CVPR 2018 目标检测(Object Detection)
Cascade R-CNN: Delving into High Quality Object Detection
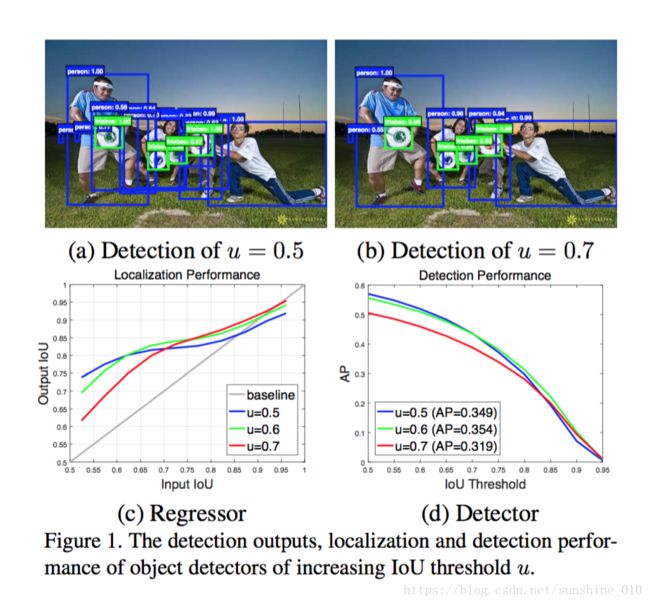
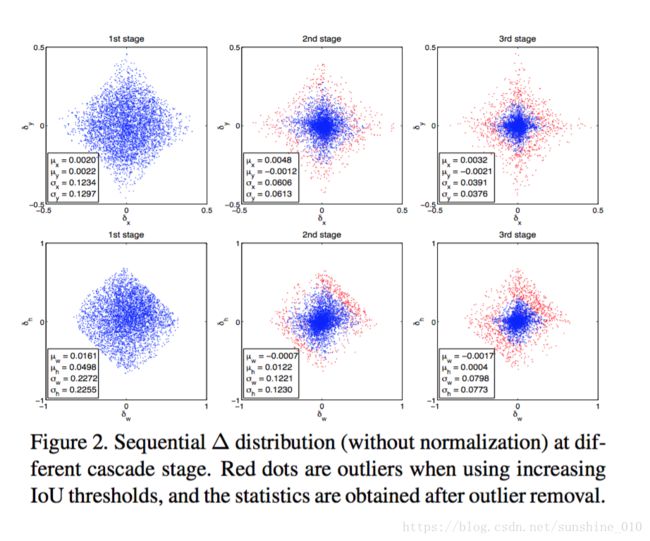
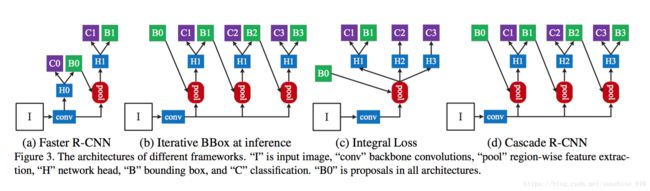
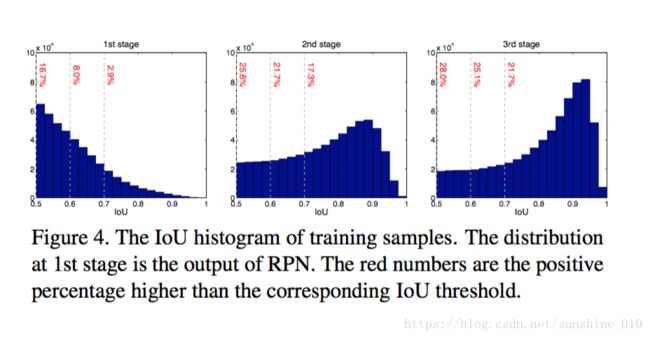
In object detection, an intersection over union (IoU) threshold is required to define positives and negatives. An object detector, trained with low IoU threshold, e.g. 0.5, usually produces noisy detections. However, detection performance tends to degrade with increasing the IoU thresholds. Two main factors are responsible for this: 1) overfitting during training, due to exponentially vanishing positive samples, and 2) inference-time mismatch between the IoUs for which the detector is optimal and those of the input hypotheses. A multi-stage object detection architecture, the Cascade R-CNN, is proposed to address these problems. It consists of a sequence of detectors trained with increasing IoU thresholds, to be sequentially more selective against close false positives. The detectors are trained stage by stage, leveraging the observation that the output of a detector is a good distribution for training the next higher quality detector. The resampling of progressively improved hypotheses guarantees that all detectors have a positive set of examples of equivalent size, reducing the overfitting problem. The same cascade procedure is applied at inference, enabling a closer match