ROS IntelRealSenseZR300 PCL+ORK+Linemod 柱状物体检测 机械臂抓取
任务主线是深度相机看到物体是什么、在哪儿,位姿发送给机械臂进行抓取,这两周主要解决了用深度相机检测一个可乐罐以及发布其位置信息。


运行环境:Ubuntu16.04+ROS Kinetic+PCL
目前深度相机主要的方法有:
1.基于霍夫变换
(可以参考2010年的论文 ppf (point pair feature):Model Globally, Match Locally: Efficient and Robust 3D Object Recognition)
2.基于模板匹配(也就是本文采用的基于linemod算法)比1效果要更好
论文:Multimodal Templates for Real-Time Detection of Texture-less Objects in Heavily Cluttered Scenes
http://campar.in.tum.de/pub/hinterstoisser2011linemod/hinterstoisser2011linemod.pdf
3.基于patch匹配+random forest(Latent-Class Hough Forests 用于处理linemd在遮挡时候识别率下降的问题)
论文:Learning 6D Object Pose Estimation using 3D Object Coordinates
LCHF:https://arxiv.org/abs/1706.03285
4.基于点云(也是之前一周采用的方法)
http://wiki.ros.org/pcl_ros/Tutorials
(学习资料)
https://blog.csdn.net/shine_cherise/article/details/79285162
http://ros-developer.com/2017/05/15/object-recognition-and-6dof-pose-estimation-with-pcl-pointcloud-and-ros/
(核心项目参考 最下面有个评论以及回复可以作为参考后面就舍弃掉这种方法了)
也就是
https://github.com/adityag6994/3D_Object_Seg_CNN
以及可以参考他的分享
https://github.com/adityag6994/object_tracking_particle_filter
https://blog.csdn.net/AmbitiousRuralDog/article/details/80268920
(地面点云分割)
5.基于CNN end-to-end
论文:SSD-6D: Making RGB-based 3D detection and 6D pose estimation great agai

关于linemod算法可以参考:
(http://campar.in.tum.de/pub/hinterstoisser2011linemod/hinterstoisser2011linemod.pdf以及https://blog.csdn.net/zmdsjtu/article/details/79933822)这里稍作简单介绍已使文章内容更加完整严谨
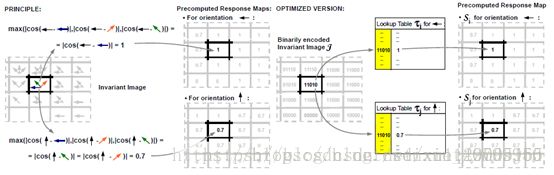
linemod主要解决的是3D刚性物体的实时检测与定位,利用较短的训练时间训练采集的RGBD信息,将其与模版匹配对比后得到物体信息、位姿及自信度。
linemod特征采用彩色图像的梯度信息结合物体表面的法向特征作为模板匹配的依据:
1.首先计算梯度方向,分别进行77高斯模糊、sobel算子计算梯度、每个像素点梯度方向及幅值求解(去掉低于阈值的梯度)、33邻阈内统计梯度方向,最终对梯度起到主成分提取和放大的提取特征效果。

2.接着方向扩散使匹配具备容错度,图像提取得到特征图后在一定邻阈让特征进行扩散、利用模版进行滑窗匹配得到容错度。

3.预处理响应图,对八个方向及处理得到的扩散图逐个像素匹配,得到距离最近方向角度的余弦值,针对每个方向遍历图片计算匹配结果。

4.线性存储3预处理的结果,并扩展到深度图。


好了开始这两周的工作内容总结:
运行环境:Ubuntu16.04+ROS Kinetic+PCL+ORK
核心是参考这两篇文章,但是其是针对Kinetic或者Xbox,所以并不完全适用
http://wg-perception.github.io/ork_tutorials/tutorial03/tutorial.html#setup-the-working-environment(ORK官网 这里有完整详细的步骤)
https://blog.techbridge.cc/2016/05/14/ros-object-recognition-kitchen/(核心是一样的,只不过是个人的应用)
接下来进行步骤总结:
**1. 下载realsense适用Intel ZR300深度相机的例程包(http://wiki.ros.org/realsense_camera)
官网下载并安装,选择branch(indigo-devel)。作为替代openni2(适用Kinetic)的启动代码,可以得到实时图像的RGBD图像并在rviz显示,这里的-b (分支名)要添加,不然下载下来的是realsense2_camera 新版本的在kinetic编译不通。(注意ZR300要接USB3.0接口!)
#git clone -b indigo-devel https://github.com/intel-ros/realsense.git
#roslaunch realsense_camera zr300_nodelet_rgbd.launch
#rviz
注意ros下运行的包要装到~/catkin_ws/src目录下编译运行!
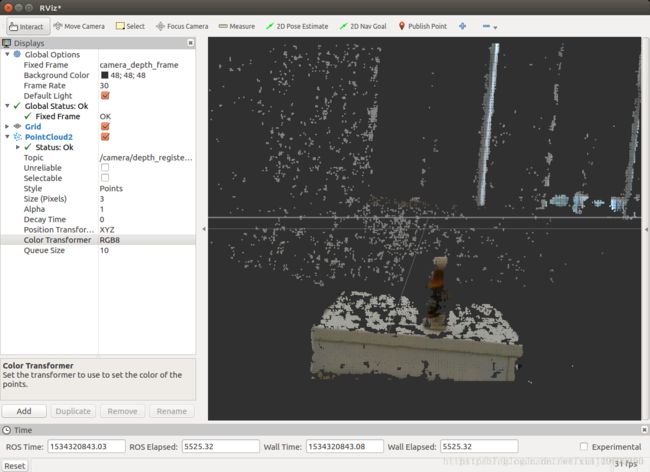

