Zynq Axidma linux下驱动axidmatest.c 驱动分析
本文的部分内容可能来源于网络,该内容归原作者所有,如果侵犯到您的权益,请及时通知我,我将立即删除,原创内容copyleft归[email protected]所有,使用GPL发布,可以自由拷贝,转载。但转载请保持文档的完整性,注明原作者及原链接,严禁用于任何商业用途。欢迎加入zynq-arm-linux提高交流群:788265722
文档错误可能很多,大家多包涵,主要理解文件的目的就好。可留言
Zynq-axidma是大家常用的功能,所以,很多同学都用到,但是有很大一部分同学比较熟悉裸跑下axidma使用,网络上也有很多这方面的教程,像米联客AXI_DMA_LOOP 环路测试,但是linux下使用axidma的使用方法却很少,所以才有了今天这个博文,
阅读这篇博文之前,大家可以参考以下博客内容,为理解linux下axi dma使用做铺垫。
Axidma 裸跑例子(更多的可以百度)
AXI_DMA_LOOP 环路测
https://www.cnblogs.com/milinker/p/6484011.html
https://blog.csdn.net/long_fly/article/details/79702222
AXI_DMA_LOOP,在viviado图里有两部分,一个是axidma模块,一个是数据回环模块,首先,用户通过写dma下发一个数据,比方1234,然后用户通过读dma读取数据读到1234,表示测试完成,这里面其实有两个dma通道一个写一个读做了两次dma操作,读写都是由用户发起的,搬运都是dma控制器执行的如下图:
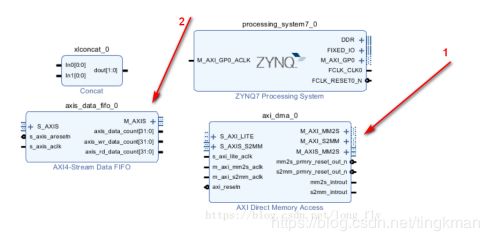
在linux下驱动主要牵涉的文件有3个,一个是设备文件描述dtb,一个是axidma控制器驱动xilinx_dma.c,一个是axidmatest.c,我们今天的主角就是axidmatest.c
Xilinx官网给的axidma驱动说明在这里大家可以看看
https://xilinx-wiki.atlassian.net/wiki/spaces/A/pages/18842337/Linux+Soft+DMA+Driver
各个文件的位置如下:
内核目录
https://github.com/Xilinx/linux-xlnx/blob/master/arch/arm/boot/dts/zynq-zc706.c,这个是官网评估板的dtb描述,原版的dtb里面没有dma的描述,要把dma的描述加进来
https://github.com/Xilinx/linux-xlnx/blob/master/drivers/dma/xilinx/xilinx_dma.c
https://github.com/Xilinx/linux-xlnx/blob/master/drivers/dma/xilinx/axidmatest.c
在设备树里表示dma读写通道,用以下表示
dma-channel@40400000 axi-dma-mm2s-channel 写通道,是ddr网datafifo写
dma-channel@40400030 axi-dma-s2mm-channel 读通道 是datafifo往ddr搬
这个描述对应的是控制器驱动xilinx_dma.c,有这个
描述xilinx_dma.c这个驱动才会加载。
| axi_dma_1: dma@40400000 { #dma-cells = <1>; clock-names = "s_axi_lite_aclk", "m_axi_sg_aclk", "m_axi_mm2s_aclk", "m_axi_s2mm_aclk"; clocks = <&clkc 15>, <&clkc 15>, <&clkc 15>, <&clkc 15>; compatible = "xlnx,axi-dma-1.00.a"; interrupt-parent = <&intc>; interrupts = <0 29 4 0 30 4>; reg = <0x40400000 0x10000>; xlnx,addrwidth = <0x20>; xlnx,include-sg ; dma-channel@40400000 { compatible = "xlnx,axi-dma-mm2s-channel"; dma-channels = <0x1>; interrupts = <0 29 4>; xlnx,datawidth = <0x20>; xlnx,device-id = <0x0>; xlnx,include-dre ; }; dma-channel@40400030 { compatible = "xlnx,axi-dma-s2mm-channel"; dma-channels = <0x1>; interrupts = <0 30 4>; xlnx,datawidth = <0x20>; xlnx,device-id = <0x0>; xlnx,include-dre ; }; }; |
在linux里驱动是分层的,一般像spi i2c dma这类的驱动都是分控制器驱动,和下面的设备驱动,控制器是单独的驱动,下面挂的设备是设备的驱动,设备的驱动都是去想控制器去申请的。
那么今天的主题设备驱动axidmatest.c也在设备树里面有自己的描述,我们看到它用了两个dma通道,就是dma控制器的两个读写通道。
axidmatest_1: axidmatest@1 {
compatible ="xlnx,axi-dma-test-1.00.a";
dmas = <&axi_dma_1 0
&axi_dma_1 1>;
