CNN图像识别_算法篇
CNN图像识别_算法篇
- 前言
- Keras
- 1外层循环
- 2中部循环
- 3内部循环
- Matlab CNN ToolBox
- 总结
前言
CNN算法方面主要参考的的zh_JNU同学的工作和Deep-Learning-ToolBox-CNN-master的Matlab源码,然后也做了些修改和解读。
Keras
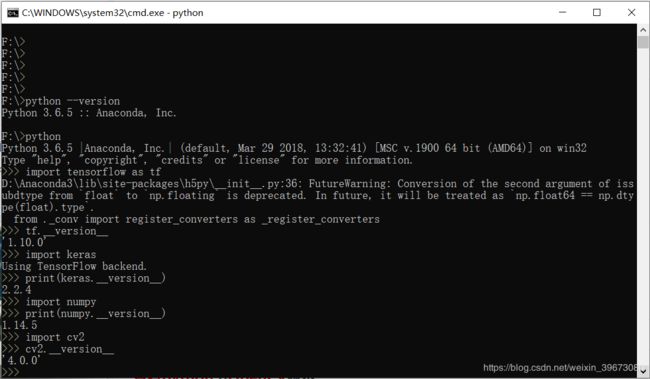
数据库是5钟分类的400张训练数据和100张测试数据,数据库网盘(提取码:f5ze)可能跟环境版本有关,我这边的预处理不能使用cv的方法,所以统一使用cv2里的方法,值得强调的是,Keras版本亦有差异,我这边的版本大致如图
首先是预处理,利用opencv对图片进行缩放和灰化,将RGB3通道降维到单通道,python果然是“玩弄”字符串的语言
#coding:utf8
import os
import cv2
# 遍历指定目录,显示目录下的所有文件名
#width_scale = 192 #缩放尺寸宽度
#height_scale = 128#缩放尺寸高度
write_path = "/data_base/all_data/test_scale/"#要写入的图片路径"/data_base/all_data/train_scale/"
#遍历每一张图片进行处理
def eachFile(filepath):
pathDir = os.listdir(filepath)
for allDir in pathDir:
child = os.path.join('%s%s' % (filepath,allDir))
write_child = os.path.join('%s%s' % (write_path,allDir))
image = cv2.imread(child,cv2.IMREAD_GRAYSCALE)#image = cv.LoadImage(child,0)
shrink = cv2.resize(image,(126,126),interpolation=cv2.INTER_AREA) #(192,128)
cv2.imwrite(write_child,shrink)
# break
if __name__ == '__main__':
filePathC = "/data_base/all_data/test/"##"/data_base/all_data/train/" 训练测试数据集分别处理
eachFile(filePathC)
这里的预处理后的维度调整为126*126,主要考虑的是每层池化层的输入都为偶数,卷积核kernel size 为3,那么,输入层126*126 --> 1卷积层124*124–>1池化层62*62–>2卷积层60*60–>2池化层30*30–>3卷积层28*28–>3池化层14*14,接下来就是全连接,预处理后
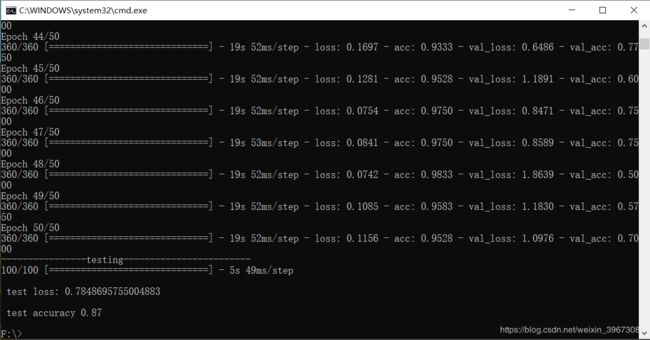
然后是测试,包括网络的训练和测试,我这里除了版本兼容上的调整,也做了些改动,
首先是修改后的源码,这里有一些术语,我将它们梳理一下
1外层循环
epoch:完整样本训练的次数;
batch:1个样本空间中样本的个数;
有时1个完整的样本空间可能包含大量的样本,这时需要对样本进行分割,分成minibatch,那么完成 一次样本训练就需要迭代iteration = batch/minibatch;minibatch的一种极限情形就是等于1,理论上不是不可以,但是容易过拟合。
2中部循环
filters:某一个卷积层中卷积核的个数,之后再经过池化层后,每一个filter都会对应一个feature map(特征图)
3内部循环
kernel_size:卷积核的维数,在滑动过程中也会有stride、padding等参数的选取
label:标签的维数,其实我觉得标签的选取还是挺自由的,可以认为每个分类就是一个实数,也可以是种类维度的独热码向量,如果是1*1的实数R,在BP过程可能会简单点,因为均方误差也是一个实数,独热码向量的形式,其实已经被赋予了一定的意义,即每一位代表了样本为该类的可能性(probability)
#coding:utf8
import re
import cv2
import os
import numpy as np
from keras.models import Sequential
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.core import Dense,Dropout,Activation,Flatten
from keras.layers.convolutional import Conv2D,MaxPooling2D
from keras.optimizers import Adam
from keras.utils import np_utils
#得到一共多少个样本
def getnum(file_path):
pathDir = os.listdir(file_path)
i = 0
for allDir in pathDir:
i +=1
return i
#制作数据集
def data_label(path,count):
data = np.empty((count,1,126,126),dtype = 'float32')#建立空的四维张量类型32位浮点
label = np.empty((count,),dtype = 'uint8')
i = 0
pathDir = os.listdir(path)
