Keras共享层模型入门:基于Python及R实现
Keras中可以多层共享一个层的输出。例如输入中可以存在多个不同的特征提取层,或者可以使用多个层来预测特征提取层的输出。
下面进行示例介绍。
本节将介绍具有不同大小内核的多个卷积层如何解译同一图像的输入。该模型采用尺寸为32*32*3像素的彩色CIFAR图像。有两个共享此输入的CNN特征提取子模型,其中一个内核大小为4,另一个内核大小为8。这些特征提取子模型的输出被平展为向量、然后串联成为一个长向量,并在最终输出层进行二进制分类之前,将其传递到全连接层进行解译。
以下为模型拓扑:
- 一个输入层
- 两个特征提取层
- 一个解译层
- 一个稠密输出层
接下来,让我们先加载数据,并查看数据结构。
```{Python}
from keras.utils import plot_model
from keras.models import Model
from keras.layers import Input
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers.convolutional import Conv2D
from keras.layers.pooling import MaxPooling2D
from keras.layers.merge import concatenate
from keras.datasets import cifar10
import keras
num_classes = 10
batch_size = 32
epochs = 10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
print("X_train shape: " + str(x_train.shape))
print("y_train shape: " + str(y_train.shape))
print("X_test shape: " + str(x_test.shape))
print("y_test shape: " + str(y_test.shape))
X_train shape: (50000, 32, 32, 3)
y_train shape: (50000, 1)
X_test shape: (10000, 32, 32, 3)
y_test shape: (10000, 1)
```
```{R}
> library(keras)
> num_classes = 10
> batch_size = 32
> epochs = 10
> c(c(x_train, y_train), c(x_test, y_test)) %<-% dataset_cifar10()
> cat("X_train shape: " ,dim(x_train))
X_train shape: 50000 32 32 3
> cat("y_train shape: ",dim(y_train))
y_train shape: 50000 1
> cat("X_test shape: " ,dim(x_test))
X_test shape: 10000 32 32 3
>cat("y_test shape: ",dim(y_test))
y_test shape: 10000 1
```现在,进行数据预处理。
```{Python}
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
```
```{R}
x_train <- x_train / 255
x_test <- x_test / 255
y_train <- to_categorical(y_train,num_classes)
y_test <- to_categorical(y_test,num_classes)
```构建模型拓扑
```{Python}
# input layer
visible = Input(shape=(32,32,3))
# first feature extractor
conv1 = Conv2D(32, kernel_size=4, activation='relu')(visible)
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
flat1 = Flatten()(pool1)
# second feature extractor
conv2 = Conv2D(16, kernel_size=8, activation='relu')(visible)
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
flat2 = Flatten()(pool2)
# merge feature extractors
merge = concatenate([flat1, flat2])
# interpretation layer
hidden1 = Dense(512, activation='relu')(merge)
# prediction output
output = Dense(10, activation='sigmoid')(hidden1)
model = Model(inputs=visible, outputs=output)
```
```{R}
# input layer
visible <- layer_input(shape = c(32,32,3))
# first feature extractor
flat1 <- visible %>%
layer_conv_2d(32,kernel_size = 4,activation = 'relu') %>%
layer_max_pooling_2d(pool_size = c(2,2)) %>%
layer_flatten()
# second feature extractor
flat2 <- visible %>%
layer_conv_2d(16,kernel_size = 8,activation = 'relu') %>%
layer_max_pooling_2d(pool_size = c(2,2)) %>%
layer_flatten()
# merge feature extractors
merge <- layer_concatenate(list(flat1,flat2))
# interpretation layer
hidden1 <- merge %>%
layer_dense(512,activation = 'relu')
# prediction output
output <- hidden1 %>%
layer_dense(10,activation = 'sigmoid')
model <- keras_model(inputs = visible,outputs = output)
```查看模型结构
```{Python}
# summarize layers
print(model.summary())
```
```{R}
# summarize layers
summary(model)
```
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 32, 32, 3) 0
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 29, 29, 32) 1568 input_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 25, 25, 16) 3088 input_1[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, 14, 14, 32) 0 conv2d_1[0][0]
__________________________________________________________________________________________________
max_pooling2d_2 (MaxPooling2D) (None, 12, 12, 16) 0 conv2d_2[0][0]
__________________________________________________________________________________________________
flatten_1 (Flatten) (None, 6272) 0 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
flatten_2 (Flatten) (None, 2304) 0 max_pooling2d_2[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 8576) 0 flatten_1[0][0]
flatten_2[0][0]
__________________________________________________________________________________________________
dense_6 (Dense) (None, 512) 4391424 concatenate_1[0][0]
__________________________________________________________________________________________________
dense_7 (Dense) (None, 10) 5130 dense_6[0][0]
==================================================================================================
Total params: 4,401,210
Trainable params: 4,401,210
Non-trainable params: 0
__________________________________________________________________________________________________
None
训练模型
```{Python}
opt = keras.optimizers.rmsprop(lr=0.0001, decay=1e-6)
# Let's train the model using RMSprop
model.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test),
shuffle=True)
```
Epoch 9/10
50000/50000 [==============================] - 268s 5ms/step - loss: 0.8295 - accuracy: 0.7160 - val_loss: 0.9999 - val_accuracy: 0.6540 ETA: 3:25 - loss: 0.8301 - accuracy: 0.7151
Epoch 10/10
50000/50000 [==============================] - 271s 5ms/step - loss: 0.7886 - accuracy: 0.7321 - val_loss: 1.0353 - val_accuracy: 0.6479 ETA: 51s - loss: 0.7906 - accuracy: 0.7311
```{R}
opt <- optimizer_rmsprop(lr=0.0001, decay=1e-6)
# Let's train the model using RMSprop
model %>% compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=c('accuracy'))
history <- model %>% fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=list(x_test, y_test),
shuffle=TRUE)
Epoch 9/10
50000/50000 [==============================] - 150s 3ms/sample - loss: 0.8233 - accuracy: 0.7187 - val_loss: 1.0517 - val_accuracy: 0.6277
Epoch 10/10
50000/50000 [==============================] - 181s 4ms/sample - loss: 0.7801 - accuracy: 0.7344 - val_loss: 1.0165 - val_accuracy: 0.6507
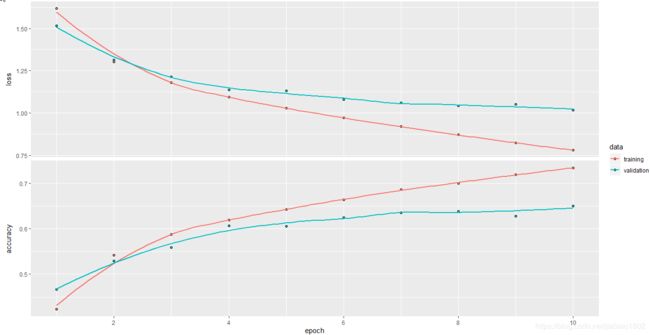
plot(history)
```
利用测试数据集评估模型的准确率
```{Python}
scores = model.evaluate(x_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
Test loss: 1.0353177757263183
Test accuracy: 0.6478999853134155
```
```{r}
scores <- model %>% evaluate(x_test, y_test, verbose=1)
cat('Test loss:',scores[[1]])
Test loss: 1.01648
cat('Test accuracy:',scores[[2]])
Test accuracy: 0.6507
```