dma-names = "axidma0", "axidma1";
} ;
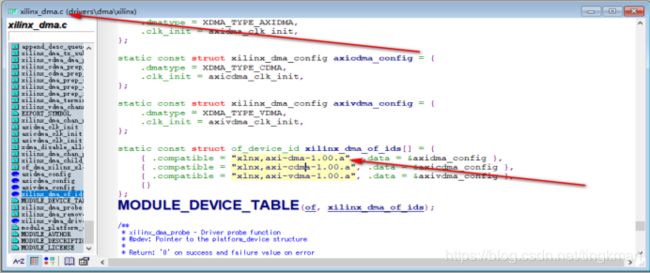
这里设备树和驱动是怎么对应的那,linux采用的是compatible里面的描述
控制器 compatible = "xlnx,axi-dma-1.00.a";
测试程序驱动compatible ="xlnx,axi-dma-test-1.00.a";
驱动程序表示如下:
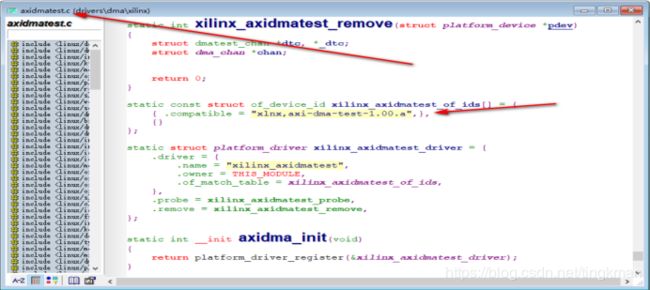
这样写好,还要把内核配置也配置好,这些驱动才都能加载
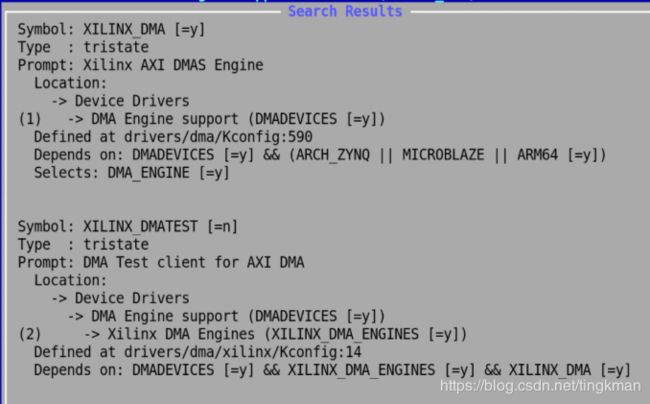
在写dma驱动我们不用关注xilinx_dma.c驱动的实现,只需要理解axidmatest.c的实现,下面就分析一下:axidmatest.c这个驱动。
那么从哪里开始分析那,我们知道一般程序都有个入口,比方说main函数,那在linux下axidmatest.c入口就是以下函数。
late_initcall这个意思大概意思就是后面初始化,实际上dma控制器xilinx_dma.c实在测试驱动axidmatest.c之前运行的,因为测试驱动要去向控制器申请通道,所以控制器要先初始化好,才能给测试驱动提供通道。
| static int __init axidma_init(void) { return platform_driver_register(&xilinx_axidmatest_driver); } late_initcall(axidma_init);
|
| static const struct of_device_id xilinx_axidmatest_of_ids[] = { { .compatible = "xlnx,axi-dma-test-1.00.a",}, {} }; static struct platform_driver xilinx_axidmatest_driver = { .driver = { .name = "xilinx_axidmatest", .owner = THIS_MODULE, .of_match_table = xilinx_axidmatest_of_ids, }, .probe = xilinx_axidmatest_probe, .remove = xilinx_axidmatest_remove, }; |
axidma_init其实使用platform_driver_register,加载平台设备驱动xilinx_axidmatest_driver,
平台设备驱动有几个描述driver和probe,remove函数,remove函数是在驱动程序卸载才会执行,这里一般内核启动后不会卸载。当xilinx_axidmatest_of_ids里面的compatible和设备树描述文件dtb里面的对应后probe就会运行
axidmatest_1: axidmatest@1 {
compatible ="xlnx,axi-dma-test-1.00.a";
dmas = <&axi_dma_1 0
&axi_dma_1 1>;
dma-names = "axidma0", "axidma1";
} ;
当probe函数xilinx_axidmatest_probe才开始测试驱动的初始化。
dma_request_slave_channel是linux驱动编写的标准函数,dma测试程序申请dma通道要用这个函数,具体实现我们可以不管,只需要用这个申请就可以了,当然了,控制器驱动已经准备好了,才能申请成功。
|
static int xilinx_axidmatest_probe(struct platform_device *pdev) { struct dma_chan *chan, *rx_chan; int err; chan = dma_request_slave_channel(&pdev->dev, "axidma0"); //---------------------向控制器申请dma发送通道 if (IS_ERR(chan)) { pr_err("xilinx_dmatest: No Tx channel\n"); return PTR_ERR(chan); } rx_chan = dma_request_slave_channel(&pdev->dev, "axidma1"); //---------------------向控制器申请dma接收通道
if (IS_ERR(rx_chan)) { err = PTR_ERR(rx_chan); pr_err("xilinx_dmatest: No Rx channel\n"); goto free_tx; } err = dmatest_add_slave_channels(chan, rx_chan); if (err) { pr_err("xilinx_dmatest: Unable to add channels\n"); goto free_rx; } return 0; free_rx: dma_release_channel(rx_chan); free_tx: dma_release_channel(chan); return err; } |
dmatest_add_slave_channels(chan, rx_chan)函数进一步初始化。
定义两个dmatest_chan类型的数据结构tx_dtc,rx_dtc用来保存之前申请的两个通道,后面就用这两个数据接口来访问通道。
