hadoop+zookeeper
系统环境:RHEL6.5 selinux and iptables is disabled
Hadoop 、jdk、zookeeper 程序使用 nfs 共享同步配置文件
软件版本:hadoop-2.7.3.tar.gz zookeeper-3.4.9.tar.gz jdk-7u79-linux-x64.tar.gz
hbase-1.2.4-bin.tar.gz
172.25.40.1:NameNode
DFSZKFailoverController
ResourceManager
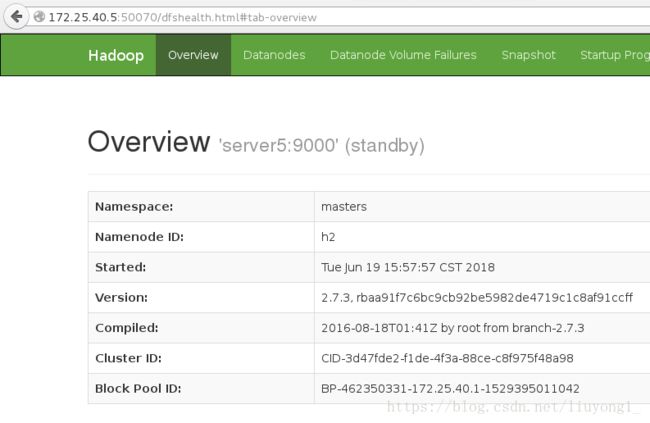
172.25.40.5:NameNode
DFSZKFailoverController
ResourceManager
172.25.40.2:JournalNode
QuorumPeerMain (zookeeper)
DataNode
NodeManager
172.25.40.3:JournalNode
QuorumPeerMain
DataNode
NodeManager
172.25.40.4:JournalNode
QuorumPeerMain
DataNode
NodeManager
1.配置zookeeper:至少三台,总节点数为奇数个
安装:
tar zxf jdk-7u79-linux-x64.tar.gz
tar zxf zookeeper-3.4.10.tar.gz编辑 zoo.cfg 文件:
/home/hadoop/zookeeper-3.4.10/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
server.1=172.25.40.2:2888:3888
server.2=172.25.40.3:2888:3888
server.3=172.25.40.4:2888:3888在默认数据目录下/tmp/zookeeper/ 创建 myid 文件,写入
一个唯一的数字,取值范围在 1-255。比如:172.25.40.2 节点的 myid 文件写入数
字“1”,此数字与配置文件中的定义保持一致,(server.1=172.25.40.2:2888:3888
)其它节点依次类推。
rm -fr /tmp/*
mkdir /tmp/zookeeper
echo x > /tmp/zookeeper/myid启动:
bin/zkServer.sh start
bin/zkServer.sh status


连接 zookeeper
bin/zkCli.sh 
- Hadoop 配置
hadoop-2.7.3.tar.gz
编辑 core-site.xml 文件:
<property>
<name>fs.defaultFSname>
<value>hdfs://mastersvalue>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>172.25.40.3:2181,172.25.40.2:2181,172.25.40.4:2181value>
