逻辑回归好文转载
Logistic Regression--逻辑回归算法汇总**
转自别处 有很多与此类似的文章 也不知道谁是原创 因原文由少于错误 所以下文对此有修改并且做了适当的重点标记(横线见的内容没大明白 并且有些复杂,后面的运行流程依据前面的得出的算子进行分类)
初步接触
谓LR分类器(Logistic Regression Classifier),并没有什么神秘的。在分类的情形下,经过学习之后的LR分类器其实就是一组权值w0,w1,...,wm.
当测试样本集中的测试数据来到时,这一组权值按照与测试数据线性加和的方式,求出一个z值:
z = w0+w1*x1+w2*x2+...+wm*xm。 ① (其中x1,x2,...,xm是某样本数据的各个特征,维度为m)
之后按照sigmoid函数的形式求出:
σ(z) = 1 / (1+exp(z)) 。②
由于sigmoid函数的定义域是(-INF, +INF),而值域为(0, 1)。因此最基本的LR分类器适合于对两类目标进行分类。
那么LR分类器的这一组权值w0,w1,...,wm是如何求得的呢?这就需要涉及到极大似然估计MLE和优化算法的概念了。
我们将sigmoid函数看成样本数据的概率密度函数,每一个样本点,都可以通过上述的公式①和②计算出其概率密度
详细描述
1.逻辑回归模型
1.1逻辑回归模型
考虑具有p个独立变量的向量 ,设条件概率
,设条件概率 为根据观测量相对于某事件发生的概率。逻辑回归模型可表示为
为根据观测量相对于某事件发生的概率。逻辑回归模型可表示为
 (1.1)
(1.1)
上式右侧形式的函数称为称为逻辑函数。下图给出其函数图象形式。

其中 。如果含有名义变量,则将其变为dummy变量。一个具有k个取值的名义变量,将变为k-1个dummy变量。这样,有
。如果含有名义变量,则将其变为dummy变量。一个具有k个取值的名义变量,将变为k-1个dummy变量。这样,有
 (1.2)
(1.2)
定义不发生事件的条件概率为
 (1.3)
(1.3)
那么,事件发生与事件不发生的概率之比为
 (1.4)
(1.4)
这个比值称为事件的发生比(the odds of experiencing an event),简称为odds。因为0
 (1.5),
(1.5),
1.2极大似然函数
假设有n个观测样本,观测值分别为 设
设 为给定条件下得到yi=1(原文
为给定条件下得到yi=1(原文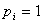 )的概率。在同样条件下得到yi=0(
)的概率。在同样条件下得到yi=0( )的条件概率为
)的条件概率为 。于是,得到一个观测值的概率为
。于是,得到一个观测值的概率为
 (1.6) -----此公式实际上是综合前两个等式得出,并无特别之处
(1.6) -----此公式实际上是综合前两个等式得出,并无特别之处
因为各项观测独立,所以它们的联合分布可以表示为各边际分布的乘积。

上式称为n个观测的似然函数。我们的目标是能够求出使这一似然函数的值最大的参数估计。于是,最大似然估计的关键就是求出参数 ,使上式取得最大值。
,使上式取得最大值。
对上述函数求对数
 (1.8)
(1.8)
上式称为对数似然函数。为了估计能使 取得最大的参数
取得最大的参数![clip_image034[1]](http://img.e-com-net.com/image/info8/9f1ac64fb788426cba4c7b9c15859050.jpg) 的值。
的值。
对此函数求导,得到p+1个似然方程。
 (1.9)
(1.9)
 ,j=1,2,..,p.-----p为独立向量个数
,j=1,2,..,p.-----p为独立向量个数
上式称为似然方程。为了解上述非线性方程,应用牛顿-拉斐森(Newton-Raphson)方法进行迭代求解。
1.3 牛顿-拉斐森迭代法
对![clip_image038[1]](http://img.e-com-net.com/image/info8/f8f365301a8242a1ae17d015d1981efe.gif) 求二阶偏导数,即Hessian矩阵为
求二阶偏导数,即Hessian矩阵为
 (1.10)
(1.10)
如果写成矩阵形式,以H表示Hessian矩阵,X表示
 (1.11)
(1.11)
令
 (1.12)
(1.12)
则 。再令
。再令 (注:前一个矩阵需转置),即似然方程的矩阵形式。
(注:前一个矩阵需转置),即似然方程的矩阵形式。
得牛顿迭代法的形式为
 (1.13)
(1.13)
注意到上式中矩阵H为对称正定的,求解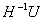 即为求解线性方程HX=U中的矩阵X。对H进行cholesky分解。