between the hypotheses and the detector quality of each stage. A simple implementation of the Cascade R-CNN is shown to surpass all single-model object detectors on the challenging COCO dataset. Experiments also show that the Cascade R-CNN is widely applicable across detector architectures, achieving consistent gains independently of the baseline detector strength. The code will be made available at https://github.com/zhaoweicai/cascade-rcnn.
在物体检测中, 需要跨越联合(IoU)阈值的交点来定义正数和负数。一个目标检测器,用低的IoU阈值训练, 如 0.5, 通常会产生噪音检测。但是, 检测性能往往会随着IoU阈值的增加而降低。两个主要因素是: 1) 在训练期间 overfitting, 由于正样本指数消失和 2)检测器最佳IoU和那些输入假说 inference-time不匹配。针对这些问题, 提出了一种multi-stage目标检测体系结构, 即Cascade R-CNN。它包括由增加的IoU门限训练的检测器序列, 循序地对接近的错误positives更具选择性。探测器是经过阶段训练的, 利用观测结果表明, 检测器的输出是一个很好的分布, 用于训练下一个更高品质的探测器。不断改进的假设的重新取样保证了所有探测器都有一个等价大小的正数集合, 减少了 overfitting 问题。同一级联程序在推理中应用, 使假设与每个阶段的检测器的质量匹配更接近。一个简单实现的Cascade R-CNN 在COCO数据集挑战赛上被展示超过所有单模型物体探测器。实验还表明, Cascade R-CNN 广泛适用于探测器体系结构, 实现了独立于baseline检测器强度的一致增益。代码将在 https://github.com/zhaoweicai/cascade-rcnn 提供。
Relation Network for Object Detection
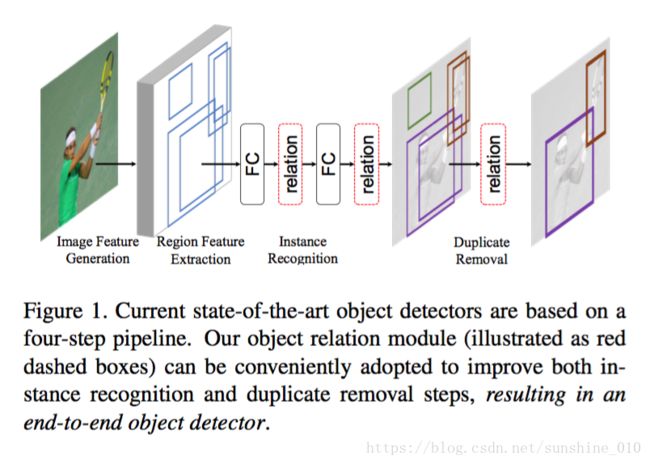
Although it is well believed for years that modeling relations between objects would help object recognition, there has not been evidence that the idea is working in the deep learning era. All state-of-the-art object detection systems still rely on recognizing object instances individually, without exploiting their relations during learning.
