深入浅出 卡尔曼滤波
转自知乎 https://www.zhihu.com/question/23971601 转载过来可能会图片乱码 可以去看下 答主 前四个回答真的很好
最通俗理解的方法 无公式
选自知乎大神 https://www.zhihu.com/question/23971601
假设你有两个传感器,测的是同一个信号。可是它们每次的读数都不太一样,怎么办?
取平均。
再假设你知道其中贵的那个传感器应该准一些,便宜的那个应该差一些。那有比取平均更好的办法吗?
加权平均。
怎么加权?假设两个传感器的误差都符合正态分布,假设你知道这两个正态分布的方差,用这两个方差值,(此处省略若干数学公式),你可以得到一个“最优”的权重。
接下来,重点来了:假设你只有一个传感器,但是你还有一个数学模型。模型可以帮你算出一个值,但也不是那么准。怎么办?
把模型算出来的值,和传感器测出的值,(就像两个传感器那样),取加权平均。
OK,最后一点说明:你的模型其实只是一个步长的,也就是说,知道x(k),我可以求x(k+1)。问题是x(k)是多少呢?答案:x(k)就是你上一步卡尔曼滤波得到的、所谓加权平均之后的那个、对x在k时刻的最佳估计值。
于是迭代也有了。
这就是卡尔曼滤波。
(无公式)作者:Kent Zeng
转自知乎大神
好了下面进入正题,先从简单的说起:
考虑轨道上的一个小车,无外力作用,它在时刻t的状态向量只与相关:
(状态向量就是描述它的t=0时刻所有状态的向量,比如:
[速度大小5m/s, 速度方向右, 位置坐标0],反正有了这个向量就可以完全预测t=1时刻小车的状态)
那么根据t=0时刻的初值,理论上我们可以求出它任意时刻的状态。
当然,实际情况不会这么美好。
这个递推函数可能会受到各种不确定因素的影响(内在的外在的都算,比如刮风下雨地震,小车结构不紧密,轮子不圆等等)导致并不能精确标识小车实际的状态。
我们假设每个状态分量受到的不确定因素都服从正态分布。
现在仅对小车的位置进行估计
请看下图:t=0时小车的位置服从红色的正态分布。
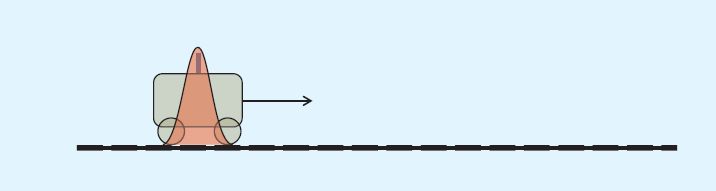
根据小车的这个位置,我们可以预测出t=1时刻它的位置:
<img src="https://pic4.zhimg.com/50/003e9521ce6e69dfd8b7f601660795ad_hd.jpg" data-rawwidth="716" data-rawheight="137" class="origin_image zh-lightbox-thumb" width="716" data-original="https://pic4.zhimg.com/003e9521ce6e69dfd8b7f601660795ad_r.jpg">

分布变“胖”了,这很好理解——因为在递推的过程中又加了一层噪声,所以不确定度变大了。
为了避免纯估计带来的偏差,我们在t=1时刻对小车的位置坐标进行一次雷达测量,当然雷达对小车距离的测量也会受到种种因素的影响,于是测量结果告诉我们,小车t=1时的位置服从蓝色分布:
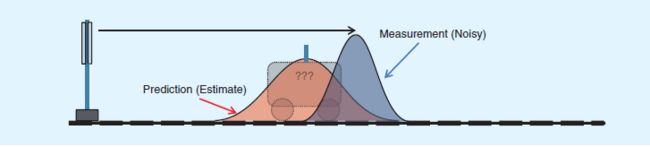
好了,现在我们得到两个不同的结果。前面有人提过加权,Kalman老先生的牛逼之处就在于找到了相应权值,使红蓝分布合并为下图这个 绿色的正态分布(啰嗦一句,这个绿色分布均值位置在红蓝均值间的比例称为Kalman增益(比如下图中近似0.8),就是各种公式里的K(t))
<img src="https://pic3.zhimg.com/50/83666ee825877a07256bc1c8b0386f45_hd.jpg" data-rawwidth="733" data-rawheight="139" class="origin_image zh-lightbox-thumb" width="733" data-original="https://pic3.zhimg.com/83666ee825877a07256bc1c8b0386f45_r.jpg">
 你问为什么牛逼?
你问为什么牛逼?
绿色分布不仅保证了在红蓝给定的条件下,小车位于该点的概率最大,而且,而且,它居然还是一个正态分布!
正态分布就意味着,可以把它当做初值继续往下算了!这是Kalman滤波能够迭代的关键。
最后,把绿色分布当做第一张图中的红色分布对t=2时刻进行预测,算法就可以开始循环往复了。
你又要问了,说来说去绿色分布是怎么得出的呢?
其实可以通过多种方式推导出来。我们课上讲过的就有最大似然法、Ricatti方程法,以及上面参考文献中提及的直接对高斯密度函数变形的方法,这个不展开说了。
另外,由于我只对小车位移这个一维量做了估计,因此Kalman增益是标量,通常情况下它都是一个矩阵。而且如果估计多维量,还应该引入协方差矩阵的迭代,我也没有提到。如果楼主有兴趣,把我提及那篇参考文献吃透,就明白了。
Kalman滤波算法的本质就是利用两个正态分布的融合仍是正态分布这一特性进行迭代而已。卡尔曼滤波是如何工作的,图解
我必须要告诉你一些关于卡尔曼滤波的知识,因为这踏马的太牛B了。
奇怪的是很少有软件工程师或者科学家对它有所了解。这让我有点小失望,因为在一些含有不确定因素的场景里,如何去综合获取有效的信息,卡尔曼滤波是一个通用并且强有力的算法。有时候它提取精确信息的能力看上去就像是“见证奇迹的时刻”。如果看到这里你认为我说的话里有夸大的水分,你可以看下我开发的效果视频(http://www.bzarg.com/p/improving-imu-attitude-estimates-with-velocity-data)。在这个demo里我通过检测角速度来获取一个自由物体的姿态,效果奇佳。
什么是卡尔曼滤波?
