Flink FAQ - Task 之间的数据交换
翻译自原文:https://cwiki.apache.org/confluence/display/FLINK/Data+exchange+between+tasks
Flink中的数据交换基于以下设计原则构建:
- 数据交换的流控是由接收方启动的,这与原始MapReduce十分相似。
- 用于数据交换的数据流,即通过物理线路的实际数据传输,是通过IntermediateResult的概念抽象的,并且是可插入的。这意味着该系统可以使用相同的实现方式去支持流式传输(streaming)与批量传输(batch)
数据交换的过程:
数据交换的过程,涉及多个对象,包括:
作为主节点的JobManager负责安排任务,恢复和协调,并通过ExecutionGraph数据结构掌握工作的概况。
TaskManagers,工作节点。TaskManager(TM)在线程中同时执行许多任务。每个TM还包含一个CommunicationManager(CM-在任务之间共享)和一个MemoryManager(MM-在任务之间共享)。 TaskManager可以通过复用的TCP连接相互交换数据,这些连接是在需要时创建的。
请注意,在Flink中,通过网络交换数据的是TaskManagers(而不是task),位于同一TaskManagers中的任务之间的数据交换,是通过一个网络连接进行多路复用的。
执行图:执行图是一个包含关于作业计算的“最基本事实”的数据结构。
它由表示计算任务的顶点(ExecutionVertex EV)和表示任务生成的数据的中间结果(IntermediateResultPartition )组成。顶点通过执行边(EE)链接到它们消耗的中间结果:
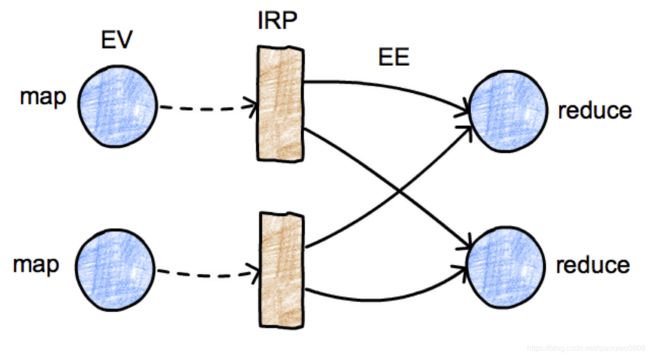
这些是位于JobManager中的逻辑数据结构。在taskmanager上进行实际数据处理的时候,由它们各自的运行时等效结构来负责。与IntermediateResultPartition等价的运行时数据结构称为ResultPartition。
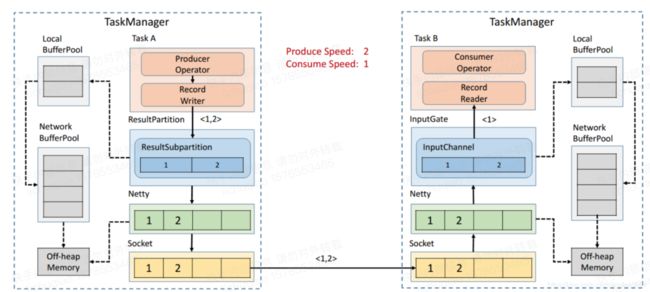
下图所示为数据在一个 taskmanager 内的流转:
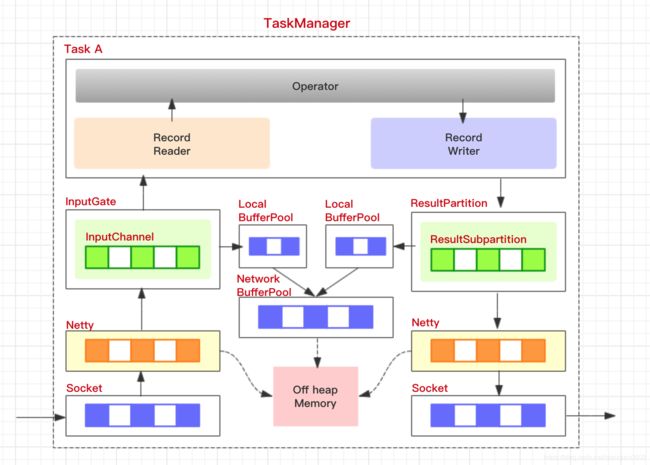
ResultPartition (RP)表示BufferWriter写入的数据块,即由单个任务产生的数据块。RS 是结果子分区(RSs)的集合。这是为了区分发送给不同接收者的数据,例如,对于reduce或join的分区转移。
ResultSubpartition (RS)表示操作符创建的数据的一个分区,以及将数据转发给接收操作符的逻辑。因此 RS 的具体实现决定了实际的数据传输逻辑,这也是一种允许系统支持各种数据传输的 可插拔的机制。例如:PipelinedSubpartition 是一个支持流数据交换的流水线实现。SpillableSubpartition是一个支持批处理数据交换的阻塞实现。RS 的存在屏蔽了底层的数据传输细节。
InputGate: 逻辑上等价于接收端的RP。它负责收集数据缓冲区并将它们向上传递。
InputChannel: 逻辑上等价于接收端的RS。它负责收集特定分区的数据缓冲区。
序列化器(Serializer) 将各种数据类型的记录转换为raw bytes buffer,反序列化器(Deserializer)在将bytes 流转成所需的数据类型,并以此机制来处理横跨多个缓冲区的记录。
buffer 细节可以参照:https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=53741525