话题名为:depth_registered
其发布了RGBD信息为:(这样就是有发布者了,下面的信息以后会用到)
Rgb_frame_id:’camera_rgb_frame’
Rgb_image_topic:’/camera/rgb/image_rect_color’
Rgb_camera_info:’/camera/rgb/camera_info’
Depth_frame_id:’camera_depth_info’
Depth_image_topic:’/camera/depth_registered/sw_registered/image_rect’
Depth_camera_info:’/camera/depth_registered/sw_registered/camera_info’
注意类似这样的错误不能正常启动的话可以重新插拔realsense摄像头,或者按下面所说的在rqt_reconfigure重新打钩enable就可以了。

#rosrun rqt_reconfigure rqt_reconfigure

陆陆续续有很多Bug,如果提示缺少什么什么包的话直接下载后重新编译即可,这里列出最近的一个:roslaunch realsense_camera zr300_nodelet_rgbd的时候出现:
IOError: [Errno 13] Permission denied .ros/rosdep/sources.cache/index
解决:
#sudo rosdep update
#apt-get update
#rospack profile
更新一下就好,并且在整个工程试验中要经常#sudo apt-get update 以及 #rospack profile,前者更新包以避免不必要的麻烦,后者是ros有时候会找不到文件的位置导致无法tap。
参考:https://answers.ros.org/question/281477/ioerror-errno-13-permission-denied-rosrosdepsourcescacheindex/
2. 安装ork需要用到的包
注:所有的资源都可以用s来下,超级好用,输入命令时只需要将proxychains加在所有命令前即可,如果有sudo就加在其后面,这样下载速度真的超级快.
Eg.#sudo proxychains apt-get install ros-kinetic-object-recognition-core
博主在安装过程中出错后重新选择了从source安装:
#git clone http://github.com/wg-perception/object_recognition_msg
#git clone http://github.com/wg-perception/object_recognition_ros-bisualization
#cd ../ && catkin_make
(可以用proxychains git clone…如果装了s的话)
3. 安装linemod
#git clone http://github.com/wg-perception/object_recognition_core
#git clone http://github.com/wg-perception/linemod
#git clone http://github.com/wg-perception/ork_renderer
#cd ../ && catkin_make
如果之前有配置过Ros,在src目录直接#cm即可。在这个过程汇总可以挨个下载后即编译,解决了出现的问题后再下载其他的继续编译,以此发现其中哪个包存在问题。这里我也碰到了bug:
@fatal error: GL/osmesa.h: 沒有此库或目录 #include 。
解决:#sudo apt-get install libosmesa6-dev 安装缺少的GL/osmesa.h
4.修改源程序
由于参考的例子使用的环境适用kinetic深度相机或者baxter,所以在realsenseZR300需要改文件使其找realsense_camera摄像头驱动包对应发布的话题名。将limemod涉及到的所有依赖包加到sublime,就可以大批量直接寻找要找的含旧话题名的文件。
4.1首先查看节点信息 图节点信息
#rosnode info /object_recognition_server
查看realsense给的例子需要订阅的主题为:
Subscriptions:
* /camera/depth_registered/camera_info [unknown type]
* /camera/depth_registered/image_raw [unknown type]
* /camera/rgb/camera_info [sensor_msgs/CameraInfo]
* /camera/rgb/image_rect_color [sensor_msgs/Image]
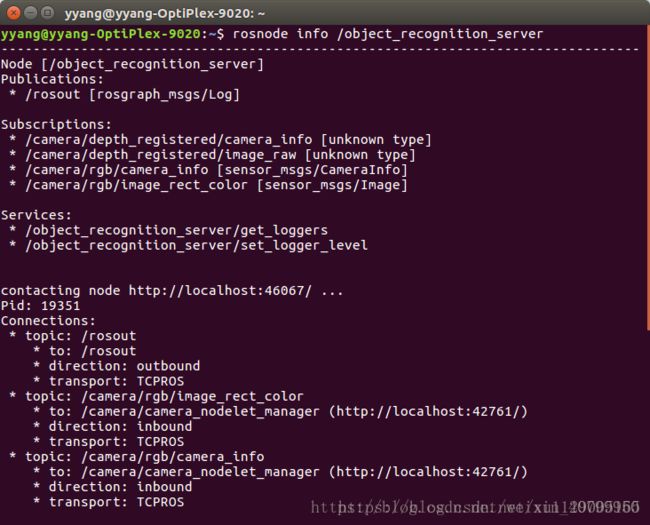
例子发布了很多没有用到的主题,用#rosnode cleanup清除无关此次项目开发的节点。
#rostopic echo /camera/depth_registered/sw_registered/camera_info
#rostopic echo /camera/depth_registered/image_raw
#rostopic echo /camera/rgb/camera_info
#rostopic echo /camera/rgb/image_rect_color
利用上面的命令即可查看例程订阅的数据,(当然查看的前提是已经roslauch了realsense_camera zr300_nodelet_rgb),这样就可以看到如果例子realsense的例子跑起来,要用到的这四个话题是否有数据,是否成功发布。
用#rqt_graph 用节点图形的方式来查看运行的节点信息。
这样我们核心就是要让detection程序(也就是linemod例程)订阅我们深度相机realsense发布的话题。

4.2修改订阅话题
4.2.1首先要装sublime,当然这是程序开发必备的开发软件,在这个工程中博主已经找到要修改的文件所以可以跳过,但是便于之后开发sublime还是必备的。
注:在指定文件夹寻找需要的内容(在例子detection暗指的话题所在位置),但是用rosed命令还是默认gedit,所以要参考(http://wiki.lofarolabs.com/index.php/Using_rosed_to_Edit_Files_in_ROS),就可以直接用rosed命令直接关联sublime。
4.2.2将用到的包linemod、ros、ork、core、msgs等(新安装的包)拖入sublime查找。
4.2.3搜索linemod订阅的的四个话题:(这里根据之前zr300_nodelet_rgbd.launch节点发布的话题已经修改并注释掉了)。

搜索发现决定订阅话题名的文件位于linemod\conf\目录下的detection.ros.ork文件,将其修改:

在~/catkin_ws/src/linemod/conf目录下的detection
# rgb_frame_id: 'camera_rgb_optical_frame'
# rgb_image_topic: '/camera/rgb/image_rect_color'
# rgb_camera_info: '/camera/rgb/camera_info'
# depth_frame_id: 'camera_depth_optical_frame'
# depth_image_topic: '/camera/depth_registered/image_raw'
# depth_camera_info: '/camera/depth_registered/camera_info'
修改为:
#rgb_frame_id: 'camera_rgb_frame'
#rgb_image_topic: '/camera/rgb/image_rect_color'
#rgb_camera_info: '/camera/rgb/camera_info'
#depth_frame_id: 'camera_depth_frame'
#depth_image_topic: '/camera/depth_registered/sw_registered/image_rect'
#depth_camera_info: '/camera/depth_registered/sw_registered/camera_info'
这样linemod就可以找到rgb图像的数据以及D的数据,RGBD三维图像的数据就可以进行处理了。
5.导入模型并训练
5.1安装CouchDB(用来建立物体辨识的工具)
#sudo apt-get install couchdb
ORK tutorials为我们提供了一个可乐罐的3D模型(coke.stl)
#git clone https://github.com/wg-perception/ork_tutorials
#cm (在src目录下cmake)
5.2上传coke物体及其mesh文件
#rosrun object_recog5.2nition_core object_add.py -n "coke " -d "A universal can of coke"
当然名字可以修改,接着在自己的资料库查看是否已经新增了该物体,将id记录下来。以后想识别其他物体也在这个物体增加模型并训练。
http://localhost:5984/_utils/database.html?object_recognition/_design/objects/_view/by_object_name
#rosrun object_recognition_core mesh_add.py
实际为:
#rosrun object_recognition_core mesh_add.py 0be612246c9b0a00baaa4adefb0009eb /home/yyang/catkin_ws/src/ork_tutorials/data/coke.stl --commit
这里的obe…就是自己物体在CouchDB的id(博主是42d…),5.2这两条命令如果不能跑可以试试在后面加–commit。
6.训练模型
#rosrun object_recognition_core training -c `rospack find object_recognition_linemod`/conf/training.ork

