- 数据机构 C语言实现队列(含代码详解 易懂)
码上好玩
/*数学模型参照《大话数据结构》队列部分!!!取余运算实现队列循环!!!*/#include#include#include#include#defineOK1#defineERROR0#defineTURE1#defineFALSE0#defineMAXSIZE20/*队列最大的成员个数即数组的长度*/typedefintStatus;typedefintQElemType;/*循环队列的顺序存
- 《大话数据结构》-程杰自学数据结构感悟
安夏886
数据结构算法
Chatzero:前言-2024.4.22作者著书的感慨记录:1.不管如何,现在您看到了这本书,那就说明我已经克服了困难战胜了自己。悟:探索一个新的领域,例如写书,本来就会有许多困难,对照我自身也是如此。但是,怕而不退,畏而不缩,这是我和作者所共同追求的,幸福感满满!2.好的自学读物的目标是让初学者“独自”全盘掌握知识,需要强调“独自”一词,这就说明读者在阅读时,是完全依靠自己的力量来向未知出发挑
- 线性表(java实现)
Coding9933
本文整理自《大话数据结构》及传智播客视频教程1.线性表定义线性表是由零个或多个数据元素组成的有限序列。根据它的定义,可以得出以下几点序列,说明线性表是有序的,若存在多个元素,第一个元素无前驱,最后一个元素无后继,其他元素都有且只有一个前驱和后继;有限,说明数据元素个数是有限的;最后一个,数据元素的类型必须相同;线性表能够逐项访问和顺序存取。2.线性表数学定义线性表是具有相同类型的n(≥0)个数据元
- 【学习总结】240131_数据结构与算法(六)
豆乳麻薯
学习
《大话数据结构》读书笔记+课程补充每日一个例题示范一、读书笔记+课程补充顺序存储顺序查找:最好情况——1次最坏情况——n平均时间复杂度——O(n)再该情况下算法的基本操作重复执行次数随问题的输入数据集有所不同考虑最坏时间复杂度(一般考虑)平均时间复杂度最好时间复杂度渐进空间复杂度:S(n)=O(f(n))n为问题的规模或大小分析例题:将一维数组a中的n个数逆序放到原数组中:for(i=0;i#in
- 【学习总结】240128_数据结构与算法(三)
豆乳麻薯
学习
《大话数据结构》读书笔记+课程补充一、读书笔记+课程补充往期知识回顾:1.抽象数据类型“复数的实现”typedefstruct{floatrealpart;floatimapart;}Complex调用函数则有:voidassign(Complex*A,floatreal,floatimag);voidadd(Complex*A,floatreal,floatimag);2.C语言实现抽象数据类型
- 【学习总结】240129_数据结构与算法(四)
豆乳麻薯
学习
《大话数据结构》读书笔记+课程补充每日一个例题示范一、读书笔记+课程补充有关线性表:零个或多个数据元素的有限序列(前驱后继)当n=0,称为空表。称i为数据元素ai在线性表中的位序。线性表的顺序存储结构:指用一段地址连续的存储单元依次存储线性表的数据元素。使用一维数组来实现顺序存储结构。长度即最大存储容量。例如:存储器中的每个存储单元都有自己的编号,这个编号称为地址。二、每日一个例题示范自然数的拆分
- 【学习总结】240201_数据结构与算法(七)
豆乳麻薯
学习
《大话数据结构》读书笔记+课程补充每日一个例题示范一、读书笔记+课程补充抽象数据类型线性表定义:ADTList{}ADTList初始化线性表销毁插入删除线性表等构造一个空的线性表——InitList(&L)销毁线性表(前提是存在)——DestroyList(&L)重置为空表——ClearList(&L)判断线性表是否为空——ListEmpty(L)若为空表则返回ture否则返回false返回数据元
- 【学习总结】2401230_数据结构与算法(五)
豆乳麻薯
学习
《大话数据结构》读书笔记+课程补充每日一个例题示范一、读书笔记+课程补充(50页)分析算法时间复杂度的基本方法尽量简化取数量级符号"O"选择最高次再化简O(n^2)时间复杂度是由嵌套最深层语句的频度决定的。分析时间复杂度的例题循环执行推导:找到执行次数最后取时间复杂度为T(n)=O(log2n)二、每日一个例题示范高手去散步题目描述鳌头山上有�n个观景点,观景点两两之间有游步道共�m条。高手的那个