你可以在任何含有不确定因素的动态系统里使用卡尔曼滤波,并且你应该可以通过一些数学建模对系统下一步动向做一个大概的预测。尽管系统总是会受到一些未知的干扰,但是卡尔曼滤波总是可以派上用场来提高系统预估的精确度,这样可以使你更加准确地清楚到底发生了什么事情。而且它可以有效利用多个粗糙数据之间的关系,而单独面对这些数据你可能都无从下手。
卡尔曼滤波尤其适合动态系统。它对于内存要求极低(它仅需要保留系统上一个状态的数据,而不是一段跨度很长的历史数据)。并且它运算很快,这使得它非常适合解决实时问题和应用于嵌入式系统。
如果你尝试谷歌去搜索相关资料,对于卡尔曼滤波的数学表达总是很枯燥并且难理解。这提高了大家的学习成本甚至打击了学习兴趣,因为卡尔曼滤波真的是超级简单,当然前提是你用正确的方式去理解它。因此这就形成了一个很有意义的学术话题,我将会通过很多清晰、漂亮的图片以及颜色标注来阐述这个话题。对学习者的预备知识要求很简单,你只需要对概率论和矩阵运算有一些简单的基础知识。
我们从一个简单的例子入手,看下卡尔曼滤波可以解决什么问题。如果你想直接看公式推导,可以跳过下一节。
利用卡尔曼滤波我们可以做什么?
我们举一个玩具的栗子:你开发了一款小型机器人,它可以在树林里自主移动,并且这款机器人需要明确自己的位置以便进行导航。
<img src="https://pic3.zhimg.com/50/v2-3e2ab5a07a120d695c3ff1db7c80a4c4_hd.jpg" data-caption="" data-size="normal" data-rawwidth="300" data-rawheight="160" class="content_image" width="300">
我们可以通过一组状态变量 来描述机器人的状态,包括位置和速度:
<img src="https://pic3.zhimg.com/50/v2-9224af698301bd5febe3fe15f9664737_hd.jpg" data-caption="" data-size="normal" data-rawwidth="108" data-rawheight="36" class="content_image" width="108">注意这个状态仅仅是系统所有状态中的一部分,你可以选取任何数据变量作为观测的状态。在我们这个例子中选取的是位置和速度,它也可以是水箱中的水位,汽车引擎的温度,一个用户的手指在平板上划过的位置,或者任何你想要跟踪的数据。
我们的机器人同时拥有一个GPS传感器,精度在10m。这已经很好了,但是对我们的机器人来说它需要以远高于10m的这个精度来定位自己的位置。在机器人所处的树林里有很多溪谷和断崖,如果机器人对位置误判了哪怕只是几步远的距离,它就有可能掉到坑里。所以仅靠GPS是不够的。
<img src="https://pic1.zhimg.com/50/v2-32aefb4b9cfcafaa43426d7807b3625f_hd.jpg" data-caption="" data-size="normal" data-rawwidth="300" data-rawheight="283" class="content_image" width="300">
同时我们可以获取到一些机器人的运动的信息:驱动轮子的电机指令对我们也有用处。如果没有外界干扰,仅仅是朝一个方向前进,那么下一个时刻的位置只是比上一个时刻的位置在该方向上远了一些。当然我们无法获取影响运动的所有信息:机器人可能会受到风力影响,轮子可能会打滑,或者碰到了一些特殊的路况;所以轮子转过的距离并不能完全表示机器人移动的距离,这就导致通过轮子转动预测机器人位置不会非常准确。
GPS传感器也会告知我们一些关于机器人状态的信息,但是会包含一些不确定性因素。我们通过轮子转动可以预知机器人是如何运动的,同样也有一定的不准确度。
如果我们综合两者的信息呢?可以得到比只依靠单独一个信息来源更精确的结果么?答案当然是YES,这就是卡尔曼滤波要解决的问题。