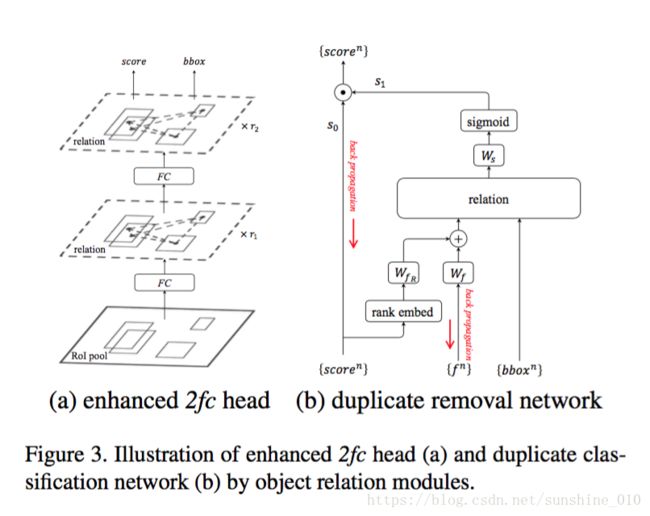
This work proposes an object relation module. It processes a set of objects simultaneously through interaction between their appearance feature and geometry, thus allowing modeling of their relations. It is lightweight and in-place. It does not require additional supervision and is easy to embed in existing networks. It is shown effective on improving object recognition and duplicate removal steps in the modern object detection pipeline. It verifies the efficacy of modeling object relations in CNN based detection. It gives rise to the first fully end-to-end object detector.
虽然多年来人们一直相信, 建模物体之间的关系将有助于物体的识别, 但没有证据表明这个想法是在深度学习的时代起效的。所有state-of-the-art物体检测系统仍然依赖于单独识别物体实例, 而不利用它们在学习过程中的关系。
本项目提出了一个object relation module。它通过它们的外观特征和几何之间的相互作用同时处理一组物体, 从而允许建模它们之间的关系。它是轻量级和in-place。它不需要额外的监督, 很容易嵌入到现有的网络中。该方法对改进现代目标检测领域中的目标识别和重复移动steps有较好的效果。验证了基于 CNN 的检测中物体关系建模的有效性。它产生了第一个完全端到端的物体探测器。
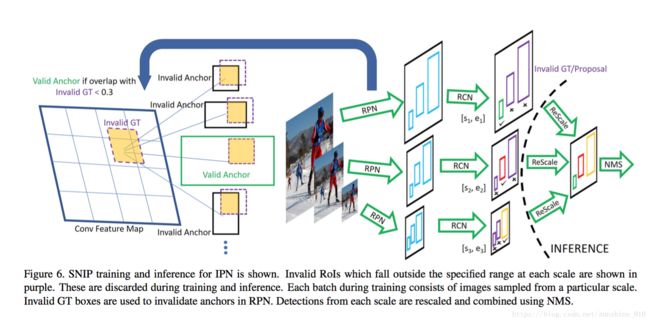
An Analysis of Scale Invariance in Object Detection-SNIP
An analysis of different techniques for recognizing and detecting objects under extreme scale variation is presented. Scale specific and scale invariant design of detectors are compared by training them with different configurations of input data. To examine if upsampling images is necessary for detecting small objects, we evaluate the performance of different network architectures for classifying small objects on ImageNet. Based on this analysis, we propose a deep end-to-end trainable Image Pyramid Network for object detection which operates on the same image scales during training and inference. Since small and large objects are difficult to recognize at smaller and larger scales respectively, we present a novel training scheme called Scale Normalization for Image Pyramids (SNIP) which selectively back-propagates the gradients of object instances of different sizes as a function of the image scale. On the COCO dataset, our single model performance is 45.7% and an ensemble of 3 networks obtains an mAP of 48.3%. We use ImageNet-1000 pre-trained models and only train with bounding box supervision. Our submission won the Best Student Entry in the COCO 2017 challenge. Code will be made available at http://bit.ly/2yXVg4c.