- 【学习总结】240202_数据结构与算法(八)
豆乳麻薯
学习
《大话数据结构》读书笔记+课程补充每日一个例题示范一、读书笔记+课程补充今天来汇集一下代码中的一些常见调试步骤和潜在问题:确保包含函数所需的库。常量和数组:确保常量适合实际问题,并且数组的大小正确。输入读数:验证输入是否被正确读取。确保值在可接受的范围内。内存溢出:检查相关值是否不超过数组大小。队列数组大小确定。数组边界:确保数组索引不会越界。否则可能会导致内存损坏和未定义的行为。循环条件:验证循
- 理论学习-C/C++编程-算法学习笔记
用户昵称100
C/C++编程理论指导算法学习c++链表
TOC读《大话数据结构》链表 初看链表程序,就是把指针包装成结构体,前后链接起来。觉得道理浅显易懂,但是自己写又很难写好,只能去copy。明显自己没有学到精髓。 后来,也许是看的多了。不自觉意识到写链表需要提炼的核心要点。帮助写好链表: ①,注意插入的位置。上图“将S插入P之后”,所以在四条语句中都只应用了S和P节点,P节点作为唯一绝对位置,其他节点也只是应用P->next索引。对于“删除节点P”
- 数据结构--克鲁斯卡尔(kruskal)算法(大话数据结构)
欧_aita
数据结构与算法数据结构算法图论
克鲁斯卡尔算法的个人解析笔记什么是克鲁斯卡尔(kruskal)算法克鲁斯卡尔算法与普里姆算法的区别在哪里呢克鲁斯卡尔算法实现宏定义对边集数组进行定义克鲁斯卡尔算法Find函数定义主函数测试代码解读什么是克鲁斯卡尔(kruskal)算法这里我们选用普里姆(prim)算法作为对比,prim算法是从一个顶点开始搜索最小路径,而克鲁斯卡尔算法是通过一个遍历好的边集数组搜索出一条最短路径。(最短路径的本质就
- 《大话数据结构》笔记——第8章 查找(二)
bm1998
#《大话数据结构》数据结构
文章目录8.6二叉排序树8.6.1二叉排序树查找操作8.6.2二叉排序树插入操作8.6.3二叉排序树删除操作8.6.4二叉排序树总结8.7平衡二叉树(AVL树)8.7.1平衡二叉树实现原理8.7.2平衡二叉树实现算法声明:本博客是本人在学习《大话数据结构》后整理的笔记,旨在方便复习和回顾,并非用作商业用途。本博客已标明出处,如有侵权请告知,马上删除。8.6二叉排序树假设查找的数据集是普通的顺序存储
- 《大话数据结构》之栈与队列
我才是臭吉吉
1.栈1.1定义栈,即只能在表尾进行插入或删除操作的线性表。其中,“表尾”称为“栈顶”,另一端则为“栈底”。栈是“后进先出”(LIFO)的线性表。1.2栈的顺序存储结构我们使用数组来描述栈的顺序存储结构。使用指针top来定义栈顶指针,其一直指向数组的最后一个元素的索引。空栈即top为-1。由于使用数组实现,故顺序栈在初始化时需要指定最大存储容量。1.2.1入栈取出数组下一位置的索引(同时更新栈顶t
- 二分查找刷题
Sking426
算法数据结构
本人目前在一所普通高校研究生在读,写笔记的目的是为了记录下自己刷题的内容,方便日后观看。参考书目:《大话数据结构》------程杰《图解算法》---------袁国忠译《深入浅出程序设计竞赛--基础篇》------汪楚奇本文结合《图解算法》的书作为参考,第一章涉及到二分查找的内容,再针对性的对二分查找刷题。练习的题目来源《深入浅出程序设计竞赛--基础篇》,本文将按照自己做题的思路以及书上例子的参考
- 校招LeetCode精选题目
Mr Liu的个人博客
校招leetcode散列表算法
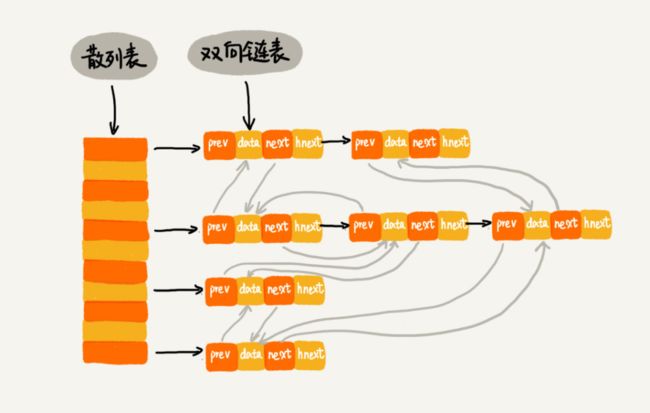
不管是春招还是秋招,校招生是避免不了刷题操作的,今天我总结了一下自己秋招过程对leetcode题目进行分类并针对性练习的过程。一些基本的数据结构练习,建议结合大话数据结构这本书食用。里面有一部分语言特性,注意总结与分析,有助于加深数据结构基础的理解。基本数据结构总结推荐题目:LeetCode1.TwoSumLeetCode187.RepeatedDNASequencesLeetCode706.De
- Java进阶核⼼之集合框架Collection
不吃青椒!