卡尔曼滤波如何看待你的问题
我们再来看下需要解决的问题,同样是上边的系统,系统状态包括位置和速度。
<img src="https://pic1.zhimg.com/50/v2-1b3668a6475a9554c4425e50507df9d5_hd.jpg" data-caption="" data-size="normal" data-rawwidth="81" data-rawheight="57" class="content_image" width="81">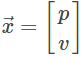
我们不知道位置和速度的准确值;但是我们可以列出一个准确数值可能落在的区间。在这个范围里,一些数值组合的可能性要高于另一些组合的可能性。
<img src="https://pic3.zhimg.com/50/v2-f7931f76177ec93a23b8adfbdbf3c9e1_hd.jpg" data-caption="" data-size="normal" data-rawwidth="621" data-rawheight="650" class="origin_image zh-lightbox-thumb" width="621" data-original="https://pic3.zhimg.com/v2-f7931f76177ec93a23b8adfbdbf3c9e1_r.jpg">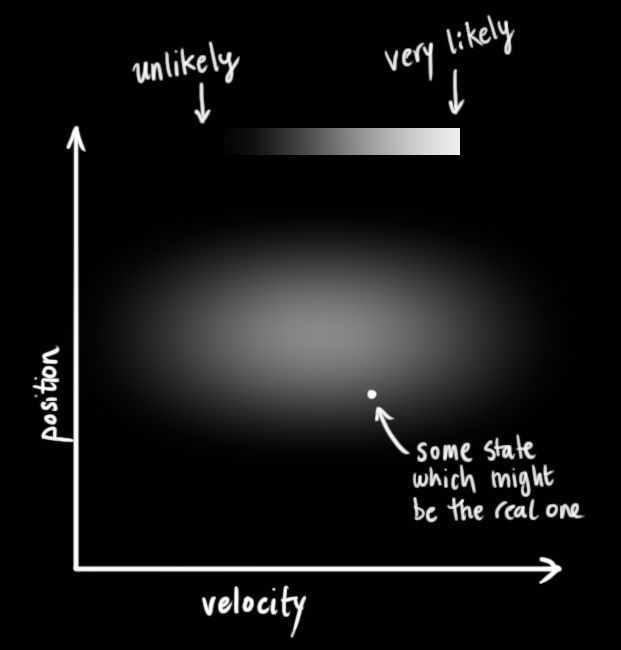
卡尔曼滤波假设所有的变量(在我们的例子中为位置和速度)是随机的且符合高斯分布(正太分布)。每个变量有一个平均值u,代表了随机分布的中心值(也表示这是可能性最大的值),和一个方差 ,代表了不确定度。
<img src="https://pic3.zhimg.com/50/v2-8eb051706a22925db4380de43274134d_hd.jpg" data-caption="" data-size="normal" data-rawwidth="621" data-rawheight="553" class="origin_image zh-lightbox-thumb" width="621" data-original="https://pic3.zhimg.com/v2-8eb051706a22925db4380de43274134d_r.jpg">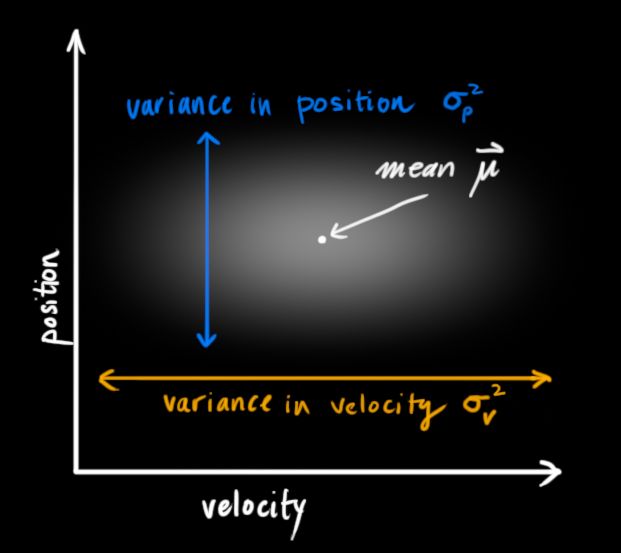
在上图中位置和速度是无关联的,即系统状态中的一个变量并不会告诉你关于另一个变量的任何信息。
下图则展示了一些有趣的事情:在现实中,速度和位置是有关联的。如果已经确定位置的值,那么某些速度值存在的可能性更高。
<img src="https://pic4.zhimg.com/50/v2-15fa86573f39f47d64e519f013de36bc_hd.jpg" data-caption="" data-size="normal" data-rawwidth="621" data-rawheight="572" class="origin_image zh-lightbox-thumb" width="621" data-original="https://pic4.zhimg.com/v2-15fa86573f39f47d64e519f013de36bc_r.jpg">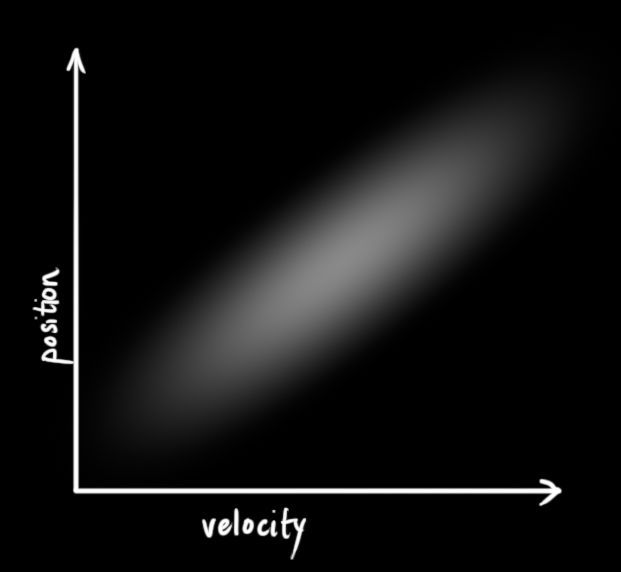
假如我们已知上一个状态的位置值,现在要预测下一个状态的位置值。如果我们的速度值很高,我们移动的距离会远一点。相反,如果速度慢,机器人不会走的很远。
这种关系在跟踪系统状态时很重要,因为它给了我们更多的信息:一个测量值告诉我们另一个测量值可能是什么样子。这就是卡尔曼滤波的目的,我们要尽量从所有不确定信息中提取有价值的信息!