数据交换控制流程:
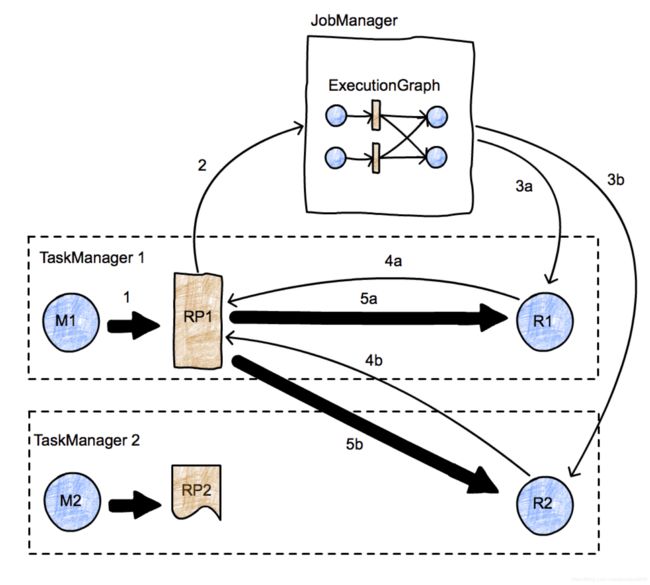
该图表示一个有两个并行任务的简单map-reduce作业。图中有两个taskmanager,每个任务(一个map和一个reduce)在两个不同的节点上运行,JobManager在第三个节点上运行,然后我们来关注一下 在任务M1和R2之间的数据流转,图中:数据传输用粗箭头表示,消息用细箭头表示。
- 首先,M1生成一个ResultPartition (RP1)(箭头1),当RP可用时,它通知JobManager(箭头2)。
- JobManager通知此分区(任务R1和R2) 的接收方分区已经准备好。如果接收器还没就绪,就会实际触发任务的部署(箭头3a, 3b)。
- 接收方(任务R1和R2)就绪后, 数据请求开始(箭头4a和4b) ,这时会启动任务(箭头5a和5b)之间的数据传输,传输可以是local模式(5a),或者跨任务管理器进行(5b)。
- "RP通知JobManager自己的可用性",这个过程本身会存在一定的自由性。eg. 如果RP1在通知JobManager之前就已经 fully produce了(可能已经落盘永久化了),则这种数据交换就大致相当于Hadoop中的批处理。如果RP1在它的第一个记录生成时就通知JM,这就是一个流式的数据交换。
两个任务之间 字节缓冲区的传输:
这个图展示了更多数据流在生产者和消费者之间的传输的细节:
最初,MapDriver生成一些记录 并传递给RecordWriter(由收集器收集)。
RecordWriter包含许多Serializer(记录序列化器对象),每个consumer task 都可能会消费这些记录
例如,在shuffle 或broadcast 模式中,Serializer的数量与consumer task的数量相同。ChannelSelector 把一条记录塞给一个或者多个Serializer。
如果记录被广播,那每个Serializer 都会受到这条记录。如果记录是哈希分区的(hash-partitioned),ChannelSelector会计算记录的哈希值,然后选择适当的序列化器。
Serializer将记录序列化成bytes 数组,并将它们放在固定大小的buffer中(一条记录可以跨多个buffer)。
之后 将这些buffer交给BufferWriter并将其写入ResultPartition (RP)中。一个ResultPartition由几个子分区(ResultSubpartitions RSs)组成,它们为特定的consumers收集buffer。
在上图中,缓冲区被指给第二个reducer (在TaskManager 2中),并被放置在RS2中。
因此,在通知JobManager后, RS2 成为了第一个缓冲区,在消费的过程中可以使用(注意: 这个行为实现了流转移)。
JobManager查找RS2的消费者,并通知TaskManager 2有一组数据可用。
发送到TM2的消息传播到InputChannel,InputChannel接收这个缓冲区,然后通知RS2可以启动网络传输。
随后,RS2将buffer交给TM1的网络堆栈,然后交给netty。这些个Network connection 是存在于TaskManager之间的长链接,Task之间不存在Network connection。
一旦buffer到达TaskManager2,它通过一个从InputChannel开始的,类似的层次结构,传输到inputGate(包含几个ICs),最后抵达一个Deserializer, Deserializer从buffer中取出bytes
解析后再传到下游接收方中去,上图所示的接收方是一个ReduceDriver。