javasejava
一,计算机核心基础之大话数据结构(精简速成)数据在内存中,它有连续的结构,也有不连续的结构,比如数组,里面的每一个数据的内存地址都是连续的,当然也有非连续的。为了方便理解数据结构,这里我们举一个例子,比如一个小区,有好多的公寓,如果他们公寓号从一公寓到n公寓,整齐排列,那么我们快递员就很容易的送货,这里可以理解为数组非连续数据包结构我们以链表为例,比如快递人员相送一个公寓,但是公寓号很乱,没在一起
- c++服务端书籍进阶书籍推荐
幽若风
入门路线规划:其中这些书可以并行参考,最好是边用边看,有效果,一.基础阶段c/c++编程语言《C++Primer》《EffectiveC++》《深度探索C++对象模型《STL源代码剖析》2.linux基础《鸟哥的Linux私房菜-基础学习篇》《跟我一起学makefile》3.数据结构与算法《大话数据结构》《算法第四版》4.设计模式《大话设计模式》《经典版的C++设计模式》5.脚本语言(可选)《py
- 经典算法问题:赫夫曼树以及赫夫曼编码
李威威
是能使得给定的字符串编码成01串后长度最短的前缀编码。1、编码问题:ASCII码:一共128个:http://tool.oschina.net/commons?type=42、前缀码:前缀唯一3、频率越高,编码越短4、等长编码与不等长编码5、构建出二叉树,左分支走0,右分支走16、非叶子结点上出现前缀,没有二义性7、WLP值一样。参考资料:《大话数据结构》算法导论第200页:殷人昆《数据结构》赫夫
- 2019年读书计划
鑫涛0603
完成24本书籍阅读,每月两本,并产出对应笔记,费曼笔记。历史《半小时漫画中国史+世界史》《明朝那些事》《三国全史》项目管理或个人提高《原则》《金字塔原理》《墨菲定律》《自控力》沟通技巧《非暴力沟通》《高效能人士的七个习惯》技术提高《智能时代》《高性能MySql》《大话数据结构》《EffectiveJava》《HeadFirstJava第2版》《疯狂java讲义》《阿里巴巴Java开发手册》《Spr
- 冒泡排序 选择排序 插入排序 快速排序 堆排序 希尔排序的C语言实现
weixin_44033321
c语言排序算法数据结构
平台:VS2019参考:《大话数据结构》#include#defineMAXSIZE10typedefstruct{intr[MAXSIZE+1];/*r[0]用作哨兵或临时变量*/intlength;}SqList;/*交换*/voidswap(SqList*L,inti,intj){inttemp;temp=L->r[i];L->r[i]=L->r[j];L->r[j]=temp;}/*冒泡排
- 排序算法三之堆排序
thepeakofmountain
数据结构排序算法算法c语言堆排序
这次介绍堆排序,堆排序分为2步,1.建堆2.排序但是建堆的过程是对堆进行调整,而排序的过程实际上也是对堆调整,堆排序,是基于完全二叉树的,凡是和树和图相关的,总是需要多花点时间弄懂,哎,基础太差。所以关键是对堆的调整,下面的代码和图用的是大顶堆,代码是参考大话数据结构,理解了之后自己动手敲的。调整的过程如下图所示,但是为了显示一个过程,图7、图8最后的虚线是visio一页不足所致,红色为每次要调整
- python 排序算法(未完待续)
林疏浅阳
内容源自哔哩哔哩up主青岛大学--王卓的算法数据结构以及大话数据结构(虽然网上已经有很多资料了,但是自己理解了再写一遍感觉印象更深刻,所以记录下来,以便以后查阅)选择排序:(1)简单选择排序(2)堆排序(1)简单选择排序基本思想是在待排序的数据中选出最大(小)的元素放在最终的位置。具体过程:1)首先通过n-1次关键字比较,从n个记录中找出关键字最小的记录,将其与第一个记录交换2)再通过n-2次比较
- 《大话数据结构》学习笔记--线性表
yuqiong11
数据结构链表
第三章线性表什么是线性表线性表的顺序存储结构基本概念及特性顺序存储结构的存取操作顺序存储结构的插入和删除操作顺序存储结构的优缺点线性表的链式存储结构单链表基本概念及特性单链表的读取操作单链表的插入和删除操作单链表的整表创建和删除静态链表循环链表双链表总结什么是线性表线性表(List)是零个或多个数据元素的有限序列,每个数据元素的数据类型相同。线性表是依据数据的逻辑结构定义的,即数据在逻辑结构上是线