这种关系可以通过一个称作协方差的矩阵表述。简而言之,矩阵中的每个元素 表示了第i个状态变量和第j个状态变量之间的关系。(你可能猜到了协方差矩阵是对称的,即交换下标i和j并无任何影响)。协方差矩阵通常表示为Σ,它的元素则表示为 。。
<img src="https://pic2.zhimg.com/50/v2-bf3c5cbfd5c791a08121e6f3220b1c4e_hd.jpg" data-caption="" data-size="normal" data-rawwidth="621" data-rawheight="572" class="origin_image zh-lightbox-thumb" width="621" data-original="https://pic2.zhimg.com/v2-bf3c5cbfd5c791a08121e6f3220b1c4e_r.jpg">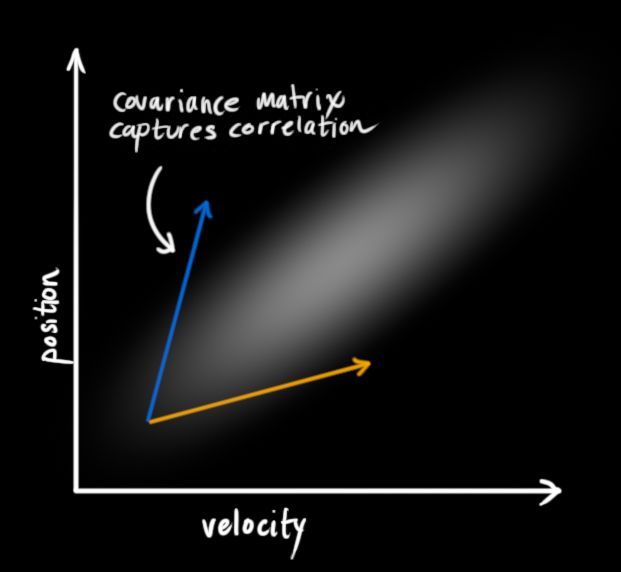
利用矩阵描述问题
我们对系统状态的分布建模为高斯分布,所以在k时刻我们需要两个信息:最佳预估值 (平均值,有些地方也表示为u),和它的协方差矩阵
<img src="https://pic4.zhimg.com/50/v2-7a37acb781ed1d3f00ea8a9107cc3e63_hd.jpg" data-caption="" data-size="normal" data-rawwidth="554" data-rawheight="88" class="origin_image zh-lightbox-thumb" width="554" data-original="https://pic4.zhimg.com/v2-7a37acb781ed1d3f00ea8a9107cc3e63_r.jpg">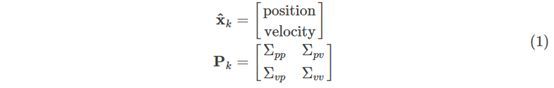
(这里我们只记录了位置和速度,但是我们可以把任何数据变量放进我们的系统状态里)
下一步,我们需要通过k-1时刻的状态来预测k时刻的状态。请注意,我们不知道状态的准确值,但是我们的预测函数并不在乎。它仅仅是对k-1时刻所有可能值的范围进行预测转移,然后得出一个k时刻新值的范围。
<img src="https://pic3.zhimg.com/50/v2-8170a6981244e9aa2f60d093e0d20a4e_hd.jpg" data-caption="" data-size="normal" data-rawwidth="621" data-rawheight="572" class="origin_image zh-lightbox-thumb" width="621" data-original="https://pic3.zhimg.com/v2-8170a6981244e9aa2f60d093e0d20a4e_r.jpg">
我们可以通过一个状态转移矩阵 来描述这个转换
<img src="https://pic2.zhimg.com/50/v2-5810ceee40fd2cf52478551e156ec773_hd.jpg" data-caption="" data-size="normal" data-rawwidth="621" data-rawheight="572" class="origin_image zh-lightbox-thumb" width="621" data-original="https://pic2.zhimg.com/v2-5810ceee40fd2cf52478551e156ec773_r.jpg">
把k-1时刻所有可能的状态值转移到一个新的范围内,这个新的范围代表了系统新的状态值可能存在的范围,如果k-1时刻估计值的范围是准确的话。
通过一个运动公式来表示这种预测下个状态的过程:
<img src="https://pic3.zhimg.com/50/v2-1277f74f7affb886f7f04800bcd2c48c_hd.jpg" data-caption="" data-size="normal" data-rawwidth="189" data-rawheight="62" class="content_image" width="189">
整理为矩阵:
<img src="https://pic3.zhimg.com/50/v2-64f3cc7d58a27ff7000a3b75e4c6b080_hd.jpg" data-caption="" data-size="normal" data-rawwidth="795" data-rawheight="94" class="origin_image zh-lightbox-thumb" width="795" data-original="https://pic3.zhimg.com/v2-64f3cc7d58a27ff7000a3b75e4c6b080_r.jpg">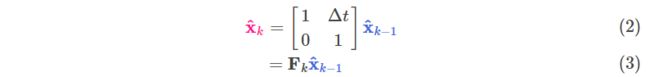
我们现在有了一个状态转移矩阵,可以简单预测下个状态,但仍不知道如何更新协方差矩阵。
这里我们需要另一个公式。如果我们对每个点进行矩阵A转换,它的协方差矩阵Σ会发生什么变化呢?
Easy,直接告诉你结果。
<img src="https://pic4.zhimg.com/50/v2-23609535ca9d95250e61c9399532de9b_hd.jpg" data-caption="" data-size="normal" data-rawwidth="788" data-rawheight="73" class="origin_image zh-lightbox-thumb" width="788" data-original="https://pic4.zhimg.com/v2-23609535ca9d95250e61c9399532de9b_r.jpg">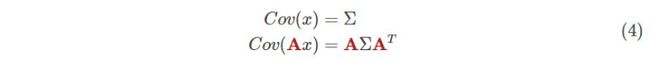
结合(4)和(3):
<img src="https://pic4.zhimg.com/50/v2-b6f39e77cf5fa5d1bd0d5fb42f95f125_hd.jpg" data-caption="" data-size="normal" data-rawwidth="790" data-rawheight="72" class="origin_image zh-lightbox-thumb" width="790" data-original="https://pic4.zhimg.com/v2-b6f39e77cf5fa5d1bd0d5fb42f95f125_r.jpg">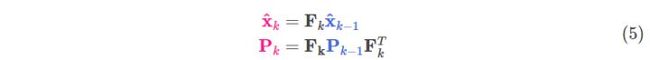
外界作用力
我们并没有考虑到所有影响因素。系统状态的改变并不只依靠上一个系统状态,外界作用力可能会影响系统状态的变化。
例如,跟踪一列火车的运动状态,火车驾驶员可能踩了油门使火车提速。同样,在我们机器人例子中,导航软件可能发出一些指令启动或者制动轮子。如果我们知道这些额外的信息,我们可以通过一个向量 来描述这些信息,把它添加到我们的预测方程里作为一个修正。
假如我们通过发出的指令得到预期的加速度a,上边的运动方程可以变化为:
<img src="https://pic4.zhimg.com/50/v2-b06a9cfebcd25e34fb0e9a90c2d9129b_hd.jpg" data-caption="" data-size="normal" data-rawwidth="287" data-rawheight="73" class="content_image" width="287">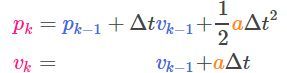
矩阵形式:
<img src="https://pic3.zhimg.com/50/v2-2bf3e12aaeb2475bc3230d0cb30acc2b_hd.jpg" data-caption="" data-size="normal" data-rawwidth="799" data-rawheight="112" class="origin_image zh-lightbox-thumb" width="799" data-original="https://pic3.zhimg.com/v2-2bf3e12aaeb2475bc3230d0cb30acc2b_r.jpg">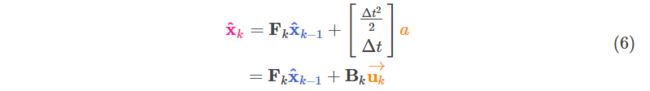
称作控制矩阵, 称作控制向量(没有任何外界动力影响的系统,可以忽略该项)。
我们增加另一个细节,假如我们的预测转换矩阵不是100%准确呢,会发生什么?
