史上最浅显易懂的KMP算法讲解:字符串匹配算法
KMP算法是一种改进后的字符串匹配算法,由D.E.Knuth与V.R.Pratt和J.H.Morris同时发现,因此人们称它为克努特-莫里斯-普拉特操作(简称KMP算法)。
KMP算法又称“看毛片”算法,是一个效率非常高的字符串匹配算法。相信很多人初识KMP算法的时候始终是丈二和尚摸不着头脑,要么完全不知所云,下面将结合本人的理解,用最浅显易懂的方法解释一下KMP算法。
首先为什么要使用KMP,比如abc这个串找它在abababbcabcac这个串中第一次出现的位置,那么如果直接暴力双重循环的话,abc的c不匹配母串中的第三个字母a后,abc将开始从母串中的头位置的下一个位置开始寻找,就是abc开始匹配母串中第二个字母bab...这样,而KMP的优势就在于可以让模式串向右滑动尽可能多的距离就是abc直接从模式串的第三个字母aba...开始匹配,为了实现这一目标,KMP需要预处理出模式串的移位跳转next数组。
1. KMP算法完成的任务是:给定两个字符串S和M,长度分别为n和m,判断M是否在S中出现,如果出现则返回出现的位置。常规方法是遍历S的每一个位置,然后从该位置开始和M进行匹配,但是这种方法的复杂度是O(nm)。KMP算法通过计算移位跳转表next[...],使匹配的复杂度降为O(n+m)。
我们首先用一个图来描述kmp算法的思想。在字符串S中寻找M,假设匹配到位置i时两个字符才出现不相等(i位置前的字符都相等),这时我们需要将字符串M向右移动。常规方法是每次向右移动一位,但是它没有考虑前i-1位已经比较过这个事实,所以效率不高。事实上,如果我们提前计算某些信息,就有可能一次右移多位。假设我们根据已经获得的信息知道可以右移x位,我们分析移位前后的M的特点,可以得到如下的结论:
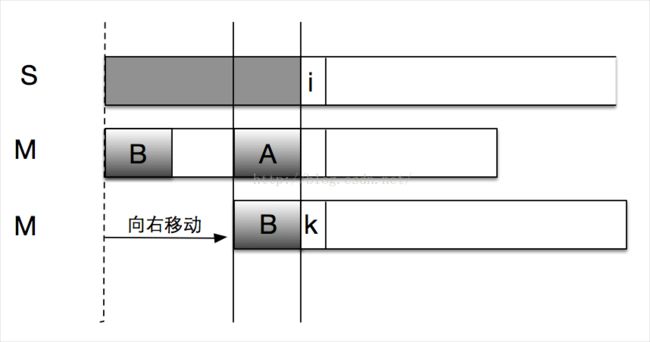
- B段字符串是M的一个前缀
- A段字符串是M的一个后缀
- A段字符串和B段字符串相等
2. KMP算法的核心思想:
所以KMP算法的核心即是计算字符串M每一个位置之前的字符串的前缀和后缀公共部分的最大长度。获得M每一个位置的最大公共长度之后,就可以利用该最大公共长度快速和字符串S比较。当每次比较到两个字符串的字符不同时,我们就可以根据最大公共长度将字符串M向右移动,接着继续比较下一个位置。
3. KMP算法关键难点就是弄清楚如何计算next数组 :为方便起见,next数组下标都从1开始,M数组下标依然从0开始
假设我们现在已经求得next[1]、next[2]、……next[i],分别表示不同长度子串的前缀和后缀最大公共长度,下面介绍如何用归纳法计算next[i+1] ?
假设k=next[i],它表示M位置i之前的字符串的前缀和后缀最大公共长度,即M[0...k-1] = M[i-k...i-1];
(1)若M[k] = M[i]相等, 则必定有next[i+1] = next[i] +1,即M位置i+1之前的字符串的前缀和后缀最大公共长度为k+1
为什么呢?也许你会半信半疑,下面用假设排除法来验证。
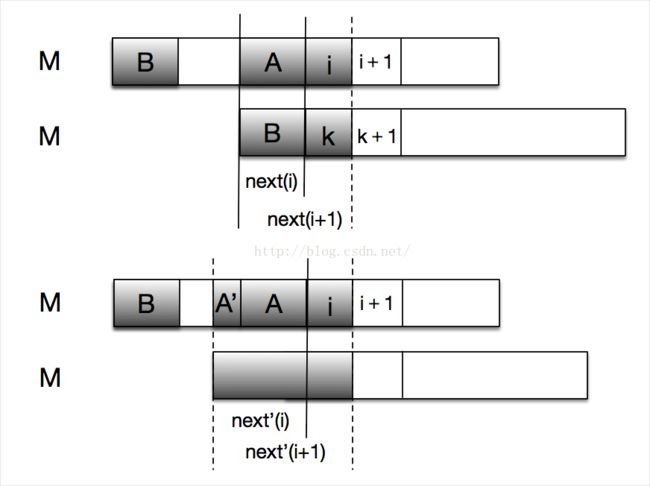
如上有两幅图,第一幅表示当M[k] = M[i]相等时,next[i+1] = next[i] +1;
第二幅假设next'[i+1] > next[i] +1成立,则两条虚线之间的阴影重叠长度肯定比第一幅图中大,从图中可以看出next'(i) = A + A‘ 的长度,而实际上next(i) = A的长度,且是最大长度,next'(i) = A + A‘ 是不可能的。因此假设不成立,则next[i+1] 的最大长度只能是 next[i] +1;