分析了在极端尺度变化下识别和检测物体的不同技术。通过对不同的输入数据配置进行训练, 比较了检测器设计的 Scale specific 和 scale invariant。为了检查是否需要 upsampling 图像来检测小物体, 我们评估了不同网络体系结构对 ImageNet 上的小物体进行分类的性能。在此基础上, 提出了一种深端到端可训练图像金字塔网络, 用于目标检测, 在训练和推理过程中在同一图像尺度上操作。由于小规模和大型物体难以识别在较小和更大的尺度上, 我们提出了一个新的训练方案称为Scale Normalization for Image Pyramids (SNIP), 有选择地反向传播的物体实例的梯度不同大小的图像缩放功能。在COCO数据集上, 我们的单模型性能为 45.7%, 3个网络的集成得到了48.3% 的映射。我们使用 ImageNet-1000 预先训练的模型, 只训练与边界箱监督。我们的投稿赢得了COCO2017挑战的Best Student Entry。代码将在 http://bit.ly/2yXVg4c 提供。



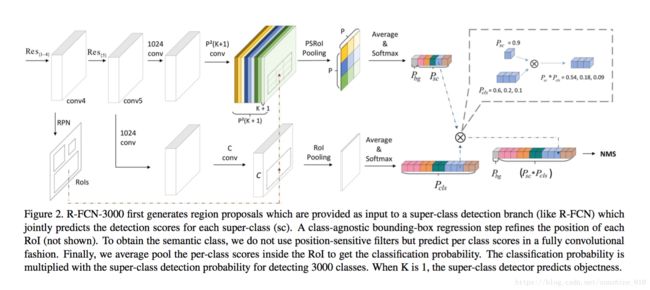
R-FCN-3000 at 30fps: Decoupling Detection and Classification
We present R-FCN-3000, a large-scale real-time object detector in which objectness detection and classification are decoupled. To obtain the detection score for an RoI, we multiply the objectness score with the fine-grained classification score. Our approach is a modification of the R-FCN architecture in which position-sensitive filters are shared across different object classes for performing localization. For fine-grained classification, these position-sensitive filters are not needed. R-FCN-3000 obtains an mAP of 34.9% on the ImageNet detection dataset and outperforms YOLO9000 by 18% while processing 30 images per second. We also show that the objectness learned by R-FCN-3000 generalizes to novel classes and the performance increases with the number of training object classes supporting the hypothesis that it is possible to learn a universal objectness detector. Code will be made available.
提出了一种大规模的实时目标检测器 R-FCN-3000, objectness 检测与分类同时进行。为了获得 RoI 的检测分数, 我们将 objectness 分数与细粒度分类评分相乘。我们的方法是对 R-FCN 体系结构的修改, 其中位置敏感过滤器是在不同的物体类之间共享的, 用于执行定位。对于细粒度分类, 不需要这些位置敏感的筛选器。R-FCN-3000 在 ImageNet 检测数据集上获得34.9% 的mAP, 并在每秒处理30幅图像时优于 18%的YOLO9000。我们还表明, objectness通过 R-FCN-3000 一般化到新的类学习并且随着正在训练的物体级别数量增加, 支持假设性能增加。有必要学习一个通用的 objectness 探测器。代码将被提供。
