论文阅读《Cascade Residual Learning: A Two-stage Convolutional Neural Network for Stereo Matching》
- 摘要
- 介绍
- 相关工作
- 堆叠残差学习
- 1 两阶段视差计算
- 2 多尺度残差学习
- 3 网络架构
- 实验
- 1 实验设置
- 2 架构对比
- 3 和其他方法比较
- 总结
- 参考文献
摘要
为解决在立体匹配内在的病态区域(目标遮挡、重复模式、无纹理区域等)难产生高质量的视差问题,这篇论文提出一种新颖的由两个阶段组成的堆叠卷积神经网络结构。第一个阶段:利用DispNet,加上额外的能够使视差图获得更多细节的反卷积模块。第二个阶段:修正由第一阶段产生的初始视差,结合第一阶段产生多尺度的残差信号。两个阶段的输出的和给出最终的视差。因此第二个阶段不是直接学习视差,而是通过残差学习提供更有效的精细化。
1 介绍
这篇论文提出的堆叠残差学习(CRL)由两个沙漏结构的卷积神经网络阶段组成。在第一阶段,利用一个简单而不平凡的反卷积模块产生细纹理视差,为第二阶段的残差学习建立一个良好的起点。在第二阶段,视差通过在多尺度产生的残差信号得到修正。学习残差比直接学习视差简单,与ResNet的机制相似。当初始视差已经最优,第二阶段的网络可以简单地产生0残差来保持最优。在ResNet中,残差构建块(residual blocks)一个一个堆叠,每个残差块不能直接监督。与ResNet不同,这篇论文在多个尺度上嵌入残差学习机制,单个残差块可以通过ground-truth视差和初始视差直接差监督,因此带来优秀的视差精细化。
2 相关工作
传统立体匹配算法由四步组成:1)匹配代价计算;2)代价聚合;3)视差计算;4)视差精细化。而基于CNN的视差估计方法映射传统方法的部分或全部步骤,可以大致分为三类:
匹配代价学习:CNNs用来衡量图像块之间的相似性,如MC-CNN、Content-CNN。尽管数据驱动的相似性度量比传承手工制作性能更好,这些方法仍然需要一系列后处理步骤(传统方法的2)-4)步)来产生良好的结果。
正则化学习:视差图通常是分段平滑的,因此一些方法在学习的过程中利用了平滑约束。有些方法用新的值替换不可靠的视差,但这会浪费计算。有些方法则联合目标检测或语义分割来正则化。
端到端的视差学习:DispNet、GC-NET
3 堆叠残差学习
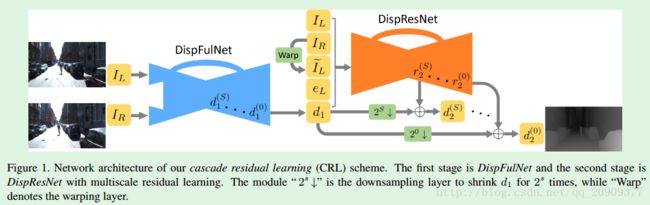
3.1 两阶段视差计算
动机:视差估计和光流估计可以通过事后的迭代精细化来改进。FlowNet2.0使用堆叠的CNNs来精细化光流。
与DispNetC类似,本论文提出的CNN的第一阶段有一个带跳跃连接的沙漏结构。然而,DispNetC输出输入立体图像的半分辨率视差图像。而本论文的网络利用了额外的反卷积模块来放大视差,因此获得与输入图像具有相同尺寸的视差图。第一阶段的网络叫做DispFulNet(Ful表示全分辨率)。DispFulNet在目标的边界提供额外的细节和尖锐的转变,为第二阶段的精细化提供了一个理想的起点。
在本来论文的网络中,第一阶段和第二阶段的堆叠方式同FlowNet2.0。第一个网络输入立体图像对 IL和IR I L 和 I R ,产生左图的初始视差 d1 d 1 。然后根据视差 d1 d 1 扭曲右图像 IR I R ,获得一个合成的左图像,即
然后第二个网络的输入的是concat
IL,IR,d1,I˜L(x,y)和eL=|IL−I˜L(x,y)| I L , I R , d 1 , I ~ L ( x , y ) 和 e L = | I L − I ~ L ( x , y ) | .扭曲操作是可微的双线性插值,使得网络可以端到端训练。
3.2 多尺度残差学习
第二个阶段精细化由第一阶段产生的初始视差。给出初始视差 d1 d 1 ,第二个网络输出对应的残差信号 r2 r 2 ,新的视差为 d2=d1+r2 d 2 = d 1 + r 2 . 因此第二个网络只关注于学习高度非线性的残差。与ResNet一样,如果第一阶段就已经产生了最优的视差,则第二阶段只需输出0残差以保持最优性。
第二阶段也是一个沙漏结构,在多个尺度上产生残差信号,称为DispResNet(Res表示残差)。在DispResNet的扩张部分,网络在多个尺度上产生残差,表示为 {r(s)2}Ss=0 { r 2 ( s ) } s = 0 S ,其中0代表全分辨率尺度。 r(s)2 r 2 ( s ) 和下采样的视差 d(s)1 d 1 ( s ) 的和给出在尺度s上的新视差:
为了训练DispResNet,监督在S+1个尺度上估计的视差 {d(s)2}Ss=0 { d 2 ( s ) } s = 0 S 。
3.3 网络架构
CRL的网络结构如图1所示,其中, d1=d(0)1,最终的视差输出是d(0)2 d 1 = d 1 ( 0 ) , 最 终 的 视 差 输 出 是 d 2 ( 0 ) .为了获得 {d(s)1}Ss=0 { d 1 ( s ) } s = 0 S ,网络中执行了一个可微的双线性下采样层,类似于空间变换网络[1]中的采样器模块。
第一阶段的DispFulNet扩大由DispNetC估计的半分辨率视差到全分辨率。与DispNetC不同的是,本论文在DispNetC的最后两个卷积层后面附加额外的反卷积层,然后把反卷积层的输出和左图像concat在一起。通过对concatenated的3D数组再使用一个卷积层(只有一个输出通道),最终获得DispFulNet的输出——一个全分辨率的视差图。这个全分辨率的视差图和其他在六个不同尺度产生的中间视差图通过与ground-truth计算L1损失进行监督。
(论文中没有给出DispFulNet的详细结构,下表是本人根据自己对论文的理解结合论文代码给出的DispFulNet详细结构,其中黑色部分是DispNetS,DispNetC是在DispNetS的conv2后加了correlation层,最后两行红色部分为DispFulNet与DispNetC的不同点,iconv0就是DispFulNet的输出 d1 d 1 )
DispFulNet