即为求解线性方程HX=U中的矩阵X。对H进行cholesky分解。
最大似然估计的渐近方差(asymptotic variance)和协方差(covariance)可以由信息矩阵(information matrix)的逆矩阵估计出来。而信息矩阵实际上是![clip_image038[2]](http://img.e-com-net.com/image/info8/6a8e6211e7b14cd8bf9eba3feb2f4856.gif) 二阶导数的负值,表示为
二阶导数的负值,表示为 。估计值的方差和协方差表示为
。估计值的方差和协方差表示为 ,也就是说,估计值
,也就是说,估计值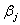 的方差为矩阵I的逆矩阵的对角线上的值,而估计值
的方差为矩阵I的逆矩阵的对角线上的值,而估计值![clip_image066[1]](http://img.e-com-net.com/image/info8/7ff9e3a478294363983feee5008e0d5d.gif) 和
和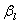 的协方差(和的协方差等于?不解。。。)为除了对角线以外的值。然而在多数情况,我们将使用估计值
的协方差(和的协方差等于?不解。。。)为除了对角线以外的值。然而在多数情况,我们将使用估计值![clip_image066[2]](http://img.e-com-net.com/image/info8/93546c583b914c99b9cbd2ed9c5bda3e.gif) 的标准方差,表示为
的标准方差,表示为
 ,for j=0,1,2,…,p (1.14)
,for j=0,1,2,…,p (1.14)
-----------------------------------------------------------------------------------------------------------------------------------------------
2.显著性检验
下面讨论在逻辑回归模型中自变量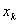 是否与反应变量显著相关的显著性检验。零假设
是否与反应变量显著相关的显著性检验。零假设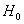 :
: =0(表示自变量
=0(表示自变量![clip_image072[1]](http://img.e-com-net.com/image/info8/62e83ad7f68842cba39710d3a6c8b2bc.gif) 对事件发生可能性无影响作用)。如果零假设被拒绝,说明事件发生可能性依赖于
对事件发生可能性无影响作用)。如果零假设被拒绝,说明事件发生可能性依赖于![clip_image072[2]](http://img.e-com-net.com/image/info8/4d9ed9a67e9a40a58fc08b6ed96511b0.gif) 的变化。
的变化。
2.1 Wald test
对回归系数进行显著性检验时,通常使用Wald检验,其公式为
 (2.1)
(2.1)
其中,  为
为 的标准误差。这个单变量Wald统计量服从自由度等于1的
的标准误差。这个单变量Wald统计量服从自由度等于1的 分布。
分布。
如果需要检验假设![clip_image074[1]](http://img.e-com-net.com/image/info8/c1c4bb6107cc4474873902ca643ce9ba.gif) :
: =0,计算统计量
=0,计算统计量
 (2.2)
(2.2)
其中,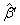 为去掉
为去掉 所在的行和列的估计值,相应地,
所在的行和列的估计值,相应地, 为去掉
为去掉![clip_image092[1]](http://img.e-com-net.com/image/info8/a449eb538e784ee9a466383ae28883ba.gif) 所在的行和列的标准误差。这里,Wald统计量服从自由度等于p的
所在的行和列的标准误差。这里,Wald统计量服从自由度等于p的![clip_image084[1]](http://img.e-com-net.com/image/info8/b2780cb1e76d421baa667645a2dff77a.gif) 分布。如果将上式写成矩阵形式,有