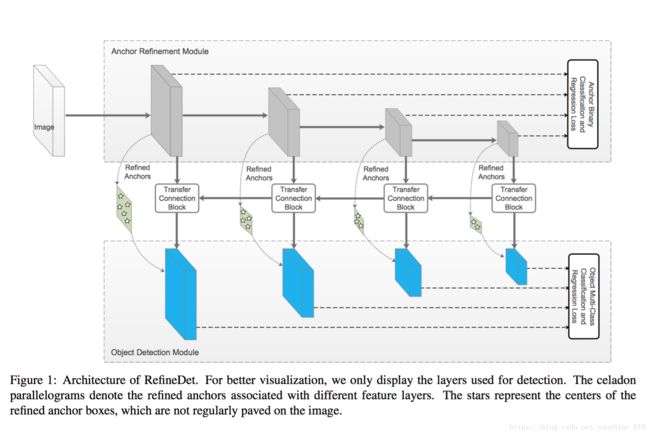
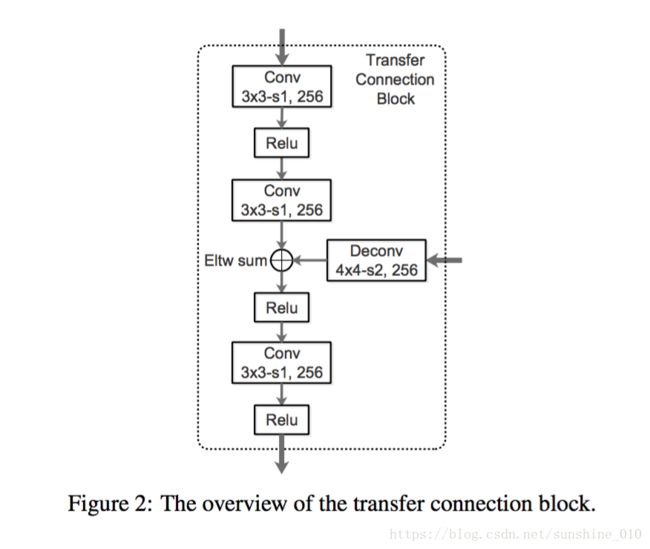
Single-Shot Refinement Neural Network for Object Detection
For object detection, the two-stage approach (e.g., Faster R-CNN) has been achieving the highest accuracy, whereas the one-stage approach (e.g., SSD) has the advantage of high efficiency. To inherit the merits of both while overcoming their disadvantages, in this paper, we propose a novel single-shot based detector, called RefineDet, that achieves better accuracy than two-stage methods and maintains comparable efficiency of one-stage methods. RefineDet consists of two inter-connected modules, namely, the anchor refinement module and the object detection module. Specifically, the former aims to (1) filter out negative anchors to reduce search space for the classifier, and (2) coarsely adjust the locations and sizes of anchors to provide better initialization for the subsequent regressor. The latter module takes the refined anchors as the input from the former to further improve the regression and predict multi-class label. Meanwhile, we design a transfer connection block to transfer the features in the anchor refinement module to predict locations, sizes and class labels of objects in the object detection module. The multitask loss function enables us to train the whole network in an end-to-end way. Extensive experiments on PASCAL VOC 2007, PASCAL VOC 2012, and MS COCO demonstrate that RefineDet achieves state-of-the-art detection accuracy with high efficiency. Code is available at https: //github.com/sfzhang15/RefineDet.