外界不确定性
如果状态只会根据系统自身特性演变那将不会有任何问题。如果我们可以把所有外界作用力对系统的影响计算清楚那也不会有任何问题。
但是如果有些外力我们无法预测呢?假如我们在跟踪一个四轴飞行器,它会受到风力影响。如果我们在跟踪一个轮式机器人,轮子可能会打滑,或者地面上的突起会使它降速。我们无法跟踪这些因素,并且这些事情发生的时候上述的预测方程可能会失灵。
我们可以把“世界”中的这些不确定性统一建模,在预测方程中增加一个不确定项。
<img src="https://pic4.zhimg.com/50/v2-3e5d0ea136563cb8b15d7e4af4af1bed_hd.jpg" data-caption="" data-size="normal" data-rawwidth="621" data-rawheight="572" class="origin_image zh-lightbox-thumb" width="621" data-original="https://pic4.zhimg.com/v2-3e5d0ea136563cb8b15d7e4af4af1bed_r.jpg">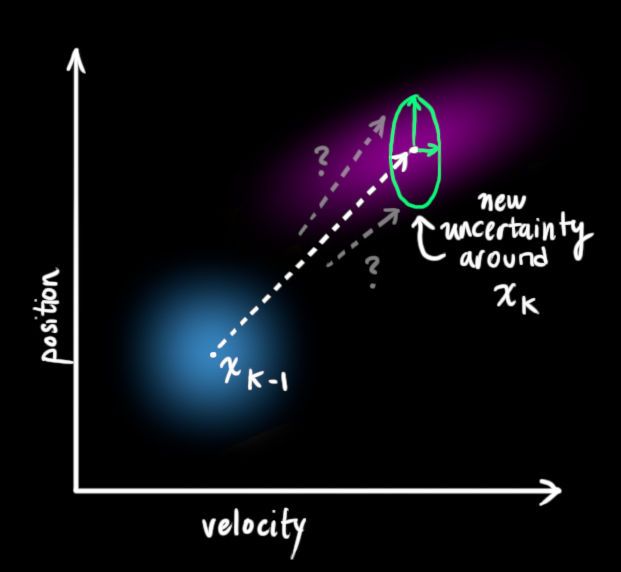
这样,原始状态中的每一个点可以都会预测转换到一个范围,而不是某个确定的点。可以这样描述: 中的每个点移动到一个符合方差 的高斯分布里。另一种说法,我们把这些不确定因素描述为方差为 的高斯噪声。
<img src="https://pic4.zhimg.com/50/v2-1736dbc6bac349f1fd86de3c9e2cc76f_hd.jpg" data-caption="" data-size="normal" data-rawwidth="621" data-rawheight="572" class="origin_image zh-lightbox-thumb" width="621" data-original="https://pic4.zhimg.com/v2-1736dbc6bac349f1fd86de3c9e2cc76f_r.jpg">
这会产生一个新的高斯分布,方差不同,但是均值相同。
<img src="https://pic1.zhimg.com/50/v2-63b04b1e1330df6d2248f9272618ba8b_hd.jpg" data-caption="" data-size="normal" data-rawwidth="621" data-rawheight="621" class="origin_image zh-lightbox-thumb" width="621" data-original="https://pic1.zhimg.com/v2-63b04b1e1330df6d2248f9272618ba8b_r.jpg">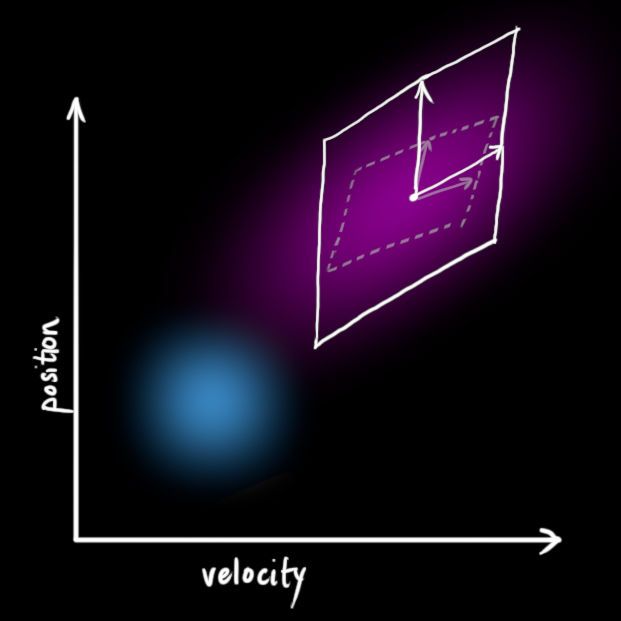
对 简单叠加,可以拿到扩展的方差,这样就得到了完整的预测转换方程。
<img src="https://pic2.zhimg.com/50/v2-ba8b5f1f09232669c8e3b97acf0b1304_hd.jpg" data-caption="" data-size="normal" data-rawwidth="793" data-rawheight="70" class="origin_image zh-lightbox-thumb" width="793" data-original="https://pic2.zhimg.com/v2-ba8b5f1f09232669c8e3b97acf0b1304_r.jpg">
新的预测转换方程只是引入了已知的可以预测的外力影响因素。
新的不确定性可以通过老的不确定性计算得到,通过增加外界无法预测的、不确定的因素成分。
到这里,我们得到了一个模糊的估计范围,一个通过 和 描述的范围。如果再结合我们传感器的数据呢?