分布。如果将上式写成矩阵形式,有
 (2.3)
(2.3)
矩阵Q是第一列为零的一常数矩阵。例如,如果检验 ,则
,则 。
。
然而当回归系数的绝对值很大时,这一系数的估计标准误就会膨胀,于是会导致Wald统计值变得很小,以致第二类错误的概率增加。也就是说,在实际上会导致应该拒绝零假设时却未能拒绝。所以当发现回归系数的绝对值很大时,就不再用Wald统计值来检验零假设,而应该使用似然比检验来代替。
2.2 似然比(Likelihood ratio test)检验
在一个模型里面,含有变量 与不含变量
与不含变量![clip_image103[1]](http://img.e-com-net.com/image/info8/453d94d0237f483dad87f70983785975.gif) 的对数似然值乘以-2的结果之差,服从
的对数似然值乘以-2的结果之差,服从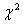 分布。这一检验统计量称为似然比(likelihood ratio),用式子表示为
分布。这一检验统计量称为似然比(likelihood ratio),用式子表示为
 (2.4)
(2.4)
计算似然值采用公式(1.8)。
倘若需要检验假设![clip_image074[2]](http://img.e-com-net.com/image/info8/2a2eabec355b43579209474cb395ddc7.gif) :
:![clip_image086[1]](http://img.e-com-net.com/image/info8/ce725a2b4d8942b6b39a824c8cbcd4b0.jpg) =0,计算统计量
=0,计算统计量
 (2.5)
(2.5)
式中,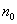 表示
表示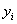 =0的观测值的个数,而
=0的观测值的个数,而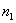 表示
表示![clip_image114[1]](http://img.e-com-net.com/image/info8/556e44cabef04a859c4b585a33a86cbd.gif) =1的观测值的个数,那么n就表示所有观测值的个数了。实际上,上式的右端的右半部分
=1的观测值的个数,那么n就表示所有观测值的个数了。实际上,上式的右端的右半部分 表示只含有
表示只含有 的似然值。统计量G服从自由度为p的
的似然值。统计量G服从自由度为p的![clip_image106[1]](http://img.e-com-net.com/image/info8/848c24d92234494bac323abecaf0537d.gif) 分布
分布
2.3 Score检验
在零假设![clip_image074[3]](http://img.e-com-net.com/image/info8/3343827a32e1485ab1dda4a81b9123fc.gif) :
:![clip_image076[1]](http://img.e-com-net.com/image/info8/7cc595e0d2df42d790e6be3360675dba.gif) =0下,设参数的估计值为
=0下,设参数的估计值为 ,即对应的
,即对应的![clip_image076[2]](http://img.e-com-net.com/image/info8/2683f365de6945e68ad15c4934835a3f.gif) =0。计算Score统计量的公式为
=0。计算Score统计量的公式为
 (2.6)
(2.6)
上式中,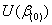 表示在
表示在![clip_image076[3]](http://img.e-com-net.com/image/info8/699ee8f7948b4b0caa408f46603bee75.gif) =0下的对数似然函数(1.9)的一价偏导数值,而
=0下的对数似然函数(1.9)的一价偏导数值,而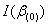 表示在
表示在![clip_image076[4]](http://img.e-com-net.com/image/info8/081f894fc6da4796a5e18e569aeffdcc.gif) =0下的对数似然函数(1.9)的二价偏导数值。Score统计量服从自由度等于1的