第二阶段的DispResNet的详细说明如下表所示。(其实网络结构和DispNetS还是相似,只是网络主要关注于学习残差,而不是直接学习视差)
DispResNet
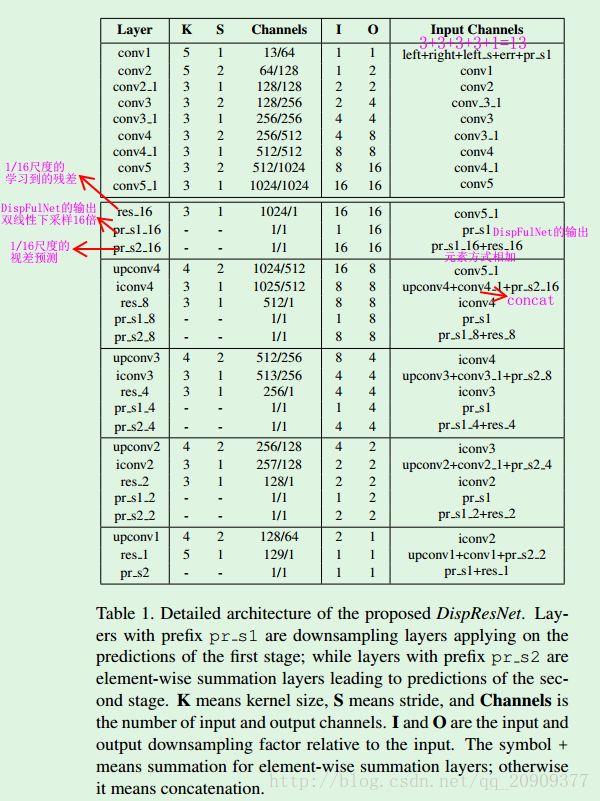
本论文旨在建立一个两阶段的网络,第一阶段设法产生一个全分辨率的初始视差,而第二阶段通过残差学习尽可能精细化初始视差。两个阶段分别扮演自己的角色,并且彼此结。
4 实验
4.1 实验设置
使用了三个数据集:
(1)FlyingThings3D :这个数据集有些图像的视差大的不合常理,因此移除一张图片中有超过25%的像素的视差大于300的图像。
(2)Middlebury 2014:只用于测试
(3)KITTI 2015:200张训练集的170张用于训练,剩下的用于验证。
训练:
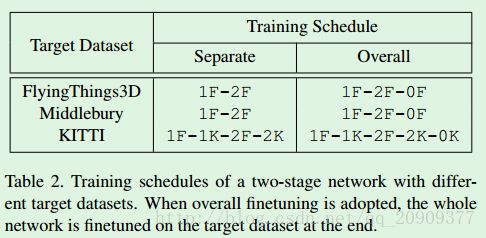
使用caffe框架。一般而言,首先训练DispFulNet,然后固定它的权重,再训练DispResNet,在这之后,有选择地微调整个网络。根据测试的目标数据集,使用不同的训练计划。如下表所示。(1F-1K-2F-2K-0K表示先用FlyingThings3D训练第一个网络,然后用KITTI微调;然后固定第一个网络的权重,用FlyingThings3D训练第二个网络,再用KITTI微调第二个网络;最后用KITTI微调整个网络)
测试:
使用两个常用的度量标准:
(1)Endpoint-error (EPE): 估计的视差和ground-truth之间的平均欧几里得距离。
(2)Three-pixel-error (3PE): 计算endpoint error超过3的像素的百分比。
4.2 架构对比
第一阶段的网络使用DispNetC或DispFulNet,第二阶段的网络使用DispNetS或DispResNet。



4.3 和其他方法比较
(1)FlyingThings3D数据集上的比较:


(2)KITTI 2015数据集上的比较:

5 总结
本论文提出一个两阶段的堆叠CNN架构:第一阶段设法产生具有好的细节的初始视差图,第二阶段使用在多个尺度产生的残差信号来精细化/修正初始视差。实验表明,残差学习不仅可以产生有效地精细化,还有益于整个两阶段网络的优化。
参考文献
[1] M. Jaderberg, K. Simonyan, A. Zisserman, et al. Spatial transformer networks. In Advances in Neural Information Processing Systems, pages 2017–2025, 2015.