for each_image in pathDir:
all_path = os.path.join('%s%s' % (path,each_image))#路径进行连接
image = cv2.imread(all_path,0)
mul_num = re.findall(r"\d",all_path)#寻找字符串中的数字,由于图像命名为300.jpg 标签设置为0
num = int(mul_num[0])-3
# print num,each_image
# cv2.imshow("fad",image)
# print child
array = np.asarray(image,dtype='float32')
array -= np.min(array)
array /= np.max(array)
data[i,:,:,:] = array
label[i] = int(num)
i += 1
return data,label
#构建卷积神经网络
def cnn_model(train_data,train_label,test_data,test_label):
model = Sequential()
#卷积层 12 × 124 × 124 大小
model.add(Conv2D(
filters = 12,
kernel_size = (3,3),
padding = "valid",
data_format = "channels_first",
input_shape = (1,126,126)))
model.add(Activation('relu'))#激活函数使用修正线性单元
#池化层12 × 62 × 62
model.add(MaxPooling2D(
pool_size = (2,2),
strides = (2,2),
padding = "valid"))
#卷积层 24 * 60 * 60
model.add(Conv2D(
24,
(3,3),
padding = "valid",
data_format = "channels_first"))
model.add(Activation('relu'))
#池化层 24×30×30
model.add(MaxPooling2D(
pool_size = (2,2),
strides = (2,2),
padding = "valid"))
#卷积层 48×28×28
model.add(Conv2D(
48,
(3,3),
padding = "valid",
data_format = "channels_first"))
model.add(Activation('relu'))
#池化层 48×14×14
model.add(MaxPooling2D(
pool_size = (2,2),
strides =(2,2),
padding = "valid"))
model.add(Flatten())
model.add(Dense(20))
model.add(Activation(LeakyReLU(0.3)))
model.add(Dropout(0.5))
model.add(Dense(20))
model.add(Activation(LeakyReLU(0.3)))
model.add(Dropout(0.4))
model.add(Dense(5,kernel_initializer="normal"))
model.add(Activation('softmax'))
adam = Adam(lr = 0.001)
model.compile(optimizer = adam,
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
print ('----------------training-----------------------')
model.fit(train_data,train_label,batch_size = 20,epochs = 50,shuffle = "True",validation_split = 0.1)
print ('----------------testing------------------------')
loss,accuracy = model.evaluate(test_data,test_label)
print ('\n test loss:',loss)
print ('\n test accuracy',accuracy)
train_path = "/data_base/all_data/train_scale/"
test_path = "/data_base/all_data/test_scale/"
train_count = getnum(train_path)
test_count = getnum(test_path)
train_data,train_label = data_label(train_path,train_count)
test_data,test_label = data_label(test_path,test_count)
train_label = np_utils.to_categorical(train_label,num_classes = 5)
test_label = np_utils.to_categorical(test_label,num_classes = 5)
cnn_model(train_data,train_label,test_data,test_label)