- 《大话数据结构》第三章学习笔记--线性表(一)
MogulNemenis
学习总结数据结构算法链表
线性表的定义线性表:零个或多个数据元素的有限序列。线性表元素的个数n定义为线性表的长度。n为0时,为空表。在比较复杂的线性表中,一个数据元素可以由若干个数据项组成。线性表的存储结构顺序存储结构可以用C语言中的一维数组来实现,每个数据元素的类型都相同。描述顺序结构存储结构需要三个属性:1.存储空间的起始位置:数组date,它的存储位置就是存储空间的存储位置。。2.线性表的最大存储容量:数组长度max
- 大话数据结构||学习笔记||从开头至链表||c/c++
kkkkkkkkkkaZZL
笔记数据结构算法
一day41时间复杂度1-1线性阶1-2对数阶1-3平方阶常见时间复杂度表2线性表2-1线性表顺序存储结构线性表的长度与数组长度区分线性表的顺序存储的结构代码#defineMAXSIZE20//存储空间初始分配量typedefintElemType;//暂定inttypedefstruct{ElemTypedate[MAXSIZE];//数组存储数据成员,最大值为MAXSIZEintlength;
- 数据结构初阶--复杂度分析
yoouuung_
数据结构数据结构
数据结构练习:大话数据结构殷人昆c++剑指offer和程序员代码面试指南leetcode牛客数据结构是计算机存储、组织数据的方式,指相互之间存在一种或多种特定关系的数据元素的集合算法就是定义良好的计算过程,取一个或一组的值为输入,并产生出一个或一组值作为输出。1.时间复杂度时间复杂度主要衡量一个算法运行快慢算法的时间复杂度是一个函数(数学中带未知数函数式)算法中的基本操作执行次数,为算法的时间复杂
- 大话数据结构之时间复杂度和空间复杂度详解
xiaoming3526
算法数据结构大话数据结构时间复杂度空间复杂度
一、算法的复杂度:算法的复杂度分为时间复杂度和空间复杂度。时间复杂度是指衡量算法执行时间的长短;空间复杂度是指衡量算法所需存储空间的大小。二、算法时间复杂度定义:在进行算法分析时候,语句总的执行次数T(n)是关于问题规模n的函数,进而分型T(n)随着n的变化情况并确定T(n)的数量级.算法的时间复杂度,也就是算法的时间度量记作:T(n)=O(f(n)).它表示随着问题规模n的增大,算法执行时间的增
- 大话数据结构-1 基础
李楠30
逻辑结构与物理结构逻辑结构指数据对象中数据元素之间的相互关系。分为四种:集合结构:数据元素除了同一属性属于一个集合外,他们之间没有其他关系。线性结构:数据元素之间是一对一的关系。树形结构:数据元素之间存在一对多的层次关系。图形结构:数据元素是多对多的关系。逻辑结构是针对具体问题的,是为了解决某个问题,在对问题理解的基础上,选择一个合适的数据结构表示数据元素之间的逻辑关系。物理结构指数据的逻辑结构在
- 数据结构_note
xiaoyuyulala
基础知识即其他数据结构
数据结构真的非常重要,不光是为了应付考试,至今觉得数据结构和编译原理没有学得特别好太遗憾了,给自己做个笔记结合大话数据结构以及天勤2019数据结构计算机考研复习指导PS:之前学数据结构的时候直接看严蔚敏的觉得太硬核了第1章绪论具体是啥翻书,记录一下常用的O(1)#include#include#definemaxSize100//定义一个顺序表typedefstruct{intdata[maxSi
- 大话数据结构之线性表--链式存储结构单链表的c++实现
Surplus°
数据结构数据结构链表
目录数据结构之线性表基本概念线性表的存储结构顺序存储链式存储链式存储结构单链表的C++实现单链表的存储结构判断链表是否为空链表返回链表的长度寻找元素获取元素插入节点删除节点头插法创建单链表尾插法创建单链表单链表的整表删除打印单链表完整代码本文简单介绍了线性表的基本概念以及具体的代码实现,并在文末提供了代码下载链接。如果有错误的地方还请不吝赐教!数据结构之线性表基本概念线性表:零个或多个数据元素的有
- js动画html标签(持续更新中)
843977358
htmljs动画mediaopacity