=0下的对数似然函数(1.9)的二价偏导数值。Score统计量服从自由度等于1的![clip_image084[2]](http://img.e-com-net.com/image/info8/7405ba03a42f453b92d9ff8f2a28dc65.gif) 分布。
分布。
2.4 模型拟合信息
模型建立后,考虑和比较模型的拟合程度。有三个度量值可作为拟合的判断根据。
(1)-2LogLikelihood
 (2.7)
(2.7)
(2) Akaike信息准则(Akaike Information Criterion,简写为AIC)
 (2.8)
(2.8)
其中K为模型中自变量的数目,S为反应变量类别总数减1,对于逻辑回归有S=2-1=1。-2LogL的值域为0至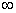 ,其值越小说明拟合越好。当模型中的参数数量越大时,似然值也就越大,-2LogL就变小。因此,将2(K+S)加到AIC公式中以抵销参数数量产生的影响。在其它条件不变的情况下,较小的AIC值表示拟合模型较好。
,其值越小说明拟合越好。当模型中的参数数量越大时,似然值也就越大,-2LogL就变小。因此,将2(K+S)加到AIC公式中以抵销参数数量产生的影响。在其它条件不变的情况下,较小的AIC值表示拟合模型较好。
(3)Schwarz准则
这一指标根据自变量数目和观测数量对-2LogL值进行另外一种调整。SC指标的定义为
 (2.9)
(2.9)
其中ln(n)是观测数量的自然对数。这一指标只能用于比较对同一数据所设的不同模型。在其它条件相同时,一个模型的AIC或SC值越小说明模型拟合越好。
3.回归系数解释
3.1发生比
odds=[p/(1-p)]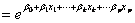 ,即事件发生的概率与不发生的概率之比。而发生比率(odds ration),即
,即事件发生的概率与不发生的概率之比。而发生比率(odds ration),即
(1)连续自变量。对于自变量![clip_image072[3]](http://img.e-com-net.com/image/info8/36fb51bc1c5e4280bf2e849f8eabc0bc.gif) ,每增加一个单位,odds ration为
,每增加一个单位,odds ration为
 (3.1)
(3.1)
(2)二分类自变量的发生比率。变量的取值只能为0或1,称为dummy variable。当![clip_image072[4]](http://img.e-com-net.com/image/info8/e9d6c12f760a47c7ace3ee4bdfb7c514.gif) 取值为1,对于取值为0的发生比率为
取值为1,对于取值为0的发生比率为
 (3.2)
(3.2)
亦即对应系数的幂。
(3)分类自变量的发生比率。
如果一个分类变量包括m个类别,需要建立的dummy variable的个数为m-1,所省略的那个类别称作参照类(reference category)。设dummy variable为![clip_image072[5]](http://img.e-com-net.com/image/info8/01d091ba390c441fa24bffab7ba889c3.gif) ,其系数为
,其系数为![clip_image076[5]](http://img.e-com-net.com/image/info8/61b2e77186764d0d88e11e3b233ede6b.gif) ,对于参照类,其发生比率为
,对于参照类,其发生比率为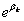 。
。
3.2 逻辑回归系数的置信区间
对于置信度1-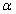 ,参数
,参数![clip_image076[6]](http://img.e-com-net.com/image/info8/7781df890ba94aeaa0bf05c186ce98b8.gif) 的100%(1-
的100%(1-![clip_image150[1]](http://img.e-com-net.com/image/info8/63485a4075f2421a870010175fa9c121.gif) )的置信区间为
)的置信区间为
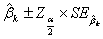 (3.3)
(3.3)
