {
Mat T1 = (Mat_<float>(3, 4) <<
1, 0, 0, 0,
0, 1, 0, 0,
0, 0, 1, 0);
Mat T2 = (Mat_<float>(3, 4) <<
R.at<double>(0, 0), R.at<double>(0, 1), R.at<double>(0, 2), t.at<double>(0, 0),
R.at<double>(1, 0), R.at<double>(1, 1), R.at<double>(1, 2), t.at<double>(1, 0),
R.at<double>(2, 0), R.at<double>(2, 1), R.at<double>(2, 2), t.at<double>(2, 0)
);
Mat K = (Mat_<double>(3, 3) << 520.9, 0, 325.1, 0, 521.0, 249.7, 0, 0, 1);
vector<point2f> pts_1, pts_2;
for (DMatch m:matches) {
// 将像素坐标转换至相机坐标
pts_1.push_back(pixel2cam(keypoint_1[m.queryIdx].pt, K));
pts_2.push_back(pixel2cam(keypoint_2[m.trainIdx].pt, K));
}
Mat pts_4d;
cv::triangulatePoints(T1, T2, pts_1, pts_2, pts_4d);
// 转换成非齐次坐标
for (int i = 0; i < pts_4d.cols; i++) {
Mat x = pts_4d.col(i);
x /= x.at<float>(3, 0); // 归一化
Point3d p(
x.at<float>(0, 0),
x.at<float>(1, 0),
x.at<float>(2, 0)
);
points.push_back(p);
}
}
Point2f pixel2cam(const Point2d &p, const Mat &K) {
return Point2f
(
(p.x - K.at<double>(0, 2)) / K.at<double>(0, 0),
(p.y - K.at<double>(1, 2)) / K.at<double>(1, 1)
);
}
三、三角法总结

三角法的使用有个条件,就是必须有平移,或者是平移不能为0,也就是说,旋转无法获得三角测量值。
那么如何提高三角化的精度呢?
有2种办法。一种就是提高特征点的匹配与提取精度。第二种就是增加平移个距离。这两种办法都有相应的优缺点。
四、PNP

我们已经介绍了平面的匹配方法,就是使用8点法,那么,如果我们知道在空间中的一个确定的三维点坐标呢,如何求解相应的相机运动呢?
在已经知道的三维点的情况下,只需要三个点就可以了。那么如何获取三维点呢?可以通过深度相机或者双目相机得到三维点,在三维点已知的情况下,就可以使用PNP求解。
> PNP 相机位姿估计pose estimation就是通过几个已知坐标(世界坐标)的特征点,结合他们在相机照片中的成像(像素坐标),求解出相机所在的世界坐标以及旋转角度, 用旋转矩阵®和平移矩阵(t)表示. PnP, which is short for perspective n point就是其中的一种2D-3D解决上述问题的算法, 也就是说, 这个算法的输入是一组点的三维世界坐标和二维像素坐标,输出是相机的旋转矩阵®和平移矩阵(t).
求解PNP的方法有很多,简而言之就是求解3D-2D的问题,常用的方法有:直接线性变换、EPNP、光束平差法(BA)等等。
五、BA
光束平差法(Bundle Adjustment)的主要思想是通过最小化重投影误差,求解位姿。
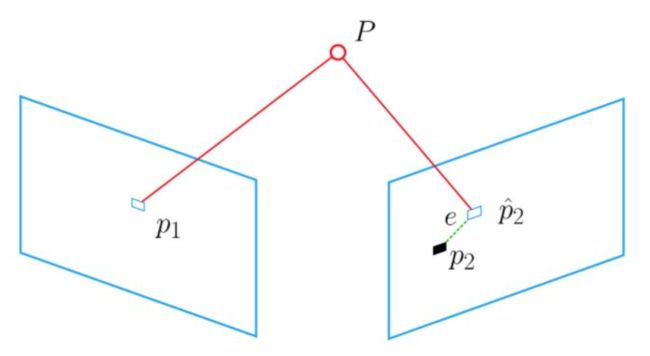
就是讲我们观察到的三维点的位置对我们推算得到的三维点的位置,进行做差优化,可以使用最小二乘估计的方法。
> 对场景中任意三维点P,由从每个视图所对应的的摄像机的光心发射出来并经过图像中P对应的像素后的光线,都将交于P这一点,对于所有三维点,则形成相当多的光束(bundle);实际过程中由于噪声等存在,每条光线几乎不可能汇聚与一点,因此在求解过程中,需要不断对待求信息进行调整(adjustment),来使得最终光线能交于点P。
#include detector = FeatureDetector::create ( "ORB" );
// Ptr descriptor = DescriptorExtractor::create ( "ORB" );
Ptr<descriptormatcher> matcher = DescriptorMatcher::create("BruteForce-Hamming");
//-- 第一步:检测 Oriented FAST 角点位置
detector->detect(img_1, keypoints_1);
detector->detect(img_2, keypoints_2);
//-- 第二步:根据角点位置计算 BRIEF 描述子
descriptor->compute(img_1, keypoints_1, descriptors_1);
descriptor->compute(img_2, keypoints_2, descriptors_2);
//-- 第三步:对两幅图像中的BRIEF描述子进行匹配,使用 Hamming 距离
vector<dmatch> match;
// BFMatcher matcher ( NORM_HAMMING );
matcher->match(descriptors_1, descriptors_2, match);
//-- 第四步:匹配点对筛选
double min_dist = 10000, max_dist = 0;
//找出所有匹配之间的最小距离和最大距离, 即是最相似的和最不相似的两组点之间的距离
for (int i = 0; i < descriptors_1.rows; i++) {
double dist = match[i].distance;
if (dist < min_dist) min_dist = dist;
if (dist > max_dist) max_dist = dist;
}
printf("-- Max dist : %f \n", max_dist);