1.jQuery 效果 - animate() 方法 改变 "div" 元素的高度: $(".btn1").click(function(){ $("#box").animate({height:"300px
- springMVC学习笔记
caoyong
springMVC
1、搭建开发环境
a>、添加jar文件,在ioc所需jar包的基础上添加spring-web.jar,spring-webmvc.jar
b>、在web.xml中配置前端控制器
<servlet>
&nbs
- POI中设置Excel单元格格式
107x
poistyle列宽合并单元格自动换行
引用:http://apps.hi.baidu.com/share/detail/17249059
POI中可能会用到一些需要设置EXCEL单元格格式的操作小结:
先获取工作薄对象:
HSSFWorkbook wb = new HSSFWorkbook();
HSSFSheet sheet = wb.createSheet();
HSSFCellStyle setBorder = wb.
- jquery 获取A href 触发js方法的this参数 无效的情况
一炮送你回车库
jquery
html如下:
<td class=\"bord-r-n bord-l-n c-333\">
<a class=\"table-icon edit\" onclick=\"editTrValues(this);\">修改</a>
</td>"
j
- md5
3213213333332132
MD5
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
public class MDFive {
public static void main(String[] args) {
String md5Str = "cq
- 完全卸载干净Oracle11g
sophia天雪
orale数据库卸载干净清理注册表
完全卸载干净Oracle11g
A、存在OUI卸载工具的情况下:
第一步:停用所有Oracle相关的已启动的服务;
第二步:找到OUI卸载工具:在“开始”菜单中找到“oracle_OraDb11g_home”文件夹中
&
- apache 的access.log 日志文件太大如何解决
darkranger
apache
CustomLog logs/access.log common 此写法导致日志数据一致自增变大。
直接注释上面的语法
#CustomLog logs/access.log common
增加:
CustomLog "|bin/rotatelogs.exe -l logs/access-%Y-%m-d.log
- Hadoop单机模式环境搭建关键步骤
aijuans
分布式
Hadoop环境需要sshd服务一直开启,故,在服务器上需要按照ssh服务,以Ubuntu Linux为例,按照ssh服务如下:
sudo apt-get install ssh
sudo apt-get install rsync
编辑HADOOP_HOME/conf/hadoop-env.sh文件,将JAVA_HOME设置为Java
- PL/SQL DEVELOPER 使用的一些技巧
atongyeye
javasql
1 记住密码
这是个有争议的功能,因为记住密码会给带来数据安全的问题。 但假如是开发用的库,密码甚至可以和用户名相同,每次输入密码实在没什么意义,可以考虑让PLSQL Developer记住密码。 位置:Tools菜单--Preferences--Oracle--Logon HIstory--Store with password
2 特殊Copy
在SQL Window
- PHP:在对象上动态添加一个新的方法
bardo
方法动态添加闭包
有关在一个对象上动态添加方法,如果你来自Ruby语言或您熟悉这门语言,你已经知道它是什么...... Ruby提供给你一种方式来获得一个instancied对象,并给这个对象添加一个额外的方法。
好!不说Ruby了,让我们来谈谈PHP
PHP未提供一个“标准的方式”做这样的事情,这也是没有核心的一部分...