| static int dmatest_add_slave_channels(struct dma_chan *tx_chan, struct dma_chan *rx_chan) { struct dmatest_chan *tx_dtc; struct dmatest_chan *rx_dtc; unsigned int thread_count = 0;
tx_dtc = kmalloc(sizeof(struct dmatest_chan), GFP_KERNEL); if (!tx_dtc) { pr_warn("dmatest: No memory for tx %s\n", dma_chan_name(tx_chan)); return -ENOMEM; } rx_dtc = kmalloc(sizeof(struct dmatest_chan), GFP_KERNEL); if (!rx_dtc) { pr_warn("dmatest: No memory for rx %s\n", dma_chan_name(rx_chan)); return -ENOMEM; } tx_dtc->chan = tx_chan; rx_dtc->chan = rx_chan; INIT_LIST_HEAD(&tx_dtc->threads); INIT_LIST_HEAD(&rx_dtc->threads);
dmatest_add_slave_threads(tx_dtc, rx_dtc); thread_count += 1;
pr_info("dmatest: Started %u threads using %s %s\n", thread_count, dma_chan_name(tx_chan), dma_chan_name(rx_chan));
list_add_tail(&tx_dtc->node, &dmatest_channels); list_add_tail(&rx_dtc->node, &dmatest_channels); nr_channels += 2;
if (iterations) wait_event(thread_wait, !is_threaded_test_run(tx_dtc, rx_dtc));
return 0; } |
dmatest_add_slave_threads实际上是创建了一个内核任务,这个任务才是发起dma操作的,
在linux-dma测试程序中发起dma请求,都是由标准的函数,我们写的时候也要用到这些函数
这里要了解一些linuxdma的相关知识,这里找几篇博客参考
http://www.wowotech.net/linux_kenrel/dma_engine_overview.html
http://www.wowotech.net/linux_kenrel/dma_engine_api.html
https://www.cnblogs.com/xiaojiang1025/archive/2017/02/11/6389194.html
Dma驱动一般分两种,一种是一致性dma一种是流式dma,本文用的dma是流式的。
相关函数如下:
dma_map_single
sg_init_table(tx_sg, bd_cnt);
sg_dma_address
sg_dma_len
device_prep_slave_sg
rxd->tx_submit
dmatest_slave_func函数基本流程我先概况一下:
先通过准备数据通过写通道dma发送给datafifo,然后在通过读通道dma从datafifo读出来,对比发送的数据是否和接收的数据一致,一致则认为测试通过,循环做几次测试
| static int dmatest_slave_func(void *data)函数分析
|
| static int dmatest_slave_func(void *data) { struct dmatest_slave_thread *thread = data; struct dma_chan *tx_chan; struct dma_chan *rx_chan; const char *thread_name; unsigned int src_off, dst_off, len; unsigned int error_count; unsigned int failed_tests = 0; unsigned int total_tests = 0; dma_cookie_t tx_cookie; dma_cookie_t rx_cookie; enum dma_status status; enum dma_ctrl_flags flags; int ret; int src_cnt; int dst_cnt; int bd_cnt = 11; int i;
ktime_t ktime, start, diff; ktime_t filltime = 0; ktime_t comparetime = 0; s64 runtime = 0; unsigned long long total_len = 0; thread_name = current->comm; ret = -ENOMEM;
/* Ensure that all previous reads are complete */ smp_rmb(); tx_chan = thread->tx_chan; rx_chan = thread->rx_chan; dst_cnt = bd_cnt; //这里为11,实际上是创建11个sg,sg支持多个分块dma传输,这里可以改成1,就一块 src_cnt = bd_cnt; //申请发送缓冲区数据结构,