通过测量值精炼预测值
我们可能还有一些传感器来测量系统的状态。目前我们不用太关心所测量的状态变量是什么。也许一个测量位置一个测量速度。每个传感器可以提供一些关于系统状态的数据信息,每个传感器检测一个系统变量并且产生一些读数。

注意传感器测量的范围和单位可能与我们跟踪系统变量所使用的范围和单位不一致。我们需要对传感器做下建模:通过矩阵
<img src="https://pic3.zhimg.com/50/v2-e014690db550baa5baaf62d1d6c21e55_hd.jpg" data-caption="" data-size="normal" data-rawwidth="1242" data-rawheight="572" class="origin_image zh-lightbox-thumb" width="1242" data-original="https://pic3.zhimg.com/v2-e014690db550baa5baaf62d1d6c21e55_r.jpg">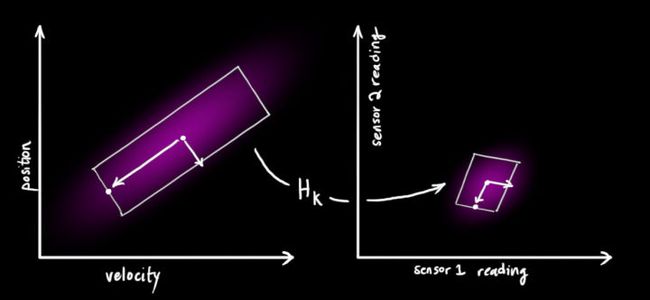
我们可以得到传感器读数分布的范围:
<img src="https://pic4.zhimg.com/50/v2-493e8796ca990f8a946b9ad7149e0fa2_hd.jpg" data-caption="" data-size="normal" data-rawwidth="194" data-rawheight="61" class="content_image" width="194">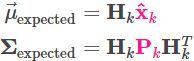
卡尔曼滤波也可以处理传感器噪声。换句话说,我们的传感器有自己的精度范围,对于一个真实的位置和速度,传感器的读数受到高斯噪声影响会使读数在某个范围内波动。
<img src="https://pic2.zhimg.com/50/v2-aaa22652895229c41402d46df09359b9_hd.jpg" data-caption="" data-size="normal" data-rawwidth="1242" data-rawheight="572" class="origin_image zh-lightbox-thumb" width="1242" data-original="https://pic2.zhimg.com/v2-aaa22652895229c41402d46df09359b9_r.jpg">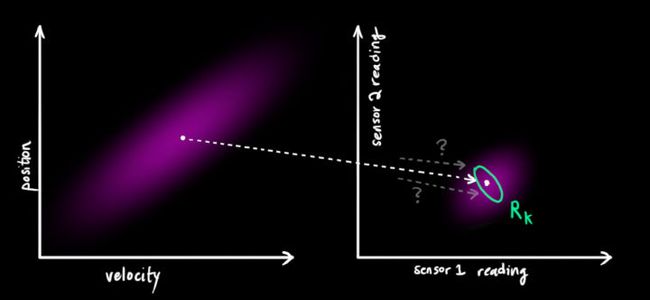
我们观测到的每个数据,可以认为其对应某个真实的状态。但是因为存在不确定性,某些状态的可能性比另外一些可能性更高。
<img src="https://pic4.zhimg.com/50/v2-8f86b40e297d206f439c2c3653357c77_hd.jpg" data-caption="" data-size="normal" data-rawwidth="621" data-rawheight="572" class="origin_image zh-lightbox-thumb" width="621" data-original="https://pic4.zhimg.com/v2-8f86b40e297d206f439c2c3653357c77_r.jpg">
我们将这种不确定性的方差为描述为 。读数的平均值为 。
所以现在我们有了两个高斯斑,一个来自于我们预测值,另一个来自于我们测量值。
<img src="https://pic2.zhimg.com/50/v2-954bea3147c72502022920b95819621b_hd.jpg" data-caption="" data-size="normal" data-rawwidth="621" data-rawheight="572" class="origin_image zh-lightbox-thumb" width="621" data-original="https://pic2.zhimg.com/v2-954bea3147c72502022920b95819621b_r.jpg">
我们必须尝试去把两者的数据预测值(粉色)与观测值(绿色)融合起来。
所以我们得到的新的数据会长什么样子呢?对于任何状态( , ),我们有两个可能性:(1)传感器读数更接近系统真实状态(2)预测值更接近系统真实状态。
如果我们有两个相互独立的获取系统状态的方式,并且我们想知道两者都准确的概率值,我们只需要将两者相乘。所以我们将两个高斯斑相乘。
<img src="https://pic1.zhimg.com/50/v2-5872b13eb9fc87370a8decd02cdf0012_hd.jpg" data-caption="" data-size="normal" data-rawwidth="621" data-rawheight="572" class="origin_image zh-lightbox-thumb" width="621" data-original="https://pic1.zhimg.com/v2-5872b13eb9fc87370a8decd02cdf0012_r.jpg">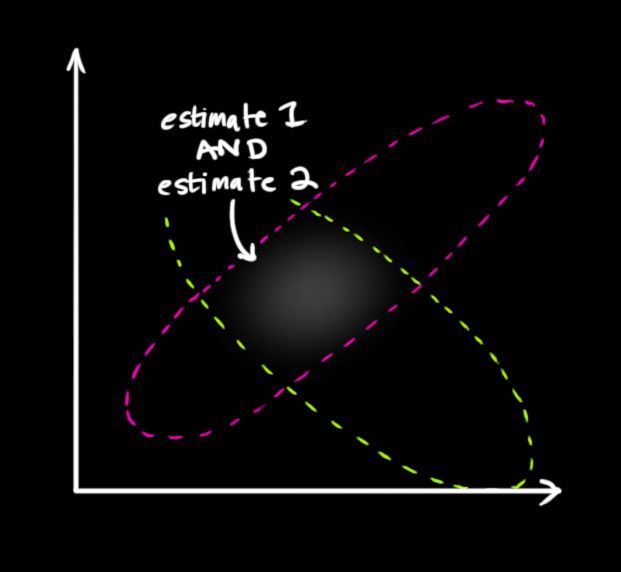
相乘之后得到的即为重叠部分,这个区域同时属于两个高斯斑。并且比单独任何一个区域都要精确。这个区域的平均值取决于我们更取信于哪个数据来源,这样我们也通过我们手中的数据得到了一个最好的估计值。