但无论如何,它并没有说我们不能做这样
- ThreadLocal与线程安全
bijian1013
javajava多线程threadLocal
首先来看一下线程安全问题产生的两个前提条件:
1.数据共享,多个线程访问同样的数据。
2.共享数据是可变的,多个线程对访问的共享数据作出了修改。
实例:
定义一个共享数据:
public static int a = 0;
- Tomcat 架包冲突解决
征客丶
tomcatWeb
环境:
Tomcat 7.0.6
win7 x64
错误表象:【我的冲突的架包是:catalina.jar 与 tomcat-catalina-7.0.61.jar 冲突,不知道其他架包冲突时是不是也报这个错误】
严重: End event threw exception
java.lang.NoSuchMethodException: org.apache.catalina.dep
- 【Scala三】分析Spark源代码总结的Scala语法一
bit1129
scala
Scala语法 1. classOf运算符
Scala中的classOf[T]是一个class对象,等价于Java的T.class,比如classOf[TextInputFormat]等价于TextInputFormat.class
2. 方法默认值
defaultMinPartitions就是一个默认值,类似C++的方法默认值
- java 线程池管理机制
BlueSkator
java线程池管理机制
编辑
Add
Tools
jdk线程池
一、引言
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。第三:提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
- 关于hql中使用本地sql函数的问题(问-答)
BreakingBad
HQL存储函数
转自于:http://www.iteye.com/problems/23775
问:
我在开发过程中,使用hql进行查询(mysql5)使用到了mysql自带的函数find_in_set()这个函数作为匹配字符串的来讲效率非常好,但是我直接把它写在hql语句里面(from ForumMemberInfo fm,ForumArea fa where find_in_set(fm.userId,f
- 读《研磨设计模式》-代码笔记-迭代器模式-Iterator
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.util.Arrays;
import java.util.List;
/**
* Iterator模式提供一种方法顺序访问一个聚合对象中各个元素,而又不暴露该对象内部表示
*
* 个人觉得,为了不暴露该
- 常用SQL
chenjunt3
oraclesqlC++cC#
--NC建库
CREATE TABLESPACE NNC_DATA01 DATAFILE 'E:\oracle\product\10.2.0\oradata\orcl\nnc_data01.dbf' SIZE 500M AUTOEXTEND ON NEXT 50M EXTENT MANAGEMENT LOCAL UNIFORM SIZE 256K ;
CREATE TABLESPA
- 数学是科学技术的语言
comsci
工作活动领域模型
从小学到大学都在学习数学,从小学开始了解数字的概念和背诵九九表到大学学习复变函数和离散数学,看起来好像掌握了这些数学知识,但是在工作中却很少真正用到这些知识,为什么?
最近在研究一种开源软件-CARROT2的源代码的时候,又一次感觉到数学在计算机技术中的不可动摇的基础作用,CARROT2是一种用于自动语言分类(聚类)的工具性软件,用JAVA语言编写,它
- Linux系统手动安装rzsz 软件包
daizj
linuxszrz
1、下载软件 rzsz-3.34.tar.gz。登录linux,用命令
wget http://freeware.sgi.com/source/rzsz/rzsz-3.48.tar.gz下载。
2、解压 tar zxvf rzsz-3.34.tar.gz
3、安装 cd rzsz-3.34 ; make posix 。注意:这个软件安装与常规的GNU软件不
- 读源码之:ArrayBlockingQueue
dieslrae
java
ArrayBlockingQueue是concurrent包提供的一个线程安全的队列,由一个数组来保存队列元素.通过
takeIndex和
putIndex来分别记录出队列和入队列的下标,以保证在出队列时
不进行元素移动.
