DBoW和KeyFrameDatabase使用记录
这篇博客旨在记录一下DBoW和KeyFrameDatabase的小细节,以防后面再忘掉。18年初的时候参考ORB slam做重定位和闭环检测挖过DBoW里的代码,没想到过了一年多很多代码细节就记不清了。这次干脆记下来吧。
文章目录
- 一、DBoW
- 1、模板定义
- 2、模板应用
- 3、字典初始化
- 4、图像描述子向BowVector和FeatureVector转换
- 5、由两帧的BowVector计算两帧的相似度得分
- 6、训练字典(DBoW3中)
- 1) 对特征进行kmeans++聚类,创建字典树。
- 2) createWords
- 3) setNodeWeights
- 4) 保存字典
- 7、好的代码学习(DBoW中抽象类的多态性)
- 二、关键帧查询数据集 KeyFrameDatabase
- 1、重要成员变量
- 2、初始化
一、DBoW
1、模板定义
template<class TDescriptor, class F>
/// Generic Vocabulary
class TemplatedVocabulary
{
}
2、模板应用
ORB slam中定义了ORB描述子类型的字典
typedef DBoW2::TemplatedVocabulary<DBoW2::FORB::TDescriptor, DBoW2::FORB> ORBVocabulary;
其中TDescriptor是cv::Mat,FORB是为ORB描述子定义的类,其中包含了计算描述子之间汉明距离以及计算描述子平均值的方法。
3、字典初始化
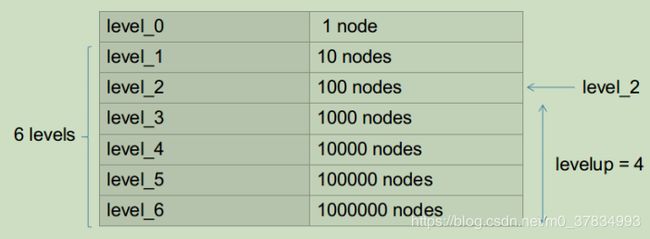
默认为10叉5层树状结构,L1_NROM距离和TF_IDF,加载txt字典时设置为6层。所说的6层是指除去根节点后中间节点及叶子节点占用的层数。
m_nodes包含了所有的节点,m_words只包含了叶子节点即最后的单词,m_words是一个vector数据,索引对应word的id,内容对应m_nodes中对应项的地址。
4、图像描述子向BowVector和FeatureVector转换
class BowVector: public std::map<WordId, WordValue>
{
//WordId是字典中word的id,不是nodeid
//WordValue是TF_IDF值
}
class FeatureVector: public std::map<NodeId, std::vector<unsigned int> >
{
//NodeId是levelup指定的那一层的对应的node的id
//vector是一个feature在当前KeyFrame中的索引
}
BowVector实际上是图像的一种降维表达,一幅图像可以表示为 v = { ( w 0 , η 0 ) , ( w 1 , η 1 ) , . . . , ( w i , η i ) , . . . } v = \{(w_0,\eta_0),(w_1,\eta_1),...,(w_i,\eta_i),...\} v={(w0,η0),(w1,η1),...,(wi,ηi),...}。其中 w i w_i wi是WordId, η i \eta_i ηi是单词 w i w_i wi的权重。 η i \eta_i ηi的计算采用TF_IDF方式,即:
η i = m i M l o g ( N n i ) \eta_i = \frac {m_i} {M} log(\frac{N}{n_i}) ηi=Mmilog(niN)
其中 m i M \frac {m_i} {M} Mmi是TF部分, m i m_i mi是 w i w_i wi在当前图像上出现的次数, M M M是当前图像上所有单词出现的总次数。 l o g ( N n i ) log(\frac {N} {n_i}) log(niN)是IDF部分, N N N是创建字典时所有特征的总数, n i n_i ni是 w i w_i wi对应的特征的个数。也就是说在一帧图像上某个单词出现的次数越多对该图像的区分度贡献越大,而在字典中某单词出现的越少则贡献越大,综合两者得出向量 v v v中每个word的权重。
将描述子沿着字典逐层向下搜索,在每层找出描述子汉明距离最小的node,并沿着该node进入到下一层Children中,重复操作直到叶子节点。如下图示意(3叉4层字典树),每一层方框中的节点被遍历,橙色的节点为根据ORB描述子选中的那一层的距离最近node,沿该node进入下一层,重复遍历操作,直到最底层。如果levelup设置的值为1,则level_3的橙色节点的nodeid被记录为FeatureVector的id项。
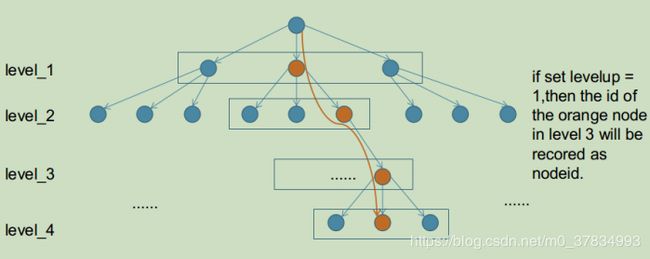