printf("-- Min dist : %f \n", min_dist);
//当描述子之间的距离大于两倍的最小距离时,即认为匹配有误.但有时候最小距离会非常小,设置一个经验值30作为下限.
for (int i = 0; i < descriptors_1.rows; i++) {
if (match[i].distance <= max(2 * min_dist, 30.0)) {
matches.push_back(match[i]);
}
}
}
Point2d pixel2cam(const Point2d &p, const Mat &K) {
return Point2d
(
(p.x - K.at<double>(0, 2)) / K.at<double>(0, 0),
(p.y - K.at<double>(1, 2)) / K.at<double>(1, 1)
);
}
void bundleAdjustmentGaussNewton(
const VecVector3d &points_3d,
const VecVector2d &points_2d,
const Mat &K,
Sophus::SE3d &pose) {
typedef Eigen::Matrix<double, 6,="" 1=""> Vector6d;
const int iterations = 10;
double cost = 0, lastCost = 0;
double fx = K.at<double>(0, 0);
double fy = K.at<double>(1, 1);
double cx = K.at<double>(0, 2);
double cy = K.at<double>(1, 2);
for (int iter = 0; iter < iterations; iter++) {
Eigen::Matrix<double, 6,="" 6=""> H = Eigen::Matrix<double, 6,="" 6="">::Zero();
Vector6d b = Vector6d::Zero();
cost = 0;
// compute cost
for (int i = 0; i < points_3d.size(); i++) {
Eigen::Vector3d pc = pose * points_3d[i];
double inv_z = 1.0 / pc[2];
double inv_z2 = inv_z * inv_z;
Eigen::Vector2d proj(fx * pc[0] / pc[2] + cx, fy * pc[1] / pc[2] + cy);
Eigen::Vector2d e = points_2d[i] - proj;
cost += e.squaredNorm();
Eigen::Matrix<double, 2,="" 6=""> J;
J << -fx * inv_z,
0,
fx * pc[0] * inv_z2,
fx * pc[0] * pc[1] * inv_z2,
-fx - fx * pc[0] * pc[0] * inv_z2,
fx * pc[1] * inv_z,
0,
-fy * inv_z,
fy * pc[1] * inv_z2,
fy + fy * pc[1] * pc[1] * inv_z2,
-fy * pc[0] * pc[1] * inv_z2,
-fy * pc[0] * inv_z;
H += J.transpose() * J;
b += -J.transpose() * e;
}
Vector6d dx;
dx = H.ldlt().solve(b);
if (isnan(dx[0])) {
cout << "result is nan!" << endl;
break;
}
if (iter > 0 && cost >= lastCost) {
// cost increase, update is not good
cout << "cost: " << cost << ", last cost: " << lastCost << endl;
break;
}
// precision(12) << cost << endl;
if (dx.norm() < 1e-6) {
// converge
break;
}
}
cout << "pose by g-n: \n" << pose.matrix() << endl;
}
/// vertex and edges used in g2o ba
class VertexPose : public g2o::BaseVertex<6, Sophus::SE3d> {
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW;
virtual void setToOriginImpl() override {
_estimate = Sophus::SE3d();
}
/// left multiplication on SE3
virtual void oplusImpl(const double *update) override {
Eigen::Matrix<double, 6,="" 1=""> update_eigen;
update_eigen << update[0], update[1], update[2], update[3], update[4], update[5];
_estimate = Sophus::SE3d::exp(update_eigen) * _estimate;
}
virtual bool read(istream &in) override {}
virtual bool write(ostream &out) const override {}
};
class EdgeProjection : public g2o::BaseUnaryEdge<2, Eigen::Vector2d, VertexPose> {
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW;
EdgeProjection(const Eigen::Vector3d &pos, const Eigen::Matrix3d &K) : _pos3d(pos), _K(K) {}
virtual void computeError() override {