对于目标检测, two-stage方法 (例如, Faster R-CNN) 已经达到了最高的精确度, 而one-stage方法 (如 SSD) 具有高效率的优点。为了继承两者的优缺点, 本文提出了一种新的基于single-shot的探测器, 称为 RefineDet, 它比two-stage方法具有更好的精度, 并保持了一级方法的可比效率。RefineDet 由两个相互连接的模块组成, 即定位细化模块和物体检测模块。具体而言, 前者旨在 (1) 过滤掉负锚, 以减少分类器的搜索空间, (2) 粗略地调整锚点的位置和大小, 为后续的回归提供更好的初始化。后一个模块以精致的锚杆作为前者的输入, 进一步改善回归, 预测多类标签。同时, 我们设计了一个传输连接块来传输定位细化模块中的特征, 以预测物体检测模块中物体的位置、大小和类标签。多任务损耗函数使我们能够以端到端的方式对整个网络进行训练。在PASCAL VOC 2007, PASCAL VOC 2012 和MS COCO的广泛实验表明, RefineDet 达到,高效的state-of-the-art的检测精度。代码可在 https://github.com/sfzhang15/RefineDet。
MegDet: A Large Mini-Batch Object Detector
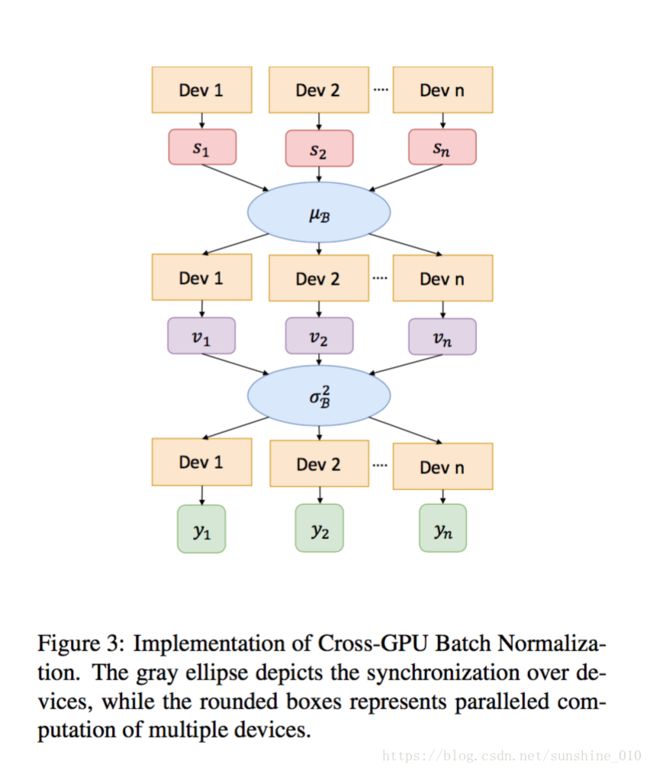
The development of object detection in the era of deep learning, from R-CNN [11], Fast/Faster R-CNN [10, 31] to recent Mask R-CNN [14] and RetinaNet [24], mainly come from novel network, new framework, or loss design. However, mini-batch size, a key factor for the training of deep neural networks, has not been well studied for object detection. In this paper, we propose a Large Mini-Batch Object Detector (MegDet) to enable the training with a large minibatch size up to 256, so that we can effectively utilize at most 128 GPUs to significantly shorten the training time. Technically, we suggest a warmup learning rate policy and Cross-GPU Batch Normalization, which together allow us to successfully train a large mini-batch detector in much less time (e.g., from 33 hours to 4 hours), and achieve even better accuracy. The MegDet is the backbone of our submission (mmAP 52.5%) to COCO 2017 Challenge, where we won the 1st place of Detection task.
目标检测在深入学习时代的发展, 从R-CNN [11], Fast/Faster R-CNN [10, 31] 到最近的Mask R-CNN [14] 和 RetinaNet [24], 主要来自新的网络, 新的框架或损失设计。然而, 小批量是深层神经网络训练的关键因素, 在目标检测方面还没有得到很好的研究。本文提出了一个Large Mini-Batch Object Detector (MegDet), 使 large minibatch size达到 256, 使我们能够有效地利用最多 128 GPUs 来显著缩短训练时间。从技术上讲, 我们建议一个warmup learning rate策略和Cross-GPU Batch Normalization, 这使得我们能够在更少的时间 (例如从33小时到4小时) 成功地训练一个large mini-batch检测器, 并取得更高的精确度。MegDet 是我们提交 (mmAP 52.5%) COCO2017挑战的backbone,并且赢得了检测任务第一名。