F e a t u r e V e c t o r FeatureVector FeatureVector是为了加速ORB slam中SearchByBow操作,如下图,对于一个6层的字典,ORB slam中levelup设置为4,则level_2的nodeid将会成为FeatureVector中的Key,而每个Key对应一张图像上的若干feature在该帧的索引值。这样在进行两帧图像的特征点匹配的时候就可以只将相同Key值下的特征描述子暴力匹配而不是对两帧图像的所有特征进行暴力匹配,达到加速算法的效果。
5、由两帧的BowVector计算两帧的相似度得分
BowVector v1,v2;
v1和v2分别是两个关键帧的BowVector,但两者可能只有一部分的WordId是相同的,计算得分时只计算相同的word得到的得分结果。
s = 0.5 × ∑ i = 1 N ∣ v 1 i ∣ + ∣ v 2 i ∣ − ∣ v 1 i − v 2 i ∣ s = 0.5 \times \sum_{i=1}^{N} |v1_i| + |v2_i| - |v1_i - v2_i| s=0.5×i=1∑N∣v1i∣+∣v2i∣−∣v1i−v2i∣
6、训练字典(DBoW3中)
demo_general.cpp中有用图片生成字典的示例,如下:
./demo_general orb ~/sequences/00/image_0/000000.png ~/sequences/00/image_0/000001.png
会利用000000.png和000001.png两张图片生成一个9叉3层的字典树,两幅图像当然太少了,示例给出了一个完整的pipeline供参考。具体创建过程是在create函数中,如下:
1) 对特征进行kmeans++聚类,创建字典树。
kmeans++ 算法可参考kmeans++算法介绍 kmeans++是一个递归算法。
1)从输入的数据点集合中随机选择一个点作为第一个聚类中心
2)对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x)
3)选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大
4)重复2和3直到k个聚类中心被选出来
5)利用这k个初始的聚类中心来运行标准的k-means算法
2) createWords
根据已经创建好的字典树遍历m_nodes判断如果是叶子节点就填充入m_words成员。m_words前面已经说过是vector,里面保存了叶子节点的地址,这样就可以根据word的id快速索引到对应的叶子节点。
3) setNodeWeights
给word添加idf权重。这个函数不长,参数training_features是一个vector型变量,内层的vector表示的是一帧图像上的所有特征描述子,一个cv::Mat是一个特征的描述子。执行的操作就是4中所述将每一帧图像上的feature沿着字典树向下查询其对应到哪个word,返回wordId,并增加对应word的计数。如果一帧图像上出现多个feature对应同一个word,则用counted[word_id]变量限制只对word的计数增加一次。最后是一次对每个word根据feature总数和word出现的次数计算 l o g ( N n i ) log(\frac {N} {n_i}) log(niN)作为idf权重值。代码如下:
void Vocabulary::setNodeWeights
(const std::vector<std::vector<cv::Mat> > &training_features)
{
const unsigned int NWords = m_words.size();//word的总数
const unsigned int NDocs = training_features.size();//feature的size,这里像是图像的帧数,不过这个值的缩放不会改变每个word的相对权重
if(m_weighting == TF || m_weighting == BINARY)
{
// idf part must be 1 always
for(unsigned int i = 0; i < NWords; i++)
m_words[i]->weight = 1;
}
else if(m_weighting == IDF || m_weighting == TF_IDF)
{
// IDF and TF-IDF: we calculte the idf path now
// Note: this actually calculates the idf part of the tf-idf score.
