推荐系统 - 基于SVD++的协同召回算法
说明
1.SVD++相对SVD做了进一步的改进,主要的改进点还是在于兴趣矩阵的计算上, 相对于之前的兴趣度计算方式,就入了更多的特征项 来作为更好的评估依据,其主要增加了增加了用户对商品行为的隐式反馈向量的计算get_Yi ,训练,更新;以及用户对商品的行为集合构建。
2.其相对SVD的调整主要在这里把兴趣公式改成下式,其相对SVD结构,加入了右边的形式,通过隐式参数形式讲用户的喜好体现在模型中,其中Iu是用户u评论过的物品的集合,yj为隐藏的评价了物品j的个人喜好偏置,也通过梯度下降算法优化。这里的-1/2是个可调节的参数,具体新加内容的计算过程可以参见代码中的 getY函数。
。
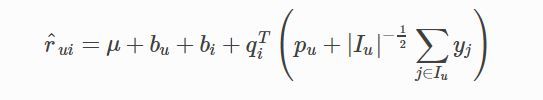
代码实现: rating = self.avg + self.bi[iid] + self.bu[uid] + np.sum(self.qi[iid] * (self.pu[uid] + u_impl_prf))
代码
数据集下载地址: https://pan.baidu.com/s/1D4H4dMDdp-5P6B7mebAIVQ 提取码:0i46
因为兴趣计算式比SVD更复杂,所以其计算时间是比较漫长的,但是效果要比SVD好得多。
# -*- encoding:utf-8 -*-
# author: wangle
import numpy as np
import random
import time
import pickle
'''
可以参考知乎这里的说明, https://zhuanlan.zhihu.com/p/42269534
但是发现训练速度好慢好慢。
SVD++相对SVD做了进一步的改进,主要的改进点还是在于兴趣矩阵的计算上, 相对于之前的兴趣度计算方式,就入了更多的特征项
来作为更好的评估依据,其主要增加了增加了用户对商品的隐式反馈向量的计算get_Yi ,训练,更新;以及用户对商品的行为集合构建。。
其相对SVD的调整主要在这里把:
rating = self.avg + self.bi[iid] + self.bu[uid] + np.sum(self.qi[iid] * (self.pu[uid] + u_impl_prf)) # 预测评分公式
具体新加的原因,参看https://blog.csdn.net/winone361/article/details/49427627 和 https://blog.csdn.net/akiyamamio11/article/details/79313339
'''
import numpy as np
import random
'''
author:huang
svd++ algorithm
'''
class SVDPP:
def __init__(self, mat, K=20):
self.mat = np.array(mat)
self.K = K
self.bi = {}
self.bu = {}
self.qi = {}
self.pu = {}
self.avg = np.mean(self.mat[:, 2])
self.y = {}
self.u_dict = {}
for i in range(self.mat.shape[0]):
uid = self.mat[i, 0]
iid = self.mat[i, 1]
self.u_dict.setdefault(uid, [])
self.u_dict[uid].append(iid)
self.bi.setdefault(iid, 0)
self.bu.setdefault(uid, 0)
self.qi.setdefault(iid, np.random.random((self.K, 1)) / 10 * np.sqrt(self.K))
self.pu.setdefault(uid, np.random.random((self.K, 1)) / 10 * np.sqrt(self.K))
self.y.setdefault(iid, np.zeros((self.K, 1)) + .1)
def predict(self, uid, iid): # 预测评分的函数
# setdefault的作用是当该用户或者物品未出现过时,新建它的bi,bu,qi,pu及用户评价过的物品u_dict,并设置初始值为0
self.bi.setdefault(iid, 0)
self.bu.setdefault(uid, 0)
self.qi.setdefault(iid, np.zeros((self.K, 1)))
self.pu.setdefault(uid, np.zeros((self.K, 1)))
self.y.setdefault(uid, np.zeros((self.K, 1)))
self.u_dict.setdefault(uid, [])
u_impl_prf, sqrt_Nu = self.getY(uid, iid)
rating = self.avg + self.bi[iid] + self.bu[uid] + np.sum(self.qi[iid] * (self.pu[uid] + u_impl_prf)) # 预测评分公式
# 由于评分范围在1到5,所以当分数大于5或小于1时,返回5,1.
if rating > 5:
rating = 5
if rating < 1:
rating = 1
return rating
# 计算sqrt_Nu和∑yj
def getY(self, uid, iid):
Nu = self.u_dict[uid]
I_Nu = len(Nu)
sqrt_Nu = np.sqrt(I_Nu)
y_u = np.zeros((self.K, 1))
if I_Nu == 0:
u_impl_prf = y_u
else:
for i in Nu:
y_u += self.y[i]
u_impl_prf = y_u / sqrt_Nu
return u_impl_prf, sqrt_Nu
def train(self, steps=30, gamma=0.04, Lambda=0.15): # 训练函数,step为迭代次数。
print('train data size', self.mat.shape)
for step in range(steps):
print('step', step + 1, 'is running')
KK = np.random.permutation(self.mat.shape[0]) # 随机梯度下降算法,kk为对矩阵进行随机洗牌
rmse = 0.0
for i in range(self.mat.shape[0]):
j = KK[i]
uid = self.mat[j, 0]
iid = self.mat[j, 1]
rating = self.mat[j, 2]
predict = self.predict(uid, iid)
u_impl_prf, sqrt_Nu = self.getY(uid, iid)
eui = rating - predict
rmse += eui ** 2
self.bu[uid] += gamma * (eui - Lambda * self.bu[uid])
self.bi[iid] += gamma * (eui - Lambda * self.bi[iid])
self.pu[uid] += gamma * (eui * self.qi[iid] - Lambda * self.pu[uid])
self.qi[iid] += gamma * (eui * (self.pu[uid] + u_impl_prf) - Lambda * self.qi[iid])
for j in self.u_dict[uid]:
self.y[j] += gamma * (eui * self.qi[j] / sqrt_Nu - Lambda * self.y[j])
gamma = 0.93 * gamma
print('rmse is', np.sqrt(rmse / self.mat.shape[0]))
def test(self, test_data): # gamma以0.93的学习率递减
test_data = np.array(test_data)
print('test data size', test_data.shape)
rmse = 0.0
for i in range(test_data.shape[0]):
uid = test_data[i, 0]
iid = test_data[i, 1]
rating = test_data[i, 2]
eui = rating - self.predict(uid, iid)
rmse += eui ** 2
print('rmse of test data is', np.sqrt(rmse / test_data.shape[0]))
def getMLData(): # 获取训练集和测试集的函数
import re
f = open("../data/ml-100k/u1.base", 'r')
lines = f.readlines()
f.close()
data = []
for line in lines:
list = re.split('\t|\n', line)
if int(list[2]) != 0:
data.append([int(i) for i in list[:3]])
train_data = data
f = open("../data/ml-100k/u1.test", 'r')
lines = f.readlines()
f.close()
data = []
for line in lines:
list = re.split('\t|\n', line)
if int(list[2]) != 0:
data.append([int(i) for i in list[:3]])
test_data = data
return train_data, test_data
train_data, test_data = getMLData()
a = SVDPP(train_data, 30)
a.train()
a.test(test_data)