很快训练完即可进行下一步detection
7.运行物体识别及检测
#roslaunch realsense_camera zr300_nodelet_rgbd.launch
(如果之前已经launch过就不需要了,当然运行过也可以重新运行,配合下面的detection)
#rosrun object_recognition_core detection -c `rospack find object_recognition_linemod`/conf/detection.ros.ork
#rviz
结果如下:

这里可乐罐对应的模型有一些偏置(白色罐和实际不重合对应,但是坐标原点确实是实际可乐罐的位置),不知道源程序作者为什么要这样设置,之后再研究。
如果检测到的话则会输出:

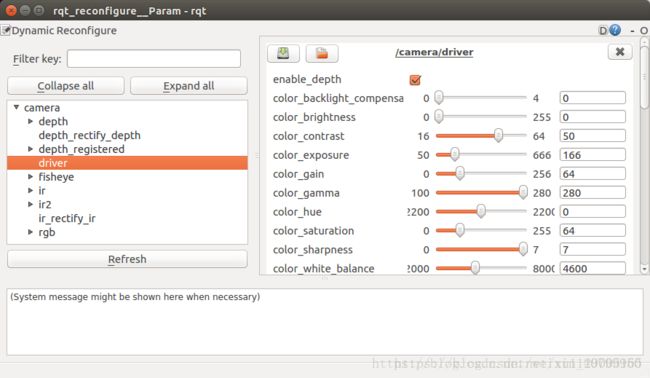
注:如果出现不了点云图或者运行过程中没有了点云图只有罐体以及坐标就按下面:
#rosrun rqt_reconfigure rqt_reconfigure
在下拉菜单中的driver中重新点击启动enable_depth(打钩)。类似下面这样卡住的情形(在rosrun detection的时候出现)

8.测试
#rostopic list
可以看到ork发布的话题信息/recognized_object_array
#rostopic echo /recognized_object_array
即可实时查看位置信息
#rostopic type /recognized_object_array
使用type来查看发布信息的类型,方便以后listener订阅talker,处理该信息发送给机械臂处理执行抓取任务。

这里就有了xyz以及物体识别的信息了,位姿估计及位置计算。


用rqt可以查看当前运行的全部节点 话题信息(方形),还可以看活跃的节点。
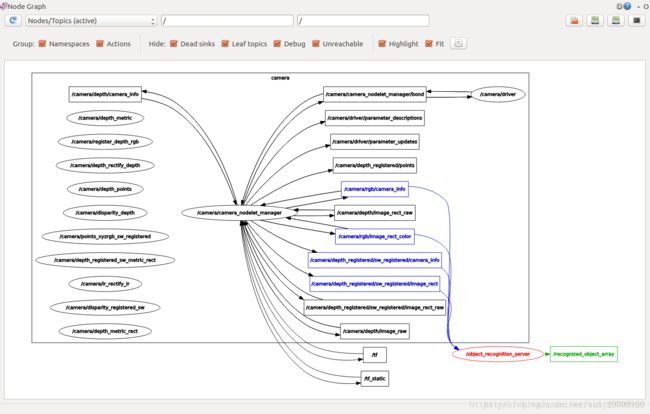
可以看到当前运行的两个例程中还有很多节点未使用,在以后的工作中逐步再处理应用。
另外,linemod算法实时显示图像并进行物体识别会卡,可以
#cd ~/catkin_ws目录,将之前的debug版本换为release版本,重新编译
#catkin_make -DCMAKE_BUILD_TYPE="Release"
并且,可以在system Monitor中(点最左上角图标 搜sys…)可以查看cpu占用情况。
9.后续展望
此项目输出:object_recognition_msgs/RecognizedObjectArray
之后针对该位置读取位置信息发送给机械臂即可继续下一步的工作。
#ipython
(ipython是python的进阶版,比python更好用,需要安装。以后用的多了再比较好用在哪儿)
#import rospy
#from object_recognition_msgs.msg import RecognizedObjectArray, RecognizedObject
将_msg包包含的信息导入,之后即可用例如
#msg=RecognizedObject()
来存储到msg(例如输入msg.pose.直接tap就可以查看所有的信息)并编写listener python程序订阅,得到信息并处理。

基本用了两个星期的时间做出来机器人的眼,这样就可以识别物体以及得到其位姿,接下来就是对接机械臂,将点坐标发送给机械臂使其执行抓取任务。接下来的任务就是实践发布话题、订阅话题,用python将结果记录下来以便后续处理识别。另外还要总结内容、深入的理解一下linemod以及这个流程,包括match的三个参数、icp以及之前看到的icp+nss?进行后续的处理(物体重叠的时候)。