property>编辑 hdfs-site.xml 文件
<configuration>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.nameservicesname>
<value>mastersvalue>
property>
<property>
<name>dfs.ha.namenodes.mastersname>
<value>h1,h2value>
property>
<property>
<name>dfs.namenode.rpc-address.masters.h1name>
<value>172.25.40.1:9000value>
property>
<property>
<name>dfs.namenode.http-address.masters.h1name>
<value>172.25.40.1:50070value>
property>
<property>
<name>dfs.namenode.rpc-address.masters.h2name>
<value>172.25.40.5:9000value>
property>
<property>
<name>dfs.namenode.http-address.masters.h2name>
<value>172.25.40.5:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://172.25.40.3:8485;172.25.40.2:8485;172.25.40.4:8485/mastersvalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/tmp/journaldatavalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.mastersname>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>
sshfence
shell(/bin/true)
value>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/home/hadoop/.ssh/id_rsavalue>
property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeoutname>
<value>30000value>
property>
configuration>配置免密
由于是nfs文件共享所以免密存在
3.启动 hdfs 集群(按顺序启动)
1)在三个 DN 上依次启动 zookeeper 集群
bin/zkServer.sh start
2)在三个 DN 上依次启动 journalnode(第一次启动 hdfs 必须先启动 journalnode)
sbin/hadoop-daemon.sh start journalnode[hadoop@server2 ~]$ jps
1493 JournalNode
1222 QuorumPeerMain
1594 Jps3)格式化 HDFS 集群
bin/hdfs namenode -formatNamenode 数据默认存放在/tmp,需要把数据拷贝到 h2
scp -rp /tmp/hadoop-hadoop 172.25.40.5:/tmp3) 格式化 zookeeper (只需在 h1 上执行即可)
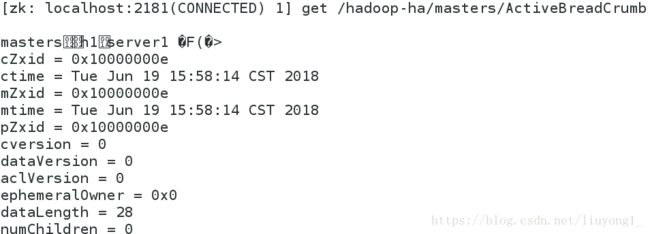
bin/hdfs zkfc -formatZK #注意大小写4)启动 hdfs 集群(只需在 h1 上执行即可)
sbin/start-dfs.sh5) 查看各节点状态
[hadoop@server1 hadoop]$ jps
1897 Jps
1727 DFSZKFailoverController
1433 NameNode
[hadoop@server5 ~]$ jps
1308 Jps
1163 NameNode
1260 DFSZKFailoverController
[hadoop@server2 hadoop]$ jps
1424 Jps
1324 DataNode
1233 JournalNode
1137 QuorumPeerMain
[hadoop@server3 hadoop]$ jps
1404 DataNode
1504 Jps
1314 JournalNode
1139 QuorumPeerMain
[hadoop@server4 hadoop]$ jps
1250 DataNode
1350 Jps
1160 JournalNode
1120 QuorumPeerMain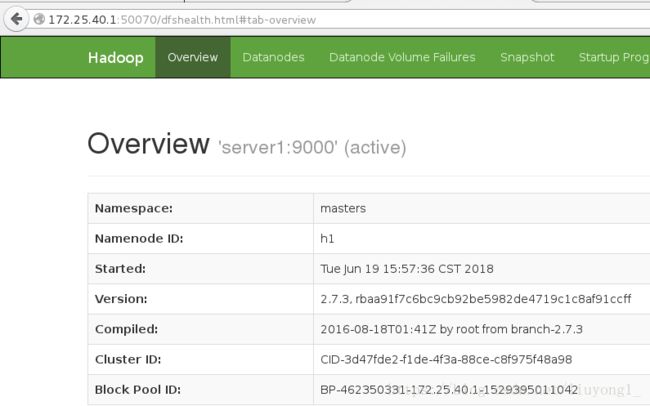
此时可进行测试:
./hdfs dfsadmin -report
./hdfs dfs -mkdir /user
./hdfs dfs -mkdir /user/hadoop
./hdfs dfs -ls
./hdfs dfs -put ../etc/hadoop/6) 测试故障自动切换
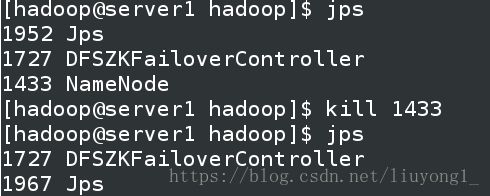
杀掉 h1 主机的 namenode 进程后依然可以访问,此时 h2 转为 active 状态接
管 namenode
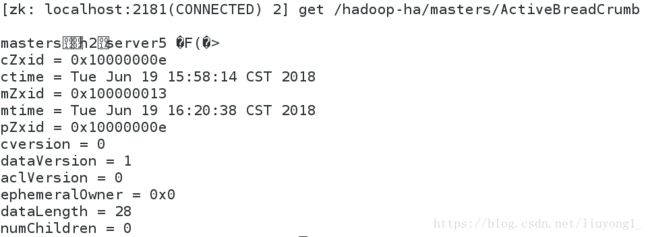
启动 h1 上的 namenode,此时为 standby 状态
sbin/hadoop-daemon.sh start namenode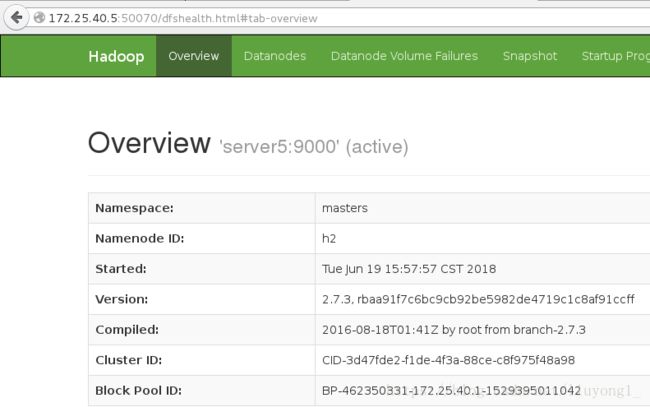
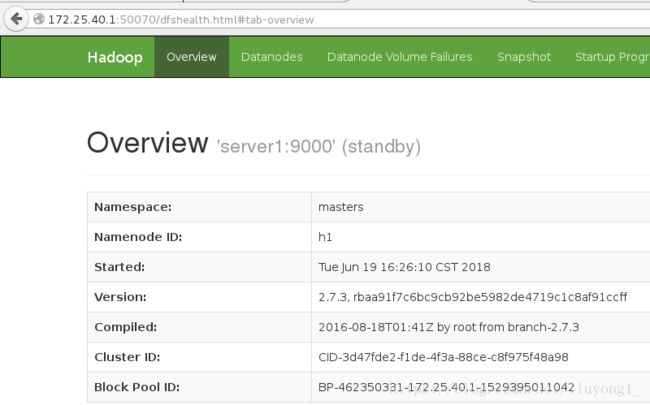
hdfs 的高可用完成
yarn 的高可用:
1) 编辑 mapred-site.xml 文件
/home/hadoop/hadoop/etc/hadoop
cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>2)编辑 yarn-site.xml 文件
vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>RM_CLUSTERvalue>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>172.25.40.1value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>172.25.40.5value>
property>
<property>
<name>yarn.resourcemanager.recovery.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.store.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStorevalue>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>172.25.40.2:2181,172.25.40.3:2181,172.25.40.4:2181value>
property>
configuration>3)启动 yarn 服务
sbin/start-yarn.sh
RM2 上需要手动启动
sbin/yarn-daemon.sh start resourcemanager
最好是把 RM 与 NN 分离运行,这样可以更好的保证程序的运行性能
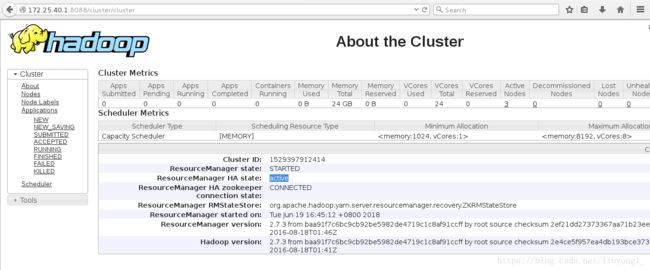
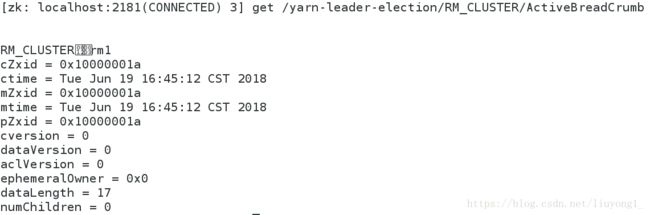
4) 测试 yarn 故障切换
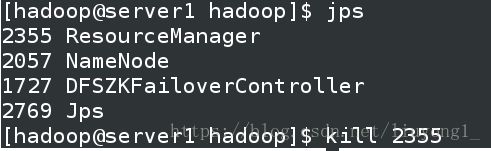
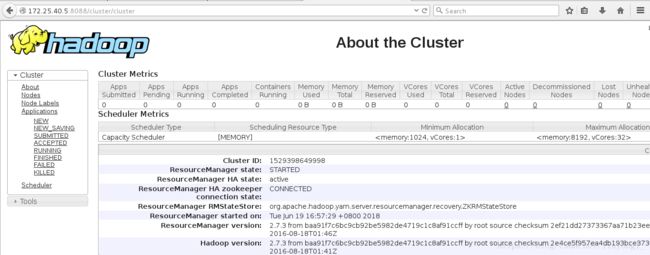
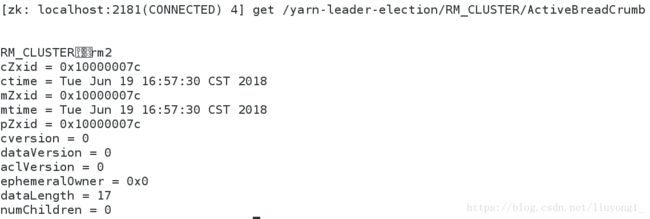
Hbase 分布式部署
1) hbase 配置
tar zxf hbase-1.2.4-bin.tar.gz配置环境:
/home/hadoop/hbase-1.2.4/conf/
vim hbase-env.sh
export JAVA_HOME=/home/hadoop/java 指定 jdk
export HADOOP_HOME=/home/hadoop/hadoop 指定 hadoop 目录,否则 hbase
无法识别 hdfs 集群配置
export HBASE_MANAGES_ZK=false 默认值时 true,hbase 在启动时自
动开启 zookeeper,如需自己维护 zookeeper 集群需设置为 falsevim hbase-site.xml
<configuration>
<property>
<name>hbase.rootdirname>
<value>hdfs://masters/hbasevalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>172.25.40.2,172.25.40.3,172.25.40.4value>
property>
<property>
<name>hbase.mastername>
<value>h1value>
property>
configuration>vim regionservers
172.25.40.2
172.25.40.3
172.25.40.42) 启动 hbase
主节点运行:
bin/start-hbase.sh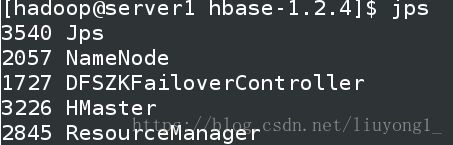
备节点运行:
bin/hbase-daemon.sh start master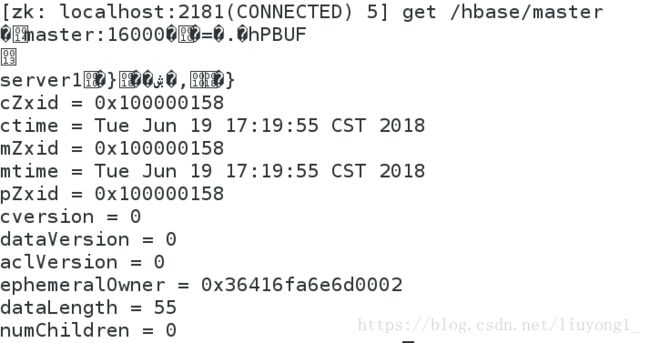
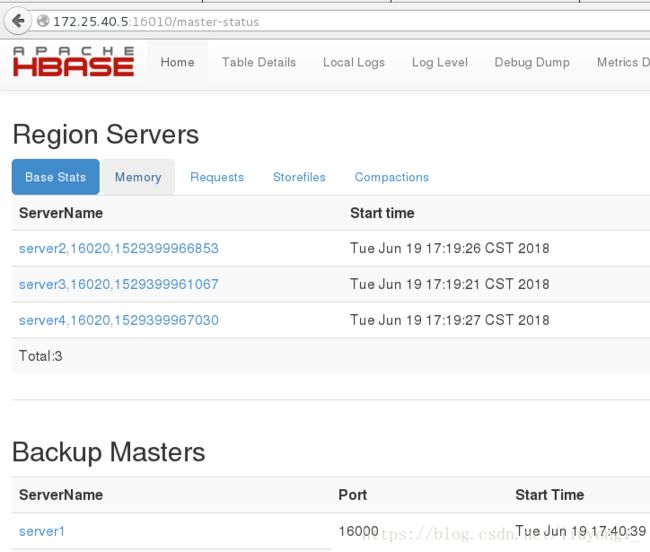
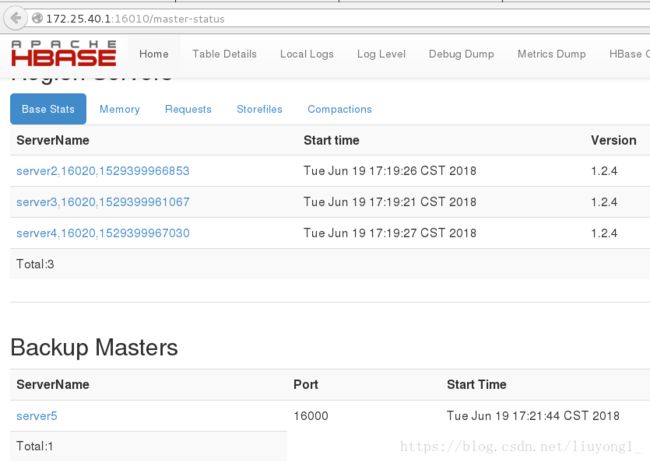
HBase Master 默认端口时 16000,还有个 web 界面默认在 Master 的 16010 端口
上,HBase RegionServers 会默认绑定 16020 端口,在端口 16030 上有一个展示
信息的界面
3) 测试
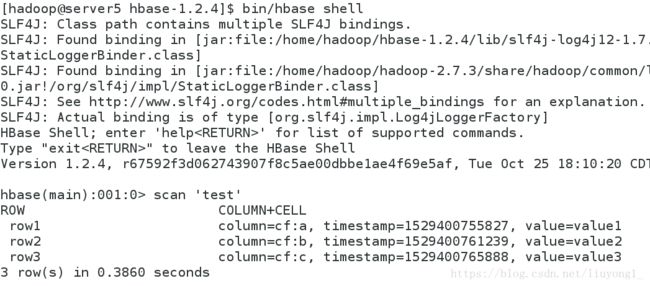
bin/hbase shell
hbase(main):001:0> create 'test', 'cf'
0 row(s) in 9.1810 seconds
=> Hbase::Table - test
hbase(main):002:0> list 'test'
TABLE
test
1 row(s) in 0.0590 seconds
=> ["test"]
hbase(main):003:0> put 'test', 'row1', 'cf:a', 'value1'
0 row(s) in 0.4460 seconds
hbase(main):004:0> put 'test', 'row2', 'cf:b', 'value2'
0 row(s) in 0.0160 seconds
hbase(main):005:0> put 'test', 'row3', 'cf:c', 'value3'
0 row(s) in 0.0150 seconds
hbase(main):006:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1529400755827, value=value1
row2 column=cf:b, timestamp=1529400761239, value=value2
row3 column=cf:c, timestamp=1529400765888, value=value3
3 row(s) in 0.1240 seconds[hadoop@server1 hadoop]$ bin/hdfs dfs -ls /
在主节点上 kill 掉 HMaster 进程后查看故障切换