上式中,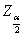 为与正态曲线下的临界Z值(critical value),
为与正态曲线下的临界Z值(critical value), 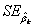 为系数估计
为系数估计 的标准误差,
的标准误差, 和
和 两值便分别是置信区间的下限和上限。当样本较大时,
两值便分别是置信区间的下限和上限。当样本较大时,![clip_image150[2]](http://img.e-com-net.com/image/info8/701beb910123418086f370faa602204a.gif) =0.05水平的系数
=0.05水平的系数![clip_image160[1]](http://img.e-com-net.com/image/info8/5712e928e7bd48f8ae93534ed1405693.gif) 的95%置信区间为
的95%置信区间为
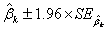 (3.4)
(3.4)
-----------------------------------------------------------------------------------------------------------------------------------------------
4.变量选择
4.1前向选择(forward selection):在截距模型的基础上,将符合所定显著水平的自变量一次一个地加入模型。
具体选择程序如下
(1) 常数(即截距)进入模型。
(2) 根据公式(2.6)计算待进入模型变量的Score检验值,并得到相应的P值。
(3) 找出最小的p值,如果此p值小于显著性水平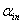 ,则此变量进入模型。如果此变量是某个名义变量的单面化(dummy)变量,则此名义变量的其它单面化变理同时也进入模型。不然,表明没有变量可被选入模型。选择过程终止。
,则此变量进入模型。如果此变量是某个名义变量的单面化(dummy)变量,则此名义变量的其它单面化变理同时也进入模型。不然,表明没有变量可被选入模型。选择过程终止。
(4) 回到(2)继续下一次选择。
4.2 后向选择(backward selection):在模型包括所有候选变量的基础上,将不符合保留要求显著水平的自变量一次一个地删除。
具体选择程序如下
(1) 所有变量进入模型。
(2) 根据公式(2.1)计算所有变量的Wald检验值,并得到相应的p值。
(3) 找出其中最大的p值,如果此P值大于显著性水平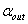 ,则此变量被剔除。对于某个名义变量的单面化变量,其最小p值大于显著性水平
,则此变量被剔除。对于某个名义变量的单面化变量,其最小p值大于显著性水平![clip_image172[1]](http://img.e-com-net.com/image/info8/a203b9556c9c4d9693aee53ff891d997.gif) ,则此名义变量的其它单面化变量也被删除。不然,表明没有变量可被剔除,选择过程终止。
,则此名义变量的其它单面化变量也被删除。不然,表明没有变量可被剔除,选择过程终止。
(4) 回到(2)进行下一轮剔除。
4.3逐步回归(stepwise selection)
(1)基本思想:逐个引入自变量。每次引入对Y影响最显著的自变量,并对方程中的老变量逐个进行检验,把变为不显著的变量逐个从方程中剔除掉,最终得到的方程中既不漏掉对Y影响显著的变量,又不包含对Y影响不显著的变量。
(2)筛选的步骤:首先给出引入变量的显著性水平![clip_image170[1]](http://img.e-com-net.com/image/info8/51c6e6127ae44095bcf1f57c0e1364dc.gif) 和剔除变量的显著性水平
和剔除变量的显著性水平![clip_image172[2]](http://img.e-com-net.com/image/info8/145adbfd35cb482fb0ab7e38eb76d314.gif) ,然后按下图筛选变量。
,然后按下图筛选变量。
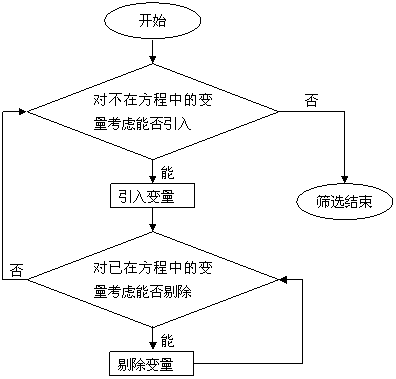
(3)逐步筛选法的基本步骤
逐步筛选变量的过程主要包括两个基本步骤:一是从不在方程中的变量考虑引入新变量的步骤;二是从回归方程中考虑剔除不显著变量的步骤。
假设有p个需要考虑引入回归方程的自变量.