#print getnum('/home/zhanghao/data/classification/test_scale/')
#data_label('/home/zhanghao/data/classification/test_scale/',1)
#cv.WaitKey(0)
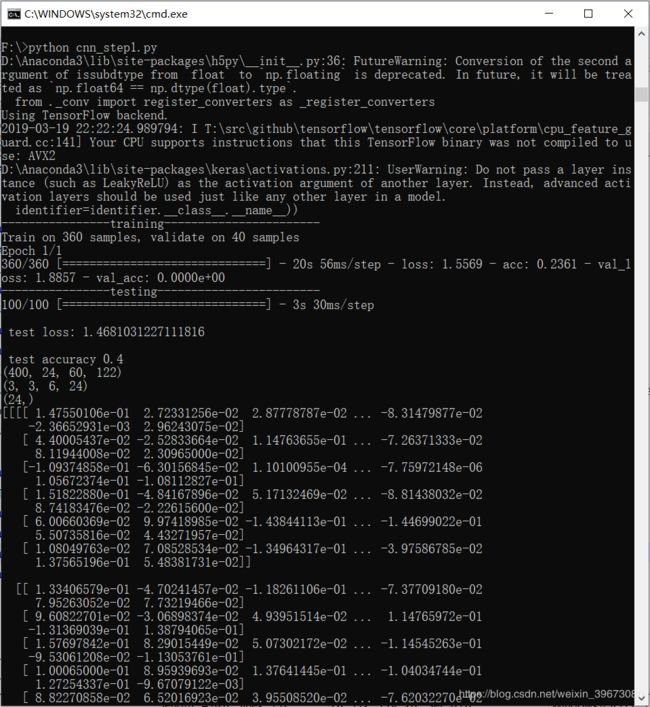
代码是3层卷积+池化再进行全连接,因为kernel_size是33,并且没有对输入样本扩展,所以卷积层后的维数就是Nin-kernel_size+1,池化层是22,所以池化后宽高减半。
查看中间变量的方法,插入观察层,首先要给每一层都取个名字,目前,它的这个打印结果有点令人挠头
#coding:utf8
import re
import cv2
import os
import numpy as np
from keras.models import Sequential
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.core import Dense,Dropout,Activation,Flatten
from keras.layers.convolutional import Conv2D,MaxPooling2D
from keras.optimizers import Adam
from keras.utils import np_utils
from keras.layers import Dense
from keras.models import Model
#得到一共多少个样本
def getnum(file_path):
pathDir = os.listdir(file_path)
i = 0
for allDir in pathDir:
i +=1
return i
#制作数据集
def data_label(path,count):
data = np.empty((count,1,126,126),dtype = 'float32')#建立空的四维张量类型32位浮点
label = np.empty((count,),dtype = 'uint8')
i = 0
pathDir = os.listdir(path)
for each_image in pathDir:
all_path = os.path.join('%s%s' % (path,each_image))#路径进行连接
image = cv2.imread(all_path,0)
mul_num = re.findall(r"\d",all_path)#寻找字符串中的数字,由于图像命名为300.jpg 标签设置为0
num = int(mul_num[0])-3
# print num,each_image
# cv2.imshow("fad",image)
# print child
array = np.asarray(image,dtype='float32')
array -= np.min(array)
array /= np.max(array)
data[i,:,:,:] = array
label[i] = int(num)
i += 1
return data,label
#构建卷积神经网络
def cnn_model(train_data,train_label,test_data,test_label):
model = Sequential()
#卷积层 12 × 120 × 120 大小
model.add(Conv2D(
filters = 12,
kernel_size = (3,3),
padding = "valid",
data_format = "channels_first",
input_shape = (1,126,126),name="cnn1"))
model.add(Activation('relu'))#激活函数使用修正线性单元
#池化层12 × 60 × 60
model.add(MaxPooling2D(
pool_size = (2,2),
strides = (2,2),
padding = "valid",name="mxp1"))
#卷积层 24 * 58 * 58
model.add(Conv2D(
24,
(3,3),
padding = "valid",
data_format = "channels_first",name="cnn2"))
model.add(Activation('relu'))
#池化层 24×29×29
model.add(MaxPooling2D(
pool_size = (2,2),
strides = (2,2),
padding = "valid",name="mxp2"))
#卷积层
model.add(Conv2D(
48,
(3,3),
padding = "valid",
data_format = "channels_first",name="cnn3"))
model.add(Activation('relu'))
#池化层
model.add(MaxPooling2D(
pool_size = (2,2),
strides =(2,2),
padding = "valid",name="mxp3"))
model.add(Flatten())
model.add(Dense(20))
model.add(Activation(LeakyReLU(0.3)))
model.add(Dropout(0.5))
model.add(Dense(20))