// The complete tf-idf score is calculated in ::transform
std::vector<unsigned int> Ni(NWords, 0);
std::vector<bool> counted(NWords, false);
for(auto mit = training_features.begin(); mit != training_features.end(); ++mit)
{
fill(counted.begin(), counted.end(), false);
for(auto fit = mit->begin(); fit < mit->end(); ++fit)
{
WordId word_id;
transform(*fit, word_id);
//这里会导致一帧上如果出现多个feature对应一个word,则只增加一次word的计数
if(!counted[word_id])
{
Ni[word_id]++;
counted[word_id] = true;
}
}
}
// set ln(N/Ni)
for(unsigned int i = 0; i < NWords; i++)
{
if(Ni[i] > 0)
{
m_words[i]->weight = log((double)NDocs / (double)Ni[i]);
}// else // This cannot occur if using kmeans++
}
}
}
4) 保存字典
DBow3支持yml格式输出和binary格式输出,至于想怎么输出完全可以自己定义,只是定义了save就需要自己定义对应的load函数就可以。DBow2支持txt和yml格式的save和load。
7、好的代码学习(DBoW中抽象类的多态性)
namespace DBoW2 {
/// Base class of scoring functions
class GeneralScoring
{
public:
virtual double score(const BowVector &v, const BowVector &w) const = 0;
virtual bool mustNormalize(LNorm &norm) const = 0;
static const double LOG_EPS;
virtual ~GeneralScoring() {}
};
/**
* Macro for defining Scoring classes
* @param NAME name of class
* @param MUSTNORMALIZE if vectors must be normalized to compute the score
* @param NORM type of norm to use when MUSTNORMALIZE
*/
#define __SCORING_CLASS(NAME, MUSTNORMALIZE, NORM) \
NAME: public GeneralScoring \
{ public: \
/** \
* Computes score between two vectors \
* @param v \
* @param w \
* @return score between v and w \
*/ \
virtual double score(const BowVector &v, const BowVector &w) const; \
\
/** \
* Says if a vector must be normalized according to the scoring function \
* @param norm (out) if true, norm to use
* @return true iff vectors must be normalized \
*/ \
virtual inline bool mustNormalize(LNorm &norm) const \
{ norm = NORM; return MUSTNORMALIZE; } \
}