thread->srcs = kcalloc(src_cnt + 1, sizeof(u8 *), GFP_KERNEL); if (!thread->srcs) goto err_srcs; //申请发送缓冲区,这里面放发送的数据,往datafifo发送的数据
for (i = 0; i < src_cnt; i++) { thread->srcs[i] = kmalloc(test_buf_size, GFP_KERNEL); if (!thread->srcs[i]) goto err_srcbuf; } thread->srcs[i] = NULL; //申请接收缓冲区数据结构, thread->dsts = kcalloc(dst_cnt + 1, sizeof(u8 *), GFP_KERNEL); if (!thread->dsts) goto err_dsts;
//申请接收缓冲区,这里是dma从datafifo搬运的数据放到这里,
for (i = 0; i < dst_cnt; i++) { thread->dsts[i] = kmalloc(test_buf_size, GFP_KERNEL); if (!thread->dsts[i]) goto err_dstbuf; } thread->dsts[i] = NULL;
set_user_nice(current, 10);
flags = DMA_CTRL_ACK | DMA_PREP_INTERRUPT;
ktime = ktime_get(); while (!kthread_should_stop() && !(iterations && total_tests >= iterations)) { struct dma_device *tx_dev = tx_chan->device; struct dma_device *rx_dev = rx_chan->device; struct dma_async_tx_descriptor *txd = NULL; struct dma_async_tx_descriptor *rxd = NULL; dma_addr_t dma_srcs[src_cnt]; dma_addr_t dma_dsts[dst_cnt]; struct completion rx_cmp; struct completion tx_cmp; unsigned long rx_tmo = msecs_to_jiffies(300000); /* RX takes longer */ unsigned long tx_tmo = msecs_to_jiffies(30000); u8 align = 0; struct scatterlist tx_sg[bd_cnt]; //定义发送dma数据结构, struct scatterlist rx_sg[bd_cnt]; //定义接收dma数据结构,
total_tests++; //----------------字节对齐,dma传输要求字节对齐 /* honor larger alignment restrictions */ align = tx_dev->copy_align; if (rx_dev->copy_align > align) align = rx_dev->copy_align;
if (1 << align > test_buf_size) { pr_err("%u-byte buffer too small for %d-byte alignment\n", test_buf_size, 1 << align); break; }
len = dmatest_random() % test_buf_size + 1; len = (len >> align) << align; if (!len) len = 1 << align; total_len += len; src_off = dmatest_random() % (test_buf_size - len + 1); dst_off = dmatest_random() % (test_buf_size - len + 1);
src_off = (src_off >> align) << align; dst_off = (dst_off >> align) << align;
start = ktime_get(); dmatest_init_srcs(thread->srcs, src_off, len); dmatest_init_dsts(thread->dsts, dst_off, len); //----------------字节对齐,dma传输要求字节对齐
diff = ktime_sub(ktime_get(), start); filltime = ktime_add(filltime, diff);
for (i = 0; i < src_cnt; i++) { u8 *buf = thread->srcs[i] + src_off; //dma映射后获取的物理地址,实际上dma初始化用的是物理地址,thread->srcs[i] 这个是虚拟地址,是程序可以直接使用的,但是dma用的是物理地址 dma_srcs[i] = dma_map_single(tx_dev->dev, buf, len, DMA_MEM_TO_DEV); }
for (i = 0; i < dst_cnt; i++) { //dma映射后获取的物理地址,实际上dma初始化用的是物理地址,thread->srcs[i] 这个是虚拟地址,是程序可以直接使用的,但是dma用的是物理地址