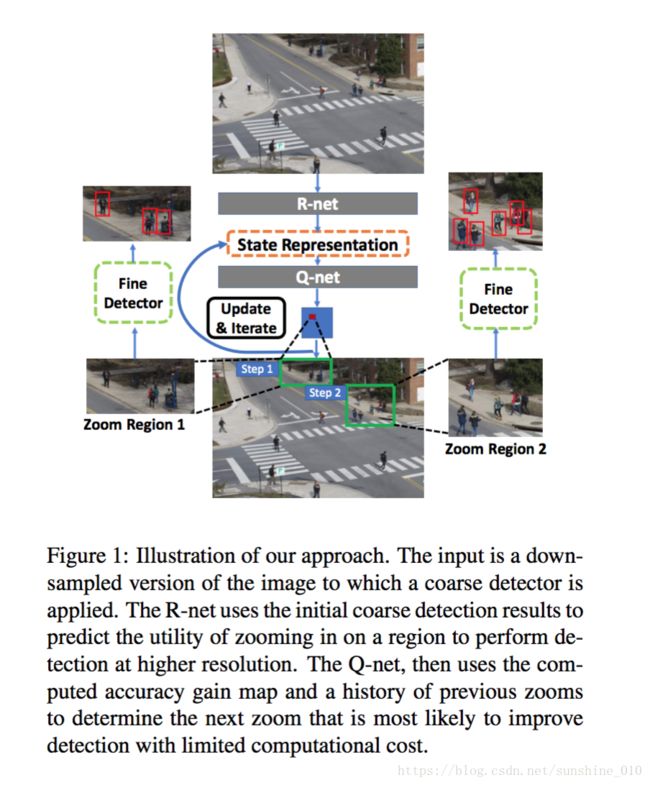
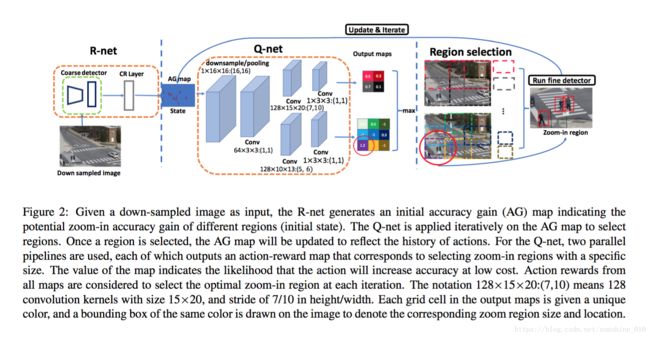
Dynamic Zoom-in Network for Fast Object Detection in Large Images
We introduce a generic framework that reduces the computational cost of object detection while retaining accuracy for scenarios where objects with varied sizes appear in high resolution images. Detection progresses in a coarse-to-fine manner, first on a down-sampled version of the image and then on a sequence of higher resolution regions identified as likely to improve the detection accuracy. Built upon reinforcement learning, our approach consists of a model (Rnet) that uses coarse detection results to predict the potential accuracy gain for analyzing a region at a higher resolution and another model (Q-net) that sequentially selects regions to zoom in. Experiments on the Caltech Pedestrians dataset show that our approach reduces the number of processed pixels by over 50% without a drop in detection accuracy. The merits of our approach become more significant on a high resolution test set collected from YFCC100M dataset, where our approach maintains high detection performance while reducing the number of processed pixels by about 70% and the detection time by over 50%.
我们引入了一个通用框架, 它降低了物体检测的计算成本, 同时保留了不同大小的物体在高分辨率图像中出现的情况的准确性。检测过程中以coarse-to-fine的方式进行, 首先对图像的下采样版本, 然后再对被识别为可能提高检测精度的更高分辨率区域排序。在强化学习的基础上, 我们的方法包括一个模型 (R-net), 使用粗检测结果来预测在更高分辨率下分析一个区域的潜在精度增益, 另一个模型 (Q-net), 继续选择区域放大.在 Caltech Pedestrians的行人数据集的实验表明, 我们的方法减少了处理像素的数量超过50% ,检测精度没有下降。我们的方法的优点在从 YFCC100M 数据集收集的高分辨率测试集上变得更加重要, 我们的方法保持了较高的检测性能, 同时将处理的像素的数量减少了 70%, 并且检测时间超过了50%。