精通flink读书笔记(2)——用DataStreamAPI处理数据
涉及的部分包括:
一 Execution environment
flink支持的环境创建方式有:
- get一个已经存在的flink环境 方式为getExecutionEnvironment()
- create一个local环境 createLocalEnvironment()
- create一个romote环境 createRemoteEnvironment(String host,int port,String and .jar files)
二 Data Source
flink内建了两种数据源方式,一种是基于socket 一种是基于File
基于socket的有:
- socketTextStream(hostName,port)
- socketTextStream(hostName,port,delimiter)
- socketTextStream(hostName,port,delimiter,maxRetry)
基于File的有:
- readTextFile(String path)
- readFile(FileInputFormat
inputFormat,String path) 如果数据源不是text文件的话,可以指定文件的格式
- readFileStream(String filePath,long intervalMills,FileMonitoringFunction.watchType watchType)
其中interval 是轮询的间隔,这个需要指定,而且watch type保留三种选择
- FileMonitoringFunction.WatchType.ONLY_NEW_FILES 只处理新文件
- FileMonitoringFunction.WatchType.PROCESS_ONLY_APPENDED 只处理追加的内容
- FileMonitoringFunction.WatchType.REPROCESS_WITH_APPENDED 既要处理追加的内容,也会处理file中之前的内容
如果文件不是text类型的文件,我们还要指定输入文件的格式
- readFile(fleInputFormat,path,watchType,interval,pathFilter,typeInfo)
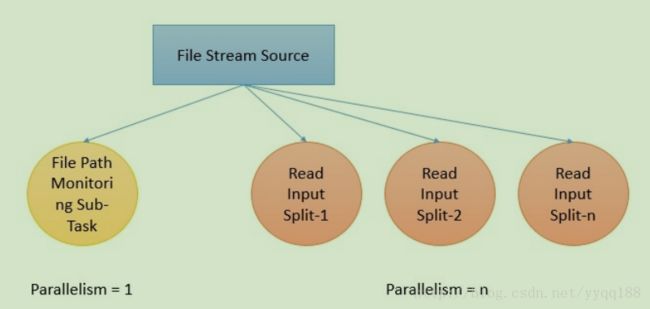
当采用这种格式的时候,要注意这背后会有两个子任务的产生,一个是基于watch type的子任务,它不是并行的,只是监控文件的轮询以及包括文件处理的情况,
另一个是并行的任务,才是真正的处理文件的
Transformations 转换的操作
map
inputStream.map{x => x * 5}
flatMap
inputStream.flatMap{ str => str.split(" ")}
filter
inputStream.filter{ _ != 1}
KeyBy
keyBy是根据key来进行逻辑分区,通常是根据hash函数来进行分区,结果是KeyedDataStream
inputStream.keyBy("someKey")
Reduce
是把一个keyedDataStream的数据流,按照给定的函数进行聚合操作
KeyedInputStream.reduce{_+_}
Fold
KeyedInputStream.fold("Start")((str,i) => {str + "=" + i})
结果是
Start=1=2=3=4=5
Aggregations
keyedInputStream.sum(0)
keyedInputStream.sum("key")
keyedInputStream.min(0)
keyedInputStream.min("key")
keyedInputStream.max(0)
keyedInputStream.max("key")
keyedInputStream.minBy(0)
keyedInputStream.minBy("key")
keyedInputStream.maxBy(0)
keyedInputStream.maxBy("key")
max 和maxBy的区别是,max返回的最大的值,max返回的是最大的值所对应的key
window操作,window操作需要作用于keyedDataStream,而且要有window的分配器
window的分配器有四类:
- tumbling window
- sliding window
- global window
- session window
当然也可以自定义window ,利用windowAssginer 的类
inputStream.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(10)))
Global window
global window 是没有结束点的window除非指定了一个触发器,通常每一个元素是被分配给一个单独的已经通过key逻辑分区的global window,
如果没有指定触发器的话,这个window是不会运行的
Tumbling window
依据一个固定的时间段来创建的window
Sliding windows
滑动窗口
Session windows
window窗口的边界根据的是输入的数据,所以该窗口的开始时间和窗口的大小是灵活不确定的,当然我们也可以配置超时时间。
windowAll
windowAll不是并发的数据转换操作
inputStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(10)))
Union
把两个或多个流合并,如果一个流和它本身合并的话,每个元素会输出两次
inputStream.union(inputStream1,inputStream2,...)