① 设仅有截距项的最大似然估计值为 。对p个自变量每个分别计算Score检验值,
。对p个自变量每个分别计算Score检验值,
设有最小p值的变量为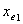 ,且有
,且有 ,对于单面化(dummy)变量,也如此。若
,对于单面化(dummy)变量,也如此。若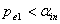 ,则此变量进入模型,不然停止。如果此变量是名义变量单面化(dummy)的变量,则此名义变量的其它单面化变量也进入模型。其中
,则此变量进入模型,不然停止。如果此变量是名义变量单面化(dummy)的变量,则此名义变量的其它单面化变量也进入模型。其中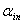 为引入变量的显著性水平。
为引入变量的显著性水平。
② 为了确定当变量![clip_image177[1]](http://img.e-com-net.com/image/info8/3ceeaedcbb7d4685ab5dd14c543aca4e.gif) 在模型中时其它p-1个变量也是否重要,将
在模型中时其它p-1个变量也是否重要,将 分别与
分别与![clip_image177[2]](http://img.e-com-net.com/image/info8/6ea3da16d6c2428c80bb937b2ce55981.gif) 进行拟合。对p-1个变量分别计算Score检验值,其p值设为
进行拟合。对p-1个变量分别计算Score检验值,其p值设为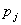 。设有最小p值的变量为
。设有最小p值的变量为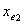 ,且有
,且有 .若
.若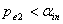 ,则进入下一步,不然停止。对于单面化变量,其方式如同上步。
,则进入下一步,不然停止。对于单面化变量,其方式如同上步。
③ 此步开始于模型中已含有变量![clip_image177[3]](http://img.e-com-net.com/image/info8/466bdc10242e49739a243dac15a02e58.gif) 与
与![clip_image190[1]](http://img.e-com-net.com/image/info8/75a345840c0f4ff7b039ac2f040f7451.gif) 。注意到有可能在变量
。注意到有可能在变量![clip_image190[2]](http://img.e-com-net.com/image/info8/778a3e11b40c4e1db782e93ad4cd1342.gif) 被引入后,变量
被引入后,变量![clip_image177[4]](http://img.e-com-net.com/image/info8/9578e1d747b2420a9bde9198e91e693d.gif) 不再重要。本步包括向后删除。根据(2.1)计算变量
不再重要。本步包括向后删除。根据(2.1)计算变量![clip_image177[5]](http://img.e-com-net.com/image/info8/f525911cd8d14c26a2a74ac893f33080.gif) 与
与![clip_image190[3]](http://img.e-com-net.com/image/info8/5048e86f233841a5a37edcec3d3dd3b1.gif) 的Wald检验值,和相应的p值。设
的Wald检验值,和相应的p值。设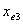 为具有最大p值的变量,即
为具有最大p值的变量,即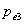 =max(
=max(![clip_image188[1]](http://img.e-com-net.com/image/info8/d56179ca50f9401c84d1fb4992b30f13.gif) ),
),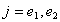 .如果此p值大于
.如果此p值大于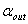 ,则此变量从模型中被删除,不然停止。对于名义变量,如果某个单面化变量的最小p值大于
,则此变量从模型中被删除,不然停止。对于名义变量,如果某个单面化变量的最小p值大于![clip_image203[1]](http://img.e-com-net.com/image/info8/00afe9f0b1684cf390f36b9f23ec6c80.gif) ,则此名义变量从模型中被删除。
,则此名义变量从模型中被删除。
④ 如此进行下去,每当向前选择一个变量进入后,都进行向后删除的检查。循环终止的条件是:所有的p个变量都进入模型中或者模型中的变量的p值小于![clip_image172[3]](http://img.e-com-net.com/image/info8/589bdd75c01947a1a53ad1c7dc68809d.gif) ,不包含在模型中的变量的p值大于
,不包含在模型中的变量的p值大于![clip_image183[1]](http://img.e-com-net.com/image/info8/58fd54b213aa4c00962ee966bb3b828d.gif) 。或者某个变量进入模型后,在下一步又被删除,形成循环。
。或者某个变量进入模型后,在下一步又被删除,形成循环。