model.add(Activation(LeakyReLU(0.3)))
model.add(Dropout(0.4))
model.add(Dense(5,kernel_initializer="normal"))
model.add(Activation('softmax'))
adam = Adam(lr = 0.001)
model.compile(optimizer = adam,
loss = 'categorical_crossentropy',
metrics = ['accuracy'])
print ('----------------training-----------------------')
model.fit(train_data,train_label,batch_size = 20,epochs = 1,shuffle = "True",validation_split = 0.1)
print ('----------------testing------------------------')
loss,accuracy = model.evaluate(test_data,test_label)
print ('\n test loss:',loss)
print ('\n test accuracy',accuracy)
##注意缩进 观察层应为模型之中
dense1_layer_model = Model(inputs=model.input,outputs=model.get_layer("cnn2").output)
dense1_output = dense1_layer_model.predict(train_data)
print (dense1_output.shape)
weight_Dense_1,bias_Dense_1 = model.get_layer("cnn2").get_weights()
print(weight_Dense_1.shape)
print(bias_Dense_1.shape)
print(weight_Dense_1)
print(bias_Dense_1)
train_path = "/data_base/all_data/train_scale/"
test_path = "/data_base/all_data/test_scale/"
train_count = getnum(train_path)
test_count = getnum(test_path)
train_data,train_label = data_label(train_path,train_count)
test_data,test_label = data_label(test_path,test_count)
train_label = np_utils.to_categorical(train_label,num_classes = 5)
test_label = np_utils.to_categorical(test_label,num_classes = 5)
cnn_model(train_data,train_label,test_data,test_label)
##错误
#取某一层的输出为输出新建为model,采用函数模型
#dense1_layer_model = Model(inputs=model.input,
# outputs=model.get_layer('cnn1').output)
#以这个model的预测值作为输出
#dense1_output = dense1_layer_model.predict(data)
#print getnum('/home/zhanghao/data/classification/test_scale/')
#data_label('/home/zhanghao/data/classification/test_scale/',1)
#cv.WaitKey(0)
train_path = "/data_base/all_data/train_scale/"
test_path = "/data_base/all_data/test_scale/"
train_count = getnum(train_path)
test_count = getnum(test_path)
train_data,train_label = data_label(train_path,train_count)
test_data,test_label = data_label(test_path,test_count)
train_label = np_utils.to_categorical(train_label,num_classes = 5)
test_label = np_utils.to_categorical(test_label,num_classes = 5)
cnn_model(train_data,train_label,test_data,test_label)
Matlab CNN ToolBox
这个工具箱最早是在Github上开源的,论坛上也有很多同学对源码进行解读,我觉得都挺好的,不过,我觉得最好的辅助理解是Sunshine同学写的两层CNN的Matlab实现,他把前一个卷积+池化和后一个卷积+池化之间的前馈和反馈连接关系讲得很清楚,并且,和这个CNN ToolBox的处理方式一致,读者能够很直观地看到各个子层的维数变化
总结
看了挺多资料的,觉得把这两个例子读通,会很有帮助,尤其是Matlab的这个,你可以看到很多细节的处理方式