dma_dsts[i] = dma_map_single(rx_dev->dev, thread->dsts[i], test_buf_size, DMA_BIDIRECTIONAL); } //初始化发送接收数据结构---------------------- sg_init_table(tx_sg, bd_cnt); sg_init_table(rx_sg, bd_cnt);
for (i = 0; i < bd_cnt; i++) { sg_dma_address(&tx_sg[i]) = dma_srcs[i]; //物理地址 sg_dma_address(&rx_sg[i]) = dma_dsts[i] + dst_off;
sg_dma_len(&tx_sg[i]) = len; //dma一次传输的长度 sg_dma_len(&rx_sg[i]) = len; } //准备发送 接收sg rxd = rx_dev->device_prep_slave_sg(rx_chan, rx_sg, bd_cnt, DMA_DEV_TO_MEM, flags, NULL);
txd = tx_dev->device_prep_slave_sg(tx_chan, tx_sg, bd_cnt, DMA_MEM_TO_DEV, flags, NULL);
if (!rxd || !txd) { for (i = 0; i < src_cnt; i++) dma_unmap_single(tx_dev->dev, dma_srcs[i], len, DMA_MEM_TO_DEV); for (i = 0; i < dst_cnt; i++) dma_unmap_single(rx_dev->dev, dma_dsts[i], test_buf_size, DMA_BIDIRECTIONAL); pr_warn("%s: #%u: prep error with src_off=0x%x ", thread_name, total_tests - 1, src_off); pr_warn("dst_off=0x%x len=0x%x\n", dst_off, len); msleep(100); failed_tests++; continue; } //接收的dma,先准备接收的 init_completion(&rx_cmp); rxd->callback = dmatest_slave_rx_callback;//dma搬运完这个函数会运行 rxd->callback_param = &rx_cmp; rx_cookie = rxd->tx_submit(rxd);
//发送的dma, init_completion(&tx_cmp); txd->callback = dmatest_slave_tx_callback;//dma搬运完这个函数会运行 txd->callback_param = &tx_cmp; tx_cookie = txd->tx_submit(txd);
if (dma_submit_error(rx_cookie) || dma_submit_error(tx_cookie)) { pr_warn("%s: #%u: submit error %d/%d with src_off=0x%x ", thread_name, total_tests - 1, rx_cookie, tx_cookie, src_off); pr_warn("dst_off=0x%x len=0x%x\n", dst_off, len); msleep(100); failed_tests++; continue; } dma_async_issue_pending(rx_chan); dma_async_issue_pending(tx_chan); //--dma_async_issue_pending这个执行后就相当于给dma控制器发命令了,dma控制器就会根据我们提供的参数来自己搬运数据了
tx_tmo = wait_for_completion_timeout(&tx_cmp, tx_tmo); //等待发送dma传输完 等completion status = dma_async_is_tx_complete(tx_chan, tx_cookie, NULL, NULL);
if (tx_tmo == 0) { pr_warn("%s: #%u: tx test timed out\n", thread_name, total_tests - 1); failed_tests++; continue; } else if (status != DMA_COMPLETE) { pr_warn("%s: #%u: tx got completion callback, ", thread_name, total_tests - 1); pr_warn("but status is \'%s\'\n", status == DMA_ERROR ? "error" : "in progress"); failed_tests++; continue; }
rx_tmo = wait_for_completion_timeout(&rx_cmp, rx_tmo); //等待接收传输完 status = dma_async_is_tx_complete(rx_chan, rx_cookie, NULL, NULL);