(2)若M[k] != M[i] 不相等,为求next[i+1] ,如下图我们需要将M继续往右移动(不能往左移,往左移上面已经用假设排除法验证不成立),获得其最大公共长度next[k], 即为第一条虚线与第二条虚线之间的阴影重叠长度。不难发现,next[k] 其实就是阴影B这段字符串的前缀和后缀最大公共长度,即 next[k] = next[ next[i] ] 。
令 next[k] = j, 继续判断M[i] 与 M[j] 是否相等,如果相等则 next[i+1] = next[k] + 1 = next[ next[i] ] + 1;如果不相等重复步骤(2),继续分割长度为next[ next[k] ]的字符串,直到字符串长度为0为止。
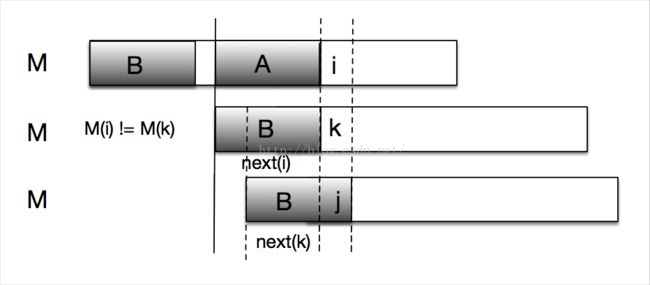
通过上述分析,我门可以总结出next[i]的递推公式:
若 M位置i之前的字符串的前缀和后缀最大公共长度为next[i] = k,即M[0...k-1] = M[i-k...i-1];则对于M位置i+1之前的字符串,则有如下可能
- M[k] == M[i] 此时 next(i+1)=k+1=next(i)+1
- M[k] ≠ M[i] 此时只能在M位置k之前的字符串中匹配,假设j=next(k),如果此时M[j]==M[i],则next(i+1)=j+1,否则重复此步骤,直到字符串长度为0为止
#include
#include
void compute_next(const string& pattern)
{
const int pattern_length = pattern.size();
int *next_function = new int[pattern_length];
int index;
next_function[0] = -1;
for(int i=1;i=0 && pattern[i]!=pattern[index+1])
{
index = next_function[index];
}
if(pattern[i]==pattern[index+1])
{
next_function[i] = index + 1;
}
else
{
next_function[i] = -1;
}
}
for(i=0;i 这样求出来的next数组其实是从下标1开始的,因为下标0之前是个空串,下标1则对应着M串的第0个字符。我们设next[0]=-1,仅仅是个标志而已,没有什么特殊的含义。
-1
-1
0
0
1
-1
0
1
2
Press any key to continue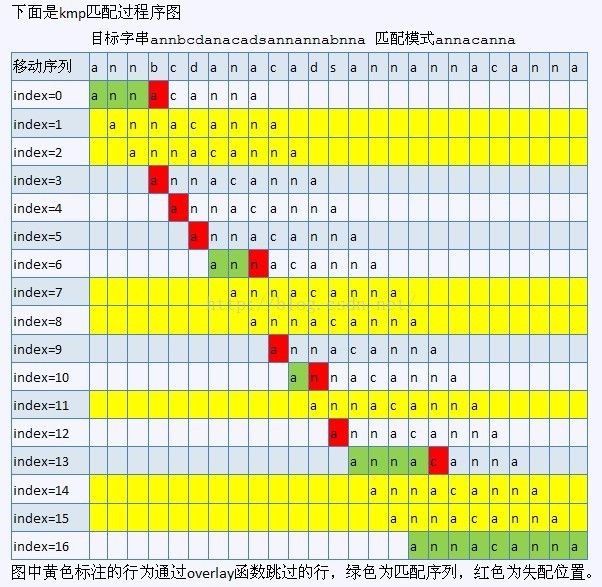
5. 改进型KMP算法:
若引入f(j)作为媒介,对 f(j) 和 next(j) 重新定义如下:
- f(j)是满足pattern[1...k - 1] = pattern[(j - (k - 1))...j -1](k < j)的k中,k的最大值
- next[j]是所有满足pattern[1...k - 1] = pattern[(j - (k - 1))...j -1](k < j),且pattern[k] != pattern[j]的k中,k的最大值
根据定义,f(j)与next[j]的有如下递推公式:
- 如果 pattern[j] != pattern[f(j)],next[j] = f(j);
- 如果 pattern[j] = pattern[f(j)],next[j] = next[f(j)];
可以看出,本篇介绍的next(i) 其实就是f(j), 并不是最优跳转表。通过f(j)可以进一步计算最优的跳转表,最优跳转表对有多个重复字符的pattern[],会表现出非常高的性能!
有关最优跳转表的具体介绍,可以参见文章:http://blog.csdn.net/joylnwang/article/details/6778316