const VertexPose *v = static_cast<vertexpose *=""> (_vertices[0]);
Sophus::SE3d T = v->estimate();
Eigen::Vector3d pos_pixel = _K * (T * _pos3d);
pos_pixel /= pos_pixel[2];
_error = _measurement - pos_pixel.head<2>();
}
virtual void linearizeOplus() override {
const VertexPose *v = static_cast<vertexpose *=""> (_vertices[0]);
Sophus::SE3d T = v->estimate();
Eigen::Vector3d pos_cam = T * _pos3d;
double fx = _K(0, 0);
double fy = _K(1, 1);
double cx = _K(0, 2);
double cy = _K(1, 2);
double X = pos_cam[0];
double Y = pos_cam[1];
double Z = pos_cam[2];
double Z2 = Z * Z;
_jacobianOplusXi
<< -fx / Z, 0, fx * X / Z2, fx * X * Y / Z2, -fx - fx * X * X / Z2, fx * Y / Z,
0, -fy / Z, fy * Y / (Z * Z), fy + fy * Y * Y / Z2, -fy * X * Y / Z2, -fy * X / Z;
}
virtual bool read(istream &in) override {}
virtual bool write(ostream &out) const override {}
private:
Eigen::Vector3d _pos3d;
Eigen::Matrix3d _K;
};
void bundleAdjustmentG2O(
const VecVector3d &points_3d,
const VecVector2d &points_2d,
const Mat &K,
Sophus::SE3d &pose) {
// 构建图优化,先设定g2o
typedef g2o::BlockSolver<g2o::blocksolvertraits<6, 3="">> BlockSolverType; // pose is 6, landmark is 3
typedef g2o::LinearSolverDense<blocksolvertype::posematrixtype> LinearSolverType; // 线性求解器类型
// 梯度下降方法,可以从GN, LM, DogLeg 中选
auto solver = new g2o::OptimizationAlgorithmGaussNewton(
g2o::make_unique<blocksolvertype>(g2o::make_unique<linearsolvertype>()));
g2o::SparseOptimizer optimizer; // 图模型
optimizer.setAlgorithm(solver); // 设置求解器
optimizer.setVerbose(true); // 打开调试输出
// vertex
VertexPose *vertex_pose = new VertexPose(); // camera vertex_pose
vertex_pose->setId(0);
vertex_pose->setEstimate(Sophus::SE3d());
optimizer.addVertex(vertex_pose);
// K
Eigen::Matrix3d K_eigen;
K_eigen <<
K.at<double>(0, 0), K.at<double>(0, 1), K.at<double>(0, 2),
K.at<double>(1, 0), K.at<double>(1, 1), K.at<double>(1, 2),
K.at<double>(2, 0), K.at<double>(2, 1), K.at<double>(2, 2);
// edges
int index = 1;
for (size_t i = 0; i < points_2d.size(); ++i) {
auto p2d = points_2d[i];
auto p3d = points_3d[i];
EdgeProjection *edge = new EdgeProjection(p3d, K_eigen);
edge->setId(index);
edge->setVertex(0, vertex_pose);
edge->setMeasurement(p2d);
edge->setInformation(Eigen::Matrix2d::Identity());
optimizer.addEdge(edge);
index++;
}
chrono::steady_clock::time_point t1 = chrono::steady_clock::now();
optimizer.setVerbose(true);
optimizer.initializeOptimization();
optimizer.optimize(10);
chrono::steady_clock::time_point t2 = chrono::steady_clock::now();
chrono::duration<double> time_used = chrono::duration_cast<chrono::duration<double>>(t2 - t1);
cout << "optimization costs time: " << time_used.count() << " seconds." << endl;
cout << "pose estimated by g2o =\n" << vertex_pose->estimate().matrix() << endl;
pose = vertex_pose->estimate();
}
六、总结
光束平差是常用的优方法之一,重投影问题也是各大算法会采用的办法。希望大家可以深刻领会这里面的算法思想。