/// L1 Scoring object
class __SCORING_CLASS(L1Scoring, true, L1);
/// L2 Scoring object
class __SCORING_CLASS(L2Scoring, true, L2);
/// Chi square Scoring object
class __SCORING_CLASS(ChiSquareScoring, true, L1);
/// KL divergence Scoring object
class __SCORING_CLASS(KLScoring, true, L1);
/// Bhattacharyya Scoring object
class __SCORING_CLASS(BhattacharyyaScoring, true, L1);
/// Dot product Scoring object
class __SCORING_CLASS(DotProductScoring, false, L1);
#undef __SCORING_CLASS
}
首先通过定义__SCORING_CLASS宏高效的定义了多个scoring子类。
然后,在TemplatedVocabulary中定义了一个GeneralScoring* m_scoring_object;的抽象类指针,通过GeneralScoring的子类来实现其中的纯虚函数,并在createScoringObject()函数中根据配置为m_scoring_object赋值,代码如下,从而实现了多态。能够兼容不同的计算相似性分数的方法。
void TemplatedVocabulary<TDescriptor,F>::createScoringObject()
{
delete m_scoring_object;
m_scoring_object = NULL;
switch(m_scoring)
{
case L1_NORM:
m_scoring_object = new L1Scoring;
break;
case L2_NORM:
m_scoring_object = new L2Scoring;
break;
case CHI_SQUARE:
m_scoring_object = new ChiSquareScoring;
break;
case KL:
m_scoring_object = new KLScoring;
break;
case BHATTACHARYYA:
m_scoring_object = new BhattacharyyaScoring;
break;
case DOT_PRODUCT:
m_scoring_object = new DotProductScoring;
break;
}
}
二、关键帧查询数据集 KeyFrameDatabase
KeyFrameDatabase的主要用于检测闭环候选帧和重定位候选帧。
1、重要成员变量
std::vector<list<KeyFrame*>> mvInvertedFile;
其主要用途为找到含有某个Word的所有关键帧的指针。每一个关键帧在ORB loopClosing线程中都被加入到KeyFrameDatabase中,同时删除冗余关键帧的时候也会将其从KeyFrameDatabase中删除。
2、初始化
KeyFrameDatabase::KeyFrameDatabase (const ORBVocabulary &voc):
mpVoc(&voc)
{
mvInvertedFile.resize(voc.size());
}
即根据字典的word数量初始化了vector的大小,vector的每个元素是一个list。
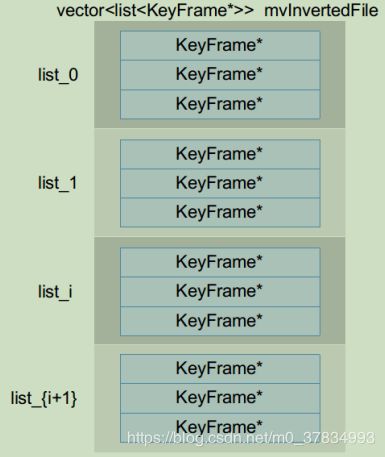
图中i是WordId。
每一个关键帧都有一个FeatureVector,其含义如下:

其中vector是该NodeId下对应的feature在当前关键帧上的索引值。
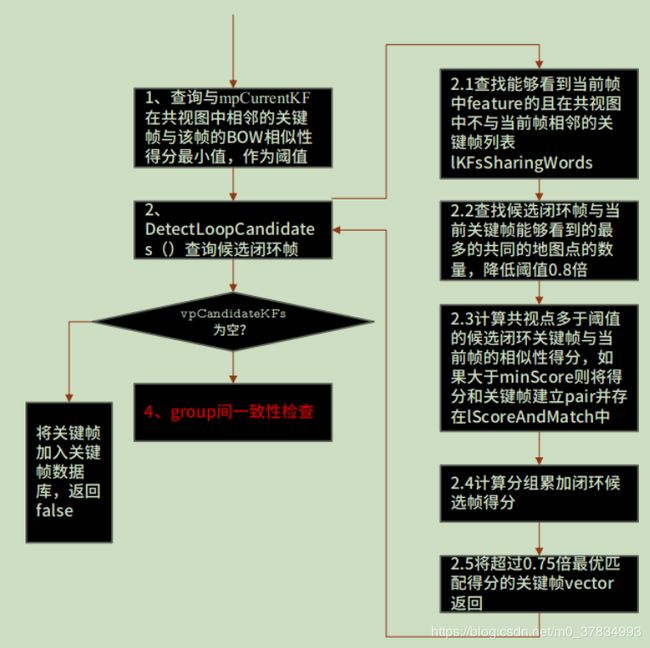
闭环检测候选帧和重定位候选帧的流程基本相同,下面给出ORB闭环检测挑选候选帧的流程图: