LDA主题模型、Word2Vec
原文地址:http://blog.csdn.net/huagong_adu/article/details/7937616
背景
隐含狄利克雷分配(Latent Dirichlet Allocation)是一种主题模型即从所给文档中挖掘潜在主题。LDA的出现是为了解决类似TFIDF只能从词频衡量文档相似度,可能在两个文档共同出现的单词很少甚至没有,但两个文档是相似的情形: 乔布斯、苹果。
LDA通常用户语义挖掘,识别文档中潜在的主题信息。在主题模型中,主题表示一个概念、一个方面,表现为一系列相关的单词,是这些单词的条件概率。形象来说,主题就是一个桶,里面装了出现概率较高的单词,这些单词与这个主题有很强的相关性。
应用场景
通常LDA用户进主题模型挖掘,当然也可用于降维。
推荐系统:应用LDA挖掘物品主题,计算主题相似度
情感分析:学习出用户讨论、用户评论中的内容主题
主题模型
LDA是一种无监督的生成模型,模型前提认为:每一篇文章的每个单词的产生是“以一定的概率选择了某个主题,并从这个主题以一定的概率选择某个单词”。因此每个文档的每个单词出现的概率计算如下:

矩阵形式:
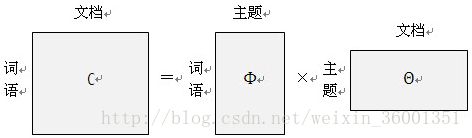
解释:
文档-词语:每个文档中每个单词的词频,即出现的概率
主题-词语:每个主题中每个单词出现的概率
文档-主题:每个文档中每个主题出现的概率
给定一系列文档,通过对文档进行分词,计算每个文档每个词的词频即左边矩阵。主题模型:左边矩阵进行训练,学习出右边两个矩阵
LDA
LDA生成的文档通常可包含多个主题,存在一个主题向量。对于一份文档的产生(伪代码):
Choose parameter θ ~ p(θ);
For each ofthe N words w_n:
Choose a topic z_n ~ p(z|θ);
Choose a word w_n ~ p(w|z); 参数解释:
θ: 主题向量,每一列表示每个主题在文档出现的概率,为非负归一化向量
p(θ): θ的Dirichlet分布,即分布的分布
p(z|θ): 给定θ时主题z的概率分布,p(w|z)
方法:
(1)选定一个主题向量θ,确定每个主题被选择的概率
(2)从主题分布θ选择一个主题z
(3)按主题z的单词概率分布生成一个单词
LDA的联合概率分布为:

图形表示:

解释:
1. corpus-level(红色):α和β表示语料级别的参数,也就是每个文档都一样,因此生成过程只采样一次
2. document-level(橙色):θ是文档级别的变量,每个文档对应一个θ,也就是每个文档产生各个主题z的概率是不同的,所有生成每个文档采样一次θ。
3. word-level(绿色):z和w都是单词级别变量,z由θ生成,w由z和β共同生成,一个 单词w对应一个主题z
LDA模型:从给定的输入语料中学习训练两个控制参数α和β,学习出了这两个控制参数就确定了模型,便可以用来生成文档:
* α:分布p(θ)需要一个向量参数,即Dirichlet分布的参数,用于生成一个主题θ向量
* β:各个主题对应的单词概率分布矩阵p(w|z)
EM算法求解α及β:
前提: 把w当做观察变量,θ和z当做隐藏变量
求解过程中遇到后验概率p(θ,z|w)无法直接求解,需要找一个似然函数下界来近似求解,原文使用基于分解(factorization)假设的变分法(varialtional inference)进行计算,用到了EM算法。每次E-step输入α和β,计算似然函数,M-step最大化这个似然函数,算出α和β,不断迭代直到收敛。
代码库
LDA实现:gensim包
实际应用
Word2Vec
通过深度学习将词表征为数值型向量的工具。它把文本内容简化处理,把词当做特征,Word2Vec将特征映射到K维向量空间,为文本数据寻求更加深层次的特征表示。Word2Vec获得的词向量可被用于聚类、找同义词、词性分析等。
通过词之间的距离(比如 cosine 相似度、欧氏距离等)来判断它们之间的语义相似度。其采用一个 三层的神经网络 :输入层-隐层-输出层。有个核心的技术是 根据词频用Huffman编码 ,使得所有词频相似的词隐藏层激活的内容基本一致,出现频率越高的词语,他们激活的隐藏层数目越少,这样有效的降低了计算的复杂度
Word2Vec优点:
(1)高效;
(2)与潜在语义分析(Latent Semantic Index, LSI)、潜在狄立克雷分配(Latent Dirichlet Allocation,LDA)的经典过程相比,Word2vec利用了词的上下文,语义信息更加地丰富
(3)而在医疗项目中,如诊断报告和检查报告,短文本很常见,因此word2vec可能会达到很好的语义表征效果
相关库
tensorflow官方github仓库中也有使用skip-gram思路实现的word2vec版本
参考文献
[1] http://blog.csdn.net/huagong_adu/article/details/7937616
[2] http://wei-li.cnblogs.com/p/word2vec.html
[3] http://blog.csdn.net/fangpinlei/article/details/52200832