if (rx_tmo == 0) { pr_warn("%s: #%u: rx test timed out\n", thread_name, total_tests - 1); failed_tests++; continue; } else if (status != DMA_COMPLETE) { pr_warn("%s: #%u: rx got completion callback, ", thread_name, total_tests - 1); pr_warn("but status is \'%s\'\n", status == DMA_ERROR ? "error" : "in progress"); failed_tests++; continue; } //前面是先映射,这里是解除映射,这样缓冲区的数据才是正确的,不执行这个操作,缓冲区数据不对。 /* Unmap by myself */ for (i = 0; i < dst_cnt; i++) dma_unmap_single(rx_dev->dev, dma_dsts[i], test_buf_size, DMA_BIDIRECTIONAL);
error_count = 0; start = ktime_get(); pr_debug("%s: verifying source buffer...\n", thread_name); error_count += dmatest_verify(thread->srcs, 0, src_off, 0, PATTERN_SRC, true); error_count += dmatest_verify(thread->srcs, src_off, src_off + len, src_off, PATTERN_SRC | PATTERN_COPY, true); error_count += dmatest_verify(thread->srcs, src_off + len, test_buf_size, src_off + len, PATTERN_SRC, true);
pr_debug("%s: verifying dest buffer...\n", thread->task->comm); //--校验接收的数据和发送的数据, error_count += dmatest_verify(thread->dsts, 0, dst_off, 0, PATTERN_DST, false); error_count += dmatest_verify(thread->dsts, dst_off, dst_off + len, src_off, PATTERN_SRC | PATTERN_COPY, false); error_count += dmatest_verify(thread->dsts, dst_off + len, test_buf_size, dst_off + len, PATTERN_DST, false); diff = ktime_sub(ktime_get(), start); comparetime = ktime_add(comparetime, diff);
if (error_count) { pr_warn("%s: #%u: %u errors with ", thread_name, total_tests - 1, error_count); pr_warn("src_off=0x%x dst_off=0x%x len=0x%x\n", src_off, dst_off, len); failed_tests++; } else { pr_debug("%s: #%u: No errors with ", thread_name, total_tests - 1); pr_debug("src_off=0x%x dst_off=0x%x len=0x%x\n", src_off, dst_off, len); } }
ktime = ktime_sub(ktime_get(), ktime); ktime = ktime_sub(ktime, comparetime); ktime = ktime_sub(ktime, filltime); runtime = ktime_to_us(ktime);
ret = 0; for (i = 0; thread->dsts[i]; i++) kfree(thread->dsts[i]); err_dstbuf: kfree(thread->dsts); err_dsts: for (i = 0; thread->srcs[i]; i++) kfree(thread->srcs[i]); err_srcbuf: kfree(thread->srcs); err_srcs: pr_notice("%s: terminating after %u tests, %u failures %llu iops %llu KB/s (status %d)\n", thread_name, total_tests, failed_tests, dmatest_persec(runtime, total_tests), dmatest_KBs(runtime, total_len), ret);
thread->done = true; wake_up(&thread_wait);
return ret; } |
|
|
至此,axidmatest.c主要部分就是这个任务,所以,把这个搞明白就行,还有一点数据准备这块有个字节对齐,有点麻烦,容易搞不清楚,可以使用__get_free_pages申请缓冲区,这种函数本身就是对齐的,还有,这种流式的dma要先dma_map_single传输完后还要dma_unmap_single后才能去读传输的数据,这种函数我测试数据量小的话好用,如果很大的话,就比较花时间,一致性dma就不用这样。后面有时间吧这个改造一下,做一致性的dma,写的尽量简单能用,能理解大概就行。