window join
我们也可以操作join的操作,依据的某些key,例如下面的例子,就是两个流的join操作,join的条件是第一个流的属性和第二个流的属性一样
inputStream.join(inputStream1)
.where(0).equalTo(1)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply( joinFunction)
Split 将一个混合的流分成多个指定的流
val split = inputStream.split(
(num : Int) =>
(num % 2) match {
case 0 => List("even")
case 1 => List("odd")
}
)
val even = split select "even"
val even = split select "odd"
val all = split.select("even","odd")
Project 选择指定的属性的数据
val in : DataStream[(Int,Double,String)] = //
val out = in.project(2,1)
结果是
(1,10.0,A) => (A,10.0)
(2,20.0,C) => (C,20.0)
Physical Partition 下面的操作都是物理分区操作,keyedBy 等操作都是逻辑分区操作
custom partitioning 用户自定义分区操作
inputStream.partitionCustom(partitioner,"somekey")
inputStream.partitionCustom(partitioner,0)
partitioner要实现一个高效的hash函数
Random partition
inputStream.shuffle()
Rebalancing partitioning 依据的是轮询的方式
inputStream.rebalance()
Rescaling 这个不会引起网络IO,只会在单个节点上进行rebalance
inputStream.rescale()
Broadcasting 是广播到每个分区partition spark是广播到每个节点
inputStream.broadcast()
三 Data sinks
- writeAsText()
- writeAsCsv()
- print()/printErr() 以标准输出的方式输出结果
- writeUsingOutputFormat() 以自定义的格式数据,定义的格式要继承 OutputFormat,它提供了序列化和反序列化
- writeToSocket() 要求定义 serializationSchema
四 Event time and watermarks
下面的例子展示如何设置输入时间和处理时间, 摄入时间和处理时间的watermark是自动生成的
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
//or
env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime)
而对于事件时间戳的和水印的分配有两种方式
一是直接采用数据源的时间戳
二是利用一个时间戳的生成器
不过最好是用数据源的时间戳
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
五 Connectors
kafka connector
kafka的数据先通过Flink-Kafka-Connector 进入到Flink Data Streams 再进入处理
需要一个jar文件,flink-connector-kafka-0.9_2.11

Properties properties = new Properties();
properties.setProperty("bootstrap.servers","localhost:9092");
properties.setProperty("group.id","test");
DataStream input = env.addSource(new FlinkKafkaConsumer09("mytopic","new SimpleStringSchema(),properties"));
scala:
val properties = new Properties();
properties.setProperty("bootstrap.servers","localhost:9092");
properties.setProperty("zookeeper.connect","localhost:2181");
properties.setProperty("group.id","test");
stream = env.addSource(new FlinkKafkaConsumer09[String]("mytopic",new SimpleStringSchema(),properties)).print
要注意容错,设置checkpoint
kafka producer也可以作为sink来用
stream.addSink(new FlinkKafkaProducer09("localhost:9092","mytopic",new SimpleStringSchema()));
ElasticSearch connector
ES有另个主要的版本,Flink都是支持的
jar文件为 flink-connector-elasticsearch_2.11
Flink的ES connector提供了两种连接ES的方式:嵌入式节点 和 运输客户端
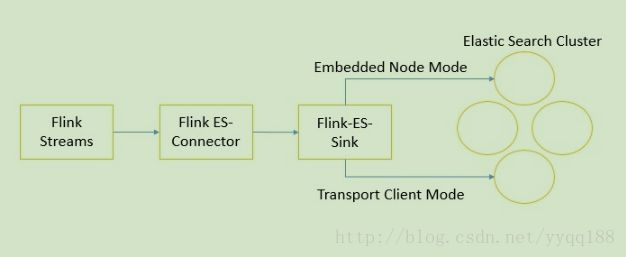
Flink的数据通过Flink-ES的connector 进入到Flink-ES的sink,就可以分两种方式传入ES节点了
以嵌入式节点的方式:使用BulkProcessor向ES发送文档数据,我们可以配置在往ES发送请求之前可以缓存多少的请求
val input : DataStream[String] = ...
val config [ new util.HashMap[String,String]
config.put("bulk.flush.max.actions","1")
config.put("cluster.name","cluster-name")
text.addSink(new ElasticsearchSink(config,new IndexRequestBuilder[String] {
override def createIndexRequest(element :String ,ctx:RuntimeContext):IndexRequest = {
val json = new util.HashMap[String,AnyRef]
json.put("data",element)
Requests.indexRequest.index("my-index",'type'("my-type").source(json))
}
}))
传输客户端的模式 :
ES也允许通过transport client 的模式在9300端口
val input : DataStream[String] = ...
val config = new util.HashMap[String,String]
config.put("bulk.flush.max.actions","1")
config.put("cluster.name","cluster-name")
val transports = new ArrayList[String]
transports.add(new InetSockettransportAddress("es-node-1",9300))
transports.add(new InetSockettransportAddress("es-node-1",9300))
transports.add(new InetSockettransportAddress("es-node-1",9300))
text.addSink(new ElasticsearchSink(config,transports,new IndexRequestBuilder[String] {
override def createIndexRequest(element : String ,ctx : RuntimeContext) : IndexRequest = {
val json = new util.HashMap[String,AnyRef]
json.put("data",element)
Requests.indexRequest.index("my-index"),'type'("my-type").source(json)
}
}))
传感器数据生成进入kafka再进入flink处理的例子
//设置流数据的执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//env.enableCheckpointing(5000)
env.setStreamtimeCharacteristic(TimeCharacteristic.EventTime);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers","localhost:9092");
properties.setProperty("zookeeper,connect","localhost:2181");
properties.setProperty("group.id","test");
FlinkKafkaConsumer09 myConsumer = new FlinkKafkaConsumer09<>("temp",new SimpleStringSchema(),properties);
myConsumer.assignTimestampsAndWatermarks(new CustomWatermarkEmitter());
消息的格式 :
Timestamp,Temperature,Sensor-Id
从消息中抽取时间戳
public class CustomWatermarkEmitter implements AssignerWithPunctuatedWatermarks {
private static final long serialVersionUID = 1L;
public long extractTimestramp(String arg0,long arg1){
if(null != arg0 && arg0.contains(",")) {
String parts[] = arg0.split(",");
return Long.parseLong(parts[0]);
}
return 0;
}
public Watermark checkAndGetNextWatermark(String arg0,long arg1){
if(null != arg0 && arg0.contains(",")) {
String parts[] = arg0.split(",")
return new Watermark(Long.parseLong(parts[000]));
}
return null;
}
}
对温度计算平均值
DataStream> keyedStream = env.addSource().flatMap(new Splitter()).keyBy(0)
.timeWindow(Time.second(300))
.apply(new WindowFunction,Tuple2,Tuple,TimeWindow>() {
public void apply(Tuple key,TimeWindow window,Iterable> input,Collector> out) throws Exception{
double sum = 0L;
int count = 0;
for(Tuple2 record : input) {
sum += record.f1;
count ++;
}
Tuple2 result = input.iterator().next();
result.f1 = (sum/count);
out.collect(result);
}
});