唔~这看上去像另一个高斯斑。
<img src="https://pic3.zhimg.com/50/v2-3c5dcbb045192ae881e94e732d29eadc_hd.jpg" data-caption="" data-size="normal" data-rawwidth="621" data-rawheight="572" class="origin_image zh-lightbox-thumb" width="621" data-original="https://pic3.zhimg.com/v2-3c5dcbb045192ae881e94e732d29eadc_r.jpg">
已经被证明,当你对两个均值方差都不相同的侧高斯斑进行相乘,你可以得到一个新的高斯斑。你可以自行推导:新高斯分布的均值和方差均可以通过老的均值方差求得。
高斯乘法
我们从一维数据开始,一维高斯(均值u,方差 )被定义为:
<img src="https://pic4.zhimg.com/50/v2-43c007b23557e76ed723f81d1349a38f_hd.jpg" data-caption="" data-size="normal" data-rawwidth="794" data-rawheight="72" class="origin_image zh-lightbox-thumb" width="794" data-original="https://pic4.zhimg.com/v2-43c007b23557e76ed723f81d1349a38f_r.jpg">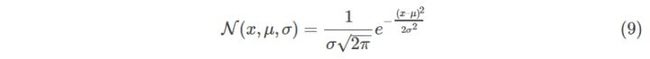
我们想知道两个高斯分布相乘会发生什么。蓝色曲线代表了两个高斯分布的交集部分。
<img src="https://pic4.zhimg.com/50/v2-855027a453eb445e25ba3b8d9b11695c_hd.jpg" data-caption="" data-size="normal" data-rawwidth="589" data-rawheight="381" class="origin_image zh-lightbox-thumb" width="589" data-original="https://pic4.zhimg.com/v2-855027a453eb445e25ba3b8d9b11695c_r.jpg">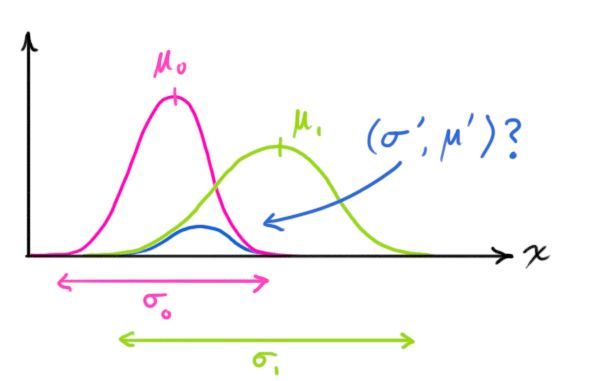 <img src="https://pic2.zhimg.com/50/v2-600338519f642bf90ee7cd5517192c06_hd.jpg" data-caption="" data-size="normal" data-rawwidth="783" data-rawheight="50" class="origin_image zh-lightbox-thumb" width="783" data-original="https://pic2.zhimg.com/v2-600338519f642bf90ee7cd5517192c06_r.jpg">
<img src="https://pic2.zhimg.com/50/v2-600338519f642bf90ee7cd5517192c06_hd.jpg" data-caption="" data-size="normal" data-rawwidth="783" data-rawheight="50" class="origin_image zh-lightbox-thumb" width="783" data-original="https://pic2.zhimg.com/v2-600338519f642bf90ee7cd5517192c06_r.jpg">
把(9)带入(10)然后做一些变换,可以得到
<img src="https://pic3.zhimg.com/50/v2-0f606327c927309a75fd83a774fa8b8d_hd.jpg" data-caption="" data-size="normal" data-rawwidth="791" data-rawheight="136" class="origin_image zh-lightbox-thumb" width="791" data-original="https://pic3.zhimg.com/v2-0f606327c927309a75fd83a774fa8b8d_r.jpg">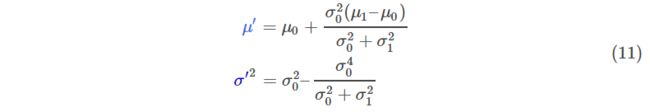
因式分解出一个部分,表示为k
<img src="https://pic1.zhimg.com/50/v2-f8711c565e07598d8fe3b73a54b8ced3_hd.jpg" data-caption="" data-size="normal" data-rawwidth="806" data-rawheight="145" class="origin_image zh-lightbox-thumb" width="806" data-original="https://pic1.zhimg.com/v2-f8711c565e07598d8fe3b73a54b8ced3_r.jpg">
注意你是如何将处理之前的预测值,仅仅是简单将两者叠加相乘就可以得到新的预测值。现在看下这个公式是多么简单。
如果是一个多维矩阵呢?我们将(12)与(13)表示为矩阵形式。Σ表示协方差矩阵, 表示平均向量:
<img src="https://pic2.zhimg.com/50/v2-ae725a6323c7cc68cc97541ad23e8c50_hd.jpg" data-caption="" data-size="normal" data-rawwidth="789" data-rawheight="121" class="origin_image zh-lightbox-thumb" width="789" data-original="https://pic2.zhimg.com/v2-ae725a6323c7cc68cc97541ad23e8c50_r.jpg">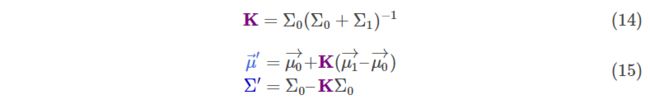
K被称为卡尔曼增益,待会会用到。
简单,我们快结束了。
综合所有信息
我们有两个独立的维度去估计系统状态:
预测值
<img src="https://pic3.zhimg.com/50/v2-02ffc20a54ab9a6369296c7bfe5445a9_hd.jpg" data-caption="" data-size="normal" data-rawwidth="265" data-rawheight="29" class="content_image" width="265">测量值
<img src="https://pic3.zhimg.com/50/v2-af1a4335091562cd6e986a49ad9916e1_hd.jpg" data-caption="" data-size="normal" data-rawwidth="179" data-rawheight="27" class="content_image" width="179">将两者相乘带入(15)寻找他们的重叠区域:
<img src="https://pic3.zhimg.com/50/v2-b1b989067590d04a4121bf56546955f9_hd.jpg" data-caption="" data-size="normal" data-rawwidth="781" data-rawheight="71" class="origin_image zh-lightbox-thumb" width="781" data-original="https://pic3.zhimg.com/v2-b1b989067590d04a4121bf56546955f9_r.jpg">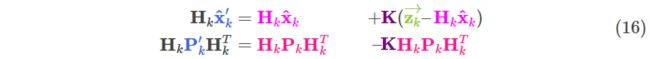
从(14)可知,卡尔曼增益为
<img src="https://pic2.zhimg.com/50/v2-53849d812636be845b7f4af3b74d05a5_hd.jpg" data-caption="" data-size="normal" data-rawwidth="789" data-rawheight="42" class="origin_image zh-lightbox-thumb" width="789" data-original="https://pic2.zhimg.com/v2-53849d812636be845b7f4af3b74d05a5_r.jpg">将(16)中的 从两边约去,注意(17)中的K也包含 。得到
<img src="https://pic2.zhimg.com/50/v2-76922f0cb82b518aa6533286fde09117_hd.jpg" data-caption="" data-size="normal" data-rawwidth="792" data-rawheight="105" class="origin_image zh-lightbox-thumb" width="792" data-original="https://pic2.zhimg.com/v2-76922f0cb82b518aa6533286fde09117_r.jpg">
至此,我们得到了每个状态的更新步骤 是我们最佳的预测值,我们可以持续迭代(独立于 )。
<img src="https://pic1.zhimg.com/50/v2-77564014db4bb16a4cdb87334c77df92_hd.jpg" data-caption="" data-size="normal" data-rawwidth="850" data-rawheight="1100" class="origin_image zh-lightbox-thumb" width="850" data-original="https://pic1.zhimg.com/v2-77564014db4bb16a4cdb87334c77df92_r.jpg">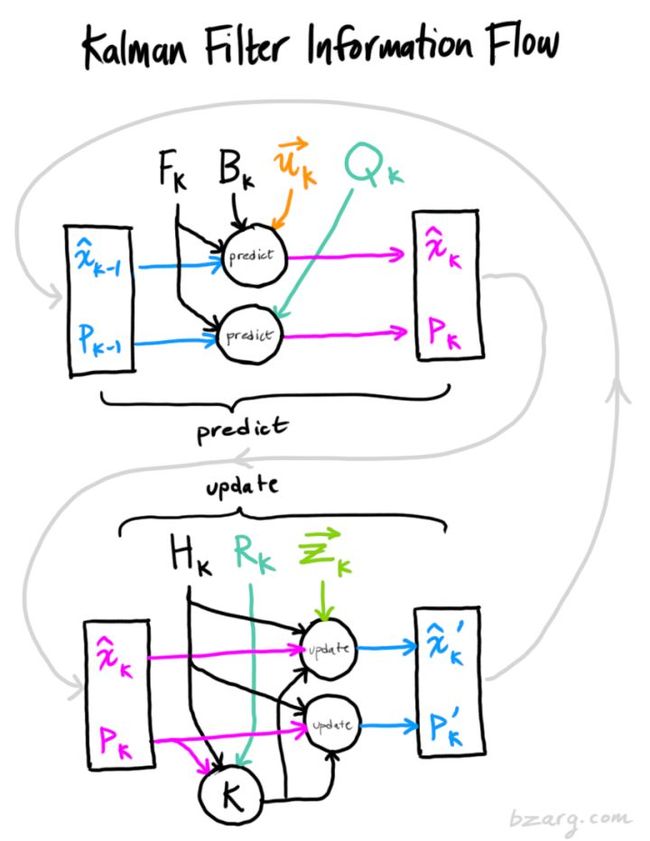
总结
以上所有公式,仅需要实现(7)(18)(19)
这使你可以对任何线性系统建模。对于非线性系统,可以使用扩展卡尔曼滤波,只是对观测值和预测值的平均值进行简单线性化。(我可能会对非线性卡尔曼再写一篇博客)
如果我可以利用卡尔曼解决我的问题,那么希望读者也可以认识到这有多酷,并且在某个新的领域将它实用。
更多参考资料可以去看http://www.cl.cam.ac.uk/~rmf25/papers/Understanding%20the%20Basis%20of%20the%20Kalman%20Filter.pdf 这里采用了相似的方法介绍卡尔曼。这里进行了更深层的介绍,如果你有兴趣的话。