//在出队列或者入队列的时候对takeIndex或者putIndex进行累加,如果已经到了数组末尾就又从0开始,保证数
- C语言学习九枚举的定义和应用
dcj3sjt126com
c
枚举的定义
# include <stdio.h>
enum WeekDay
{
MonDay, TuesDay, WednesDay, ThursDay, FriDay, SaturDay, SunDay
};
int main(void)
{
//int day; //day定义成int类型不合适
enum WeekDay day = Wedne
- Vagrant 三种网络配置详解
dcj3sjt126com
vagrant
Forwarded port
Private network
Public network
Vagrant 中一共有三种网络配置,下面我们将会详解三种网络配置各自优缺点。
端口映射(Forwarded port),顾名思义是指把宿主计算机的端口映射到虚拟机的某一个端口上,访问宿主计算机端口时,请求实际是被转发到虚拟机上指定端口的。Vagrantfile中设定语法为:
c
- 16.性能优化-完结
frank1234
性能优化
性能调优是一个宏大的工程,需要从宏观架构(比如拆分,冗余,读写分离,集群,缓存等), 软件设计(比如多线程并行化,选择合适的数据结构), 数据库设计层面(合理的表设计,汇总表,索引,分区,拆分,冗余等) 以及微观(软件的配置,SQL语句的编写,操作系统配置等)根据软件的应用场景做综合的考虑和权衡,并经验实际测试验证才能达到最优。
性能水很深, 笔者经验尚浅 ,赶脚也就了解了点皮毛而已,我觉得
- Word Search
hcx2013
search
Given a 2D board and a word, find if the word exists in the grid.
The word can be constructed from letters of sequentially adjacent cell, where "adjacent" cells are those horizontally or ve
- Spring4新特性——Web开发的增强
jinnianshilongnian
springspring mvcspring4
Spring4新特性——泛型限定式依赖注入
Spring4新特性——核心容器的其他改进
Spring4新特性——Web开发的增强
Spring4新特性——集成Bean Validation 1.1(JSR-349)到SpringMVC
Spring4新特性——Groovy Bean定义DSL
Spring4新特性——更好的Java泛型操作API
Spring4新
- CentOS安装配置tengine并设置开机启动
liuxingguome
centos
yum install gcc-c++
yum install pcre pcre-devel
yum install zlib zlib-devel
yum install openssl openssl-devel
Ubuntu上可以这样安装
sudo aptitude install libdmalloc-dev libcurl4-opens
- 第14章 工具函数(上)
onestopweb
函数
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- Xelsius 2008 and SAP BW at a glance
blueoxygen
BOXelsius
Xelsius提供了丰富多样的数据连接方式,其中为SAP BW专属提供的是BICS。那么Xelsius的各种连接的优缺点比较以及Xelsius是如何直接连接到BEx Query的呢? 以下Wiki文章应该提供了全面的概览。
http://wiki.sdn.sap.com/wiki/display/BOBJ/Xcelsius+2008+and+SAP+NetWeaver+BW+Co
- oracle表空间相关
tongsh6
oracle
在oracle数据库中,一个用户对应一个表空间,当表空间不足时,可以采用增加表空间的数据文件容量,也可以增加数据文件,方法有如下几种:
1.给表空间增加数据文件
ALTER TABLESPACE "表空间的名字" ADD DATAFILE
'表空间的数据文件路径' SIZE 50M;
&nb
- .Net framework4.0安装失败
yangjuanjava
.netwindows
上午的.net framework 4.0,各种失败,查了好多答案,各种不靠谱,最后终于找到答案了
和Windows Update有关系,给目录名重命名一下再次安装,即安装成功了!
下载地址:http://www.microsoft.com/en-us/download/details.aspx?id=17113
方法:
1.运行cmd,输入net stop WuAuServ
2.点击开